博客服务领域驱动(DDD)改造(1) - 领域模型
目录
-
- 学习方面
- 博客项目改造
-
- 项目分层依赖关系
- 业务场景
- 领域模型建模
- ArticleAggreate(文章聚合)
- CategoryAggreate(文章分类聚合)
- CommentAggreate(评论聚合)
- BloggerAggreate(博客用户聚合)
- 领域对象仓储接口
- 领域事件
- 领域服务
- 领域对象怎么做查询,分页,筛选
- 总结
小编最近晚上都去运动,跑步去了,发现好像很久都没更新博客了。然后最近这两三个月也一直在学习关于领域驱动设计的东西,所以打算下面出三到四篇关于领域驱动设计的文章来分享和记录一下我在学习领域驱动设计的感受,或者是坑和对自己项目的改造过程吧。
注意:这篇文章就不过多的去讨论一些领域概念,比较侧重于实践落地,所以如果没有接触过DDD的读者希望还是先去看一看一些基础的领域驱动设计概念。
学习方面
在正式开始领域驱动设计的学习之前都只是在一些公众号或者网上的文章中零零散散的接触到。
之后我是看了Vaughn Vernon的《实现领域驱动设计》一书,然后还有.Net 微服务-体系结构电子书 这个是在微软官方文档中关于DDD实现的文档,我认为这是在网上能找到的最好的关于落地DDD设计的最好的文章了,篇幅不多,不长,但都是刀刀到肉。微软文档大多都是C#的所以不用过多的纠结语言的差异,主要是思想。
在对我自己的博客服务改造的过程中微软的示例项目也给到了很大的帮助 eShopOnContainers
博客项目改造
因为小编也是刚学习DDD,所以可能很多地方大家会有不同的意见或者观点,也希望大家在下面评论,一起学习交流,如果你是大佬就更好了ヾ(≧▽≦*)o。
博客项目Github地址
以前这个项目就是一个经典的三层架构,controller,service,repository。现在要对该项目进行领域驱动设计的改造。
项目分层依赖关系
因为该系列文章可能要分三到四篇文章来写,所以这里我先做个架构铺垫,不然容易懵。
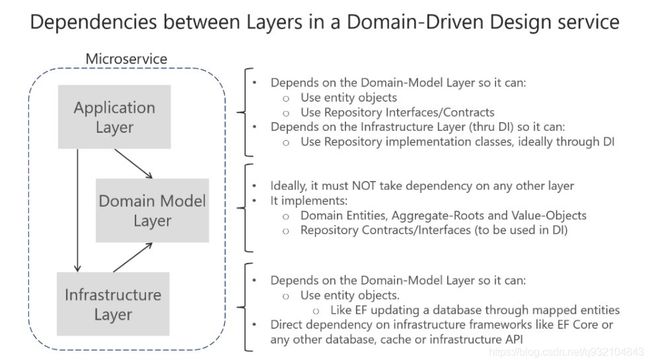
上图是微软的DDD文档的截图,我个人是比较赞同这样的分层依赖关系的,当然还有很多不一样的分层依赖架构。表现在项目中是如下的项目架构。

首先上图中分了三个层,应用层依赖基础设施层和领域模型层,基础设施层同时也依赖领域模型层。领域模型层处于依赖关系的最底端(也是我们这篇文章重点讨论的层)。
为什么领域模型层放在依赖关系的最底端,一个原因是领域模型不应该依赖任何的基础设施,就例如仓储,对于领域模型来说应该只包含业务本身。还有一个原因是小编我自己认为的就是对单元测试绝对的友好呀,根本不需要Mock任何的对象,几乎完美的对业务流程做单元测试。
好了,基础的架构铺垫就到这里了。下面就来说一下对于博客项目怎样做领域模型的落地实践。
业务场景
因为我的这个博客项目也是今年刚做,业务场景并不复杂,额外功能以后再加。
文章业务:创建(选文章分类),编辑,删除,点赞,因为目前只用在个人博客所以还没有发布和审核操作。
文章分类:创建分类,编辑,删除。
评论业务:创建评论,回复评论,删除,点赞。
用户业务:用户业务因为存在一个用户中心(jwt Token做授权认证),所以对于博客这样服务来说只存一些跟博客业务相关的用户信息就好了。
可能因为业务上并不复杂其实现阶段上面的业务都可以归类为一个限界上下文,即博客限界上下文。上下文中有文章,分类,评论等这些子域。
用户中心是另外的一个上下文,用户限界上下文,因为用户的概念太宽泛了。在博客服务中可能就是作者,读者。商城中可能就是买家卖家。所以在这种边界位置还是把用户中心归到一个单独的上下文去更好。
注意:界限上下文跟子域这些东西,不一定说一个子域或者一个上下文对应到一个微服务或项目,就算单体项目也能做DDD也能分出很多上下文和子域,重点是业务。落实到微服务的部署可能还要考虑技术的影响,例如尽量少的分布式事务,尽量少的RPC调用等。
上面也说了这篇文章就不过多讨论上下文,子域这些概念性了东西了。只是我们要知道这些东西可以帮助我们很好的去做模块划分,特别对现在的微服务很有用。但这些模块划分在我看来是需要丰富的行业经验的,就算是遵循了DDD的设计也是需要丰富的经验才能准确的去分辨业务边界。所以小编我就不献丑了。
领域模型建模
下图就是上面提到的几种业务的领域模型项目的项目目录结构。

ArticleAggreate(文章聚合)
对于文章的业务很明显是可以直接创建一个文章的聚合的,如Article.cs。
