Elastic stack 技术栈学习(七)—— kibana中索引的基本操作(创建、删除、更新、查看)以及文档的基本操作
目录
一、Restful风格
二、关于索引的基本操作
1. 创建
(1)创建索引
(2)创建索引规则
2.GET获取信息
(1)获得索引信息
(2)获得文档信息
(3)补充常用命令 GET _cat/... 获取es集群的信息
3. 使用POST命令更新文档
4. 删除
(1)删除索引
(2)删除索引中的某个文档
三、关于文档的基本操作
1、PUT/POST创建文档
2、GET获取文档
3、POST更新文档
4、简单的搜索
(1) 在索引中根据关键字搜索文档
5、复杂搜索
(1)模糊查询
(2)过滤不想看的字段
(3)排序
(4)分页查询
(5)布尔值bool查询
(6)模糊查询的多条件查询
(7)term精确查询
(8)精确查询的多条件查询
(9)高亮查询 及 自定义高亮样式
一、Restful风格

在kibana的创建索引、修改索引、删除索引等操作时,要严格遵循上面url地址的各个字段。
二、关于索引的基本操作
1. 创建
(1)创建索引
找到Dev tool(开发工具),左栏就是发送JSON格式的命令的,点击绿色的三角形发送命令,右栏是返回结果。

PS:对于kibana7.0以后的版本,索引的type字段被省略掉了,或者说默认是_doc类型。上面的命令可以改成
POST /test1/zxf
POST /test1/_doc/zxf然后,在head里查看一下

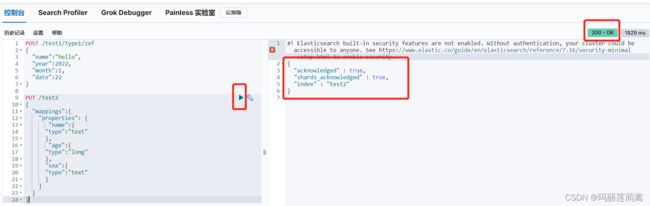
(2)创建索引规则
PUT /test2
{
"mappings":{
"properties": {
"name":{
"type":"text"
},
"age":{
"type":"long"
},
"sex":{
"type":"text"
}
}
}
}
在head里查看一下,test2这个索引里没有文档,是空的。
2.GET获取信息
(1)获得索引信息
获取索引信息,我们在创建test1时没有指明文档内各个字段的类型,创建test2时,通过规则指定了文档内各个字段的类型(long,text,text)。分别获取看一下区别。
① test2:创建时指定了各个字段的类型。自然返回的结果和我们在上文规定的一样。
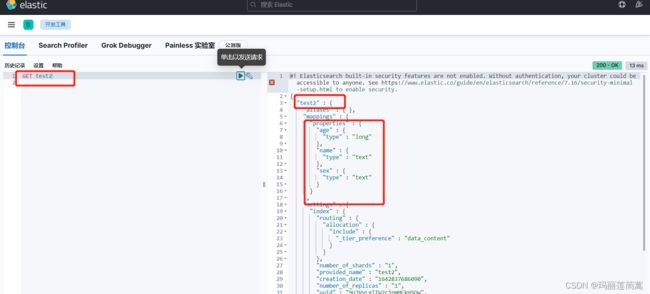
② test1:创建时没有指明各个字段的类型。从返回的结果可以看出,es默认识别出并赋予了"name""year"等字段的类型
(2)获得文档信息
GET不仅可以获取索引信息,还可以具体到索引中每个文档的信息。
这里的文档类型type1写成_doc就行。

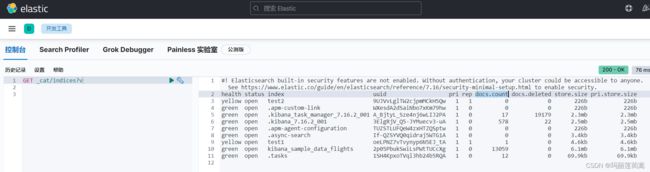
(3)补充常用命令 GET _cat/... 获取es集群的信息
查看集群的健康值:
GET _cat/health
查看es包含的所有索引的信息:
GET _cat/indices?v
 3. 使用POST命令更新文档
3. 使用POST命令更新文档
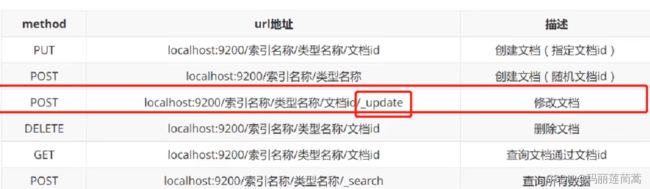
POST test1/_doc/zxf/_update
{
"doc":{
"name":"修改后的name"
}
}提交后,返回的结果可以看出修改成功。
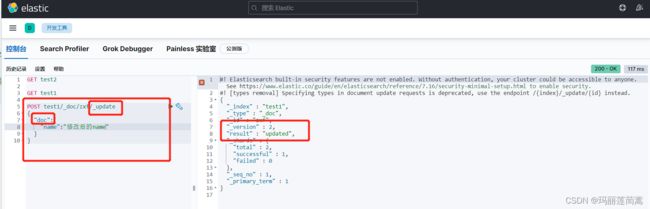 然后去head里面确认一下
然后去head里面确认一下

