CHAPTER4 Numpy基础:数组与向量化计算(Arrays and Vectories)
1、背景介绍(introduction)
在数值计算领域,说Numpy是python最重要的包也不为过。在numpy中有下面这些东西: nadarry,一种高效多维数组,提供了基于数组的便捷算术操作及灵活的广播功能。(broadcasting) 便利的数组函数 用于读取/写入(reading/writing)数据到磁盘的便利工具 线性代数,随机生成,傅里叶变换能力 可以用CAPI来写C,C++,或FORTRAN 通过学习理解numpy中数组和数组的导向计算,能帮我们理解pandas之类的工具。
2、方法及数据(methonds and data)
2.1The Numpy ndarray: A Multidimensional Array Object(nadarry:多维数组对象)
N-dimensisonal array object(n维数组对象),or ndarray,这是numpy的关键特征。先来尝试一下,生成一个随机数组:
In [6]:
import numpy as np
In [4]:
# Generate some random data生成随机数组
data = np.random.randn(2,3)
设置种子(随便设置一个有趣的数字),确保每次生成的随机数是一致的。如果不设置那嚒每次随机的数组 不一样
In [5]:
np.random.seed(123)
In [6]:
data
Out[6]:
array([[ 0.46135328, 0.32250428, -0.19077805],
[ 1.06864943, 0.05923916, -0.10650734]])
In [7]:
data.ndim
Out[7]:
2
一个ndarray是一个通用的多维数组的同类数据容器,也就是说它包含的每一个元素均为相同类型。每个数组都有一个shape,来表示维数的大小,而用dtype表示数据的类型
In [8]:
data.shape
Out[8]:
(2, 3)
In [9]:
data.dtype
Out[9]:
dtype('float64')
进行一些数学运算
In [10]:
data*10
Out[10]:
array([[ 4.61353275, 3.22504279, -1.90778049],
[10.6864943 , 0.59239157, -1.06507342]])
In [11]:
data+data
Out[11]:
array([[ 0.92270655, 0.64500856, -0.3815561 ],
[ 2.13729886, 0.11847831, -0.21301468]])
In [12]:
al=np.array([[1,2],[3,4],[5,6]])
al
Out[12]:
array([[1, 2],
[3, 4],
[5, 6]])
In [13]:
al*al
Out[13]:
array([[ 1, 4],
[ 9, 16],
[25, 36]])
实现数组的转置,T
In [14]:
al.T
Out[14]:
array([[1, 3, 5],
[2, 4, 6]])
把一个数组的维数转换成另一个数组,实现重构reshape()
In [22]:
al.reshape(2,3)
Out[22]:
array([[1, 2, 3],
[4, 5, 6]])
实现数组的点乘dot 下面维al数组与其转置数组的乘积,最终为3*3
In [25]:
al.dot(al.T)
Out[25]:
array([[ 5, 11, 17],
[11, 25, 39],
[17, 39, 61]])
2.1.1创建n维数组,生成ndarray
In [13]:
datal=[6,7.5,80,1]
arr1=np.array(datal)
arr1
Out[13]:
array([ 6. , 7.5, 80. , 1. ])
嵌套序列能被转换为多维数组:
In [12]:
data2=[[1,2,3,4],[5,6,7,8]]
arr2=np.array(data2)
arr2
Out[12]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
因为data2是一个包含列表的列表(list of lists), 所以arr2维数为2,我们能用ndim和shape属性夹来确认
In [5]:
print(arr2.ndim)
print(arr2.shape)
2
(2, 4)
除非主动声明,否则np.array会自动推断生成的数据类型,并存储在一个特殊的元数据dtype中
In [14]:
arr1.dtype
Out[14]:
dtype('float64')
In [22]:
arr2.dtype
Out[22]:
dtype('int32')
除了np.array,还有一些其他函数能创建数组,比如给定长度及形状后,zeros可以一次性创造全0数组,ones可以一次性创造全1数组。empty可以创建一个没有初始化数值的数组
In [27]:
np.zeros(10) #生成全为0的一维数组,参数为shape
Out[27]:
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [36]:
np.zeros((3,6)) #生成全为0的二维数组
Out[36]:
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
In [35]:
np.empty((2,3,2)) #empty并不能保证返回的所有是0的数组,某些情况下,会返回为初始化的垃圾数值,比如上面
Out[35]:
array([[[1.19014900e-311, 3.16202013e-322],
[0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 1.34033316e-075]],
[[2.16612719e+184, 1.79253058e+160],
[7.62780957e+169, 1.09395731e-042],
[1.21544411e-046, 2.46364746e+184]]])
arrange是一个数组版的Python range函数:
In [43]:
np.arange(3,8,2) #括号参数(i,j,k),i为起始值,j为终值,k为步长
Out[43]:
array([3, 5, 7])
In [6]:
np.arange(15).reshape(3,5) #'int' object is not callable
Out[6]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
2.1.2 Data Types for ndarrays(ndarray的数据类型)
dtype保存数据的类型:
In [30]:
arr3=np.array([1,2,3],dtype=np.float64)
In [31]:
arr3
Out[31]:
array([1., 2., 3.])
In [32]:
arr4=np.array([1,2,3],dtype=np.int32)
In [33]:
arr4.dtype
Out[33]:
dtype('int32')
可以使用astype方法显式地转换数组的数据类型
In [15]:
arr=np.array([1,2,3,4,5])
In [16]:
arr.dtype
Out[16]:
dtype('int32')
In [17]:
float_arr=arr.astype(np.float64)
In [18]:
float_arr.dtype
Out[18]:
dtype('float64')
In [19]:
arr=np.array([3.7,-1.2,-2.6,0.5,12.9,10.1])
In [20]:
arr
Out[20]:
array([ 3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [21]:
arr.astype(np.int32)
Out[21]:
array([ 3, -1, -2, 0, 12, 10])
如果你有一个数组,里面的元素都是表达数字含义的字符串,也可以通过astype将字符串转换为数字
In [24]:
numeric_strings=np.array(['1.25','-9.6','42'],dtype=np.string_)
In [25]:
numeric_strings.astype(float)
Out[25]:
array([ 1.25, -9.6 , 42. ])
如果因为某些原因导致转换类型失败(比如字符串无法砖混为float64位时),将会抛出一个valueerror。这里我们可以使用float来代替np.float64,时因为NumPy可以使用相同别名来表征与Python精度相同的Python数据类型
In [26]:
in_array=np.arange(10)
In [27]:
calibers=np.array([.22,.270,.357,.380,.44,.50],dtype=np.float64)
In [28]:
in_array.astype(calibers.dtype)
Out[28]:
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
也可以用类型代码来传入数据类型
In [29]:
empty_uint32=np.empty(8,dtype='u4')
In [30]:
empty_uint32
Out[30]:
array([0, 0, 0, 0, 0, 0, 0, 0], dtype=uint32)
2.1.3 NumPy数组算数
In [31]:
arr=np.array([[1.,2.,3.],[4.,5.,6.]])
