美团大数据查询技术
系列文章
- 实时存储引擎和实时计算引擎
- 美团点评 Hadoop/Spark 系统实践
- 美团大数据查询技术
- 美团深度学习平台实践
- 美团广告系统实践
文章目录
- 系列文章
- 一、应用场景
- 二、系统架构
-
- 2.1.系统架构 Review - Presto
- 2.2.分布式 OLAP 系统扩展技术
-
- 2.2.1 Kylin 与 Cube 预聚合
- 2.2.2 Druid 与 流式写入隔离,维度列倒排
- 2.2.3 Clickhouse 与 SIMD
- 2.2.4 Doris 与 我们的融合计划
- 三、改造案例
-
- 3.1 Presto on Yarn
- 3.2 统一ADhoc查询One SQL
- 3.3 统一OLAP建设
- 3.4 数据库对比方法
本文主要涉及数据资源与服务中的数据产品和数据服务部分。
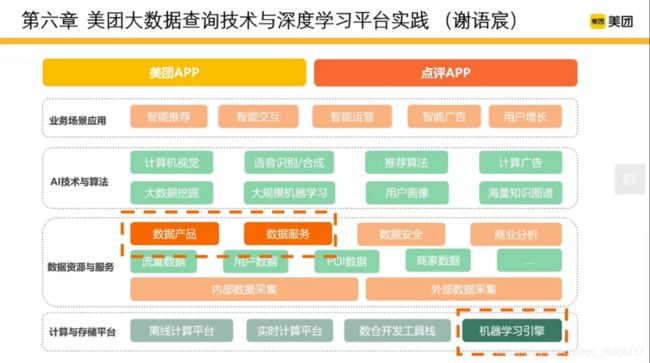
本文目录如下:

一、应用场景
背景:电子公交卡的业务试点,想要了解这个业务对整个美团 App 有什么样的影响。
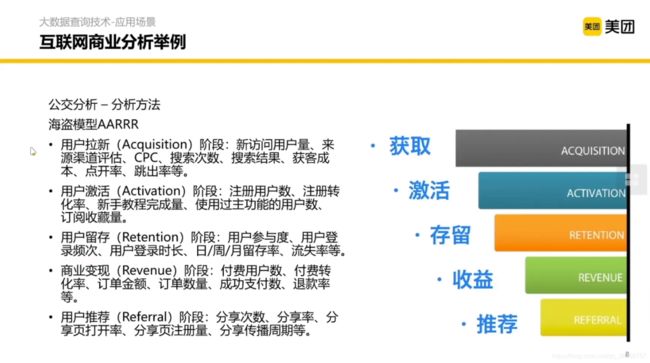
《增长黑客》中提到了一个海盗模型的方法,本质上是对流量的转换做一个漏斗形的拆解和分析。包含了从获取用户到用户转化和激活的步骤和对应的分析方法。
但是仅有方法是不够的,还要有对应的数据支撑。那数据是怎么组织的呢?这里分为5个部分。
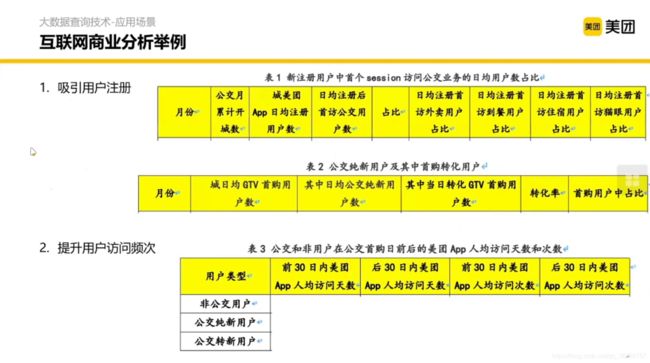
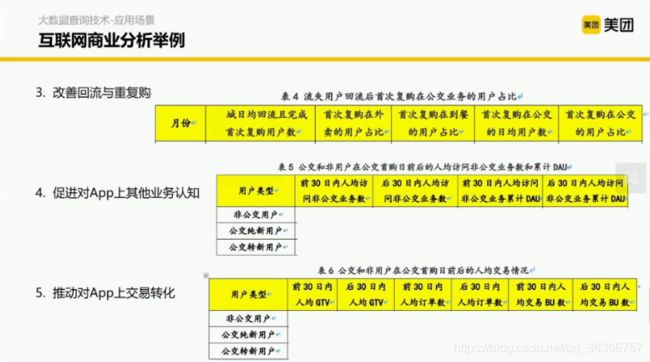
那我们要做这些分析的时候该怎么办呢?