4. 删除
(1)删除索引
DELETE test2
回到head确认一下,test2这个索引不在了。
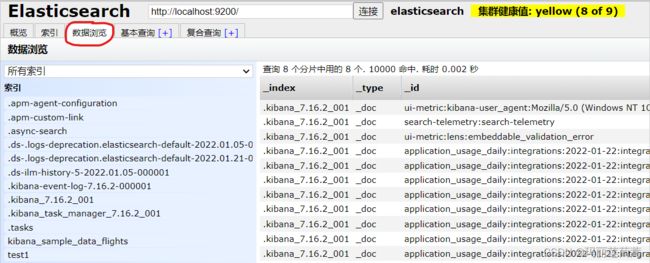
当然,除了在kibana中通过发送json命令的形式删除索引,在head中也可以手动删除,操作如下
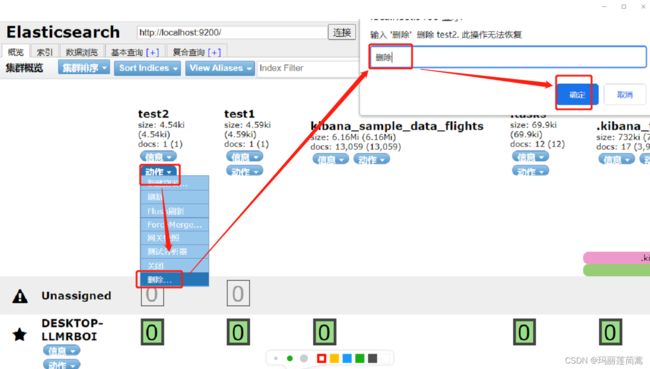
(2)删除索引中的某个文档
DELETE test1/_doc/zxf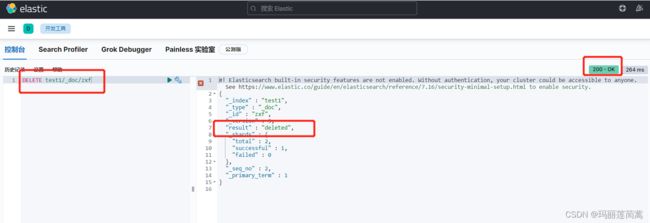
回到head确认一下,文档没有了

三、关于文档的基本操作
1、PUT/POST创建文档
前面创建索引的时候已经顺便讲过了如何创建文档,比如
PUT test1/_doc/zxf
{
"name":"zxf",
"year":2022,
"month":1,
"date":25
}
PUT test1/_doc/wanna_sleep
{
"name":"wanna sleep",
"year":2022,
"month":1,
"date":25
}
2、GET获取文档
GET test1/_doc/morning
3、POST更新文档
同上文,
POST test1/_doc/zxf/_update
{
"doc":{
"name":"修改后的name"
}
}4、简单的搜索
(1) 在索引中根据关键字搜索文档
# 搜索类型为type1的索引test1中,name字段值为zxf的文档
GET test1/type1/_search?q=name:zxf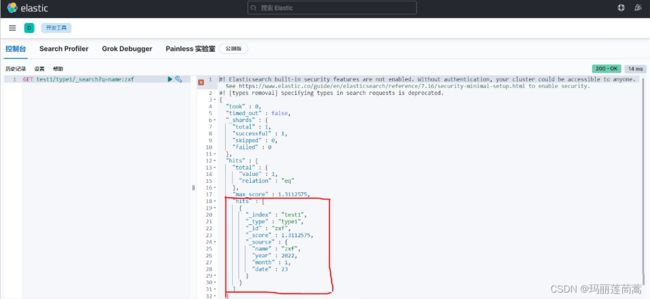
# 搜索类型为type1的索引test1中,year字段值为2022的文档
GET test1/type1/_search?q=year:2022
这里存在一个问题, 如果没有给es安装分析器插件的话,就不能实现部分匹配,比如说通过name字段搜索,必须在命令中给出完整name才能匹配到。 为了实现部分匹配,我决定安装一个分词器。
elastic stack技术栈学习(八)—— 安装elasticsearch IK分词器(一个插件)_玛丽莲茼蒿的博客-CSDN博客
安装完毕后可以实现部分匹配了。 
需要注意的是,部分匹配是根据字典进行拆分的,默认的英文字典有一些“呆板”,还无法实现像百度、谷歌那样的部分匹配。比如上面的查询我不用wanna,而是只输入wann,是查不到的,除非手动将wann加入字典。
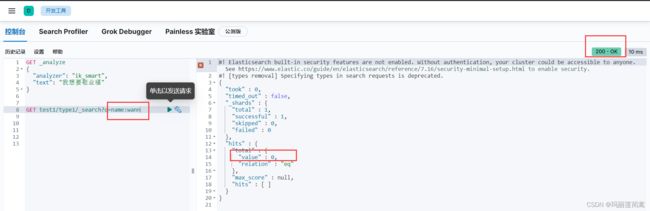
我又添加了如下两个中文name字段用来测试分词器。
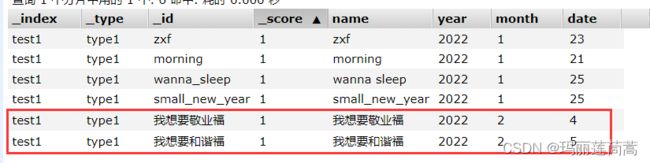

