第六章 Cortex-A7 MPCore 架构学习
本章参考了《Cortex-A7 Technical ReferenceManua.pdf》和《ARM Cortex-A(armV7)编程手册 V4.0.pdf》这俩份文档,这两份文档都是 ARM 官方的文档,详细的介绍了 Cortex-A7 架构和ARMv7-A 指令集。
I.MX6ULL 使用的是 Cortex-A7 架构,本章学习 Cortex-A7 架构的一些基本知识。
6.1 Cortex-A7 MPCore 简介
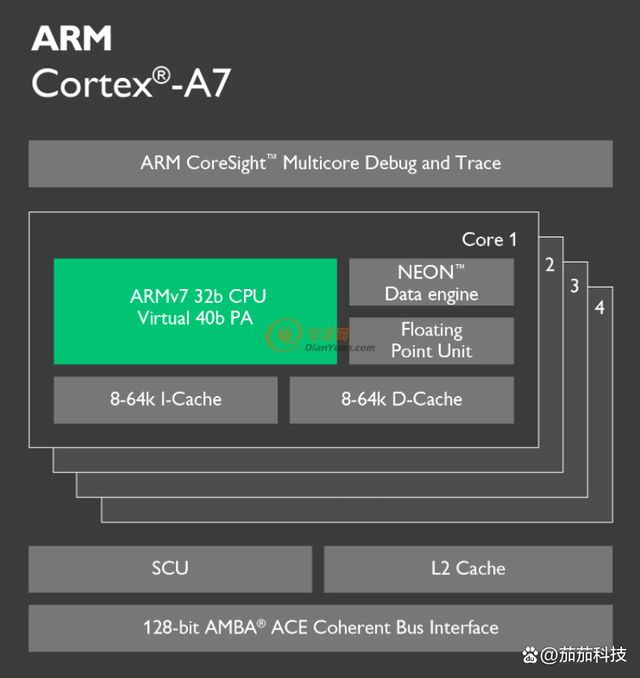
Cortex-A7 MPcore 处理器支持 1~4 核,通常是和 Cortex-A15 组成 big.LITTLE 架构的,Cortex-A15 作为大核负责高性能运算,比如玩游戏啥的, Cortex-A7 负责普通应用,因为 CortexA7 省电。 Cortex-A7 本身性能也不弱,不要看它叫做 Cortex-A7 但是它可是比 Cortex-A8 性能要强大,而且更省电。 ARM 官网对于 Cortex-A7 的说明如下:
“在 28nm 工艺下, Cortex-A7 可以运行在 1.2~1.6GHz,并且单核面积不大于 0.45mm2(含有浮点单元、 NEON 和 32KB 的 L1 缓存),在典型场景下功耗小于 100mW, 这使得它非常适
合对功耗要求严格的移动设备,这意味着 Cortex-A7 在获得与 Cortex-A9 相似性能的情况下,其功耗更低”。
Cortex-A7 MPCore 支持在一个处理器上选配 1~4 个内核, Cortex-A7 MPCore 多核配置如图6.1.1 所示:
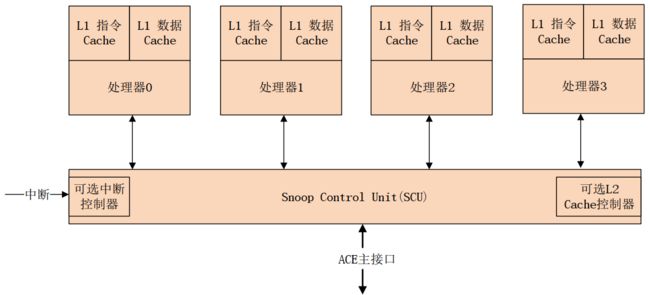
图 6.1.1 多核配置图
L1 可选择 8KB、 16KB、 32KB、 64KB;
L2 Cache 可以不配,也可以选择 128KB、 256KB、 512KB、 1024KB;
I.MX6ULL 配置了 32KB 的 L1 指令 Cache 和 32KB 的L1 数据 Cache,以及 128KB 的 L2 Cache。
下面和图6.11等价:
注:关于SCU(数据来源:https://www.cnblogs.com/zenny-chen/archive/2011/09/01/2162076.html)
SCU通过AXI接口将一至四个Cortex-A9处理器连接到存储器系统。
1、SCU功能是:
1)在Cortex-A9处理器之间维护数据Cache的一致性
2)初始化L2 AXI存储器访问
3)在请求L2访问的Cortex-A9处理器之间仲裁
4)管理ACP【译者注:加速器一致性端口】访问。
注:Cortex-A9 SCU不支持对指令Cache一致性的硬件管理。
2、AMBA[译者注:高级微控制器总线接口(Advanced Microcontroller Bus Interface)]AXI[译者注:高级可扩展接口(Advanced eXtensible Interface)]主机端接口
Cortex-A7MPCore 使用 ARMv7-A 架构,主要特性如下:
①、 SIMDv2 扩展整形和浮点向量操作。
②、提供了与 ARM VFPv4 体系结构兼容的高性能的单双精度浮点指令,支持全功能的
IEEE754。
③、支持大物理扩展(LPAE),最高可以访问 40 位存储地址,也就是最高可以支持 1TB 的
内存。
④、支持硬件虚拟化。
⑥、支持 Generic Interrupt Controller(GIC)V2.0。
⑦、支持 NEON,可以加速多媒体和信号处理算法。
6.2 Cortex-A 处理器运行模型