In [32]:
arr
Out[32]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [33]:
arr*arr
Out[33]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
In [34]:
1/arr
Out[34]:
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
In [35]:
arr**0.5
Out[35]:
array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
同尺寸数组之间比较,会产生一个布尔值数组
In [36]:
arr2=np.array([[0.,4.,1.],[7.,2.,12.]])
In [37]:
arr2
Out[37]:
array([[ 0., 4., 1.],
[ 7., 2., 12.]])
In [39]:
arr2>arr
Out[39]:
array([[False, True, False],
[ True, False, True]])
2.1.4 Basic Indexing and Slicing(基本的索引和切片)
有多种方式可以让我们选中数据的子集或者某个单个元素
In [7]:
arr=np.arange(10)
In [8]:
arr
Out[8]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [9]:
arr[5]
Out[9]:
5
In [10]:
arr[5:8]
Out[10]:
array([5, 6, 7])
In [11]:
arr[5:8]=12 #数值被传递给了整个切片
In [12]:
arr
Out[12]:
array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
In [13]:
arr[[2,3,5]] #实现跳着取值
Out[13]:
array([ 2, 3, 12])
数组的切片是原数组的视图,这意味着数组并不是被复制,任何对于数组的修改都会反映到原数组上
In [14]:
arr_slice=arr[5:8]
In [15]:
arr_slice
Out[15]:
array([12, 12, 12])
当改变arr_slice,变化也会体现在原数组上
In [16]:
arr_slice[1]=1234
In [17]:
arr
Out[17]:
array([ 0, 1, 2, 3, 4, 12, 1234, 12, 8, 9])
不写切片值[:]将会引用数组的所有值
In [18]:
arr_slice[:]=64
In [19]:
arr
Out[19]:
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
在一个二维数组中,每个索引值对应的元素不再是一个值,而是一个一维数组
In [20]:
arr2d=np.array([[1,2,3],[4,5,6],[7,8,9]])
In [21]:
arr2d[2]
Out[21]:
array([7, 8, 9])
我们可以通过传递索引的都好分隔列表取选择单个元素,下面两种方法都可以取出矩阵中的元素
In [22]:
arr2d[0][2]
Out[22]:
3
In [23]:
arr2d[0,2]
Out[23]:
3
可以展示二维数组上的索引,我们可以将0轴看成行,将1轴看作列
0
1
2
0
0,0
0,1
0,2
1
1,0
1,1
1,2
2
2,0
2,1
2,2
在一个numpy数组中对元素进行索引
In [24]:
arr3d=np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
In [25]:
arr3d
Out[25]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
In [26]:
arr3d[0] #其是一个2×3的数组
Out[26]:
array([[1, 2, 3],
[4, 5, 6]])
标量和数组都可以传递给arr3d[0]
In [27]:
old_values=arr3d[0].copy()
In [28]:
arr3d[0]=42
In [29]:
arr3d
Out[29]:
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
In [30]:
arr3d[0]=old_values
In [31]:
arr3d
Out[31]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
类似地,arr3d[1,0]返回的是一个一维数组
2.1.4.1 数组的切片索引
In [32]:
arr
Out[32]:
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
In [33]:
arr[1:6]
Out[33]:
array([ 1, 2, 3, 4, 64])
In [34]:
arr2d
Out[34]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [35]:
arr2d[:2]
Out[35]:
array([[1, 2, 3],
[4, 5, 6]])
In [36]:
arr2d[:2,1:]
Out[36]:
array([[2, 3],
[5, 6]])
In [37]:
arr2d[1,:2] #只选择第二行但选择前两列
Out[37]:
array([4, 5])
In [38]:
arr2d[:,:1]
Out[38]:
array([[1],
[4],
[7]])
In [40]:
arr2d[:2,1:]=0
In [41]:
arr2d
Out[41]:
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])
2.1.5 Bollean Indexing(布尔索引)
假设我们的数组数据里有一些重复,我们这里用numpy.random里的randn函数来随机生成一些离散数据
In [44]:
names=np.array(['bob','joe','will','bob','joe','will'])
names
Out[44]:
array(['bob', 'joe', 'will', 'bob', 'joe', 'will'], dtype=')
In [45]:
data=np.random.randn(6,4)
In [46]:
names
Out[46]:
array(['bob', 'joe', 'will', 'bob', 'joe', 'will'], dtype=')
In [47]:
data
Out[47]:
array([[-0.15617029, 0.78810436, 0.55919985, 0.01472379],
[ 0.97582425, -0.51494762, -0.82604889, 1.15550465],
[ 0.74239806, 0.06849439, 0.29434997, 1.00783583],
[ 1.2865622 , 0.44044342, 0.81274569, -0.25539585],
[-1.05129912, 0.55896724, -1.63058723, 0.06068184],
[-0.69533374, 0.83924114, -0.40033448, -0.01697505]])
比较names数组与字符串’bob’会产生一个布尔值类型
In [48]:
names=='bob'
Out[48]:
array([ True, False, False, True, False, False])
In [49]:
data[names == 'bob'] #布尔值数组的长度必须与数组轴索引长度一致
Out[49]:
array([[-0.15617029, 0.78810436, 0.55919985, 0.01472379],
[ 1.2865622 , 0.44044342, 0.81274569, -0.25539585]])
In [50]:
data[names=='bob',2:]
Out[50]:
array([[ 0.55919985, 0.01472379],
[ 0.81274569, -0.25539585]])
In [51]:
data[names=='bob',3]
Out[51]:
array([ 0.01472379, -0.25539585])
可以使用!=或在条件表达式前使用~对条件取反
In [52]:
names!='bob'
Out[52]:
array([False, True, True, False, True, True])
In [53]:
data[~(names=='bob')]
Out[53]:
array([[ 0.97582425, -0.51494762, -0.82604889, 1.15550465],
[ 0.74239806, 0.06849439, 0.29434997, 1.00783583],
[-1.05129912, 0.55896724, -1.63058723, 0.06068184],
[-0.69533374, 0.83924114, -0.40033448, -0.01697505]])
~符号可以在你想要对一个通用条件取反时使用:
In [54]:
cond= names=='bob'
In [55]:
data[~cond]
Out[55]:
array([[ 0.97582425, -0.51494762, -0.82604889, 1.15550465],
[ 0.74239806, 0.06849439, 0.29434997, 1.00783583],
[-1.05129912, 0.55896724, -1.63058723, 0.06068184],
[-0.69533374, 0.83924114, -0.40033448, -0.01697505]])
当要选择三个名字中的两个来组合多个布尔值条件,需要使用布尔算数运算符如&(and)和|(or):
In [56]:
mask=(names=='bob')|(names=='will')
In [57]:
mask
Out[57]:
array([ True, False, True, True, False, True])
In [58]:
data[mask]
Out[58]:
array([[-0.15617029, 0.78810436, 0.55919985, 0.01472379],
