SpringCloud Alibaba(四) Nacos服务端本地启动和源码浅析(AP架构),Distro协议介绍,CAP原则介绍
前一章 SpringCloud Alibaba(三) Nacos 客户端源码浅析(AP架构),我们学习了Nacos的客户端,我们知道了客户端会调用服务端的接口,包括注册到注册中心,心跳保活,拉取服务列表.这一章我们来看一下Nacos服务端,也是基于Nacos1.4.1(21年初)版本,尽管现在已经出了2.0版本,他们之间最大的改变是1.X的Http请求,2.X使用的是grpc,但是市面上用得最多的仍然是1.X版本,我们只需要学会他的思想 ,万变不离其宗.Spring Cloud版本为Hoxton.SR8,Spring Cloud Alibaba版本为2.2.5.RELEASE.
1. 基础知识
1.1 CAP原则
CAP定理: 指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得
- 一致性(C):所有节点都可以访问到最新的数据,这里的一致性指强一致性
- 可用性(A):每个请求都是可以得到响应的,不管请求是成功还是失败
- 分区容错性(P):除了全部整体网络故障,其他故障都不能导致整个系统不可用
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡
所谓的一致性并不是指集群中所有节点在任一时刻的状态必须完全一致,而是指一个目标,即让一个分布式系统看起来只有一个数据副本,并且读写操作都是原子的,这样应用层就可以忽略系统底层多个数据副本间的同步问题。也就是说,我们可以将一个强一致性(线性一致性)分布式系统当成一个整体,一旦某个客户端成功的执行了写操作,那么所有客户端都一定能读出刚刚写入的值。即使发生网络分区故障,或者少部分节点发生异常,整个集群依然能够像单机一样提供服务。
CA: 如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的 CP: 如果不要求A(可用),每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统 AP:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。Nacos集群同步数据即可以有AP模式也可以有CP模式
CA模式:单机的mysql
CP模式:Nacos,Zookeeper(选取leader的时候,集群对外是不可用的)
AP模式:Nacos,Eureka
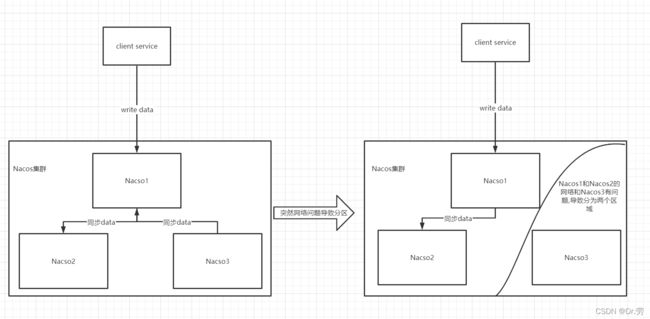
下面我们来看一下为什么分布式环境下CA是冲突的.下图左有Nacos1,Nacos2,Nacos3,3个节点组成的Nacos集群(注册中心集群),我们的client写data到集群,他会先写到Nacos1,Nacos1会把data同步到Nacos2和Nacos3,同步完成才返回给客户端说写入data成功,这样即使我们的client去每一个节点读数据,都是能读到一样的数据,如果有一个节点没成功,则报错,这样是不是可以满足我们的C,一致性.
突然由于网络的问题Nacos1和Nacos2节点是可以正常通信,但是Nacos3却不可以和他们两个节点通信,这个时候就产生了2个区域.产生分区的时候,如果整个集群不可用,那你这个集群太脆弱了,一点网络问题就会导致集群不可以用,所以分布式系统一定需要满足P,即使发生部分分区,仍然可以对外进行服务.
假设现在发生了分区,为了保证可用性A,那我的客户端写入data的时候,不可能写到Nacos3节点,因为网络不通畅,即使写入了Nacos1也同步不过去Nacos3,所以整个集群保证不了一致性C,只有等网络恢复,我们的Nacos3再去Nacos1拉取数据,达到最终一致.如果你硬要保持一致性C,那只能整个集群不能对外提供服务,等Nacos3恢复网络,再提供服务,这和我们的可用性A产生冲突.
所以我们得出结论,在分布式存储环境下,CA是有冲突的.
1.1.1脑裂
- 是指在多机房(网络分区)部署中,若出现网络连接问题,形成多个分区,则可能出现脑裂问题,会导致数据不一致。
- 以下图为例(Nacos CP模式),假设我的Nacos1,Nacos2,Nacos3是一个集群,CP模式下,会有一个主节点,假设Nacos1是leader(领导,集群的大脑),他负责写数据以及同步数据到Nacos2,3.现在发生了分区,Nacos3被独立出来了,这个时候Nacos3发现我自己变成一个区域了,这个区域还没有leader,然后把自己选为了leader,这就是脑裂.
- .这个时候Nacos1和Nacos3都是leader.我们假设这个时候client可以往Nacos1和Nacos3两个集群写数据(Nacos1集群和Nacos3集群网络是不通的),那他一会写1一会写3,就会造成整个集群数据不一致,网络恢复的时候数据要怎么解决冲突呢?
- 网络恢复的时候已经分不清哪些数据的变化,如果强行合并显然这不是一个很好的方法,所以Nacos(cp)和zookeeper会有一个过半选举机制,当Nacos3想把自己选为leader的时候,需要得到半数以上节点的投票,现在集群3个节点,需要得到2票他才可以选自己为leader,这个时候分区了,显然Nacos3是不可能得到2票的,这个时候我们的Nacos3不应该对外提供服务,直到网络恢复,然后Nacos3去Nacos1主节点,把最新的数据给拉下来.
- 那么假设Nacos1(主节点)网络不通畅分区了,Nacos2,3选举,Nacos2变成leader,那么现在集群有个节点对外服务,一个是Nacos1,一个Nacos2,如果两个主节点都能写的话,那么等Nacos1网络恢复,两个节点数据不就乱套了,所以我们写数据的时候,需要同步到n/2+1节点,才能算成功,即我有半数节点都是正常的,你才是正常的leader.否则你就写入失败.在这个场景下Nacos1写数据铁定失败,只有Nacos2可以写.