就要看下面这种 SQL。
先看 FROM,关联订单表、城市表和城市维度表
然后看 WHERE,选出来在 18 年 8 月到 19 年 8 月之间的公交业务和复购的订单
再看 GROUP BY 和 SUM,基本就清楚了。

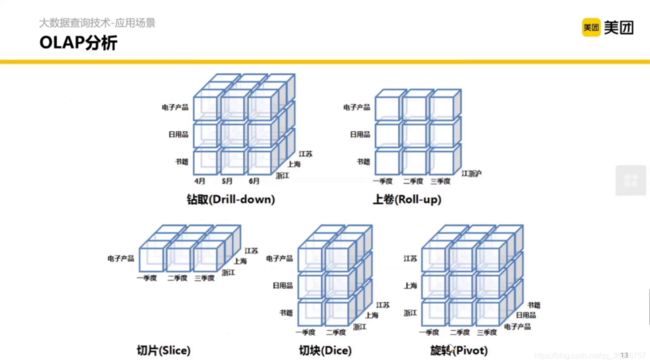
这里用到了之前说到的 OLAP 分析。OLAP 分析有哪些方法呢?这里提到了 5 种。
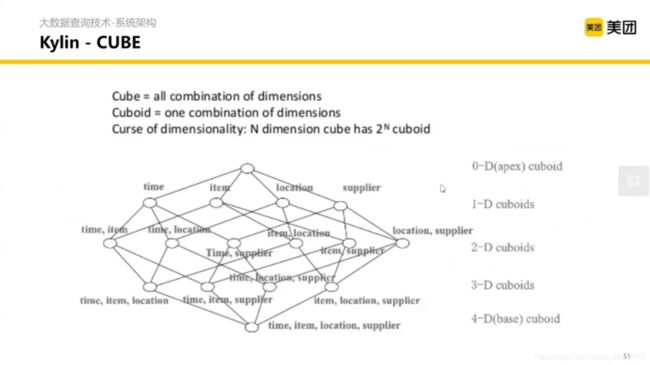
- 钻取(下钻):增加维度,能够通过更细的粒度去分析问题。(假设一个长方体有一层,扩展成三层)
- 上卷(上钻):减少维度,能够从宏观(相对)的角度看待问题。(假设一个立方体有三层,压缩成一层)
- 切片:同一个维度,只看其某一个值。(假设一个立方体有三层,只保留一层)
- 切块:同一个维度,只看其某几个值。(假设一个立方体有三层,只保留两层)
- 旋转:行列变换。
一些商业 BI 系统

二、系统架构
2.1.系统架构 Review - Presto
重点介绍一下使用比较广,也比较有代表性的数据库来看一下分布式 SQL 语句是怎么跑起来的。
首先介绍一下美团这边的数据库选型思路。主要分为三种以下场景:

我们下一阶段介绍的 Presto 主要是在即席查询这个部分。先来看下 Presto 的演化历史,如果有兴趣的话。

