k8s总结
k8s
最近学到k8s总结一下
文章目录
- k8s
-
- 1. 概述
- 2. 使用kubeadm方式搭建集群
-
- 2.1 实现步骤
- 2.2 快速构建
-
- 1. 部署k8s master
- 2. 加入k8s node
- 3. 部署CNI网络插件
- 2.3 测试
- 3. k8s核心技术
-
- 3.1 kubectl
- 3.2 pod
-
- 1. 基本概念
- 2. pod存在的意义
- 3. pod实现机制
- 4. pod镜像拉取策略(imagePullPolicy)
- 5. pod资源限制
- 6. pod重启机制(restartPolicy)
- 7. pod健康检查
- 8. pod调度
- 9. 创造pod的流程
- 10 污点和污点容忍(Taint)
- 3.3 controller
-
- 1. 简介
- 2. 使用deployment部署应用(yaml)
- 3. 应用升级和弹性伸缩
- 4. 部署有状态应用
- 5. 一次性任务(job)
- 6. 定时任务(cronjob)
- 3.4 service
-
- 1. service存在的意义
- 2. pod和service的关系
- 3.常用的service的类型
- 3.5 Secret
- 3.6 ConfigMap
- 3.7 k8s集群安全机制
-
- 1. 概述
- 2. 步骤
- 3.8 Ingress
- 3.9 Helm
- 3.10 持久存储
- 3. 搭建高集群
- 4. 实战
1. 概述
-
k8s是谷歌在2014年开源的容器化集群管理系统
-
使用k8s进行容器化应用管理
-
使用k8s利于应用扩展
-
k8s让部署容器化应用更加简介和高效
-
k8s集群架构组件
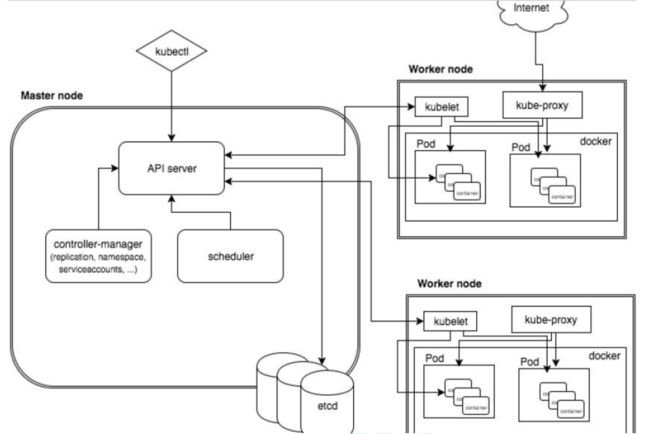
-
master 组件
- apiserver – 集群统一入口,以resful方式,交给etcd存储
- scheduler – 节点调度,选择node节点应用部署
- controller-manager – 处理集群中常规后台任务,一个资源对应一个控制器
-
worker node 组件
- kubelet – master派到node节点的代表,管理本机容器
- kube-proxy – 提供网络代理,负载均衡等操作
2. 使用kubeadm方式搭建集群
2.1 实现步骤
总结一下:
- 准备环境
- 安装docker、kubelet、kubeadm-1.18.0 kubectl
- 部署k8s master
- 加入k8s node
- 部署CNI网络插件
- 测试k8s集群
2.2 快速构建
1. 部署k8s master
在192.168.31.61(Master)执行。
$ kubeadm init \
--apiserver-advertise-address=192.168.44.146 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.18.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址。
使用kubectl工具:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ kubectl get nodes
2. 加入k8s node
在node节点执行。
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
$ kubeadm join 192.168.1.11:6443 --token esce21.q6hetwm8si29qxwn \
--discovery-token-ca-cert-hash sha256:00603a05805807501d7181c3d60b478788408cfe6cedefedb1f97569708be9c5
默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,操作如下:
kubeadm token create --print-join-command
3. 部署CNI网络插件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
默认镜像地址无法访问,sed命令修改为docker hub镜像仓库。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl get pods -n kube-system # 查看节点
2.3 测试
在Kubernetes集群中创建一个pod,验证是否正常运行:
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
3. k8s核心技术
3.1 kubectl
-
k8s集群命令行工具 - kubectl
-
语法格式
kubectl [name] [TYPE] [NAME] [flags] -