public class Article: AggregateRoot
{
private long _bloggerId;
private DateTime _createTime;
private DateTime? _updateTime;
private int _view;
private int _comment;
private int _like;
private List<CategoryAssociation> _categories;
//...更多其他字段
//...
//...
/// 上面的代码就是文章聚合的领域模型,所有的文章业务都在该领域模型中实现。可以看到实体类前面的数据字段声明跟经典的三层架构基本一样,只是有很多字段变成私有了(有一点要提一下,DDD中对领域模型的设计要求我们抛掉以前的数据库思维。从业务出发去思考如何对业务对象建模,然后才是数据库的表结构)。如果刚接触DDD的人看到代码可能会有很多疑问,下面我把当时我也有同样疑问的地方都解释一下吧。
在我看来把字段设为private在DDD中意义重大,意味着开始有点面向对象的味了,以前的经典三层架构其实业务代码只能叫做面向过程的流水账式的编程。当字段设置为私有的话那么Article类的调用者就无法直接通过简单赋值的方式来对数据进行直接操作。这时候我们就可以在Article类中暴露业务方法,在业务方法中去修改私有数据的值,这样的方式会大大提高数据的一致性。小编我对这点深有感触,做商城项目特别是订单,维权等等,状态非常的多,而随着业务越复杂,可能会在很多地方都存在修改订单状态的代码,这种直接改状态的很容易就会因为自己操心大意改错或者漏改。
注意到Article的默认构造函数是protected的,调用者是无法调用默认的构造函数创建的文章的,只能通过调用带参数的构造函数,而带参数的构造函数会根据形参初始化一个正确的文章对象,这一方面也是为了保证数据的一致性。
现在ORM框架很多都是支持私有字段的,所以在基础设施层的仓储实现中是不会有问题的,具体的仓储实现我会在第二篇基础设施层中详细说一下。
还有一个就是可以看到Article类继承AggregateRoot对象,表明Article是一个聚合根,待会我们就会看到在仓储接口的定义中我们会用AggregateRoot作泛型约束,只有继承AggregateRoot的对象才能被仓储增删查改。这么做的目的也是为了数据一致性。想象复杂一点的业务例如订单,订单肯定会有子订单,而且在数据库中这两个肯定是两个表结构的,而在领域建模的时候可以把订单建模为聚合根,子订单建模为普通的实体,而子订单的操作只能通过聚合根进行操作,在代码中就表现为在订单聚合根中有个子订单的List字段,那么这时候我们只需要维护聚合根,然后把聚合根更新到数据库就好了。
在Article类的代码中还有一个对象ArticleInfo,代码如下:
/// 可以看到上面的代码中ArticleInfo是实现IValueObject接口(接口是自己定义的非其他框架提供),该接口是一个空接口,作标记作用,标记为一个值对象。所以说ArticleInfo不是一个实体,而实一个值对象。DDD中对值对象的解释是没有唯一标识的,不可变的,固定的,但是这个值对象有时候又可以修改。所以这个概念我个人觉得挺模糊的,我也是凭自己的理解去用。我认为就是那些描述性的东西就能很好的表现为值对象,一旦创建了就不经常变动的,例如上面的文章标题,描述。或者最常用的一个例子就是收货地址。关于值对象的持久化,因为值对象没有唯一标识所以一般都是将值对象跟引用这个值对象的实体持久化到一张表去,需要配置一下字段名。也有分开两张表的方案,分开两张表的话就相当于还是会有一个隐式的外键。还有如果这个值对象是一个列表,就是一对多这种关系的话也有一些是序列化成JSON然后再跟实体放同一张表,这些方案小编目前也还没有尝试过,不过这也是基础设施层考虑的问题了。
在Article类中还有一个列表private List,其中CategoryAssociation是文章和分类的关联对象,因为文章和文章分类是多对多的关系,所以需要一个中间实体(表)来表示,代码如下(类继承Entity表明是一个实体,有唯一标识):
/// 同时在类中暴露一个该对象的只读列表public IReadOnlyList,只允许外部访问,不允许直接从外部修改。在ORM框架查询Article类的同时也会级联查询并填充_categories列表。_categories列表完全由Article聚合来维护,保证一致性。在编辑文章分类的时候把原本的列表清空,重新添加新的关联关系并持久化的数据库中。