设计理念一言以蔽之的话就是用可靠性换性能,之前我们说到的 Spark 和 Map Reduce 在 shuffle 的过程中是落盘的,这样即使一个节点挂了,也能在之前的基础上很快的跑起来,尽可能的复用之前的数据。但是 Presto 并没有考虑这个问题,他的定位相对于 Hive 和 Spark 超大规模的场景。
然后如果扛不住了就尽快挂掉(fail fast)。也可以关联其他类型数据库的数据。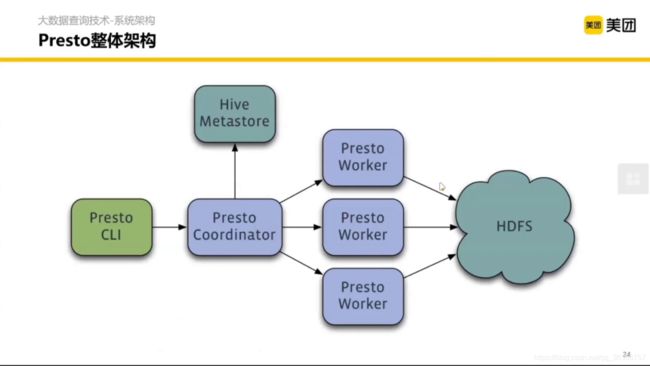
然后宏观来看,整体架构如上图。蓝色的是 Presto 本身的服务, 前置呢是一个客户端类型的控件,类似 MySQL 的命令行。MetaStore 基本上存的是数据在 HDFS 上的表、库怎么组织的元数据。(禁止套娃)
Presto 内部还是主从架构,Cordinator 是协调者, Worker 是打工人。
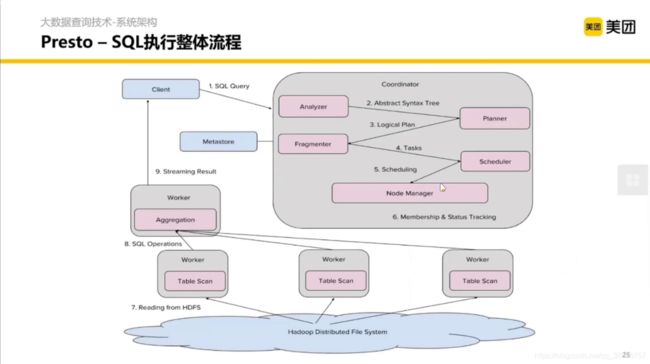
详细架构如图:
Client 提交一个 SQL,在 Coordinator 内做分析、计划、拆分、调度,然后提交每个 Worker 管理的模块,每个 Worker 拿到任务之后从 HDFS 去扫数据然后计算,每个 Worker 聚合之后再通过一个流接口返回给 Client。