1.1.3 为什么推荐注册中心使用AP模式
我们思考一下为什么推荐用AP模式来作为注册中心,CP模式主要实现的注册中心有zookeeper,consul,为什么叫他们为CP模式的实现,他们也有集群,也是高可用的为什么没有A?
- 记住一句话,只要高可用,必定需要副本,数据同步必定要通过网络请求,有网络请求必然会产生分区,所以所有中间件都会实现P,世界上没有完美的强一致,就算你同步也会有延迟,所以分区是一个必然事件.
- 那么zookeeper和consul他们用的一致性协议是raft和zab,他们最大的特点是有一个leader节点来负责数据的写入,然后再同步给从节点,半数从节点返回成功,我们才返回给客户端写入成功.假设leader宕机了,他们需要在从节点重新进行选举出新的leader,选举过程中对外是不提供服务的,并且选举完之后,他需要通过一致性协议同步数据保证集群数据的一致性,这都需要时间所以是CP模式.
- 而我们注册中心最需要的是高可用,一段时间内数据不一致是可以容忍的,而AP模式会通过不断重试或者定时任务来使整个集群数据达到最终一致,任意一个节点宕机了,不影响我整个集群的可用性.
1.2 BASE理论
什么是Base理论
- CAP 中的一致性和可用性进行一个权衡的结果,核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性, 来自 ebay 的架构师提出,就是CA两个特性的权衡.
-
Basically Available(基本可用)
- 假设系统,出现了不可预知的故障,但还是能用, 可能会有性能或者功能上的影响
-
Soft state(软状态)
- 允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时
-
Eventually consistent(最终一致性)
- 系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值
- 以上图为例client写数据data到Nacos1的时候我不再需要等数据同步完成到Nacos2,3再返回成功了,即使写入Nacos2,3失败了也不影响,所以1和2,3的数据会有延迟或者这个时候集群的节点里面数据可能不一致,这就是软状态,但是最终会一致.就算2,3节点挂了,我1节点仍然可用这就是基本可用,并且2,3节点恢复之后,我可以把数据同步回来,达到最终一致.
- 他牺牲了强一致性来获得可用性,并且最终一致.
总结
在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。
总结:如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。
1.3 Distro协议
作为注册中心,P要保证,C和A需要权衡;常见的一致性协议有paxos、zab、raft,他们都是强一致性协议(CP),然而nacos的distro协议时弱一致协议(AP),即最终一致性协议.
当然nacos也使用了raft实现了CP模式,但是作为注册中心,可用性比一致性更重要,所以CP模式很少用,我可以允许他暂时不一致,但是最终一致.这里推荐文章阿里巴巴为什么不用 ZooKeeper 做服务发现?
总结来说Distro协议是一个让集群中数据达到最终一致的一个协议,他是Nacos AP模式下每个节点直接同步数据的一个协议,规范.
1.4 Nacos AP/CP的配套一致性协议
需要回顾 Nacos 中的两个概念:临时服务和持久化服务。
- 临时服务(Ephemeral):临时服务健康检查失败后会从列表中删除,常用于服务注册发现场景。
- 持久化服务(Persistent):持久化服务健康检查失败后会被标记成不健康,常用于 DNS 场景。
两种模式使用的是不同的一致性协议:
- 临时服务使用的是 Nacos 为服务注册发现场景定制化的私有协议 distro,其一致性模型是 AP;
- 而持久化服务使用的是 raft 协议,其一致性模型是 CP。
配置文件配置是否临时实例,默认不写为true
spring:
application:
name: mall-order #微服务名称
#配置nacos注册中心地址
cloud:
nacos:
discovery:
server-addr: 120.77.213.111:8848
#group: mall-order
cluster-name: SH
ephemeral: true
我们可以看到Nacos可以同时支持AP和CP两种模式,我同一个集群里,既可以有临时实例,也可以有持久化实例,而且持久化实例即使不在线,也不会删除
如果是临时实例,则instance不会在 Nacos 服务端持久化存储,需要通过上报心跳的方式进行包活,如果instance一段时间内没有上报心跳,则会被 Nacos 服务端摘除。在被摘除后如果又开始上报心跳,则会重新将这个实例注册。
持久化实例则会持久化被 Nacos 服务端,此时即使注册实例的客户端进程不在,这个实例也不会从服务端删除,只会将健康状态设为不健康。
同一个服务下可以同时有临时实例和持久化实例,这意味着当这服务的所有实例进程不在时,会有部分实例从服务上摘除,剩下的实例则会保留在服务下。

2.Nacos服务端介绍
2.1AP模式下的distro 协议
distro 协议的工作流程如下:
- Nacos 启动时首先从其他远程节点同步全部数据。
- Nacos 每个节点是平等的都可以处理写入请求,同时把新数据同步到其他节点。
- 每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据一致性。
- 当该节点接收到属于该节点负责的服务时,直接写入。
- 当该节点接收到不属于该节点负责的服务时,将在集群内部路由,转发给对应的节点,从而完成写入。
- 读取操作则不需要路由,因为集群中的各个节点会同步服务状态,每个节点都会有一份最新的服务数据。
- 而当节点发生宕机后,原本该节点负责的一部分服务的写入任务会转移到其他节点,从而保证 Nacos 集群整体的可用性。
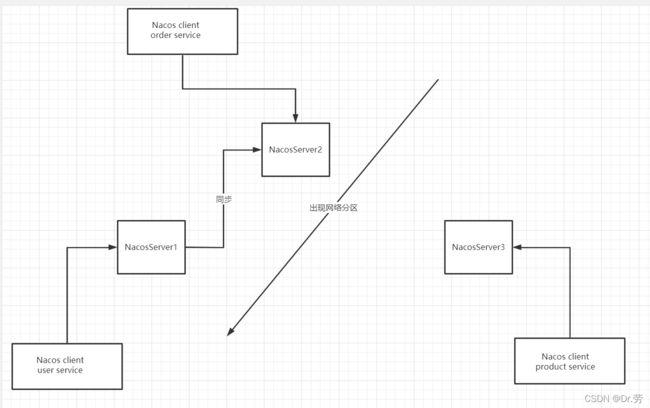
如下图,每个order服务可以向任意一个NacosServer发起注册,Nacos服务端集群每个节点都是平等的.