Article类中其他的业务方法都比较简单就不一一解释了,都只是对状态或者属性进行修改而已。
CategoryAggreate(文章分类聚合)
分类聚合比较简单,只有创建,编辑,删除这些基本的操作,而且聚合也没有包含其他实体。聚合代码如下:
public class Category: AggregateRoot
{
/// 注意到上面分类聚合中的SetDefault()方法中发布了一个领域事件,因为业务规定为一个用户只能设置一个默认分类,所以当一个分类设置为默认的时候其他分类就需要取消默认分类的设置。这个场景就是通过在分类聚合里面发布一个设置默认分类的领域事件来实现的。你们可能会问AddDomainEvent()方法哪来的?等下我会详细讲解。
CommentAggreate(评论聚合)
下面是评论聚合的代码,业务也不复杂,很多注意的点都在上面说过了这里就不重复了:
public class Comment: AggregateRoot
{
private long _articleId;
public EntityStatusEnum Status { get; private set; }
/// 下面是值对象BloggerInfo的代码:
public class BloggerInfo : IValueObject
{
public long? UserId { get; private set; }
public string UserName { get; private set; }
public BloggerInfo() { }
public BloggerInfo(long? userId, string userName)
{
UserId = userId;
UserName = userName;
}
}
BloggerAggreate(博客用户聚合)
上面我也说过我们有一个用户中心,所以这里的博客用户是对于这个博客服务来说的用户,就是说一个用户可能在用户中心有一个账户,但是不一定在博客服务中有这个用户的记录。但是在博客服务中有他的记录那么在用户中心也一定会有。有点类似微信跟其他使用微信登陆的APP这种关系。
聚合代码如下:
public class Blogger: AggregateRoot
{
/// 领域对象仓储接口
还有一个要在领域模型层做的就是定义聚合的仓储接口,我上面说的领域层不应该依赖任何的仓储的实现。而仓储的接口是要在领域层中定义的,虽然理论上在基础设施层去定义仓储也是可以的,但是因为仓储操作的是聚合对象所以还是放在领域模型层会好点,再在基础设施层去实现每个聚合的仓储接口。
文章的博客服务有四个聚合对象所以我们需要定义四个仓储接口。
如下是文章聚合仓储:
public interface IArticleRepository : IAggregateRepository<Article, long>
{
IUnitOfWork UnitOfWork { get; }
}
上面的UnitOfWork属性是返回工作单元对象,这种模式有点类似事务完成所有的操作然后再一并提交到数据库(关于工作单元模式百度有很多了,就不一一讲解了)。
除了这个工作单元,剩下的就是那个IAggregateRepository接口了,该接口是我自定义的一个仓储基础接口,提供最基础的仓储功能,代码如下:
public interface IAggregateRepository<T,TKey> where T:IAggregateRoot
{
Task AddAsync(T o);
Task RemoveAsync(T o);
Task UpdateAsync(T o);
Task<T> GetByIdAsync(TKey id);
}
可以看到接口有泛型约束,只有实现了IAggregateRoot接口的对象才能够使用该仓储接口而该接口是一个空接口只作标记作用,这个基础的仓储接口提供了四个基础的方法,其实就是增删查改。如果某聚合需要一些不同功能的操作可以在对应的聚合仓储接口中增加。
评论聚合,博客用户聚合,文章聚合这三个聚合仓储接口都是直接继承IAggregateRepository接口,除了工作单元属性就没有添加其他的操作了。但是文章分类聚合不一样,还记得文章分类聚合有一个业务场景是设置默认分类吗?用户只能设置一个默认分类,所以需要把其他分类取消默认设置,所以这时候就需要在仓储上增加一个查询某用户的所有文章分类聚合的方法,如下:
public interface ICategoryRepository : IAggregateRepository<Category, long>
