大数据技术之Spark(二)——RDD常用算子介绍
目录
前言
一、转换算子
1.1 Value类型
1)map
2)mapPatririons
map和mapPartitions的区别:
3)mapPartitionsWithIndex
4)flatMap
5)glom
6)groupBy
7)filter
8) sample
9)distinct
10)coalesce
11)repartition
12)sortBy
1.2 双Value类型
13)intersection
14)union
15)subtract
16)zip
1.3 Key-Value类型
17)partitionBy
18)reduceByKey
19)groupByKey
20)aggregateByKey
21)foldByKey
22)combineByKey
23)sortByKey
24)join
25)leftOuterJoin
26)cpgroup
1.4 案例实操
二、行动算子
1) reduce
2)collect
3)count
4)first
5)take
6)takeOrdered
7)aggregate
8)fold
9)countByKey
10)save相关算子
11)foreach
前言
RDD 的操作分为转化(Transformation)操作和行动(Action)操作。
转化操作就是从一个 RDD 产生一个新的 RDD;
行动操作就是进行实际的计算。
我们把RDD方法也称为算子。所以转换操作和行动操作一般也被叫做转换算子和行动算子。

一、转换算子
1.1 Value类型
1)map
说明:将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
val dataRDD = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = dataRDD.map(_+1)
dataRDD.collect
dataRDD2.collect
2)mapPatririons
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]说明:将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理。
val mprdd = sc.makeRDD(List(1,2,3,4,3,2,6,45,21,233),3)
// 查看元数据
mprdd.glom.collect
res29: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 3, 2), Array(6, 45, 21, 233))
// 过滤出偶数
mprdd.mapPartitions(x=> x.filter(_%2==0)).collect
res36: Array[Int] = Array(2, 4, 2, 6)
// 如果数据e>10,添加"a",否则添加"b"
mprdd.mapPartitions(x=> for(e<-x) yield(e,if(e>10) "aaa" else "b")).collect
res37: Array[(Int, String)] = Array((1,b), (2,b), (3,b), (4,b), (3,b), (2,b), (6,b), (45,aaa), (21,aaa), (233,aaa))![]()

其中,yield的主要作用是记住每次迭代中的有关值,并逐一存入到一个数组中。
—— map和mapPartitions的区别:
- 数据处理角度:
map 算子 是 分区内 一个数据一个数据的执行, 类似于串行操作 。mapPartitions 算子 是以分区为单位进行批处理操作。
- 功能的角度:
map 算子主要目的将数据源中的 数据进行转换和改变。但是 不会减少或增多数据。 m apPartitions 算子需要 传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变, 所以可以增加或减少数据。
- 性能的角度:
m ap 算子因为类似于串行操作,所以性能比较低mapPartitions 算子类似于批处理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作完成即可。
3)mapPartitionsWithIndex
说明:mapPartitions可以实现分区的功能,但是我们无法知道数据存储在第几个分区。而且分区是无序的,不能保证哪个分区先执行。为了解决这类问题,我们引入了mapPartitionsWithIndex,增加了分区编号(分区索引)。
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]-
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
val mprdd = sc.makeRDD(List(1,2,3,4,3,2,6,45,21,233),3) mprdd.mapPartitionsWithIndex((index,x) => for(e<-x) yield(index,e)).collect res49: Array[(Int, Int)] = Array((0,1), (0,2), (0,3), (1,4), (1,3), (1,2), (2,6), (2,45), (2,21), (2,233))
4)flatMap
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]val array = mprdd.glom.collect
array: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 3, 2), Array(6, 45, 21, 233))
// 未用展开
array.foreach(x=>println(x))
[I@3f2ab74f
[I@6b1c4de4
[I@795de682
array.map(x=>(x,"A")).foreach(x=>print(x))
([I@3f2ab74f,A)([I@6b1c4de4,A)([I@795de682,A)
scala> array.flatMap(x=>x).foreach(println)
1
2
3
4
3
2
6
45
21
233
array.flatMap(x=>x).map(x=>(x,"A")).foreach(x=>print(x))
(1,A)(2,A)(3,A)(4,A)(3,A)(2,A)(6,A)(45,A)(21,A)(233,A)