目前使用到的命令
# 常见一个应用nginx
kubectl create deployment nginx --image=nginx
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看节点与端口
kubectl get pod,svc

3.2 pod
1. 基本概念
-
最小的部署单元
-
包含多个容器(一组容器的集合)
-
一个pod中容器共享网络命名空间
-
pod是短暂的
2. pod存在的意义
- 一个docker对应一个容器,一个容器有进程,一个容器运行一个应用程序
- pod是多进程,可以运行多个应用程序(一个pod有多个容器,一个容器运行一个应用程序)
- pod存在为了亲密性应用
- 两个应用之间进行交互
- 网络之间调用
- 两个应用需要频繁调用(例如读写操作)
3. pod实现机制
共享网络,共享存储
-
共享网络
docker容器之间是相互隔离的,但是通过pause容器,把其他业务容器加入到pause容器里面,让所有的业务容器在用一个名称空间中,从而实现网络共享。

-
共享存储
引入数据卷概念volumn,使用数据卷进行持久化存储
4. pod镜像拉取策略(imagePullPolicy)
imagePullPolicy
- IfNotPresent:默认值,镜像在宿主机上不存在时才拉取;
- Always:每次创建pod都会重新拉取一次镜像;
- Never:pod永远不会主动拉取这个镜像
5. pod资源限制
yaml代码段分析
resources:
requests:
memory:"64M"
cpu:"250M"
limits:
memory:"128M"
cpu:"500M"
- requests - 调度
- limits - 最大
6. pod重启机制(restartPolicy)
restartPolicy
- Always: 当容器终止退出后,总是重启容器,默认策略;
- OnFailure: 当容器异常退出后(退出状态码为非0)时,才重启容器;
- Never: 当容器终止退出,从不重启容器
7. pod健康检查
分析一段代码:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: docker.io/alpine
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy;
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
本例创建了一个容器,通过检查一个文件是否存在来判断容器运行是否正常。容器运行30秒后,将文件删除,这样容器的liveness检查失败从而会将容器重启。
- 两种检查
# LivenessProbe(存活检查)
如果检查失败,将杀死容器,根据pod的restartPolicy来操作。
# readinessProbe(就绪检查)
如果检查失败,k8s会把pod从service endpoints中剔除。
- Probe支持以下三种检查方法
# httpGet
发送http请求,返回200-400范围状态码为成功;
# exec
执行shell命令返回状态码是0为成功;
# tcpSocket
发送Tcp Socket建立成功。
8. pod调度
影响调用的属性:1. pod资源的限制 2. 节点选择器标签影响pod调度
- 节点选择器(nodeSelector)
首先对节点创建标签
kubectl label node k8snode1 env_role=dev
具体体现在代码中:
spec:
nodeSelector:
env_role:dev # 根据不同的环境选择不同的节点node
containers:
-name:nginx
image:nginx1.15
- 节点亲和性(nodeAffinity)
NodeAffinity意为Node节点亲和性的调度策略,是用于替换NodeSelector的全新调度策略
- 硬亲和性(约束条件必须满足) – `requiredDuringSchedulinglgnoredDuringExecution
- 软亲和性(尝试满足,不保证)-- preferredDuringSchedulinglgnoredDuringExecution`
9. 创造pod的流程

-
master节点
创建pod --> apiserver(集群的统一入口) --> 交给etcd
scheduler(节点调度)时刻监控 --> apiserver --> etcd -->调度算法,把pod调度到某个node节点上
-
node节点
kubelet(master派到node节点的代表,管理本机容器)时刻监控 --> apiserver --> 读取etcd,分配给当前节点pod --> docker创建容器
10 污点和污点容忍(Taint)
-
nodeSelector 和 nodeAffinity:pod调度到某些节点上,调度时候实现
-
Taint污点:节点不做普通分配调度,是节点属性