[ 0.74239806, 0.06849439, 0.29434997, 1.00783583],
[ 1.2865622 , 0.44044342, 0.81274569, -0.25539585],
[-0.69533374, 0.83924114, -0.40033448, -0.01697505]])
使用布尔值索引选择数据时,纵使生成数据的拷贝,即使返回数组并没有任何变化
In [59]:
data[data<0]=0
In [60]:
data
Out[60]:
array([[0. , 0.78810436, 0.55919985, 0.01472379],
[0.97582425, 0. , 0. , 1.15550465],
[0.74239806, 0.06849439, 0.29434997, 1.00783583],
[1.2865622 , 0.44044342, 0.81274569, 0. ],
[0. , 0.55896724, 0. , 0.06068184],
[0. , 0.83924114, 0. , 0. ]])
In [62]:
data[names !='joe']=7
In [63]:
data
Out[63]:
array([[7. , 7. , 7. , 7. ],
[0.97582425, 0. , 0. , 1.15550465],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[0. , 0.55896724, 0. , 0.06068184],
[7. , 7. , 7. , 7. ]])
2.1.6 神奇索引(花式索引)
用整数数组进行数据索引
In [50]:
arr=np.empty((8,4))
In [52]:
for i in range(8):
arr[i]=i
In [53]:
arr
Out[53]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
In [64]:
arr[[4,3,0,6]] #可以通过传递一个包含指明所需顺序的列表或数组来完成
Out[64]:
array([ 4, 3, 0, 64])
如果想要使用负索引,将从尾部进行选择,且尾部从-1开始
In [55]:
arr[[-3,-5,-7]]
Out[55]:
array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
In [66]:
arr=np.arange(32).reshape((8,4))
In [67]:
arr
Out[67]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
In [68]:
arr[[1,5,7,2],[0,3,1,2]] #元素(1,0),(5,3),(7,1)和(2,2)被选中
Out[68]:
array([ 4, 23, 29, 10])
In [69]:
arr[[1,5,7,2]][:,[0,3,1,2]] #选择对应行的所有列的元素然后对其元素进行重排列
Out[69]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
2.1.7 数组转置与转轴
In [62]:
arr=np.arange(15).reshape((3,5))
In [63]:
arr
Out[63]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [65]:
arr.T #实现转置
Out[65]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
In [66]:
arr=np.random.randn(6,3)
In [70]:
arr
Out[70]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
In [71]:
np.dot(arr.T,arr) #运动np.dot来实现矩阵内积的运算
Out[71]:
array([[2240, 2352, 2464, 2576],
[2352, 2472, 2592, 2712],
[2464, 2592, 2720, 2848],
[2576, 2712, 2848, 2984]])
对于更高维的数组,transpose方法可以接收包含轴编号的元组,用于置换轴
In [72]:
arr=np.arange(16).reshape((2,2,4))
In [73]:
arr
Out[73]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [74]:
arr.transpose((1,0,2)) b
Out[74]:
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
transpose对应的为(x,z,y)所以原本对应的为(0,1,2),而此时为(1,0,2)则说明为x轴与z轴做转换

ndarray有一个swapaxes方法,该方法接受一对轴编号作为参数,并对轴进行调整用于重组数据
In [75]:
arr
Out[75]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [76]:
arr.swapaxes(1,2)
Out[76]:
array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])
swapaxes返回的是数据视图,而没有对数据进行复制
2.2 Universal Functions:Fast ELement-Wise Array Function通用函数:快速的逐元素组函数
通用函数,也可以称为ufunc,是一种ndarray数据中进行逐元素操作的函数。某些简单的函数接收一个或多个标量数值,并产生一个或多个标量结果,而通用函数就是对这些简单函数的向量化封装。
In [3]:
import numpy as np
arr=np.arange(10)
arr
Out[3]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [2]:
np.sqrt(arr)
Out[2]:
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
In [3]:
np.exp(arr)
Out[3]:
array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,
5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03])
这些所谓的一元通用数组。还有一些通用函数,比如add或maximum则会接收两个数组并返回一个数组作为结果,因此称为二元通用数组;
In [4]:
x=np.random.randn(8)
In [5]:
y=np.random.randn(8)
In [6]:
x
Out[6]:
array([-1.71934677, 0.45956982, -0.56925864, 0.64122796, 0.58176134,
0.62108431, 0.21585084, 0.29798706])
In [7]:
y
Out[7]:
array([ 1.54563281, 0.50781319, -1.38705888, 2.25442914, 0.70391184,
0.76855306, -0.18677131, -0.8331781 ])
In [8]:
np.maximum(x,y)
Out[8]:
array([ 1.54563281, 0.50781319, -0.56925864, 2.25442914, 0.70391184,
0.76855306, 0.21585084, 0.29798706])
这里的numpy.maximum逐个元素将x和y中元素的最大值计算出来
也有一些通用函数返回多个数组。比如modf,是python内建函数divmod的向量化版本。它返回了一个浮点数组的小数部分和整数部分
In [9]:
arr=np.random.randn(7)*5
In [10]:
arr
Out[10]:
array([-4.54753594, 7.06939254, -9.12280319, -2.60143795, -1.17506862,
8.38533238, -0.55305598])
In [11]:
remainer, whole_part=np.modf(arr)
In [12]:
remainer
Out[12]:
array([-0.54753594, 0.06939254, -0.12280319, -0.60143795, -0.17506862,
0.38533238, -0.55305598])
In [13]:
whole_part
Out[13]:
array([-4., 7., -9., -2., -1., 8., -0.])
通用函数接收一个可选参数out,允许对数组按位置操作:
In [14]:
arr
Out[14]:
array([-4.54753594, 7.06939254, -9.12280319, -2.60143795, -1.17506862,
8.38533238, -0.55305598])
In [15]:
np.sqrt(arr)
C:\Users\YUZI\Anaconda3\lib\site-packages\ipykernel_launcher.py:1: RuntimeWarning: invalid value encountered in sqrt
"""Entry point for launching an IPython kernel.
Out[15]:
array([ nan, 2.65883293, nan, nan, nan,
2.89574384, nan])
nan-NaN,Not a Number,非数,它即不是无穷大, 也不是无穷小,无穷大减无穷大会导致NaN,无穷大乘以0或无穷小或除以无穷大会导致NaN,有NaN参与的运算, 其结果也一定是NaN,NaN != NaN
In [16]:
np.sqrt(arr,arr)
C:\Users\YU\Anaconda3\lib\site-packages\ipykernel_launcher.py:1: RuntimeWarning: invalid value encountered in sqrt
"""Entry point for launching an IPython kernel.