例如我的orderService注册到NacosServer2,然后他先到会到Server2的DistroFilter,通过distroHash(serviceName) % servers.size()哈希当前的服务名取模计算出当前的orderService属于哪个节点,假如计算出属于NacosServer1,则会路由到NacosServer1去注册,NacosServer1注册完之后他会同步到NacosServer2,3,假如这个时候同步失败了,会不断重试,直到成功或者NacosServer2,3节点不存在了就结束.

假设现在出现了分区,AP模式的话不存在主节点的概念,虽然NacosAP和CP可以共存,如果是临时节点的情况下是不会触发raft协议同步数据只会用distro协议去作为集群的数据,达到最终一致,但是服务端同步数据只能AP或者CP.所以AP模式下不存在脑裂问题,加速如下图,出现了分区,这个情况会损害可用性,这个时候因为客户端可以从任意一个节点拉取数据并且缓存下来,客户端会表现为有时候服务存在有时候服务不存在,等网络恢复了,集群之间又开始同步数据达到最终一致.
2.2 Distro协议中主要概念:
- Memer: 在Nacos-Server启动时,会在cluster.conf中配置整个集群列表,其作用是让每个节点都知道集群中的所有节点,该列表中的每一个节点都抽象成一个Member
- MemberInfoReportTask: 在Nacos-Server启动成功后,会定时给除自己之外的其他Member进行通信,检测其他节点是否还存活。如果通信失败,会将该Member状态置为不健康的,如果后续和该节点重新通信成功,会将该节点的状态置为健康,该Task与Responser的计算密切相关
- Responser(对应下面5.1的distroMapper选择节点): 对于每一个服务(比如:com.ly.OrderService)来说,在Nacos-Server集群中都会有一个专门的节点来负责。比如集群中有三个健康节点,这三个节点的IP:Port就是组成一个长度为3的List
,对三个节点的IP:Port组成的addressList进行排序,这样在每一个节点中,addressList的顺序都是一致的。这时com.ly.OrderService服务注册上来,会根据服务名计算对应的hash值,然后对集群的节点数取余获得下标,从addressList中获取对应的IP:Port,这时这个IP:Port对应的节点就是该服务的Responser,负责该服务的健康检查,数据同步,心跳维持,服务注册。如果客户端服务注册请求到了某个节点,但是本次注册的服务不是由该节点负责,会将该请求重定向到responser的节点去进行处理。注意: 这里的addressList是健康节点,一旦某个节点宕机或者网络发生故障,该节点会从addressList中移除,Service对应的Responser会发生变化。 - HealthChecker: 对于每一个服务,都有一个HealthCheck去对其中的实例进行检测,检测的原则就是该实例最近上报心跳的时间与当前时间的时间差是否超过阈值,如果超过阈值,需要将该实例从服务中摘除。HealthCheck在检测时,也会去进行Responser的检查,只有自己是当前服务的Responser,才会去进行检测。
- DistroTask: 由于Responser规则的存在,对于某一个服务来说,只会有一个node来进行负责,那么其他的node是如何感知到非responser节点的服务数据的呢。DistroTask就是做数据同步的,对当前自己持有的所有服务进行检测,只要有是自己response的,就把该服务的实例数据同步给其他node。这里就有一个优化点,在同步数据时,并不是把该服务下所有的实例全部同步给其他节点,而是对该服务当前所有实例计算一个checksum值(减少传输的数据量,而且一般来说,实例变动是不频繁的)同步到其他节点。其他节点收到数据后,首先会检查同步过来的服务是否是由远端负责,如果是,比对自己节点中该服务的checksum值和远端的是否一致,如果不一致,请求远端节点获取最新的实例数据,再更新本地数据。
- LoadDataTask: 在节点刚启动时,会主动向其他节点拉取一次全量的数据,来让当前节点和整个集群中的数据快速保持一致。
2.2Nacos注册中心是什么.
还记得我们在SpringCloud Alibaba(一) Nacos注册中心快速入门,我们启动nacos的时候是执行了一个脚本.
里面执行的命令启动了target下面的一个jar
然后看到jar里面的MANIFEST.MF文件,看到启动类是com.alibaba.nacos.Nacos
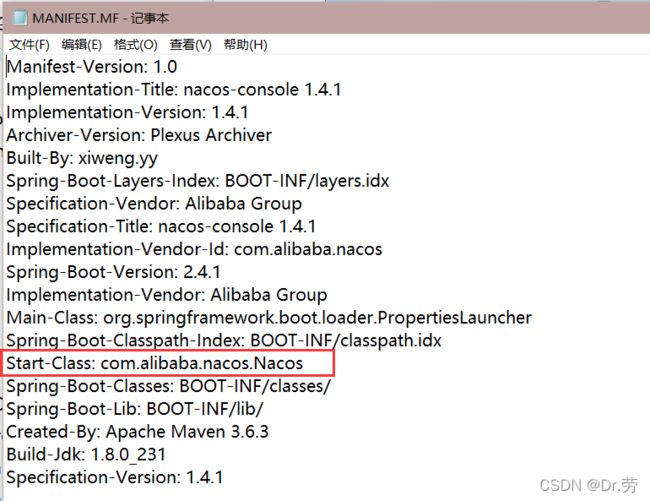
我们来到com.alibaba.nacos.Nacos,发现他本质上是一个web服务.