除了 User(USR)用户模式以外,其它 8 种运行模式都是特权模式。这几个运行模式可以通过软件进行任意切换,也可以通过中断或者异常来进行切换。用户模式是不能直接进行切换的,用户模式下需要借助异常来完成模式切换,当要切换模式的时候,应用程序可以产生异常,在异常的处理过程中完成处理器模式切换。
当中断或者异常发生以后,处理器就会进入到相应的异常模式种,每一种模式都有一组寄存器供异常处理程序使用,这样的目的是为了保证在进入异常模式以后,用户模式下的寄存器不会被破坏。
6.3 Cortex-A 寄存器组
注意:是Cortex-A 的内核寄存器组,注意不是芯片的外设寄存器。本节主要参考
《ARM Cortex-A(armV7)编程手册 V4.0.pdf》的“第 3 章 ARM Processor Modes And Registers”
ARM 架构提供了16 个 32 位的通用寄存器(R0~R15)供软件使用:
通用寄存器:R0~R14用作通用的数据存储, R15 是程序计数器 PC,用来保存将要执行的指令;
当前状态寄存器: CPSR
备份程序状态寄存器: SPSR,SPSR 寄存器就是 CPSR 寄存器的备份。
18 个寄存器如图 6.3.1 所示:
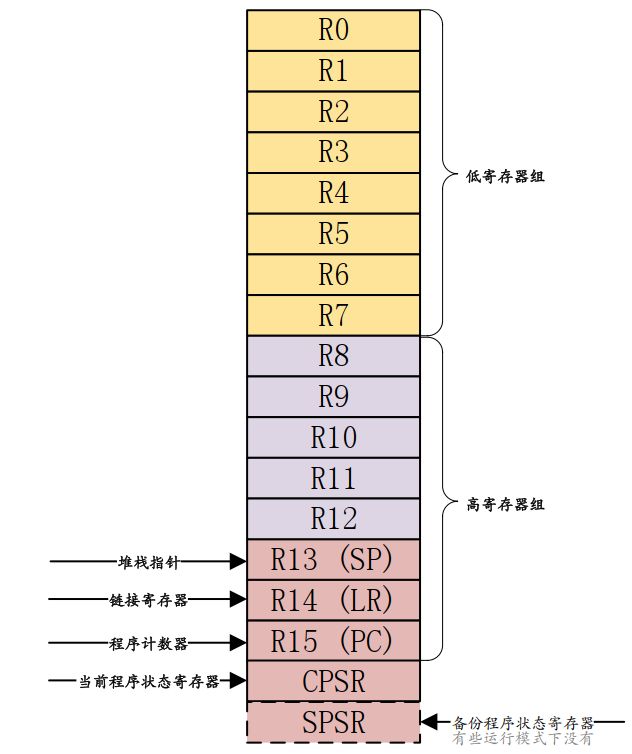
图 6.3.1 Cortex-A 寄存器