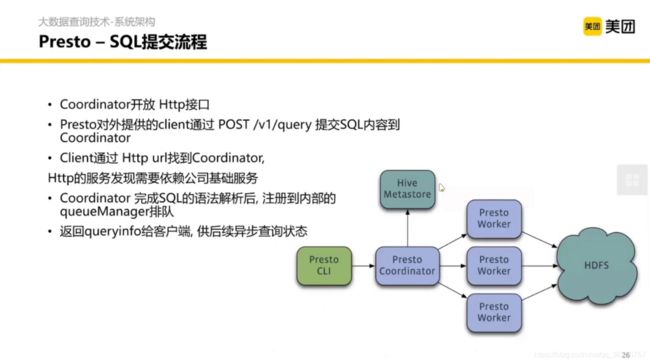
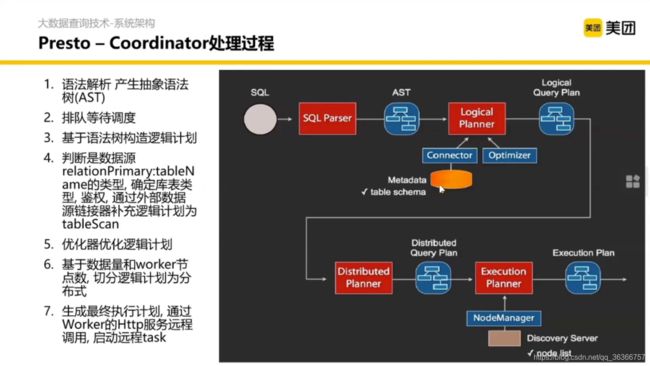
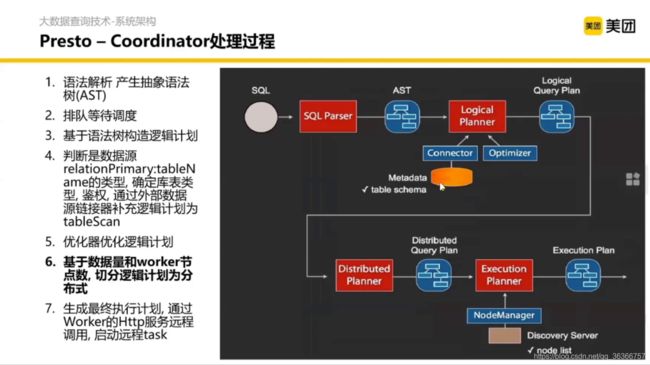
重要的部分是 Coordinator 内部的处理过程。
语法解析怎么解析呢?这里其实涉及编译原理的知识,通过词法分析、语法分析等生成语法树。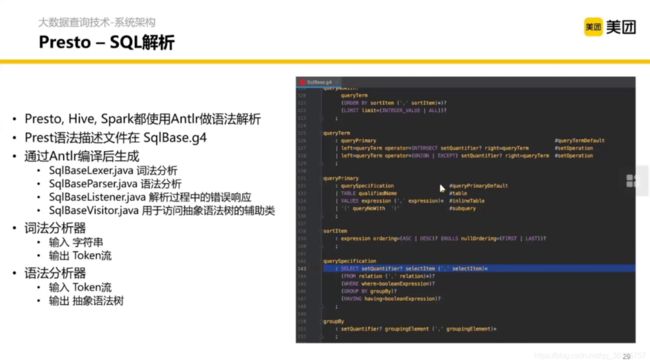
语法树长什么样呢?大概就是这个样子

在 SQL 语句打一个 explain 数据库会告诉你接下来怎么执行。根据上面得到的语法树去构造一个执行过程的逻辑计划。

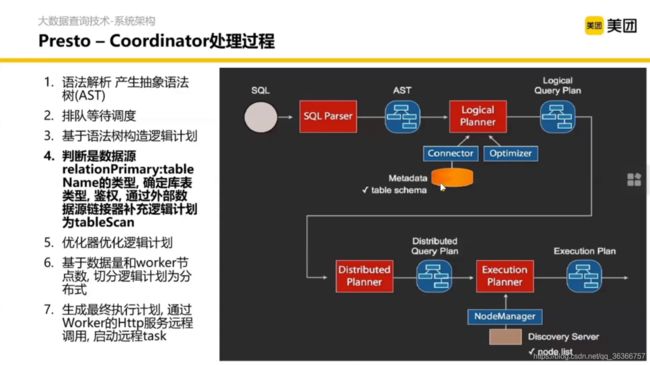
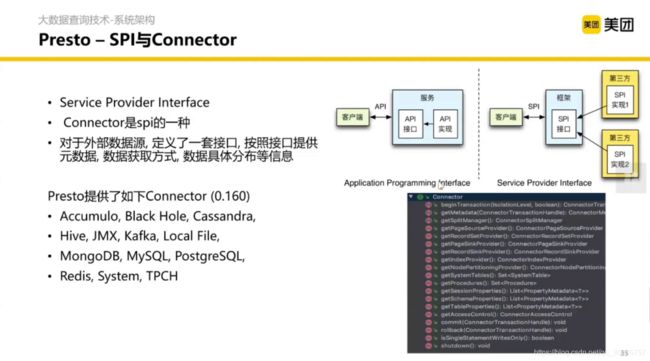
这里是 Presto 对数据源的接入抽象,在读数据这一层对于 SQL 本身是屏蔽了的,这要做一些配置就能去访问数据源。
这里说的是 SQL 的优化部分。pv 是用户浏览的表。
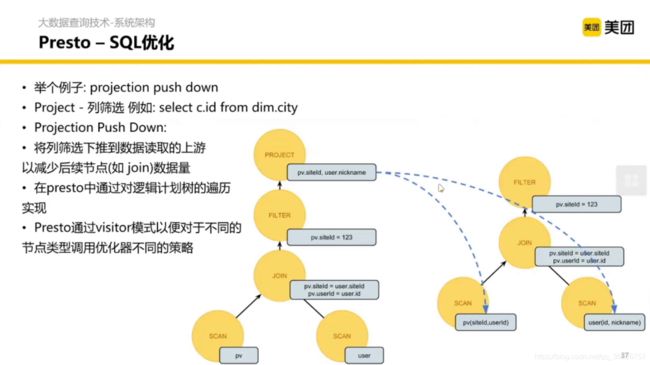
正常我们写一个 SQL 的过程是关联 pv 和 user,然后选出符合条件的行。那这里能不能优化呢?如果能又要怎么优化呢?
