1 Greenplum架构学习讲解
Greenplum架构学习讲解
Greenplum架构学习讲解1、什么是Greenplum2、Greenplum 体系架构2.1 Greenplum Master2.2 Greenplum Segment2.3 网络配置示例3 Greenplum 高可用性体系架构3.1 Master/Standby 镜像保护3.2 数据冗余-Segment 镜像保护3.3 网络冗余4 Greenplum 应用场景5 数据分布5.1 数据库分布键分布数据策略5.11 HASH策略5.12 随机分布5.13 master主节点获取segment节点上的数据顺序
1、什么是Greenplum
Greenplum,该公司成立于2003年,2006年推出了首款产品,其主营业务关注在数据仓库和商业智能方面,Greenplum DW/BI软件可以在虚拟化x86服务器上运行无分享(shared-nothing)的大规模并行处理(MPP)架构 。
Greenplum是基于 PostgreSQL 8.2开发的,与PostgreSQL 8.2有相同的客户端功能(Pgadmin III支持Greenplum,但是PGadmin VI则不能连接到Greenplum),在PostgreSQL 8.2上增加支持并行处理的技术,增加支持数据仓库和BI的特性,外部表(external tables)/并行加载(parallel loading),资源管理,查询优化器增强(query optimizer enhancements)
Greenplum(以下简称GPDB)是一款开源数据仓库,基于开源的PostgreSQL改造而来,主要用来处理大规模数据分析任务。相比Hadoop,Greenplum更适合做大数据的存储、计算和分析引擎。
GPDB是典型的Master/Slave架构,在Greenplum集群中,存在一个Master节点和多个Segment节点,每个节点上可以运行多个数据库。Greenplum采用shared nothing架构(MPP),典型的Shared Nothing系统汇集了数据库、内存Cache等存储状态的信息,不在节点上保存状态的信息。节点之间的信息交互都是通过节点互联网络实现的。通过将数据分布到多个节点上来实现规模数据的存储,再通过并行查询处理来提高查询性能。每个节点仅查询自己的数据,所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
2、Greenplum 体系架构
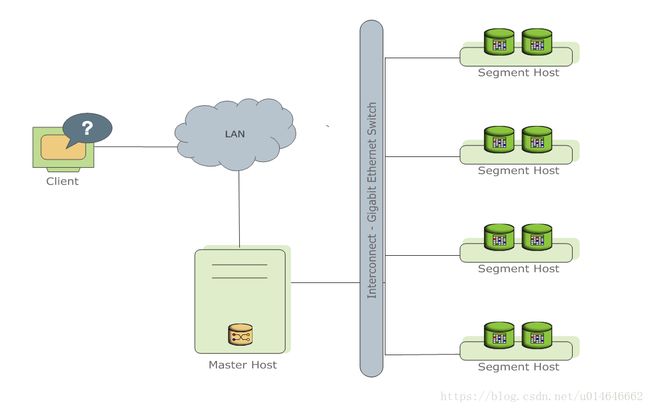
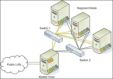
图1 GPDB的基本架构 图1为GPDB的基本架构,客户端通过网络连接到gpdb,其中Master Host是GP的主节点(客户端的接入点),Segment Host是子节点(连接并提交SQL语句的接口),主节点不存储用户数据,子节点存储数据并负责SQL查询,主节点负责相应客户端请求并将请求的SQL语句进行转换,转换之后调度后台的子节点进行查询,并将查询结果返回客户端。
2.1 Greenplum Master
Master只存储系统元数据,业务数据全部分布在Segments上。其作为整个数据库系统的入口,负责建立与客户端的连接,SQL的解析并形成执行计划,分发任务给Segment实例,并且收集Segment的执行结果。正因为Master不负责计算,所以Master不会成为系统的瓶颈。
Master节点的高可用类似Hadoop的NameNode HA,如图2,Standby Master通过synchronization process,保持与Primary Master的catalog和事务日志一致,当Primary Master出现故障时,Standby Master承担Master的全部工作。
主节点Master host的主要功能
访问系统的入口 数据库侦听进程 (postgres) 处理所有用户连接 建立查询计划 协调工作处理过程 管理工具 系统目录表和元数据(数据字典) 不存放任何用户数据 数据节点Segment host的主要功能
2.2 Greenplum Segment
Greenplum中可以存在多个Segment,Segment主要负责业务数据的存储和存取(图3),用户查询SQL的执行时,每个Segment会存放一部分用户数据,但是用户不能直接访问Segment,所有对Segment的访问都必须经过Master。进行数据访问时,所有的Segment先并行处理与自己有关的数据,如果需要关联处理其他Segment上的数据,Segment可以通过Interconnect进行数据的传输。Segment节点越多,数据就会打的越散,处理速度就越快。因此与Share All数据库集群不同,通过增加Segment节点服务器的数量,Greenplum的性能会成线性增长。