2.3Nacos服务端源码下载
- idea去https://github.com/alibaba/nacos.git,把源码拉取下来.
- git checkout tag or revision,输入1.4.1
2.4本地启动Nacos服务端源码
2.4.1 编译nacos-consistency
因为会提示有几个类缺失,是因为这个包目录是由protobuf在编译时自动生成
可以通过mvn compile来自动生成他们。如果使用的是IDEA,也可以使用IDEA的protobuf插件
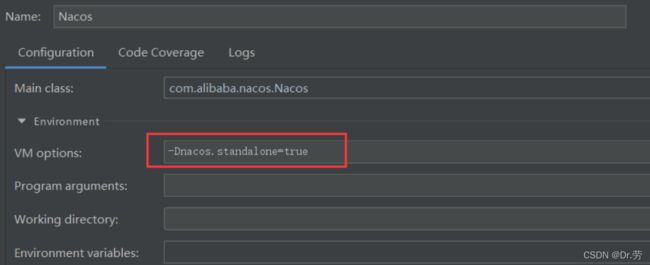
2.4.2单机启动
直接运行console模块里的 com.alibaba.nacos.Nacos.ja va并且增加启动vm参数
-Dnacos.standalone=true
2.4.3集群启动
nacos集群需要配置mysql存储,需要先创建一个数据,名字随便取,然后执行 distribution/conf 目录下的 nacos-mysql.sql 脚本,
然后修改 console\src\main\resources 目录下的 application.properties 文件里的mysql配置.
### If use MySQL as datasource:
spring.datasource.platform=mysql
### Count of DB:
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoRecon
nect=true&useUnicode=true&useSSL=false&serverTimezone=UTCdb.user.0=root
db.password.0=roo
运行console模块里的 com.alibaba.nacos.Nacos.java,需要增加启动vm参数端口号和实例运行路径nacos.home(对应的目录需要自己提前创建好),每台server的nacos.home目录里需要创建一个conf文件夹,里面放一个cluster.conf文件,文件里需要把所有集群机器ip和端口写入进去
最后在idea的service里面进行配置


3.源码分析
3.1如何看源码
我们第一次看源码,最好的是看静态源码,不要debug,而且第一次看只看主流程,不要进去细枝末节去琢磨,看到if return这些代码一般可以过掉,实现类不知道是哪个可以根据上下文推测,不行就打断点.
源码分析前我在Nacos github看到的https://github.com/alibaba/nacos/issues/7264,我觉得这对我们看代码和平常的设计会有很大的启发,Nacos源码里面大量用了异步和事件化机制,去提高吞吐量,并且解耦.

3.2Nacos服务列表结构
我们在SpringCloud Alibaba(三) Nacos 客户端源码浅析(AP架构)_Dr.劳的博客-CSDN博客,看到了客户端调用了Nacos服务端几个接口,官网NacosOpen API 指南
- POST /v1/ns/instance 注册实例
- PUT /v1/ns/instance/beat 心跳保活
- GET /v1/ns/instance/list 获取服务列表 获取我们的ServiceMap里面的数据
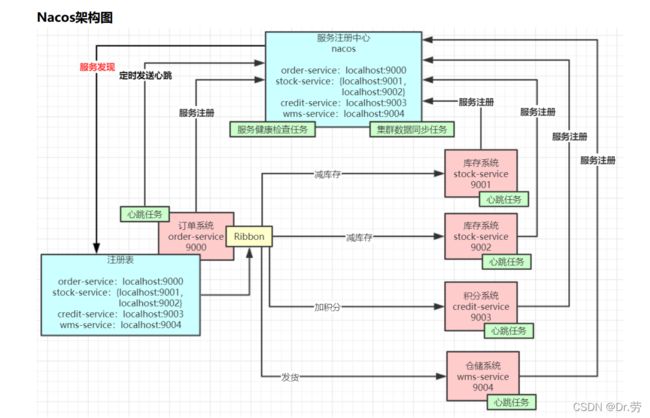
这里我们提前说一下,服务端保存的服务列表是一个Map结构ServiceMap

- Map
- Service里面有一个Map
- Cluster里面有两个集合Set