当数据很多的时候,如果我们在关联表之前筛选出我们需要的数据就好了。在 Presto 中,在关联之前,扫描表的时候,并不拿出全部的数据,只用 siteId 和 userid 进行关联,这样变得更高效了。
那怎么做到这些优化呢?首先会定义一些规则,然后基于这些逻辑计划的树结构,一遍遍的去跑这些优化的策略,但凡是发现类似的结构,就可以去调逻辑计划的树,让整个 SQL 更高效。

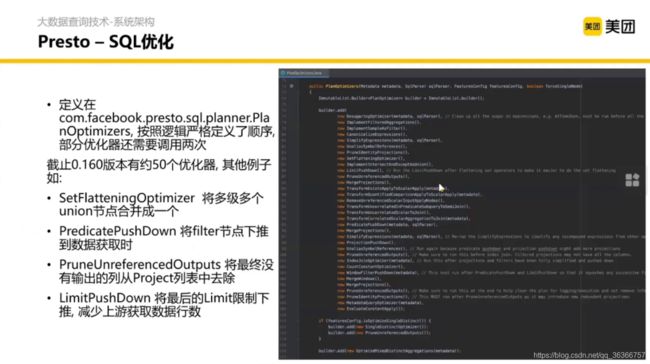
对逻辑计划优化完之后,我们就要考虑如何将逻辑计划进行物理实现。
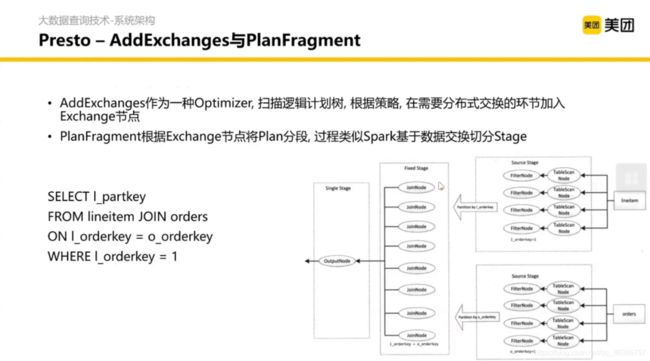
划分主要是基于 Optimizer 的抽象做的。然后切分完之后会做一些 Shuffle 和 Group by 以及 HashJoin。
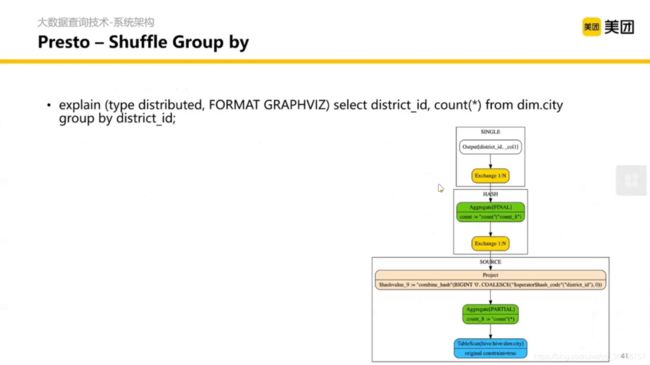
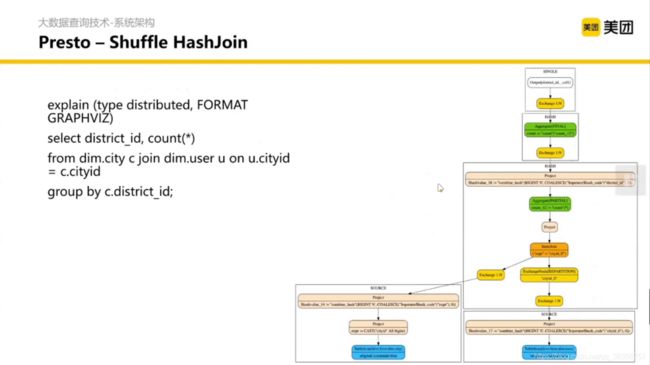
这里的 Shuffle 是不落盘的。
提问:如果在 Shuffle 的时候不落盘了, SQL 会收什么限制?(提示:在 join / groupby 的时候)
答:在关联的时候或者合并的时候,我们想要把同一个 key