图 6.3.2 九种模式所对应的寄存器
上图说明:浅色字体的是与 User 模式所共有的寄存器,蓝绿色背景的是各个模式所独有的寄存器。
在所有的模式中,低寄存器组(R0~R7)是共享同一组物理寄存器的,只是一些高寄存器组在不同的模式有自己独有的寄存器。
总结一下, CortexA 内核寄存器组成如下(注意是9种模式一共):
①、 34 个通用寄存器,包括 R15 程序计数器(PC),这些寄存器都是 32 位的。
②、 8 个状态寄存器,包括 CPSR 和 SPSR。
③、 Hyp 模式下独有一个 ELR_Hyp 寄存器
6.3.1 通用寄存器
R0~R15 就是通用寄存器,通用寄存器可以分为以下三类:
①、 未备份寄存器,即 R0~R7。
②、 备份寄存器,即 R8~R14。
③、程序计数器 PC,即 R15。
分别来看一下这三类寄存器
1、未备份寄存器
所有的处理器模式下这 8 个寄存器都是同一个物理寄存器,在不同的模式下,这 8 个寄存器中的数据就会被破坏。所以这 8 个寄存器并没有被用作特殊用途。
2、备份寄存器
基本上每种模式都有一个自己的 R13 物理寄存器,应用程序会初始化 R13,使其指向该模式专用的栈地址,这就是常说的初始化 SP 指针。
R14 也称为连接寄存器(LR),LR 寄存器在 ARM 中主要用作如下两种用途:
①、每种处理器模式使用 R14(LR)来存放当前子程序的返回地址
MOV PC, LR @寄存器 LR 中的值赋值给 PC,实现跳转
或者可以在子函数的入口出将 LR 入栈:
PUSH {LR} @将 LR 寄存器压栈
在子函数的最后面出栈即可:
POP {PC} @将上面压栈的 LR 寄存器数据出栈给 PC 寄存器,严格意义上来讲应该是将
@LR-4 赋给 PC,因为3级流水线,这里只是演示代码②、当异常发生以后,该异常模式对应的 R14寄存器被设置成该异常模式将要返回的地址,R14 也可以当作普通寄存器使用。
3、程序计数器
程序计数器 R15 也叫做 PC,ARM 处理器 3 级流水线:取指->译码->执行,这三级流水线循环执行,
比如当前正在执行第一条指令(以此为参考点)的同时->也对第二条指令进行译码->第三条指令也同时被取出存放,对于 32 位的 ARM 处理器,每条指令是 4 个字节,所以:
R15 (PC)值 = 当前执行的程序位置 + 8 个字节
6.3.2 程序状态寄存器
所有的处理器模式都共用一个 CPSR 物理寄存器,因此 CPSR 可以在任何模式下被访问。CPSR 是当前程序状态寄存器,该寄存器包含了条件标志位、中断禁止位、当前处理器模式标志等一些状态位以及一些控制位。所有的处理器模式都共用一个 CPSR 必然会导致冲突,为此,除了 User 和 Sys 这两个模式以外,其他 7 个模式每个都配备了一个专用的物理状态寄存器,叫做 SPSR(备份程序状态寄存器),当特定的异常中断发生时, SPSR 寄存器用来保存当前程序状态寄存器(CPSR)的值,当异常退出以后可以用 SPSR 中保存的值来恢复 CPSR。因为 User 和 Sys 这两个模式不是异常模式,所以并没有配备 SPSR,因此不能在 User 和Sys 模式下访问 SPSR,会导致不可预知的结果。由于 SPSR 是 CPSR 的备份,因此 SPSR 和CPSR 的寄存器结构相同,如图 6.3.2.1 所示:

图 6.3.2.1 CPSR 寄存器
N(bit31):当两个补码表示的 有符号整数运算的时候, N=1 表示运算对的结果为负数, N=0表示结果为正数。
Z(bit30): Z=1 表示运算结果为零, Z=0 表示运算结果不为零,对于 CMP 指令, Z=1 表示进行比较的两个数大小相等。
C(bit29):在加法指令中,当结果产生了进位,则 C=1,表示无符号数运算发生上溢,其它情况下 C=0。在减法指令中,当运算中发生借位,则 C=0,表示无符号数运算发生下溢,其它
情况下 C=1。对于包含移位操作的非加/减法运算指令, C 中包含最后一次溢出的位的数值,对于其它非加/减运算指令, C 位的值通常不受影响。
V(bit28): 对于加/减法运算指令,当操作数和运算结果表示为二进制的补码表示的带符号数时, V=1 表示符号位溢出,通常其他位不影响 V 位。
Q(bit27): 仅 ARM v5TE_J 架构支持,表示饱和状态, Q=1 表示累积饱和, Q=0 表示累积不饱和。
IT[1:0](bit26:25): 和 IT[7:2](bit15:bit10)一起组成 IT[7:0],作为 IF-THEN 指令执行状态。
J(bit24): 仅 ARM_v5TE-J 架构支持, J=1 表示处于 Jazelle 状态,此位通常和 T(bit5)位一起表示当前所使用的指令集,如表 6.3.2.1 所示:

表 6.3.2.1 指令类型
GE[3:0](bit19:16): SIMD 指令有效,大于或等于。
IT[7:2](bit15:10): 参考 IT[1:0]。
E(bit9): 大小端控制位, E=1 表示大端模式, E=0 表示小端模式。
A(bit8): 禁止异步中断位, A=1 表示禁止异步中断。
I(bit7): I=1 禁止 IRQ, I=0 使能 IRQ。
F(bit6): F=1 禁止 FIQ, F=0 使能 FIQ。
T(bit5): 控制指令执行状态,表明本指令是 ARM 指令还是 Thumb 指令,通常和 J(bit24)一
起表明指令类型,参考 J(bit24)位。
M[4:0]: 处理器模式控制位,含义如表 6.3.2.2 所示:

表 6.3.2.2 处理器模式位