persistentInstances,持久化集合,临时实例集合Set ephemeralInstances. - Instance里面存储的是这个节点的属性,ip,port,lastHeatbeat,等等属性
3.3 POST /v1/ns/instance 注册实例(AP模式,临时实例)
我们找到他是一个register方法,调用了SeriveManager#registerInstance,并且客户端注册过来的serviceName会带有group的拼接
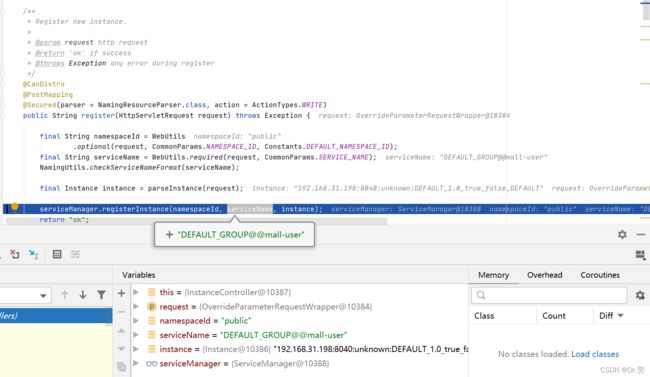
3.3.1 ServiceManager#registerInstance
首先创建了一个空的Service存储到ServiceMap里面,然后调用addInstance

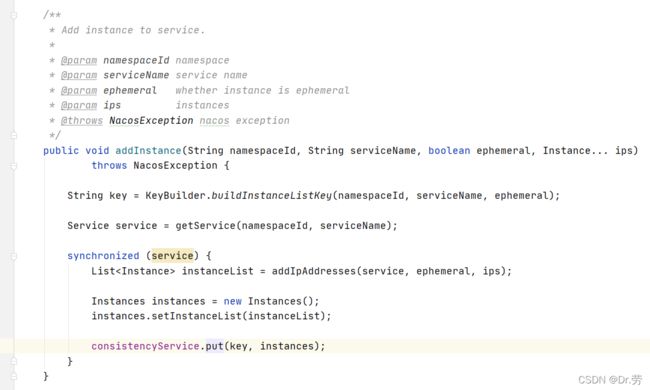
3.3.2 SeriveManager#addInstance
这里的buildInstanceListKey他会根据是否临时实例,拼接一个新的key,客户端默认是ap模式注册+
- 临时实例:com.alibaba.nacos.naming.iplist.ephemeral.public##DEFAULT_GROUP@@mall-user
- 持久化实例com.alibaba.nacos.naming.iplist.public##DEFAULT_GROUP@@mall-user
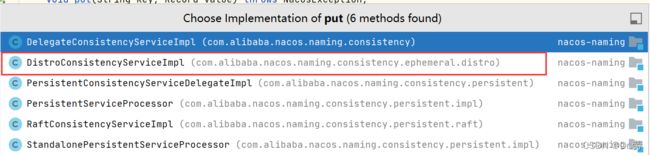
3.3.3 DistroConsistencyServiceImpl#put
因为我们讲的AP架构所以肯定进的Distro,如果不知道可以打断点.这个方法做了两件事
-
onput方法,注册实例
-
sync方法,将注册完的实例同步到其他Nacos集群的节点

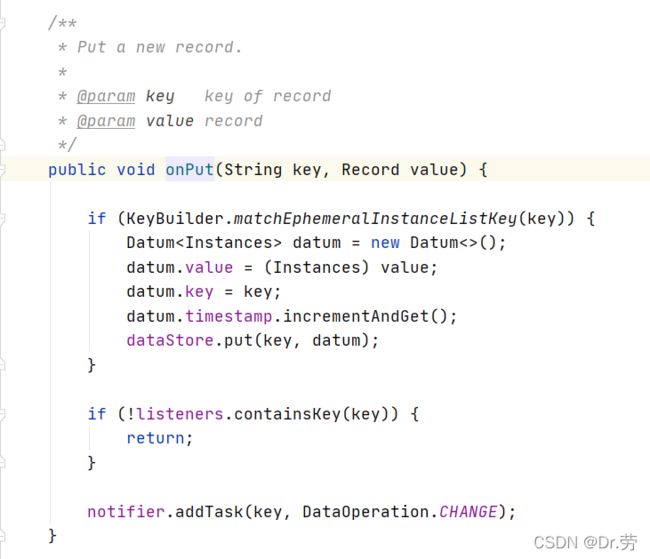
而put方法他只是封装了一个datum放进dataStore,dataStore是Nacos用来缓存客户端节点数据,并且往一个map里面put了一下,然后addTask,他只做了一件事,把这个key放进一个BlockingQueue,方法结束,然后直接返回给客户端注册成功,很明显他是异步执行的.我们应该看task的run方法做了什么.
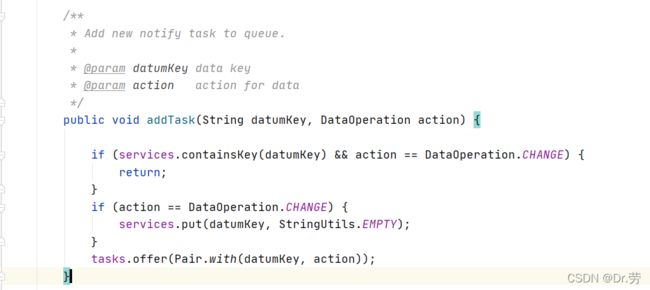
3.3.4 DistroConsistencyServiceImpl#run
死循环从阻塞队列获任务并且执行DistroConsistencyServiceImplhandler,注意他是单线程的,就算并发他也是单线程去执行完一个任务再到下一个.

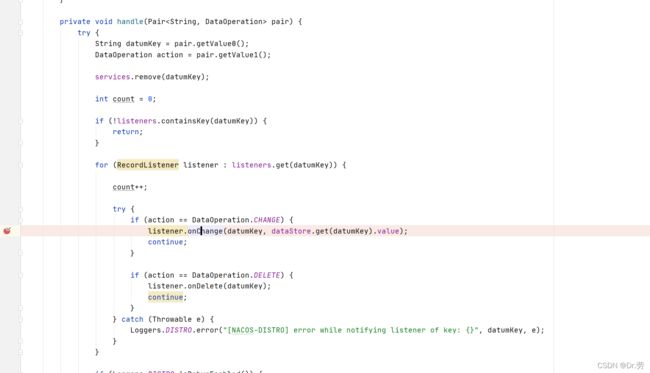
3.3.5 DistroConsistencyServiceImpl#handler
这里发现会根据action调用onChange或者onDelete,我们猜测,有注册,肯定就有删除注册实例的方法.
3.3.6 Service#updateIps
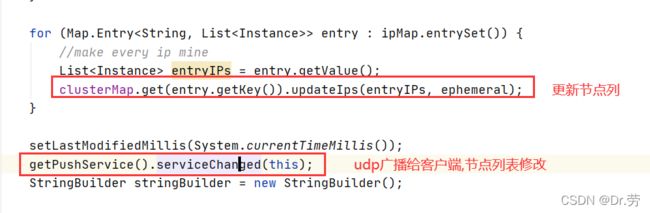
上面的onChange会调用到Service#onChange,这里有一个关键的方法updateIps

Service#updateIps重点方法在于clusterMap.get(entry.getKey()).updateIPs(entryIPs, ephemeral),去更新我们的ServiceMap,并且使用udp推送给其他服务,告诉我们的客户端节点,我更新了服务列表.
/**
* Update instances.