的数据在同一个节点计算,但是如果发生了数据倾斜,某一个节点的数据特别多这个节点的内存就会爆炸。
然后我们得到了分布式的执行计划,调度到每个节点分别执行。这就是 Coordinator 内部的详细执行逻辑。
下面是物理计划的调度。
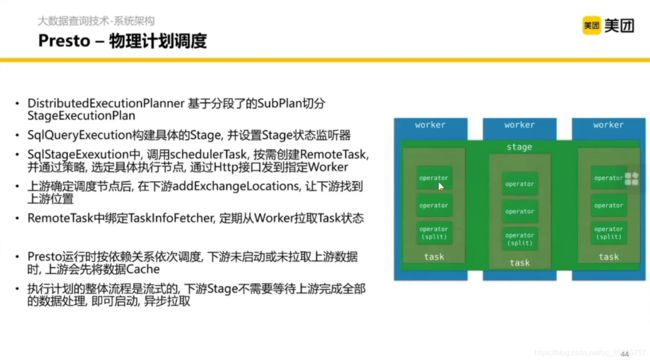
Presto 也会做一些物理层面的计划,比如 codegen,主要特点是 运行时编译。
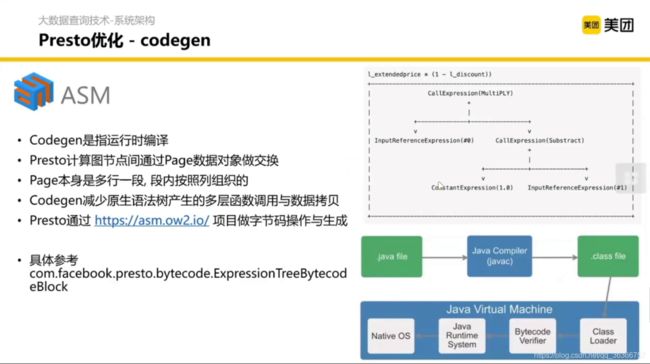
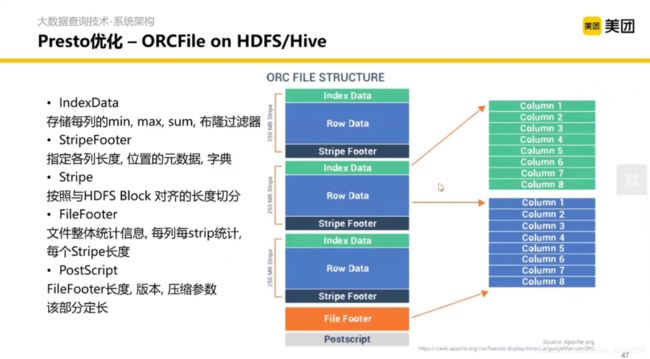
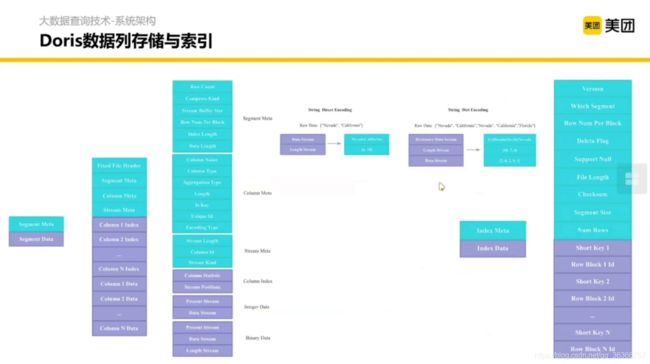
另外一个优化是偏存储层的,数据索引和数据组织结构的优化。从只按行存储的结构衍生出按列存储的结构(如 ORC、parquet等)。
2.2.分布式 OLAP 系统扩展技术
介绍一些系统在实现架构设计的时候的一些权衡。主要介绍四个系统:Kylin,Druid,Clickhouse 和 Doris。
2.2.1 Kylin 与 Cube 预聚合
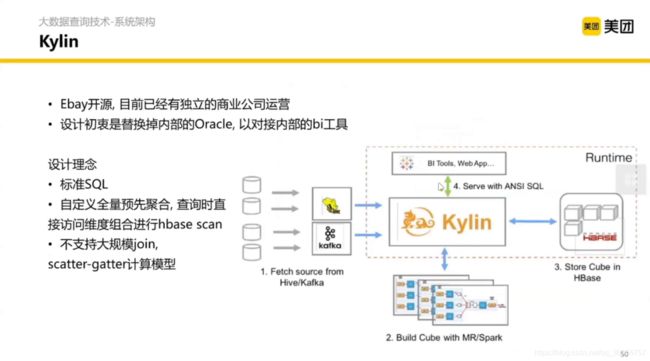
有开源和商业版本。具体特点的是预聚合。什么意思呢?