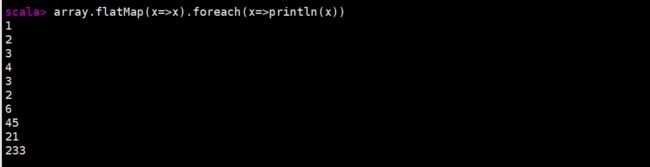
flatMap( arr => arr ) 中,将传入的Array数组整体拆分成一个个的个体。但是返回值不能有多个,需要进行简单封装。
第一个arr:传入的元素
第二个arr:为了将单独的个体一起返回,进行了封装
rdd.flatMap( x => x match {
case list:List[_] => list;
case data=>List(data)
}
).collect
res71: Array[Any] = Array(1, 2, 3, 4, 5)

5)glom
def glom(): RDD[Array[T]]
定义完分区之后,显示mprdd的数据类型为RDD[Int] 类型,无法查看到具体的分区信息。通过glom可以进行查看。
val mprdd = sc.makeRDD(List(1,2,3,4,3,2,6,45,21,233),3)
// 使用glom算子
mprdd.glom.collect
res72: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 3, 2), Array(6, 45, 21, 233))
// 未使用glom算子
mprdd.collect
res73: Array[Int] = Array(1, 2, 3, 4, 3, 2, 6, 45, 21, 233)

6)groupBy
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]说明:将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样 的操作称之为 shuffle。极限情况下,数据可能被分在同一个分区中。
groupBy会将数据源中的每一个数据进行分组判断,根据返回的分组key进行分组。
相同的key值的数据回放置再一个组中。
注意:分组和分区没有必然的关系。groupBy会将数据打乱(打散),重新组合。这个操作我们称之为shuffle。极限情况下,数据可能被分再同一个分区中。
一个组的数据在一个分区中,但一个分区不一定只有一个组。

mprdd.groupBy(_%2==0).collect
res109: Array[(Boolean, Iterable[Int])] = Array((false,CompactBuffer(1, 3, 3, 45, 21, 233)), (true,CompactBuffer(2, 4, 2, 6)))

7)filter
def filter(f: T => Boolean): RDD[T]说明:将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。 当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
val dataRDD = sc.makeRDD(List(1,2,3,4,1,2,4,21))
dataRDD.filter(_%2==0).collect
8) sample
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]说明:根据指定的规则从数据集中抽取数据
val rdd = sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
// sample算子需要传递三个参数
// 1. 第一个参数:抽取数据后是否将数据返回 true(返回),false(丢弃)
// 2. 第二个参数:
抽取不放回:数据源中每条数据被抽取的概率,基准值的概念
抽取放回:数据源中的每条数据被抽取的可能次数
// 3. 第三个参数:抽取数据时随机算法的种子
// 如果不传递第三个参数,那么使用的是当前系统时间
rdd.sample(false,0.4,1).collect

sample算子的作用:
当发生数据倾斜的时候可以使用sample算子。
在分区的时候数据是均衡的,但进行了shuffle操作之后,数据会被打乱重新组合。如果shuffle后的数据分布不均匀,可以通过sample算子进行抽取数据。
9)distinct
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]说明:将数据集中重复的数据去重。
val rdd = sc.makeRDD(List(1,2,3,4,1,2,3,4))
// 数据去重
rdd.distinct.collect
// 去重后分区
rdd.distinct(3).glom.collect- distinct

- distinct(3)

10)coalesce
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T]说明:根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本。
coalesce方法默认不会将分区的数据打乱重新组合。这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜。如果想要让数据均衡,可以进行shuffle处理。
object Partition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("partitions").setMaster("local[5]")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(1 to 20)
rdd.glom.collect().foreach(x=>println(x.toList))
println("===================coalesce,false(默认不进行shuffle)===================")
// 分区合并,不进行shuffle
val rdd2 = rdd.coalesce(3,false)
rdd2.glom.collect().foreach(x=>println(x.toList))
println("===================coalesce,true(进行shuffle处理)===================")
// 重新shuffle
val rdd3 = rdd.coalesce(3,true)
rdd3.glom.collect().foreach(x=>println(x.toList))
}
}
11)repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]说明:该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的 RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition 操作都可以完成,因为无论如何都会经 shuffle 过程。