Out[16]:
array([ nan, 2.65883293, nan, nan, nan,
2.89574384, nan])
In [17]:
arr
Out[17]:
array([ nan, 2.65883293, nan, nan, nan,
2.89574384, nan])
一元通用函数
| 函数名 | 描述 |
|---|---|
| abs、fabs | 逐个元素地计算整数、浮点数或复数地绝对值 |
| sqrt | 计算每个元素地平方根(与arr**0.5相等) |
| square | 计算每个元素的平方(与arr**2)相等 |
| exp | 计算每个元素的自然指数值为e^x |
| log、log10、log2、log1p | 分别对应:自然对数(e为底)、对数10为底、对数2为底、log(1+x) |
| sign | 计算每个元素的符号值:1(整数)、0(0)、-1(负数) |
| ceil | 计算每个元素的最高整数值(即大于等于给定数值的最小整数 |
| floor | 计算每个元素的最小整数值(即小于等于给定元的最大整数) |
| rint | 将元素保留到整数位,并保持dtype |
| modf | 分贝将数组的小数部分和整数部分按数组的形式返回 |
| isnan | 返回数组中的元素是否是一个naN(不是一个数值),形式为布尔值数组 |
| isfinite、isinf | 分别返回数组中元素是否有限(非inf、非NaN)是否是无限,形式为布尔值数组 |
| cos、cosh、sin | 常规的双曲三角函数 |
| sinh、tan、tanh | |
| arccos、arccosh、arcsin | 反三角函数 |
| arcsinh、arctan、arctanh | |
| logical_not | 对数组的元素按位取反(与~arr效果一致 |
二元通用函数
| 函数名 | 描述 |
|---|---|
| add | 将数组的对应元素相加 |
| substract | 在第二个数组中,将第一个数组中包含的元素去除 |
| multiply | 将数组对应元素相乘 |
| divide,floor_divide | 除或整除(放弃余数) |
| power | 将第二个数组的元素作为第一个数组对应元素的幂次方 |
| maximum,fmax | 逐个元素计算最大值,fmax忽略NaN |
| minimun,fmin | 逐个元素计算最小值,fmin忽略NaN |
| mod | 暗元素的求模计算(即求除法的余数) |
| copysign | 将第一个数组的符号值改为第二个数组的符号值 |
| greater,greater_equal,less | 进行逐个元素比较、返回布尔值 |
| less_equal,equal,not_equal | 操作符>,>=,<,<=,==,!=效果一致 |
| logical_and,logical_or | 逐个进行元素的逻辑操作(与逻辑运算符&、 |
| logical_xor |
2.3使用数组进行面向数组编程
使用Numpy数组表达式可以替代一些显示循环的方法,称为向量化
作为一个简单的示例,假设我们想要对一些网络书来计算函数sqrt(x2+y2)的值。np.meshgris函数接收两个一维数组,并根据两个数组的索引(x,y)对应生成一个二维数组
In [6]:
points=np.arange(-5,5,0.01) # 1000 equally spaces points
In [7]:
xs,ys=np.meshgrid(points,points)
In [8]:
ys
Out[8]:
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])
现在你可以用和两个坐标值同样的表达式来使用函数
In [10]:
z=np.sqrt(xs**2+ys**2)
In [11]:
z
Out[11]:
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]])
我们使用matplotlib来生成这个二维数组的可视化
假设x是长度为m的向量,y是长度为n的向量,则最终生成
In [1]:
import numpy as np
m,n=(5,3)
x=np.linspace(0,1,m) #起始值为0,终止值为1,生成的样本数为5
y=np.linspace(0,1,n)
X,Y=np.meshgrid(x,y) #np.meshgrid(*xi, **kwargs),从坐标向量中返回坐标矩阵
x
Out[1]:
array([0. , 0.25, 0.5 , 0.75, 1. ])
In [13]:
y
Out[13]:
array([0. , 0.5, 1. ])
In [14]:
X
Out[14]:
array([[0. , 0.25, 0.5 , 0.75, 1. ],
[0. , 0.25, 0.5 , 0.75, 1. ],
[0. , 0.25, 0.5 , 0.75, 1. ]])
In [15]:
Y
Out[15]:
array([[0. , 0. , 0. , 0. , 0. ],
[0.5, 0.5, 0.5, 0.5, 0.5],
[1. , 1. , 1. , 1. , 1. ]])
函数:numpy.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
参数:
start:scalar类型(个人理解是标量的意思,这不是一个具体的数据类型,而是指某一些数据类型,比如int,float,bool,long,str等等都属于sclar类型)。这个数参数表示这个序列的开始值。
stop:scalar类型。如果endpoint=True。那么stop就是序列的终止数值。当endpoint=False时,返回值中不包含最后一个端点,并且步长会改变。
num:int型,可选参数,默认值为50。表示要生成的样本数,必须是非负值。
endpoint:bool类型。可选参数,默认值为True,这时stop就是最后的样本。为False时,不包含stop的值。
retstep:bool类型。可选参数,默认值为True,这时返回值是(samples,step),前面的是数组,后面是步长。
dtype:表示输出的数组的数据类型,如果没有给出就从其他输入中推断输出的类型
可以看到x和y的shape都是3*5,用图的画更好理解
把x和y画出来后,就可以看到网络
In [16]:
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot') #样式美化作用
plt.plot(X,Y,marker='.',color='blue',linestyle='none')
Out[16]:
[<matplotlib.lines.Line2D at 0x28055dc0a48>,
<matplotlib.lines.Line2D at 0x28057e2d9c8>,
<matplotlib.lines.Line2D at 0x28057e27b08>,
<matplotlib.lines.Line2D at 0x28057e2da08>,
<matplotlib.lines.Line2D at 0x28057e2db08>]
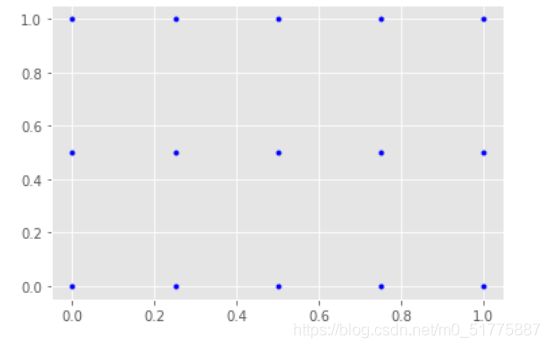
说明:
x:x轴数据,列表或数组,可选
y:y轴数据,列表或数组
format_string:控制曲线的格式字符串,可选
**kwargs:第二组或更多,(x,y,format_string)
可以用zip得到网络平面上坐标点的数据
In [17]:
z=[i for i in zip(X.flat,Y.flat)]
In [18]:
z
Out[18]:
[(0.0, 0.0),
(0.25, 0.0),
(0.5, 0.0),
(0.75, 0.0),
(1.0, 0.0),
(0.0, 0.5),
(0.25, 0.5),
(0.5, 0.5),
(0.75, 0.5),
(1.0, 0.5),
(0.0, 1.0),
(0.25, 1.0),
(0.5, 1.0),
(0.75, 1.0),
(1.0, 1.0)]
接下来就是书上的内容
In [19]:
points=np.arange(-5,5,0.01)
In [20]:
xs,ys=np.meshgrid(points,points)
In [21]:
ys
Out[21]:
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])
现在可以用两个坐标值相同的表达式来使用函数
In [22]:
z=np.sqrt(xs**2+ys**2)
In [23]:
z
Out[23]:
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]])
In [24]:
import matplotlib.pyplot as plt
In [25]:
plt.imshow(z,cmap=plt.cm.gray);plt.colorbar()
plt.title("Image plot of $\sqrt{x^2+y^2}$ for a grid of values")
Out[25]:
Text(0.5, 1.0, 'Image plot of $\\sqrt{x^2+y^2}$ for a grid of values')

2.3.1 讲条件逻辑作为数组操作
numpy.where函数是三元表达式x if conditon else y的向量化版本,假设我们有一个布尔值数组和两个数值数组
In [26]:
xarr=np.array([1.1,1.2,1.3,1.4,1.5])
In [27]:
yarr=np.array([2.1,2.2,2.3,2.4,2.5])
In [28]:
cond=np.array([True,False,True,True,False])
假设cond中元素为True时,我们去xarr中对应元素值,否则取yarr中元素。我们可以通过列表推导式来完成
In [29]:
result=[(x if c else y)
for x,y,c in zip(xarr,yarr,cond)]
In [30]:
result
Out[30]:
[1.1, 2.2, 1.3, 1.4, 2.5]
如果数组很大的话,速度会很慢,其次,当数组时多维时,就无法奏效。而且使用np.where时,就可以非常简单的完成
In [31]:
result=np.where(cond,xarr,yarr)
In [32]:
result
Out[32]:
array([1.1, 2.2, 1.3, 1.4, 2.5])
np.where的第二个和第三个参数并不是一定要为数组,它可以为标量。where在数据分析中的一个典型用法就是根据数组来生成一个新的数组。假设你有一个随机生成的矩阵数据,并且你想将其中的正值都替换为2,将所有负值替换为-2,使用np.where会很容易实现
In [33]:
arr=np.random.randn(4,4)
In [34]:
arr
Out[34]:
array([[-0.38950138, -0.71566067, 1.71015045, -0.76597411],
[-2.23808388, 0.11958176, 0.60700502, 0.00694105],
[ 1.04539582, 0.603809 , -0.63171234, -0.58905507],
[ 0.62776747, 1.10346074, 1.84641653, -1.31122948]])
In [35]:
arr>0
Out[35]:
array([[False, False, True, False],
[False, True, True, True],
[ True, True, False, False],
[ True, True, True, False]])
In [36]:
np.where(arr>0,2,-2)
Out[36]:
array([[-2, -2, 2, -2],
[-2, 2, 2, 2],
[ 2, 2, -2, -2],
[ 2, 2, 2, -2]])
你也可以使用np.where将标量和数组联合,例如:我可以像下面的代码那样将arr中的所有正值替换为常数2;
In [37]:
np.where(arr>0,2,arr)
Out[37]:
array([[-0.38950138, -0.71566067, 2. , -0.76597411],
[-2.23808388, 2. , 2. , 2. ],
[ 2. , 2. , -0.63171234, -0.58905507],
[ 2. , 2. , 2. , -1.31122948]])
传递给np.where的数组既可以是同等大小的数组,也可以是标量
2.3.2 数学和统计方法
许多关于计算整个数组统计值或关于轴向数据的数学函数,可以作为数组类型的方法被调用。可以使用聚合函数,如sum,mena和std(标准差)。既可直接调用数组实例的方法,也可以用顶层的Nympy函数
In [38]:
arr=np.random.randn(5,4)
In [39]:
arr
Out[39]:
array([[ 0.87987064, 2.28629166, 0.13273007, -0.97836356],
[ 1.05282823, 0.05833666, -1.31463745, 0.94271998],
[ 2.38726341, -0.45275962, 0.68676748, 0.94508085],
[ 1.71832893, 0.42135837, -0.59547423, -0.35479958],
[ 1.42495389, 0.43276111, -1.51416962, -1.44537225]])
In [40]:
arr.mean() #求取这个数组中的平均值
Out[40]:
0.3356857485379926
In [41]:
np.mean(arr) #同样可以实现求取数组的平均值
Out[41]:
0.3356857485379926
In [42]:
arr.sum()
Out[42]:
6.713714970759852
像mean,sum这样的函数可以接受一个可选参数axis,这个参数可以用于计算给定轴向上的统计值,形成一个下降一维度的数组
In [43]:
arr.mean(axis=1) #计算每一列的平均值,但实际看成的为行上的元素的运算
Out[43]:
array([ 0.5801322 , 0.18481186, 0.89158803, 0.29735337, -0.27545672])
In [44]:
arr.sum(axis=0) #计算行轴向的和,但实际看成为列上的元素的运算
Out[44]:
array([ 7.46324511, 2.74598818, -2.60478375, -0.89073456])
其他方法,例如cumsum和cumprod并不会聚合,它们会产生一个中间结果:
In [46]:
arr=np.array([0,1,2,3,4,5,6,7])
In [47]:
arr.cumsum()
Out[47]:
array([ 0, 1, 3, 6, 10, 15, 21, 28], dtype=int32)
在多维数组中,像cumsum这样的累积函数返回相同长度的数组,但是可以在指定轴向上根据较低维度的切片进行部分聚合:
In [48]:
arr=np.array([[0,1,2],[3,4,5],[6,7,8]])
In [49]:
arr
Out[49]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [50]:
arr.cumsum(axis=0) #按行进行累加,但实际看成按列累加
Out[50]:
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]], dtype=int32)
In [52]:
arr.cumprod(axis=1) #按列进行累乘,但实际看成按行累乘
Out[52]:
array([[ 0, 0, 0],
[ 3, 12, 60],
[ 6, 42, 336]], dtype=int32)
基础数组统计方法
| 方法 | 描述 |
|---|---|
| sum | 沿着轴向计算所有元素的累和,0长度的数组,累和为0 |
| mead | 数学平均,0长度的数组平均值为NaN |
| std,var | 标准差和方差,可以选择自由度调整(默认分母是n) |
| min,max | 最小值和最大值 |