图3 Segment负责业务数据的存取 每个Segment的数据冗余存放在另一个Segment上,数据实时同步,当Primary Segment失效时,Mirror Segment将自动提供服务。当Primary Segment恢复正常后,可以很方便地使用gprecoverseg -F工具来同步数据。
2.3 网络配置示例
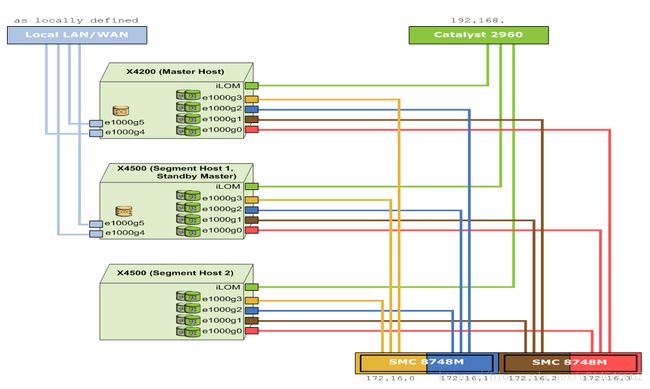
第一块是Master host 用于客户端的访问
第二块即使Standby host,也是Segment host的节点,当Master host 节点出现故障时,Standby host可以切换为Master host,以接受用户的访问,如果是生产环境,建议分开
第三块时Segment host 主要用于数据存储和计算
3 Greenplum 高可用性体系架构
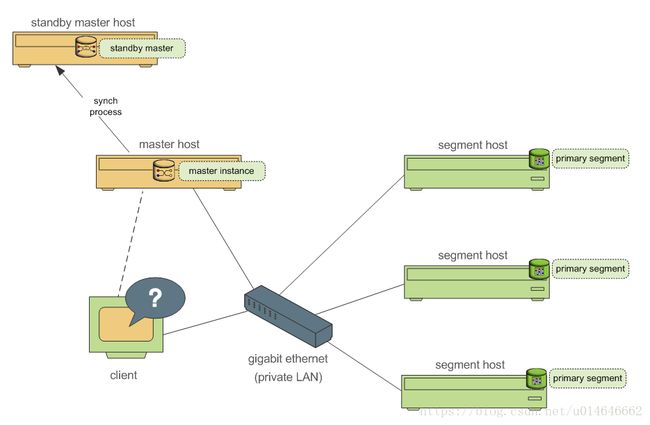
Standby 节点用于当 Master 节点损坏时提供 Master 服务 Standby 实时与 Master 节点的 Catalog 和事务日志保持同步 每个Segment的数据冗余存放在另一个Segment上,数据实时同步 当Primary Segment失败时,Mirror Segment将自动提供服务 Primary Segment恢复正常后,使用gprecoverseg –F 同步数据。
3.1 Master/Standby 镜像保护

-
Standby 节点用于当 Master 节点损坏时提供 Master 服务
-
Standby 实时与 Master 节点的 Catalog 和事务日志保持同步
3.2 数据冗余-Segment 镜像保护
-
每个 Segment 的数据冗余存放在另一个 Segment 上,数据实时同步
-
当 Primary Segment 失败时,Mirror Segment 将自动提供服务
-
Primary Segment 恢复正常后,使用 gprecoverseg –F 同步数据。
Segment 主机硬件配置示例

3.3 网络冗余
4 Greenplum 应用场景
Greenplum数据引擎是为新一代数据仓库和大规模分析处理而建立的软件解决方案,其最大的特点是不需要高端的硬件支持仍然可以支撑大规模的高性能数据仓库和商业智能査询。在数据仓库、商业智能的应用上,尤其在海量数据的处理方面Greenplum表现出极其优异的性能。
传统数据库侧重交易处理,关注的是多用户的同时的双向操作,在保障即时性的要求下,系统通过内存来处理数据的分配、读写等操作,存在IO瓶颈。而分析型数据库是以实时多维分析技术作为基础,对数据进行多角度的模拟和归纳,从而得出数据中所包含的信息和知识。Greenplum虽然是关系型数据库产品,但是它具有査询速度快、数据装载速度快、 批量DML处理快的主要特点,而且性能可以随着硬件的添加呈线性增加,拥有非常良好的可扩展性。因此,Greenplum主要适用于面向分析的应用,比如构建企业级ODS/EDW、数据集市等。
5 数据分布
5.1 数据库分布键分布数据策略
由于greenplum数据库是个分布式数据库,数据分布在每一个segment节点上,其中数据的分布策略有两种分别是hash分布于随机分布。
5.11 HASH策略
Hash分布是利用Distributed by (filed1,filed2....) 做为数据分布的条件,计算hash值,并通过hash值路由到制定的segment上,如果不指定分布键,默认的是获取第一个字段作为分布键。在字段作为分布键时,该字段的值尽量是唯一的,这样才能分布的均匀,效率会更高,否则会降低数据库的想能。
5.12 随机分布
随机分布也叫平均分布。数据会随机的落在每一个segment节点上,不管数据内容是什么格式都会落到segment上,在SQL查询数据,数据会重新分布,性能会比较差,随机分布的用法为Distributed randomly;
5.13 master主节点获取segment节点上的数据顺序
Master在执行sql语句时由于数据切分放在每个segment上,master获取结果的顺序是segment提交的顺序,segment提交到master的顺序是随机的,就会导致一样的数据每次的查询结果顺序不一致,这也是与其他的数据不一样的地方。