——coalesce和repartition的区别
coalesce算子可以用于扩大分区。但是如果不进行shuffle操作,操作不起作用。这时候的coalesce操作没有意义。所以如果想要实现扩大分区的效果,需要使用shuffle操作。
也就是说,shuffle为false时,如果传入的分区参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的。
repartition算子只是coalesce接口中shuffle为true的简易实现。
缩减分区:coalesce。如果想要数据均衡,可以采用shuffle
扩大分区:repartition,底层调用的是coalesce,且肯定采用shuffle。
12)sortBy
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]说明:该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理 的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一 致。中间存在 shuffle 的过程。
object SortRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("sort")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(2,4,1,5,14,2))
val unit = rdd.sortBy(x=>x)
unit.collect.foreach(println)
}
}
sortBy方法可以根据指定的规则对数据源中的数据进行排序。默认为升序。第二个参数可以改变排序的方式。
sortBy默认情况下,不会改变分区。但是中间存在shuffle操作。
object SortRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("sort")
val sc = new SparkContext(conf)
val rdd2 = sc.makeRDD(List(("1",1),("12",2),("2",3)))
val newRDD = rdd2.sortBy(x=>x._1.toInt,false)
newRDD.collect().foreach(println)
}
}1.2 双Value类型
13)intersection
def intersection(other: RDD[T]): RDD[T]val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.intersection(dataRDD2)
14)union
def union(other: RDD[T]):val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.union(dataRDD2)
15)subtract
def subtract(other: RDD[T]): RDD[T]val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.subtract(dataRDD2)

16)zip
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.zip(dataRDD2)
注意点:
数据类型:
交集、并集、差集要求两个数据源的数据类型保持一致。
拉链操作两个数据源的类型可以不一致。
分区数量:
zip操作的两个数据源要求分区数量要保持一致。
分区数据量:
zip操作的两个数据源要求分区中数据的数量要保持一致。
1.3 Key-Value类型
17)partitionBy
def partitionBy(partitioner: Partitioner): RDD[(K, V)]object Transform_scala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Operator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD((List(1,2,3,4)))
val mapRDD = rdd.map((_,1))
// partitionBy根据指定的分区规则对数据进行重分区
mapRDD.partitionBy(new HashPartitioner(2)).saveAsTextFile("output")
}
}如果重分区的分区器和当前 RDD 的分区器一样怎么办?匹配 类型 相等、分区 数量 相等,会被认为是同一个分区器。不会执行任何操作,返回本身,不会产生新的RDD。Spark 还有其他分区器吗?- HashPartitioner- RangePartitioner- PythonPartitioner
18)reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
val dataRDD2 = dataRDD1.reduceByKey(_+_)
val dataRDD3 = dataRDD1.reduceByKey(_+_, 2)19)groupByKey
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
val dataRDD2 = dataRDD1.groupByKey();
——groupBy和groupByKey的区别
groupBy()方法是根据用户自定义的情况进行分组
groupByKey()方法则是根据key值进行分组的
也就是说,进行groupByKey()方法的数据本身就是一种key-value类型的,并且数据的分组方式就是根据这个key值相同的进行分组的。
——groupByKey和reduceByKey的区别
spark中,shuffle操作必须落盘处理,不能在内存中数据等待,会导致内存溢出。所以shuffle操作的性能较低。
reduceByKey 和 groupByKey 都存在 shuffle 的操作。
groupByKey [只有分组,没有聚合] 只是进行分组,不存在数据量减少的问题
reduceByKey [分组+聚合] 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少shuffle时落盘的数据量
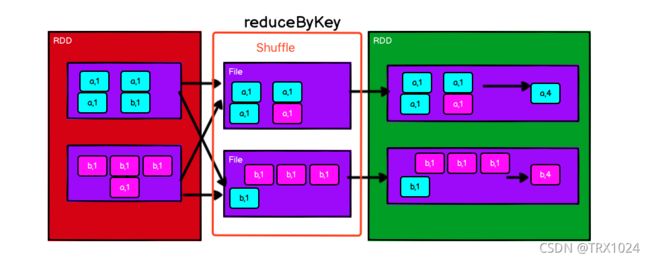
在红色RDD的一个分区中就有相同的Key,而且value是可以聚合的。
由于groupbykey没有聚合功能,实现聚合计算是将所有数据分组完成后再进行聚合。
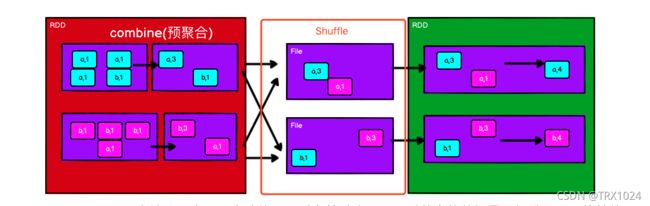
而 reduceByKey 是有聚合功能的,实现过程中,在分组前也同样满足聚合条。所以reduceByKey可以实现在分组前就将数据先进行聚合(预聚合),流程图如下:
所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey。