-
查看节点污点情况
kubectl describe node k8smaster | grep Taint
# 污点值有三个
1. NoSchedule:一定不被调度
2. PreferNoSchedule:尽量不被调度
3. NoExecute:不会被调度,并且还会驱逐Node已有Pod
- 为节点添加污点
kubectl taint node [node] key=value:污点三个值
- 删除污点
kubectl taint K8snode1 env_role:NoSchedule-
3.3 controller
在集群上管理和运行容器的对象
1. 简介
- pod和controller的关系
- pod是通过controller实现应用的运维,比如伸缩,滚动升级;
- pod和controller之间通过label标签建立关系;
- deployment应用场景
- 部署无状态应用
- 管理pod和Replicaset
- 部署、滚动升级等功能(应用场景:web服务、微服务)
2. 使用deployment部署应用(yaml)
- 第一步:导出yaml文件
kubectl create deployment web --image=mginx --dry-run -o yaml >web.yaml
- 第二步:使用yaml部署应用
kubectl apply -f web.yaml
- 第三步:对外发布,暴露端口号
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web1 -o yaml > web1.yaml
kubectl apply -f web1.yaml
3. 应用升级和弹性伸缩
把nginx1.14升级成nginx1.15
- 应用升级
kubectl set image deployment web nginx=nginx1.15
- 查看升级状态
kubectl rollout status deployment web
- 查看升级版本
kubectl rollout history deployment web
- 回滚到指定的版本
kubectl rollout undo deployment web --to-revision=2
- 回滚到上一个版本
kubectl rollout undo deployment web
- 弹性伸缩
kubectl scale deployment web --replicas=10
4. 部署有状态应用
- 无状态应用和有状态应用的区别?
- 无状态
- 认为pod都是一样的
- 没有顺序的要求
- 不用考虑在哪个node上运行
- 随意进行伸缩和扩展
- 有状态
- 同无状态一样
- 让每个pod独立的,保持pod启动顺序和唯一性
- 唯一的网络标识符,持久存储
- 有序(比如mysql主从)
- 部署有状态的应用
无头service(ClusterIP:None)
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
SatefulSet部署有状态应用
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: default
- deployment和statefuset的区别
有身份的(唯一标识)
根据主机名+按照一定规则生成域名
格式:主机名称.service名称.名称空间.svc.cluster.local
5. 一次性任务(job)
apiVersion: batch/v1
kind: Job
metadata:
name: pi
6. 定时任务(cronjob)
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" # 定时一分钟
3.4 service
1. service存在的意义
- 防止pod失联(类似于注册中心的作用)
- 定义一组pod访问策略(负载均衡)
2. pod和service的关系
- pod和service根据label和selector标签建立关联
- 通过service实现pod的负载均衡
3.常用的service的类型
# ClusterIP - 集群内部使用
# NodePort - 对外访问应用使用
# LoadBalancer - 对外访问应用时使用,公有云
3.5 Secret
-
作用:加密数据存在etcd里面,让pod容器以挂载Volume方式进行访问
-
场景:凭证
-
形式:base64编码
步骤:
- 创建secret加密数据
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
- 以变量形式挂载到pod容器中
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
- 以Volume形式挂载pod容器中
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
3.6 ConfigMap