假设一个事实表有很多维度,经常需要根据这些维度进行聚合,然后 Kylin 在我们查找之前就会聚合好,当我们查找到时候去到 Kylin 里面刷选就好。在数据立方体分析的时候很常用。
2.2.2 Druid 与 流式写入隔离,维度列倒排
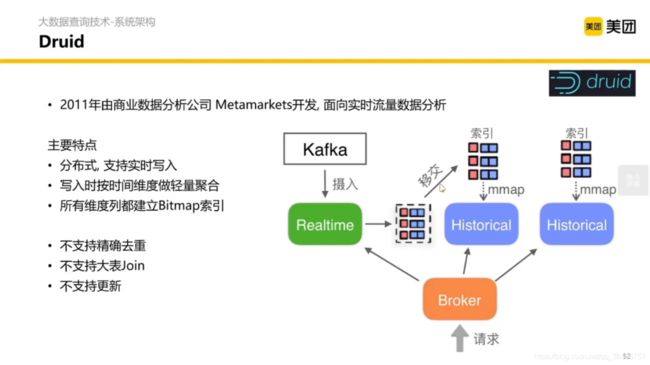
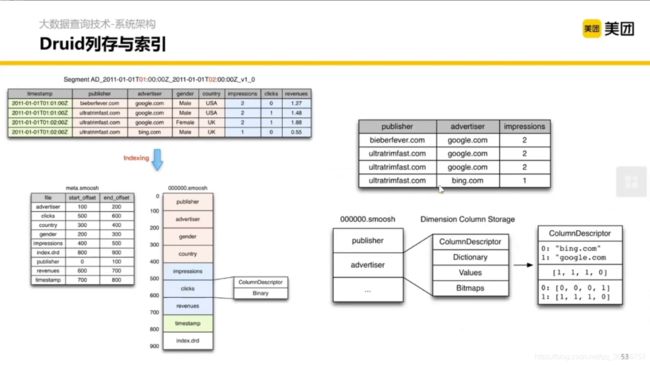
本身 Druid 也是列式存储,更极致的是做了一个倒排索引——用一个 bitmap 存储一个列的值的索引。
比如在列 advertiser 中有两个值,我们扫描整列可以得到一个 bitmap,{"bing.com” :[0,0,0,1], “google.com” : [1, 1, 1, 0]}。数组的长度是列的行数,bing.com 对应的 [0,0,0,1] 的意思是在第 4 行出现的 bing.com 这个值。为什么是 4 呢?因为数组中 1 的位置/索引是 4 (索引 1 开始)。我们也很容易看出 google.com 对应的 [1, 1, 1, 0] 意思是在第1,2,3 行出现了 google.com。
这样当我们 WHERE 之后有多个条件的时候就可以直接取 and 操作,使运算变得高效。
2.2.3 Clickhouse 与 SIMD
主要是通过利用硬件和内存提高现场计算能力,能够充分利用CPU。


2.2.4 Doris 与 我们的融合计划
Doris 是内聚的,没有大的外部依赖。兼容 MySQL 协议。(之前叫Palo,OLAP的反写)