| argmin,argmax | 最小值和最大值的位置 |
| cumsum | 从0开始元素累积和 |
| cumprod | 从1开始元素累积积 |
2.3.3布尔数组的方法
在前面介绍的方法中,布尔值会被强制为1(True)和0(False)。因此,sum通常也可以用来计算布尔值书中的True的个数
In [53]:
arr=np.random.randn(100)
In [55]:
(arr>0).sum()
Out[55]:
54
对于布尔值数组,有两个非常有用的方法any和all。any检查数组中是否至少有一个True,而all检查是否每个值都是True:
In [56]:
bools=np.array([False,False,False,True])
In [59]:
bools.any()
Out[59]:
True
In [60]:
bools.all()
Out[60]:
False
这些方法也可适用于非布尔值数组,所有非0元素都会按照True处理
2.3.4排序
和Python的内建列表类型相似,Numpy数组可以使用sort方法按照位置排序
In [61]:
arr=np.random.randn(6)
In [62]:
arr
Out[62]:
array([ 1.56951451, 0.73367014, 1.39641352, 1.02966621, 0.56809946,
-0.36350897])
In [63]:
arr.sort()
In [64]:
arr
Out[64]:
array([-0.36350897, 0.56809946, 0.73367014, 1.02966621, 1.39641352,
1.56951451])
也可以在多维数组中根据传递的axis值,沿着轴向对每个一维数据段进行排序:
In [65]:
arr=np.random.randn(5,3)
In [66]:
arr
Out[66]:
array([[ 1.35634546, -1.0137158 , 0.91577766],
[ 0.94592147, -1.26512955, -1.85269001],
[-0.17392526, -2.16555175, 0.31154325],
[-0.97832666, -1.94065093, -0.66912016],
[-0.40120236, 0.07929388, 1.1182761 ]])
In [67]:
arr.sort(1) #对应列进行排序,但实际是对应行进行排列
In [68]:
arr
Out[68]:
array([[-1.0137158 , 0.91577766, 1.35634546],
[-1.85269001, -1.26512955, 0.94592147],
[-2.16555175, -0.17392526, 0.31154325],
[-1.94065093, -0.97832666, -0.66912016],
[-0.40120236, 0.07929388, 1.1182761 ]])
顶层np.sort返回的是已经排序好的数组拷贝,而不是对原数组按照位置排序。下面的例子计算的是一个数组的分位数,并选出分位数所对应的值,这是一个字应急的方法
In [69]:
large_arr=np.random.randn(1000)
In [70]:
large_arr.sort()
In [71]:
large_arr[int(0.05*len(large_arr))] #5% quantile
Out[71]:
-1.685247675588742
2.3.5唯一值与其他集合逻辑
常用的一个方法np.unique返回的是数组中唯一值排序后形成的数组
In [72]:
names=np.array(['bob','joe','will','bob','will','joe','joe'])
In [73]:
np.unique(names)
Out[73]:
array(['bob', 'joe', 'will'], dtype=')
In [75]:
ints=np.array([3,3,3,2,2,1,4,4])
In [76]:
np.unique(ints)
Out[76]:
array([1, 2, 3, 4])
In [77]:
sorted(set(names))
Out[77]:
['bob', 'joe', 'will']
np.in1d可以检查一个数组中的值是否在另外一个数组中,并返回一个布尔值数组
In [78]:
values=np.array([6,0,0,3,2,5,6])
In [79]:
np.in1d(values,[2,3,6])
Out[79]:
array([ True, False, False, True, True, False, True])
数组的集合操作
| 方法 | 描述 |
|---|---|
| unique(x) | 计算x的唯一值,并排序 |
| intersect1d(x,y) | 计算x和y的交集,并排序 |
| union1d(x,y) | 计算x和y的并集,并排序 |
| in1d(x,y) | 计算x中的元素是否包含在y中,返回一个布尔值数组 |
| setdiff1d(x,y) | 差集,在x中但不在y中的元素 |
| setxot1d(x,y) | 异或集,在x或y中,但不属于x、也交集的元素 |
2.4使用数组进行文件输入和输出
Numpy可以在硬盘中将数据以文本或二进制文件的形式进行存入硬盘或由硬盘载入
np.save和np.load是高效存取硬盘数据的两大工具函数。数组是在默认情况下以未压缩的格式进行存储的,后缀名为.npy
In [4]:
arr=np.arange(10)
In [5]:
np.save('some_array',arr)
如果文件存放路径没写.npy时,后缀名会被自动加上。硬盘上的数组可以使用np,load进行载入
In [6]:
np.load('some_array.npy')
Out[6]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
也可以用np.savez并将数组作为参数传递给该函数,用于未压缩文件中保存多个数组
In [8]:
np.savez('array_archive.npz',a=arr,b=arr)
当载入一个.npy文件的时候,你会获得一个字典型对象,并通过该对象很方便的载入单个数组
In [9]:
arch=np.load('array_archive.npz')
In [10]:
arch['b']
Out[10]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
如果你的数据已经压缩好啦,你可能想要使用numpy.savez_conpressed将数组存入已经压缩的文件:
In [11]:
np.savez_compressed('arrays_compressed.npz',a=arr,b=arr)
2.5线性代数
比如矩阵乘法、分解、行列式等方阵数学,是所有数组类库的重要组成部分,Numpy的线性代数中所不同的是*是矩阵的逐元素乘积,而不是矩阵的点乘积
In [2]:
x=np.array([[1.,2.,3.],[4.,5.,6.]])
In [3]:
y=np.array([[6.,23.],[-1,7],[8,9]])
In [4]:
x
Out[4]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [5]:
y
Out[5]:
array([[ 6., 23.],
[-1., 7.],
[ 8., 9.]])
In [6]:
x.dot(y)
Out[6]:
array([[ 28., 64.],
[ 67., 181.]])
x.dot(y)等价于np.dot(x,y):
In [7]:
np.dot(x,y)
Out[7]:
array([[ 28., 64.],
[ 67., 181.]])
一个二维数组和一个长度合适的一维数组之间的矩阵乘积,其结果是一个一维数组:
In [8]:
np.dot(x,np.ones(3))
Out[8]:
array([ 6., 15.])
@特殊符号也可以作为中缀操作符,用于点乘矩阵操作
In [9]:
x @ np.ones(3)
Out[9]:
array([ 6., 15.])