20)aggregateByKey
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]aggregateByKey存在函数柯里化,有 两个参数列表:
第一个参数列表:需要传递1个参数,表示为初始值
主要用于当碰见第一个key的时候,和value进行分区内计算
第二个参数列表:需要传递2个参数
第一个参数: 分区内计算规则
第二个参数: 分区间计算规则

object Transform_scala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Operator").setMaster("local[*]")
val sc = new SparkContext(conf)
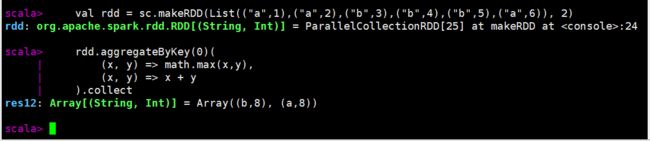
val rdd = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4),("b",5),("a",6)), 2)
// (a,[1,2]),(a,[3,4])
// (a,2), (a,4)
// (a,6)
rdd.aggregateByKey(0)(
(x, y) => math.max(x,y),
(x, y) => x + y
).collect
// 分区内和分区间如果操作一致,函数也可以简化为:
rdd.aggregateByKey(0)(_+_, _+_ ).collect
}
}
21)foldByKey
如果聚合计算时,分区内和分区间计算规则相同,spark提供了简化的方法用于简化aggregateByKey。
object Transform_scala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Operator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4),("b",5),("a",6)), 2)
rdd.foldByKey(0)( _+_ ).collect
}
}
22)combineByKey
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]combineByKey:方法需要三个参数
第一个参数表示:将相同key的第一个数据进行结构的转换,实现操作
第二个参数表示:分区内的计算规则
第三个参数表示:分区间的计算规则
object Transform_scala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Operator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4),("b",5),("a",6)), 2)
rdd.combineByKey( value => (value, 1 ))(
(x:(Int, Int), v) =>(x._1 + v, x._2 + 1),
(x1:(Int, Int), x2:(Int, Int)) => (x1._1 + x2._1, x1._2 + x2._2)
).collect
}
}——reduceByKey、foldByKey、aggregateByKey、combineByKey的区别
rdd.reduceByKey(_+_).collect
rdd.aggregateByKey(0)(_+_,_+_).collect
rdd.foldByKey(0)(_+_).collect
rdd.combineByKey(x=>x,(x:Int,y)=>x+y,(x:Int,y:Int)=>x+y).collect


核心都是调用combineByKeyClassTag函数,调用不同的参数,实现不同的功能。
combineByKeyClassTag[V]( createCombiner // 相同key的第一条数据进行的处理 mergeValue // 分区内数据的处理函数 mergeCombiners // 分区间数据的处理函数 )reduceByKey:
相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同
foldByKey:
相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同
aggregateByKey:
相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同
combineByKey:
当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区内和分区间计算规则不相同。
23)sortByKey
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]true:默认排序方式,按照key值从小到大排序false:按照key值从大到小排序
val rdd = sc.makeRDD(List((1,2),(1,3),(1,1),(2,3),(2,4),(2,1),(3,2),(4,1),(1,6)))

24)join
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]在类型为(K, V)和(K, W)的两个数据源上调用该方法。返回一个相同的key对应的所有元素连接在一起组成的(K, (V, W))类型的RDD。其中的(V, W)是一个元组tuple类型。
join:
两个不同数据源的数据,相同key的value会连接在一起,形成元组。
如果两个数据源中的key没有匹配上,那么数据不会出现在结果中。
如果两个数据源中的key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。
object Transform_scala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Operator").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(("a",1),("c",2),("b",3)))
val rdd2 = sc.makeRDD(List(("a",4),("c",2),("b",1)))
rdd1.join(rdd2).collect
}
}
25)leftOuterJoin & rightOuterJoin
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]val rdd2 = sc.makeRDD(List(("a",'4'),("c",'2'),("a",'1')))
rdd1.leftOuterJoin(rdd2).collect