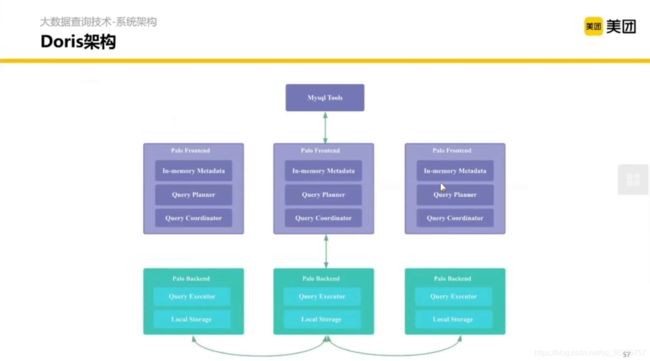
Frontend 可以认为是 Presto 横向扩展的 Coordinator,Bankend 可以认为是横向扩展的 Worker 加一些存储。
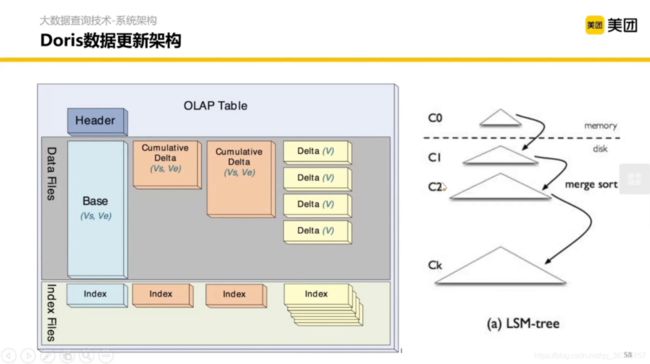
使用 LSM-Tree 的模式。解决了在快速大批量写入的时候,我希望在整体吞吐能力提升的同时,对 KV 的查询有一个比较快的结果的问题。
三、改造案例
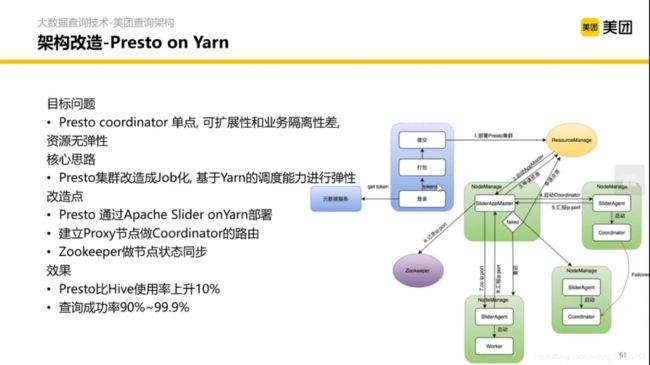
3.1 Presto on Yarn
把 Presto 的弹性伸缩,查询调度以及 YARN 绑定在一起。
3.2 统一ADhoc查询One SQL
主要是解决多引擎的方言不同等问题
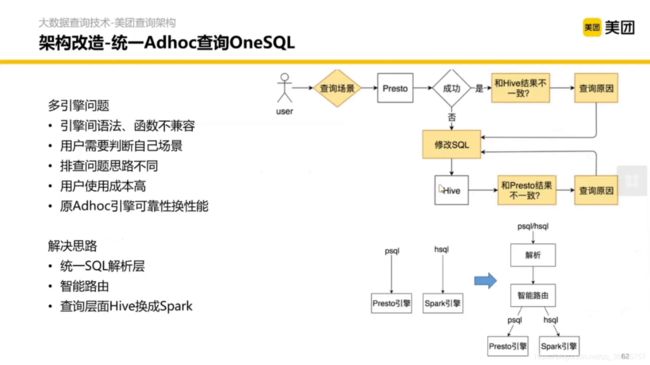
改造后的架构如图:

(竟然还有训练决策树模型,抽取特征判断语句在那个数据库上更快,再生成对应的引擎方言)
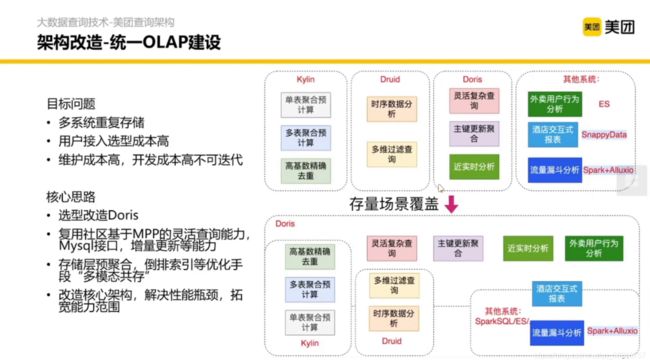
3.3 统一OLAP建设
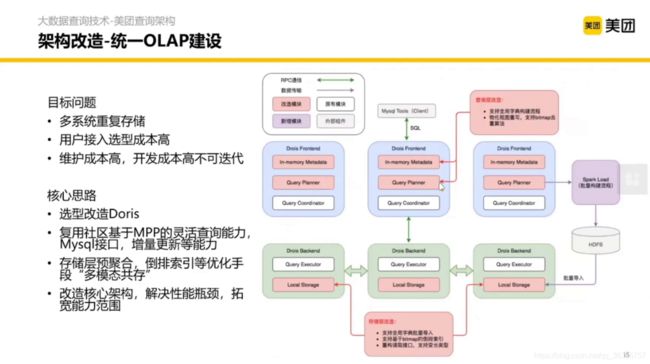
3.4 数据库对比方法
通过多维角度对比数据库,有两个方法可以帮你构建数据库的内容和 SQL 的结构,后拿着结构去测试数据库的实现。
这是改造完之后的性能对比:
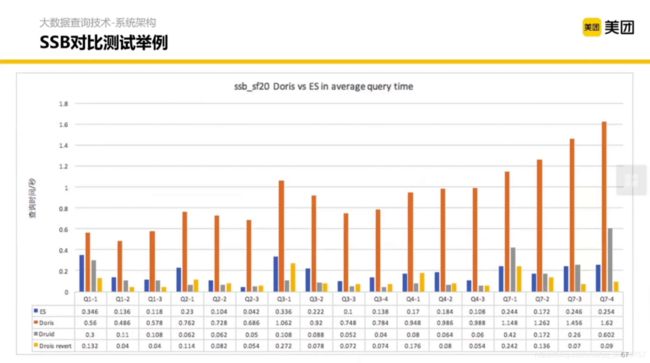
学习不易,且赞且收藏。