*
* @param instances instances
* @param ephemeral whether is ephemeral instance
*/
public void updateIPs(Collection instances, boolean ephemeral) {
// 创建一个临时的服务对应的map。
Map> ipMap = new HashMap<>(clusterMap.size());
for (String clusterName : clusterMap.keySet()) {
ipMap.put(clusterName, new ArrayList<>());
}
// 遍历instance列表
for (Instance instance : instances) {
try {
if (instance == null) {
Loggers.SRV_LOG.error("[NACOS-DOM] received malformed ip: null");
continue;
}
// 设置cluster名称
if (StringUtils.isEmpty(instance.getClusterName())) {
instance.setClusterName(UtilsAndCommons.DEFAULT_CLUSTER_NAME);
}
// 创建一个空的Cluster,设置到clusterMap中
if (!clusterMap.containsKey(instance.getClusterName())) {
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
Cluster cluster = new Cluster(instance.getClusterName(), this);
cluster.init();
getClusterMap().put(instance.getClusterName(), cluster);
}
List clusterIPs = ipMap.get(instance.getClusterName());
if (clusterIPs == null) {
clusterIPs = new LinkedList<>();
ipMap.put(instance.getClusterName(), clusterIPs);
}
// 将instance添加到ipMap中此instance对应的clustername位置上
clusterIPs.add(instance);
} catch (Exception e) {
Loggers.SRV_LOG.error("[NACOS-DOM] failed to process ip: " + instance, e);
}
}
// 遍历ipMap,,从clusterMap获取节点包含了老的和最新的Instance。将instance对应的cluster更新到clusterMap中。
for (Map.Entry> entry : ipMap.entrySet()) {
//make every ip mine
List entryIPs = entry.getValue();
// 真正的更新服务列表
clusterMap.get(entry.getKey()).updateIps(entryIPs, ephemeral);
}
setLastModifiedMillis(System.currentTimeMillis());
// 服务列表更新了,发生变化,发布推送事件,触发服务端向客户端的推送任务
getPushService().serviceChanged(this);
StringBuilder stringBuilder = new StringBuilder();
for (Instance instance : allIPs()) {
stringBuilder.append(instance.toIpAddr()).append("_").append(instance.isHealthy()).append(",");
}
Loggers.EVT_LOG.info("[IP-UPDATED] namespace: {}, service: {}, ips: {}", getNamespaceId(), getName(),
stringBuilder.toString());
} 3.3.7 Cluster#updateIps CopyOnWrite机制
上面的Service#UpdateIps会调用到Cluster#updateIps,这个方法其实最终就是更新我们ServiceMap(服务列表)里面的Set
如果我们直接修改ephemeralInstances,他里面的Instance对象状态会不断的变化,这里用了写时复制的思想,先写到一个临时变量,修改为最终版的时候,最后再替换我们原来的变量.但是我们同一个实例很多客户端同一时间注册的时候,不就乱套了吗?复制了多个临时变量一直在覆盖,客户端集群同一时间多个机器如果这个时候获取了这个ephemeralInstances,会里面的Instance不就变来变去.
- 首先我们上面说了阻塞队列获取任务是单线程的所以同一个服务多个实例注册过来不会同时修改我们的ephemeralInstances,就算不同的服务注册进来,也只会单线程的修改.
- 那么我们修改ephemeralInstances的时候直接加一把锁不就好了吗,修改的时候客户端就不能获取,这样我们服务端获取的时候都是一致的.那这不是就降低了我们并发.但是这里的代码避开了加锁这个问题.他在修改的时候,先将老的ephemeralInstances数据赋值给我们的一个oldMap,这个ips里面有我们所有的最新的Instance,然后和我们的oldMap去做比较,如果是新增的节点就添加进oldMap,如果是删除节点就删除oldMap的节点,如果是修改节点状态,就new一个新Instance的对象替换我们的oldMap里面的对象.直到修改完成最后返回修改完后的ips,然后直接替换ephemeralInstances.这样我们就可以不用加锁,然后修改的时候也不会影响客户端,导致我一个order client的集群,同一时间去拉取我们的服务列表ServiceMap,然后服务列表的状态不一致的问题.
/**
* Update instance list.
*
* @param ips instance list
* @param ephemeral whether these instances are ephemeral
*/
//ips这个参数包含了当前Nacos内存里面当前节点的所有Instance,包含我新注册的
public void updateIps(List ips, boolean ephemeral) {
Set toUpdateInstances = ephemeral ? ephemeralInstances : persistentInstances;
HashMap oldIpMap = new HashMap<>(toUpdateInstances.size());
for (Instance ip : toUpdateInstances) {
oldIpMap.put(ip.getDatumKey(), ip);
}
List updatedIPs = updatedIps(ips, oldIpMap.values());
...省略代码,这里省略的代码为更新我们的ips
toUpdateInstances = new HashSet<>(ips);
if (ephemeral) {
ephemeralInstances = toUpdateInstances;
} else {
persistentInstances = toUpdateInstances;
}
} 3.3.8PushService#udpPush
更新完节点列表会触发一个ServiceChangeEvent事件,Spring会执行对应的onApplicationEvent方法,最后会触发PushService#udpPush,这个方法就是异步upd通知Nacos客户端,推送失败会重复一定次数,我新注册了一个client.这样客户端就不需要等到15秒定时拉取,也能知道服务列表有改变.