{
IUnitOfWork UnitOfWork { get; }
/// 所以聚合仓储的定义也是可以根据具体业务去定义的。
领域事件
我们来看一下文章分类设置默认分类的领域事件的定义:
public class SetDefaultCategoryEvent : IDomainEvent
{
public long CategoryId { get; private set; }
public SetDefaultCategoryEvent(long categoryId)
{
if (categoryId <= 0) throw new ArgumentException(nameof(categoryId));
CategoryId = categoryId;
}
}
可以看到这就是一个普通的类,只不过是实现了IDomainEvent接口,该接口是一个空接口为了标记领域事件的。其他的领域事件也是类似的定义,属性+构造函数的简单定义,主要就是为了传递参数给事件处理程序。
在上面四个聚合的代码中可能有留意到分类聚合的设置默认分类方法,和文章聚合的构造函数中有一个方法AddDomainEvent(),这个是添加领域事件的。具体实现是怎样的呢,可以看到每个聚合类都继承了一个AggregateRoot,类如下:
public class AggregateRoot : SnowFlakeEntity, IAggregateRoot
{
private List<IDomainEvent> _domainEvents;
public IReadOnlyList<IDomainEvent> DomainEvents => _domainEvents;
/// 该类实现IAggregateRoot接口,继承SnowFlakeEntity类,所以该类是一个聚合也是一个实体。而在仓储中也提到了该接口是空接口只是为了说明实现它的类是聚合并无实际用处。SnowFlakeEntity中只包含一个Id属性和一个生成Id的雪花算法。
在上面的代码中我们就可以看到AddDomainEvent()了,而且还有RemoveDomainEvent()。实现上面也很简单,只是把实现了IDomainEvent接口的领域事件添加到一个私有的事件列表里面。这就是在领域模型层中领域事件的全部了,你可能会想那事件的发布呢,消费呢???还记得上面仓储提到的工作单元吗,领域事件中事件的发布就是在工作单元提交到数据库之前遍历领域模型的事件列表,一个一个的发布,消费,都成功后最后再提交到所有更改到数据库。目前在博客服务项目中都是进程内的发布订阅,所以可以用中介者模式来做进程内的发布订阅。如果是跨进程的就需要用到MQ中间件了,这其中可能也会包含分布式事务等这些技术细节。
所以分布式事务使用的多少跟模块划分还是关系很大的
领域服务
接下来说一下领域服务,在《实现领域驱动设计》一书中说到当一个操作不适合放在聚合或者值对象中的时候就可以放在领域服务中去。领域服务就像以前的经典三层模型中的服务层,所以说在DDD中是不应该过多的使用领域服务,大部分的业务都应该在领域模型中实现,过多的领域服务会就会慢慢演变成以前的贫血模型了。
在这里的博客服务中有一个使用领域服务的例子,考虑下面一个需求,创建文章的时候如果作者没有建文章分类,那么就会创建一个默认的文章分类,然后新建的文章放在该默认分类下。以上需求放在文章聚合或者文章分类聚合都是一个不太好的选择,所以这种情况下就干脆放在领域服务下,代码如下:
public class ArticleDomainService
{
private readonly IArticleRepository _articleRepository;
private readonly ICategoryRepository _categoryRepository;
private readonly IBloggerRepository _bloggerRepository;
private IUnitOfWork UnitOfWork => _articleRepository.UnitOfWork;
public ArticleDomainService(
IArticleRepository articleRepository,
ICategoryRepository categoryRepository,
IBloggerRepository bloggerRepository)
{
_articleRepository = articleRepository;