通过匹配的结果可以看出来,分词器既拆分了我们输入的关键字,也拆分了被查询的name字段。
5、复杂搜索
(1)模糊查询
和MySQL一样,es使用query进行查询。elastic stack提供了很多匹配方式的API。
match是模糊查询:输入“敬业福”,相当于SQL语句的 WHERE name LIKE '%敬业福%' OR LIKE '%敬业%' OR LIKE '敬' OR LIKE '业' OR LIKE '业'(和SQL不同的是,es的模糊查询会分词)
term是精确查询:输入“我想要敬业福”,相当于SQL语句的 WHERE name = '我想要敬业福'

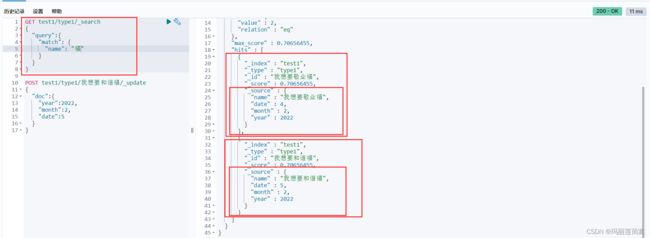
我们先采用match模糊查询方式去匹配:
GET test1/type1/_search
{
"query":{
"match": {
"name": "福"
}
}
}
(2)过滤不想看的字段
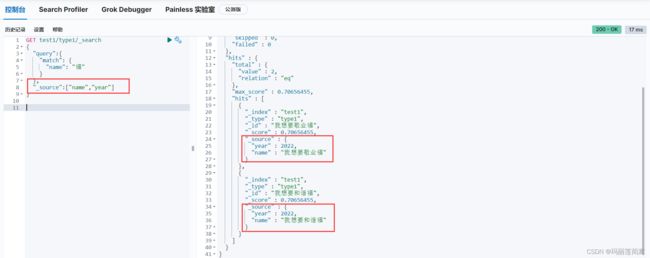
如果我们只想看查询结果的name字段和year字段,不想看其他month、date字段,可以使用过滤器。
GET test1/type1/_search
{
"query":{
"match": {
"name": "福"
}
},
"_source":["name","year"]
}
(3)排序
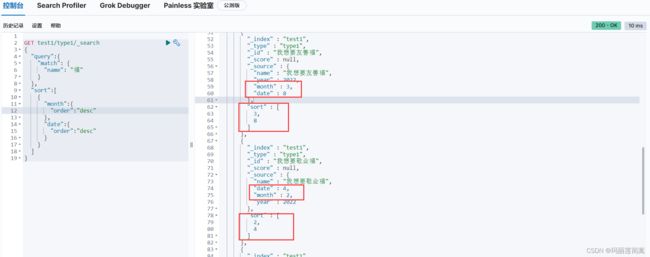
为了测试,索引test1的文档更改如下:

实现先按照月份再按照日期的倒序排序:
GET test1/type1/_search
{
"query":{
"match": {
"name": "福"
}
},
"sort":[
{
"month":{
"order":"desc" # 升序是"asc"
},
"date":{
"order":"desc"
}
}
]
}
(4)分页查询
下面是百度的分页:

GET test1/type1/_search
{
"query":{
"match": {
"name": "福"
}
},
"_source":["name","month"],
"sort":[
{
"month":{
"order":"desc"
}
}
],
"from":0,
"size":3
}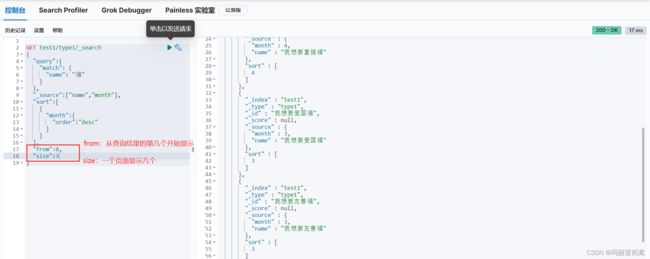
注意,返回的查询结果下标从0开始。
(5)布尔值bool查询
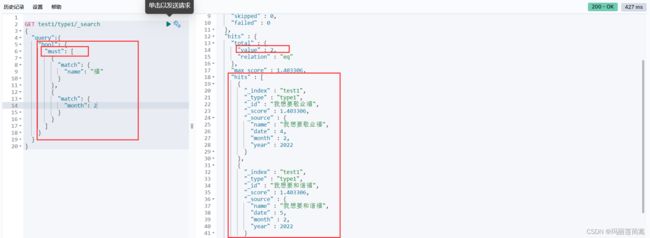
1) must关键字:实现的是“逻辑与” AND
2) should关键字:实现的是“逻辑或”OR

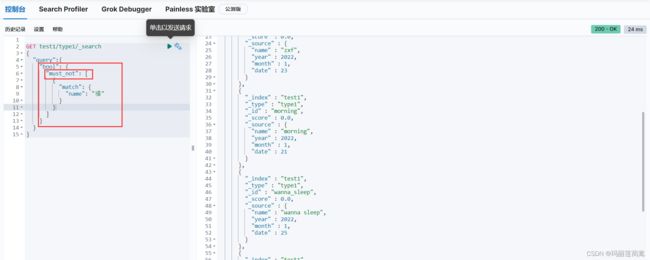
3) must_not关键字:实现的是“逻辑非”NOT,name字段不带“福”字的文档被查询出来了。
4)过滤器
GET test1/type1/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "福"
}
}
],
"filter": [
{
"range": {
"month": {
"gte": 3,
"lte": 4
}
}
}
]
}
}
}
(6)模糊查询的多条件查询
多个条件直接用“空格”隔开,这一点比MySQL数据库查询方便得多。
GET test1/type1/_search
{
"query":{
"match": {
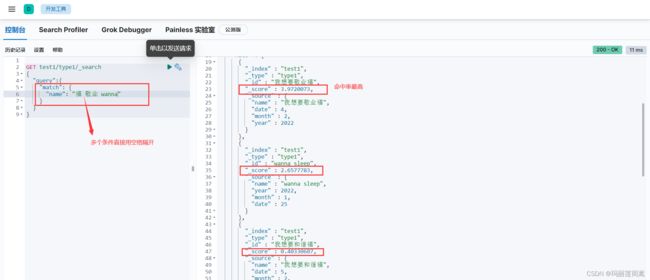
"name": "福 敬业 wanna"
}
}
}
(7)term精确查询
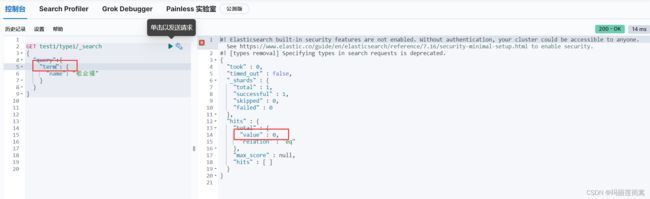
先看模糊查询的结果

精确查询,没查到。必须要输入完整的“我想要敬业福”才能匹配到(相当于SQL中的 WHERE name = '我想要敬业福')
(8)精确查询的多条件查询
模糊查询的多条件查询直接用“空格”隔开就行了,但是精确查询不能直接用空格隔开。
GET test1/type1/_search
{
"query":{
"bool": {
"must": [
{
"term": {
"month": 4
}
},
{
"term": {
"date": 1
}
}
]
}
}
}

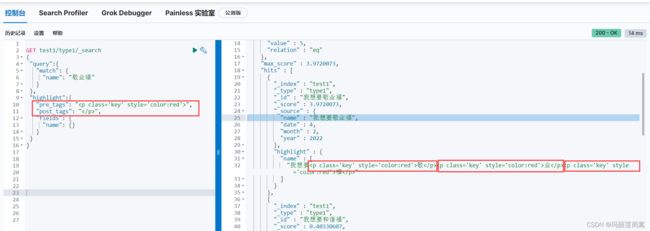
(9)高亮查询 及 自定义高亮样式

通过增加前标签和后标签自定义高亮的颜色等样式:
GET test1/type1/_search
{
"query":{
"match": {
"name": "敬业福"
}
},
"highlight":{
"pre_tags": "",
"post_tags": "
",
"fields": {
"name": {}
}
}
}