numpy.linalg拥有一个矩阵分解的标准函数集,以及其他常用函数
In [10]:
from numpy.linalg import inv,qr
In [12]:
X=np.random.randn(5,5)
In [13]:
mat=X.T.dot(X) #其表示X和它的转置矩阵X.T的点乘积
In [14]:
inv(mat)
Out[14]:
array([[ 2.4479836 , 0.88165589, 1.89633401, 2.72472027, -1.48177422],
[ 0.88165589, 0.68570008, 0.66711201, 0.88992203, -0.63835411],
[ 1.89633401, 0.66711201, 1.85172773, 1.97102654, -1.0465132 ],
[ 2.72472027, 0.88992203, 1.97102654, 3.47073023, -1.73375198],
[-1.48177422, -0.63835411, -1.0465132 , -1.73375198, 1.20475385]])
In [15]:
mat.dot(inv(mat))
Out[15]:
array([[ 1.00000000e+00, 1.37810355e-15, -7.06076290e-16,
1.28576220e-16, -8.54476868e-16],
[-4.37550877e-16, 1.00000000e+00, -1.77510579e-16,
4.24607795e-16, 6.95872593e-17],
[-1.53401778e-15, -5.03197394e-16, 1.00000000e+00,
-7.34267302e-16, 7.83794051e-18],
[-1.44780744e-15, -4.22974365e-16, 2.69135865e-16,
1.00000000e+00, -5.36236979e-16],
[-2.47386095e-16, 1.94053247e-16, -1.40177551e-16,
-8.35028207e-16, 1.00000000e+00]])
In [16]:
q,r=qr(mat)
In [17]:
r
Out[17]:
array([[-11.01440913, 2.05529808, 4.86045722, 4.56266707,
-1.79503566],
[ 0. , -3.55864374, 0.78800698, -1.26569404,
-3.41544318],
[ 0. , 0. , -1.53161019, 0.86317398,
-0.28644568],
[ 0. , 0. , 0. , -1.60431972,
-2.90629349],
[ 0. , 0. , 0. , 0. ,
0.35016297]])
常用的numpy linalg函数
| 函数 | 描述 |
|---|---|
| diag | 将一个方阵的对角(或非对角)元素作为一维数组的返回,或者将一维数组转换为一个方阵,并且在非对角线上有零点 |
| dot | 矩阵点乘 |
| trace | 计算对角元素和 |
| det | 计算矩阵的行列式 |
| eig | 计算方阵的特征值和特征向量 |
| inv | 计算方阵的逆矩阵 |
| pinv | 计算矩阵的Mopre-Penrose伪逆 |
| qr | 计算QR分解 |
| svd | 计算奇异值分解(SVD) |
| solve | 求解x的线性系统Ax=b,其中A是方阵 |
| lstsq | 计算Ax=b的最小二乘解 |
2.6伪随机数生成
numpy.random填补了python内建的random模块不足,可以高效地生成多种概率分布下的完整样本值数值
In [19]:
samples=np.random.normal(size=(4,4))
In [20]:
samples
Out[20]:
array([[ 0.97833729, -0.41295546, -1.43254045, -1.27911546],
[-1.08261732, -0.36482406, 0.9934679 , -0.82584687],
[-0.37644652, -0.7477525 , -0.75179765, -1.02207229],
[ 0.70579449, -1.66386649, 0.90375065, 0.3044154 ]])
numpy.random在生成大型样本时比纯python的方法快了一个数量级
In [21]:
from random import normalvariate
In [22]:
N=1000
In [26]:
%timeit samples=[normalvariate(0,1)for _ in range(N)]
633 µs ± 4.18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [25]:
%timeit np.random.normal(size=N)
24.6 µs ± 392 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
我们可以成这些为伪随机数,因为它们是由具有确定性行为的算法根据随机数生成器中的随机种子生成的。我们可以通过np.random.seed更改为Numpy的随机种子
In [27]:
np.random.seed(1234)
numpy.random中数据生成函数使用了一个全局随机种子。为了避免全局状态,可以使用numpy.random.RandomState创建一个随机数生成器,使数据独立于其他的随机状态
In [28]:
rng=np.random.RandomState(1234)
In [29]:
rng.randn(10)
Out[29]:
array([ 0.47143516, -1.19097569, 1.43270697, -0.3126519 , -0.72058873,
0.88716294, 0.85958841, -0.6365235 , 0.01569637, -2.24268495])
numpy.ransom中可用的部分函数列表
| 函数 | 描述 |
|---|---|
| seed | 向随机数生成器传递随机状态种子 |
| permutation | 返回一个序列的随机排列,或者返回一个乱序的整数范围序列 |
| shuffle | 随机排列一个序列 |
| rand | 从均匀分布中抽取样本 |
| randint | 根据给的那个的由低到高的范围随机抽取随机整数 |
| randn | 从均值0到方差1的正态分布抽取样本 |
| binomial | 从二项分布中抽取样本 |
| normal | 从正态(高斯)分布中抽取样本 |
| beta | 从beta分布中抽取样本 |
| chisquare | 从卡方分布中抽取样本 |
| gama | 从伽马分布中抽取样本 |
| uniform | 从均匀[0,1]分布中抽取样本 |
2.7示例:随机分布
首先让我们考虑一个简单的随机漫步,从0开始步进为1和-1,且两种步进发生的概率相等
以下是一个内建random模块利用纯Python实现一个1000步的随机漫步
In [33]:
import random
position=0
walk=[position]
steps=1000
for i in range(steps):
steps=1 if random.randint(0,1) else -1
position+=steps
walk.append(position)
In [48]:
import matplotlib.pyplot as plt
In [49]:
plt.plot(walk[:100])
Out[49]:
[<matplotlib.lines.Line2D at 0x1cd9a07f208>]

walk只是对随机进步的积累,并且可以通过一个数组的形式进行表达,因此,我们用np.random模块一次性抽取1000次投掷硬币的结果,每次投掷的结果为1或-1,然后计算累积值
In [35]:
nsteps=1000
In [36]:
draws=np.random.randint(0,2,size=nsteps)
In [39]:
steps=np.where(draws>0,1,-1)
In [41]:
walk=steps.cumsum()
由此我们可以从漫步轨道上提取一些统计数据,如最大值、最小值等
In [43]:
walk.min()
Out[43]:
-9
In [44]:
walk.max()
Out[44]:
60
统计随机漫步的某一步达到了某一特定值,这里假设我们想要知道漫步中是何时连续朝某个方向走了10秒,np.abs(walk)>=10给我们一个布尔值数组,用于表示漫步是否在同一方向走了十步,但是我们想要知道是第一次走了10步或-10步的位置,我们可以使用argmax来计算,该函数可以返回布尔值数组中最大值的第一个位置
In [47]:
(np.abs(walk)>=10).argmax()
Out[47]:
297
2.7.1一次性模拟多次随机漫步
如果你的目标是模拟多次随机漫步,比如说5000步
In [52]:
nwalks=5000
In [53]:
nsteps=1000
In [54]:
draws=np.random.randint(0,2,size=(nwalks,nsteps))