_categoryRepository = categoryRepository;
_bloggerRepository = bloggerRepository;
}
public async Task<Article> CreateArticleNoCategory(long userId, string title, string desc, string content)
{
var blogger = await _bloggerRepository.GetByIdAsync(userId);
if(blogger == null)
{
return null;
}
var category = await _categoryRepository.QueryUserDefaultCategoryAsync(userId);
if (category == null)
{
category = new Category(userId, "默认分类");
category.SetDefault();
await _categoryRepository.AddAsync(category);
}
var article = new Article(userId, title, desc, content, new List<Category>
{
category
});
await _articleRepository.AddAsync(article);
await UnitOfWork.SaveChangesAsync();
return article;
}
}
可以看到上面判断作者是否有默认的分类,没有则创建一个默认的。并且创建的文章关联该分类。
上面的领域服务我并没有按往常一样先定义一个服务接口,而是直接写一个服务实现类。我个人观点是接口是为了在多实现中提供一个公共的接口抽象,而很多时候我们的业务逻辑都不需要多实现的,在工作中也是往往都不会对一个服务写多个实现,所以这里我就直接去掉了服务接口了。
关于领域服务在哪个层实现,我这里是在领域层去实现领域服务,因为领域层同时也定义的仓储的接口所以在领域层中实现领域服务,而领域服务通过依赖注入注入仓储的接口是没有问题的,而且因为包含领域业务逻辑所以我就放在了领域层了。更多的人可能会把领域服务放在应用层。不过目前这个感觉区别不大。
对于领域服务还有一点需要注意的就是领域服务和应用服务需要区分好,领域服务会包含更多的领域业务逻辑,而如果只是简单的协调每个聚合的调用调度的话就更应该使用应用服务。过多的领域服务会把框架变成以前的贫血模型,业务散布到项目的各处,难以维护。
领域对象怎么做查询,分页,筛选
最后一个我想要来讨论一下的就是这个领域模型(聚合)的查询,不知道大家有没有这个困惑,反正小编我刚开始接触DDD的时候就觉得很疑惑。思考一下既然我们使用领域模型来表示一下系统的业务对象,例如上面的文章聚合,文章聚合里面还有一个分类关联的列表。那么如果我现在只想要查询文章的基础信息,我不想要那些多余的什么分类关联,而且如果是查列表,分页的话如果每个文章对象都需要加载一个分类关联的列表那么性能也是肯定会有影响的。而且如果需要在领域模型中做复杂的筛选操作的话也是缺少灵活性,对应的聚合仓储的接口也会变得臃肿。
上面的这些问题都可以用CQRS模式解决,概念性的东西就不多说了,网上大把。其实这个就是读写分离,但是不同于我们平常理解的读写分离,我们平常数据库中的读写分离更多的是物理上的分离,而CQRS是数据模型的分离。领域模型(聚合)作用于业务对象的增,删,改,领域模型能很好的保证业务对象的一致性,完整性的约束。而查的部分则使用另外的一套模型,可以使用轻量级的ORM框架,查询的数据模型更多的是Dto(数据传输对象)这种贫血的模型给前端提供视图接口,因为查询是不会对数据产生任何影响,操作都是幂等的,所以一些ORM框架可以直接编写SQL查询进行各种连表,条件,排序等直接操作数据库表从而可以实现复杂查询。
所以可以看到上面项目中的几个聚合仓储接口都是没有列表查询,或者一些复杂查询的方法的,因为领域模型只用来对数据进行增,删,改的时候才使用领域模型来保证业务对象的数据一致性,完整性。而列表分页查询等则是在另一套模型中实现(在应用层中实现)。
总结
这篇文章就到这里了,文章主要是针对自己的个人项目的DDD的领域层改造过程中的一些点进行了总结和分享吧,下一篇文章中将主要讲一下第二层,基础设施层的具体实现。
下面是个人公众号,经常更新是不可能经常更新的,只有有空的时候写写才维持得了生活这样子。