Nacos的这种推送模式 比起ZK的TCP方式来说 节约了资源,增强了效率 Client收到Server的消息之后 会给Server一个ACK,如果一定时间内Server没有接收到ACK,会进行重发 当超过重发之后,不再重发 尽管UDP会丢包,但是仍然有定时任务的轮训兜底 不怕丢了数据
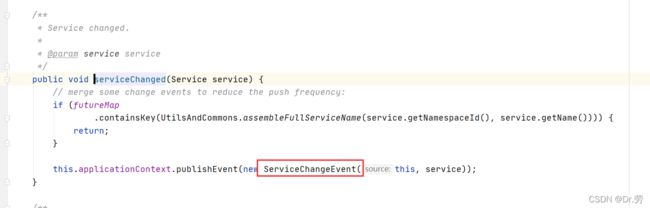
//ServiceChangeEvent会触发这个方法
@Override
public void onApplicationEvent(ServiceChangeEvent event) {
Service service = event.getService();
String serviceName = service.getName();
String namespaceId = service.getNamespaceId();
Future future = GlobalExecutor.scheduleUdpSender(() -> {
try {
Loggers.PUSH.info(serviceName + " is changed, add it to push queue.");
//获取需要推送的client
ConcurrentMap clients = clientMap
.get(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName));
Map cache = new HashMap<>(16);
long lastRefTime = System.nanoTime();
for (PushClient client : clients.values()) {
if (client.zombie()) {
Loggers.PUSH.debug("client is zombie: " + client.toString());
clients.remove(client.toString());
Loggers.PUSH.debug("client is zombie: " + client.toString());
continue;
}
Receiver.AckEntry ackEntry;
Loggers.PUSH.debug("push serviceName: {} to client: {}", serviceName, client.toString());
String key = getPushCacheKey(serviceName, client.getIp(), client.getAgent());
//省略代码
//for循环推送给对应的服务
udpPush(ackEntry);
}
} catch (Exception e) {
Loggers.PUSH.error("[NACOS-PUSH] failed to push serviceName: {} to client, error: {}", serviceName, e);
} finally {
futureMap.remove(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName));
}
}, 1000, TimeUnit.MILLISECONDS);
futureMap.put(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName), future);
} 3.4 distroProtocol#sync---Nacos集群同步新增的节点
上面我们看到的实际逻辑就是直接往队列里面放一个任务,然后异步修改了ServiceMap,那么修改完,我Nacos是一个集群啊,我其他Nacos节点怎么同步你当前节点的数据呢?所以我们看回之前的put方法,他的distroProtocol#sync方法就是为了集群同步新增节点数据.
- sync方法首先去MemberManager去找到所有的Nacos服务端节点,然后排除掉自己,因为自己已经修改了ServiceMap
- 新增同步节点延时任务
- 由于这里连续调用了两个线程池执行异步任务最终会调用到DistroSyncChangeTask,中间找的地方特别难找,所以直接看到DistroSyncChangeTask.
- DistroSyncChangeTask的run方法是发送http请求去其他节点最终调用到NamingProxy#sync(这个类我们客户端也看到过,专门用于http请求同步数据),最终发送PUT请求到/v1/ns/distro/datum,如果发送了就把当前任务丢进一个延时队列,无限循环执行,直到成功,或者需要发送的Nacos服务端不在线.这样就可以保证我们集群的最终一致.并且我们可以发现,Nacos服务端集群之间能彼此感知对应的存在,所以他们之间肯定还会有个心跳任务.
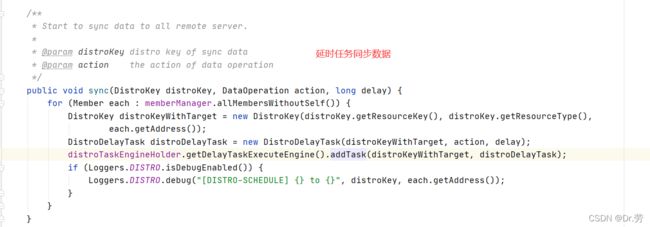
最终会调用到DistroSyncChangeTask#run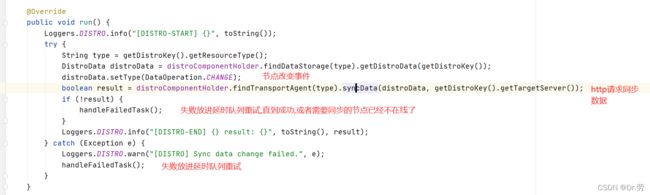
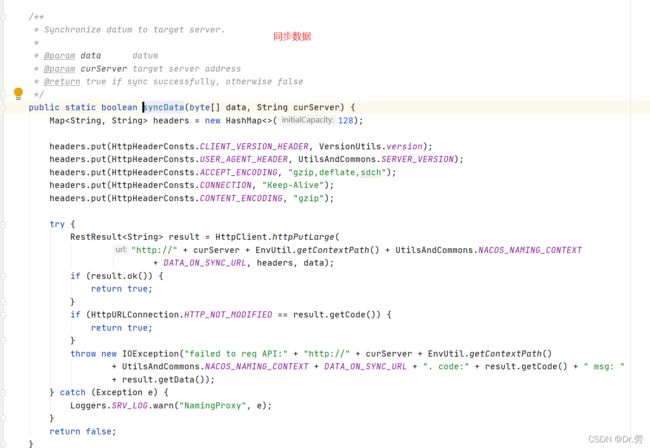
3.4.1 PUT /v1/ns/distro/datum 集群间同步数据
上面说到Nacos客户端请求去服务端之后,服务端会调用PUT /v1/ns/distro/datum,这个接口去同步新增的节点数据.

上面的onReceive会调用DistroConsistencyServiceImpl#processData,然后DistroConsistencyServiceImpl#onPut方法和上面新增节点方法一模一样,这里就不说了,就是最终修改ServiceMap,只不过不需要在同步去其他Nacos服务端的节点.