In [55]:
steps=np.where(draws>0,1,-1)
In [57]:
walks=steps.cumsum(1)
In [58]:
walks
Out[58]:
array([[ -1, 0, 1, ..., -6, -5, -4],
[ -1, -2, -1, ..., -18, -19, -18],
[ 1, 0, -1, ..., 24, 23, 22],
...,
[ -1, 0, -1, ..., -2, -3, -4],
[ -1, 0, -1, ..., 30, 29, 30],
[ 1, 0, -1, ..., 18, 19, 20]], dtype=int32)
现在我们可以计算这些随机步的最大值和最小值了
In [60]:
walks.max()
Out[60]:
137
In [62]:
walks.min()
Out[62]:
-137
让我们在这些随机步中计算30或-30的最小穿越时间,有点苦难,因为并不是所有的5000个都达到30,我们可以用any的方法来检查
In [63]:
hits30=(np.abs(walks)>=30).any(1)
In [65]:
hits30
Out[65]:
array([False, True, True, ..., False, True, True])
In [66]:
hits30.sum() #达到30或-30的数字
Out[66]:
3431
我们可以用布尔值数组选出绝对步数超过30的步所在行,并使用arfmax从轴向1上获取穿越时间
In [67]:
crossing_times=(np.abs(walks[hits30])>=30).argmax(1)
In [68]:
crossing_times.mean()
Out[68]:
506.2532789274264
利用其他分布而不是等概率的投掷硬币实验随机漫步也是很容易的。我们需要不同的随机数生成函数,比如normal,再根据特定的均值和标准差即可生成正态分布下随机步
In [71]:
steps=np.random.normal(loc=0,scale=0.25,size=(nwalks,nsteps))
5.结果与讨论(Result and Discussion)
5.1naarray创建方式
array函数
接收一个普通的python序列,并将其转换为ndarray
numpy.array(object,dtype=None,copy=True,order=None,subok=False,ndmin=0)
| 参数 | 描述 |
|---|---|
| object | 任何暴露数组接口方法的对象都会返回一个数组或任何(嵌套)序列 |
| dtype | 数组所需的数据类型,可选 |
| copy | 可选,默认为true,对象是否被复制 |
| order | C(换行)、F(按列)或A(任意,默认) |
| subok | 默认情况下,返回的数组被强制为基类数组。如果为true。则返回子类。 |
| ndimin | 指定返回数组的最小维数 |
empty()函数
创建制定形状和dtype的未初始化数组
numpy.empty(shape,dtype=float,order=‘c’
| 参数 | 描述 |
|---|---|
| shape | 空数组的性质,整数或整数元组 |
| dtype | 数组所需的数据类型,可选 |
| order | C(换行)、F(按列)或A(任意,默认) |
zeros()函数
创建指定长度或者形状的全零数组
ones()函数
创建指定长度或者形状的全1数组
asarray()函数
类似 numpy.array 可以将Python序列转换为ndarray。
arange()函数
类似于python的range函数,通过指定开始值、终值和步长来创建一个一维数组,注意:最终创建数组不包含终值
numpy.arange(start,stop,step,dtype)
linspace()函数
通过指定开始值、终值和元素个数来创建一个一维数组,数组的数据元素符合等差数列,可以通过endpoint关键字指定是否包含终值,默认包含终值。
numpy.linspace(start,stop,num,endpoint,retstep,dtype)
logspace()函数
和linspace函数类似,不过创建的是等比数列数组
numpy.logscale(start, stop, num, endpoint, base, dtype)
random()函数
使用随机数填充数组,即使用numpy.random中的random()函数来创建0-1之间的随机元素,数组包含的元素数量由参数决定。
| 参数 | 描述 |
|---|---|
| rand | 返回0-1随机值 |
| randn | 返回一个样本具有标准正态分布 |
| randint | 返回随机的整数,位于半开区间[low,hight]size=10(3,3) |
| random_integers(low[,high,size] | 返回随机的整数,位于闭区间 |
| random | 返回随机浮点数 |
5.2ndarray对象属性
shape
数组的维数
这个数组属性返回一个包含数组维数的元组,它也可以用于调整数组大小
reshape调整数组大小
ndim
数组轴(维数)的个数
itemsize
数组中每个元素的字节大小
size
数组元素的总个数,等于shape属性中元组元素的乘积
dtype
描述数组中的元素类型的对象
| 数据类型 | 类型简写 | 说明 |
|---|---|---|
| int_ | 默认整形 | |
| intc | i1 | 等价于long的整形 |
| int8 | i1 | 字节整形,1个字节,范围:[-128,127] |
| int16 | i2 | 整形,2个字节,范围:[-32768,32767] |
| int32 | i3 | 整形,4个字节,范围:[-2^31, 2^31-1] |
| int64 | i4 | 整形,8个字节,范围:[-2^63, 2^63-1] |
| uint8 | u1 | 无符号整形, 1个字节, 范围:[0,255] |
| uint16 | u2 | 无符号整形, 2个字节, 范围:[0,65535] |
| uint32 | u3 | 无符号整形, 1个字节, 范围:[0, 2^32-1] |
| uint64 | u4 | 无符号整形, 1个字节, 范围:[0,2^64-1] |
| bool_ | 以一个字节形成存储的布尔值(True或者False) | |
| float_ | float64简写形式 | |
| float16 | f2 | 半精度浮点型(2字节):1符号位+5位指数+10位的小数部分 |
| float32 | f4或者 f | 单精度浮点型(4字节):1符号位+8位指数+23位的小数部分 |
| float64 | f8或者d | 双精度浮点型(8字节):1符号位+11位指数+52位的小数部分 |
| complex_ | c16 | complex128的简写形式 |
| complex64 | c8 | complex128的简写形式 |
| complex128 | c16 | 复数,由两个64位的浮点数来表示 |
| object | O | Python对象类型 |
| String_ | S | 固定长度的字符串类型(每个字符1个字节),比如:要创建一个长度为8的字符串,应该使用S8 |
| String_ | U | 固定长度的unicode类型的字符串(每个字符占用字节数由平台决定),长度定义类似String_类型 |
每个数据类型都有一个类型代码,即简写方式!
| 布尔值 | 符号整数 | 无符号整数 | 浮点 | 复数浮点 | 时间间隔 | 日期时间 | Python对象 | 字节串 | Unicode | 原始数据(void) |
|---|---|---|---|---|---|---|---|---|---|---|
| b | i | u | f | c | m | MO | O | S\a | U | V |
6.小结(Summary)
通过Jupter熟悉如何撰写一个完整的实验报告。
对于此章节的学习,
第一,明白了如何运用array函数来生成一个新的包含传递数组的Numpy数组,当然除了np.array也可以运用其他函数来创建新的数组,比如zeros可以一次性创造全0数组,ones可以一次性创造全1的数组,empty可以创建一个没有初始化数值的数组
第二,数组之间可以进行一些基本的算数运算处理,加法乘法除法在满足矩阵运算的条件下都可以成立
第三,对于数组的基本性质可以通过特定的方法获取,dytpe表示的位ndarray的数据类型;shape来表示维数的大小
第四,一些基本的函数对于数组的转换和运算处理,astype方法可以显式地转换数组的数据类型;a.T实现矩阵的转置:reshape()实现重构,把一个数组的维数转换成另一个数组;a.dot实现数组的点乘运算
第五,运用索引与切片的方法可以实现数组中截取特定的元素,可以对数据内部元素进行重新定义,特别注意:不写切片值的[:]将会引用数组的所有值
第六,可以将两个数组建立相互对应关系,进行数组之间的比较(==),运用!=或~实现取反和&(and)和|(or)布尔运算符
7.参考文献(references)
Wes Mckinney,2020,利用Python进行数据分析
sxau_zhangtao,2019.Python之多维数组
如有不正确的地方,望各位大佬指正