26)cogroup(connect + group)
val cg: RDD[(String, (Iterable[Int], Iterable[Char]))] = rdd1.cogroup(rdd2)
cg.collect
二、行动算子
1) reduce
def reduce(f: (T, T) => T): T说明: 聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据。
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 聚合数据
val reduceResult: Int = rdd.reduce(_+_)2)collect
def collect(): Array[T]说明:在驱动程序中,以数组 Array 的形式返回数据集的所有元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 收集数据到 Driver
rdd.collect().foreach(println)3)count
def count(): Long说明:返回RDD中元素的个数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val countResult: Long = rdd.count()4)first
def first(): T说明:返回RDD中的第一个元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val firstResult: Int = rdd.first()
println(firstResult)5)take
def take(num: Int): Array[T]说明:返回一个由RDD的前n个元素组成的数组
vval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))6)takeOrdered
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]说明:返回该RDD排序后的前n个元素组成的数组
降序第二个参数,这里传【Ordering.Int.reverse】
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
// 返回 RDD 中元素的个数
val result: Array[Int] = rdd.takeOrdered(2)
// 返回 RDD 中元素,从大到小排序
val result: Array[Int] = rdd.takeOrdered(2)(Ordering.Int.reverse)
7)aggregate
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U说明:分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合。
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8)
// 将该 RDD 所有元素相加得到结果
//val result: Int = rdd.aggregate(0)(_ + _, _ + _)
val result: Int = rdd.aggregate(10)(_ + _, _ + _)——aggregate和aggregateByKey的区别
aggregateByKey:
初始值只会参与分区内计算
aggregate:
初始值会参与分区内计算,并且参与分区间计算
8)fold
def fold(zeroValue: T)(op: (T, T) => T): T说明:折叠操作,aggregate的简化版操作
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val foldResult: Int = rdd.fold(0)(_+_)9)countByKey
def countByKey(): Map[K, Long]说明:统计每种key的个数
val rdd = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2,"b"), (3, "c"), (3, "c")))
// 统计每种key的个数
val result = rdd.countByKey()
10)save相关算子
def saveAsTextFile(path: String): Unit
def saveAsObjectFile(path: String): Unit
def saveAsSequenceFile(
path: String,
codec: Option[Class[_ <: CompressionCodec]] = None): Unit说明:将数据保存到不同格式的文件中
// 保存成 Text 文件
rdd.saveAsTextFile("output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
// 保存成 Sequencefile 文件
rdd.map((_,1)).saveAsSequenceFile("output2")11)foreach
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}收集后打印:rdd.collect.foreachDriver端内存集合的循环遍历方法
分布式打印:rdd.foreachExecutor端内存数据打印
所以收集后打印(rdd.collect.foreach)输出有顺序,分布式打印(rdd.foreach)的输出没有顺序。
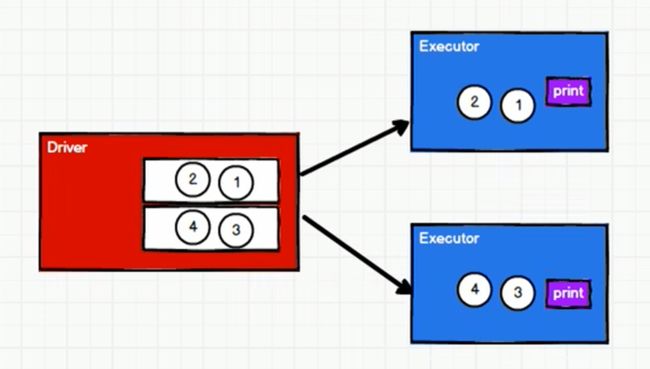
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 收集后打印
rdd.map(num=>num).collect().foreach(println)
// 分布式打印
rdd.foreach(println)
三、Scala集合的方法于RDD算子的区别
执行的方式不同:
集合对象的方法都是再同一个节点的内存中完成的
RDD的方法可以将计算逻辑发送到Executor端(分布式节点)执行
——RDD方法外部的操作都是在Driver端执行,而方法内部的逻辑代码实在Executor端执行。
因此,为了区分scala集合的方法和RDD的方法,将RDD的方法称为算子。