- 作用:存储不加密数据到etcd,让pod以变量或者Volume挂载到容器中
- 场景:配置文件
步骤:
- 创建配置文件
redis.host=127.0.0.1
redis.port=6379
redis.password=123456
- 创建ConfigMap
kubectl create configmap redis-config --from-file=redis.peoperties
kubectl get cm
kubectl describe cm redis-config
-
以Volume挂载到pod容器中
-
以变量形式挂载到pod容器中
创建yaml,声明变量信息configmap创建
以变量挂载
3.7 k8s集群安全机制
1. 概述
- 在访问k8s集群的时候,需要经过三个步骤(认证、授权、准入控制)
- 进行访问控制的时候,都需要经过apiserver,apiserver做统一协调,比如门卫(访问过程中需要证书、token、或者用户名+密码;如果访问pod,需要serviceAccount)
2. 步骤
- 认证
- 传输安全—对外不暴露8080端口,只能内部访问,对外使用端口6443
- 认证
# 客户端身份常用方式
- https证书认证。基于认证
- http token认证,通过token识别用户
- http基本认证,用户名+密码认证
- 授权
- 基于RBAC进行鉴权操作(基于角色访问控制)
角色 -- 角色绑定 -- 主体 # 特定的角色执行特定的访问
# 步骤
1. 创建命名空间
2. 在新创建的命名空间创建pod
3. 创建角色
4. 创建角色绑定
5. 使用证书识别身份
- 准入控制
- 就是准入控制器的列表
- 如果列表有请求内容,通过,没有拒绝
3.8 Ingress
- 把端口号对外暴露,通过ip+端口号进行访问(使用 service 里面的NodePort实现)
- 上述的做法有缺陷
# 缺陷
1. 在每个节点都会启动端口,在访问的时候通过任何节点,通过节点ip+端口号实现访问;
2. 意味着每个端口只能使用一次,一个端口只能对应一个应用;
3. 实际访问中都是用域名,根据不同域名跳转到不同的端口服务中。
- Ingress和Pod的关系(重要)
1. pod和ingress通过service关联
2. ingress作为统一的入口,由service关联一组pod
- 步骤(使用ingress对外暴露端口)
1. 创建nginx应用,对外暴露端口使用Nodeport
2. 部署ingress controller
3. 创建ingress访问规则
4. 在windows系统host文件中添加域名访问规则
3.9 Helm
之前方式部署单一应用,少数服务的应用,比较合适
但是部署微服务项目,可能有十几个服务,每个服务都有一套yaml文件,需要维护大量的yaml文件,版本管理特别不方便
- 使用helm可以解决哪些问题?
- 使用helm可以把这么yaml文件作为一个整理管理
- 实现yaml高效复用
- 使用helm应用级别的版本管理
- 概述
helm是k8s的包管理工具,类似于linux下的包管理器(yum)
可以方便的将之前打包好的yaml文件部署到k8s上
- 三个重要概念
- heml - 一个命令行客户端工具
- Chart - 把yaml打包,是yaml集合
- Release - 基于chart部署实体,应用级别的版本管理
3.10 持久存储
-
之前数据卷 emptydir 是本地存储,pod重启后,数据就不存在了,所以需要数据持久化存储
-
nfs网络存储,pod重启,数据还存在的
3. 搭建高集群
- 之前一直搭建的集群是单master节点
- 单master节点存在这样的弊端:当master宕机后,集群就无法正常的运行
- 这里尝试搭建多master节点
(18条消息) 使用kubeadm搭建高可用的k8s集群_Kc635908933的博客-CSDN博客
- 单master和多master节点的区别
- 所有节点都需要部署keepalived、haproxy;
- 多master节点和node节点之间存在着一个 load balancer(时刻检查master节点的状态,如果master1出错,就运行master2);
- 正式访问的时候通过 VIP(虚拟ip)进行访问
- 测试
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
4. 实战
在k8s集群中部署Java项目
学到现在总结一下
- 容器交付流程
- 开发代码阶段(编写代码、测试、编写dockerfile)
- 持续交付/集成(代码编译打包、制作镜像、上传镜像库)
- 应用部署(环境准备、pod、service、ingress)
- 运维(监控、故障排除、升级优化)
- k8s部署项目流程
- 制作镜像(dockerfile)
- 推送镜像仓库(Harbor)
- 控制器部署镜像(Deployment)
- 对外暴露应用(Service、Ingress)
- 运维(监控、升级)