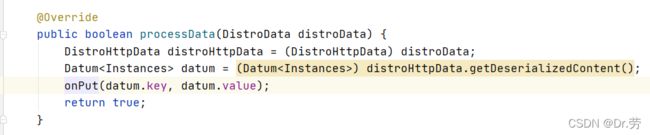
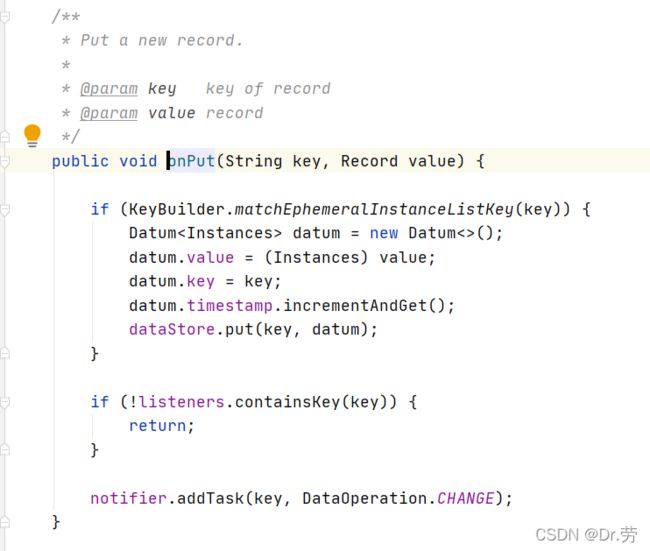
3.5 GET /v1/ns/instance/list
上面说了服务注册就是在修改ServiceMap,那获取服务列表肯定是获取ServiceMap.
3.5.1GET /v1/ns/instance/list
直接找到这个接口
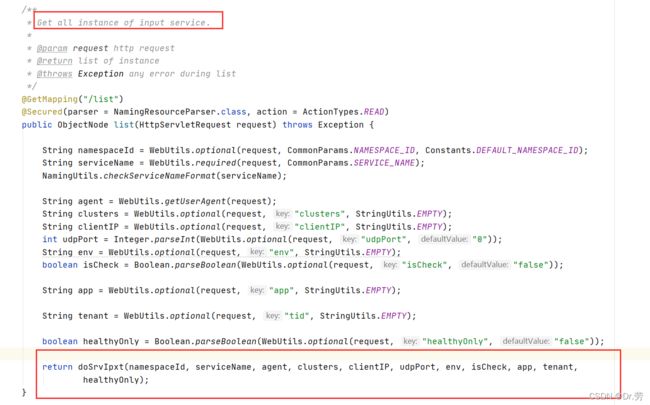
InstanceController#doSrvIpxt
我们可以看到这个方法其实就是去ServiceMap获取对应的信息,然后返回,后面的逻辑有兴趣可以自己看一下.
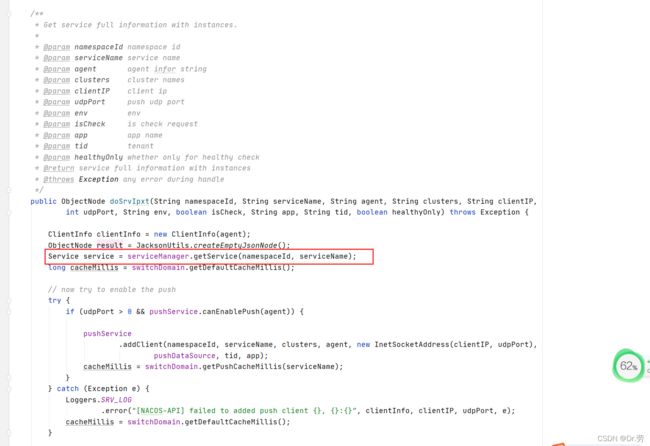
中间省略一大串代码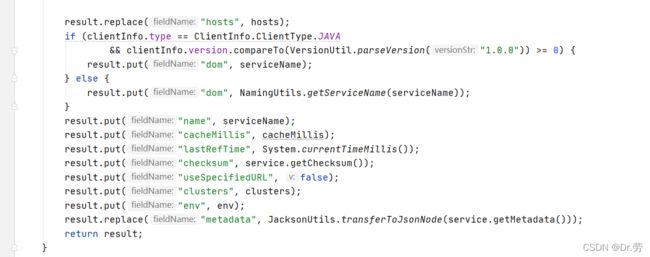
getService,去serviceMap,获取信息
3.6 PUT /v1/ns/instance/beat 心跳保活
我们知道Nacos客户端会有个定时任务,定时请求服务端的这个接口PUT /v1/ns/instance/beat,去告诉服务端我还活着.
3.6.1 PUT /v1/ns/instance/beat
- 根据心跳去当前的ServiceMap找这个Instance,如果找不到就重新走上面的注册逻辑,不懂可以看一下上面的serviceManager#registerInstance,这里可以很好的解释了,我为什么注册接口是异步的,如果失败了呢?
1. 注册接口逻辑太长,所以异步
2. 即使注册失败了,心跳上来也会重新注册.达到最终一致
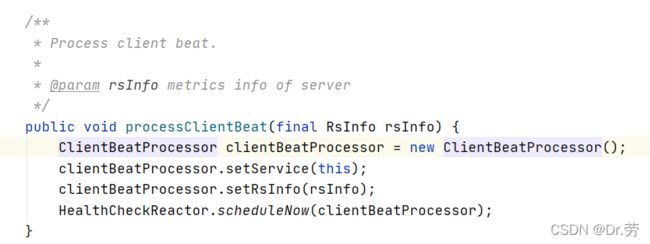
- 调用service#processClientBeat(clientBeat);处理心跳
/**
* Create a beat for instance.
*
* @param request http request
* @return detail information of instance
* @throws Exception any error during handle
*/
@CanDistro
@PutMapping("/beat")
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
public ObjectNode beat(HttpServletRequest request) throws Exception {
//前面省略代码
//根据上传的心跳去找对应的实例,找不到就new一个,重新走注册逻辑,可以看上面的注册逻辑
if (instance == null) {
if (clientBeat == null) {
result.put(CommonParams.CODE, NamingResponseCode.RESOURCE_NOT_FOUND);
return result;
}
instance = new Instance();
instance.setPort(clientBeat.getPort());
//前面省略代码
serviceManager.registerInstance(namespaceId, serviceName, instance);
}
//前面省略代码
Service service = serviceManager.getService(namespaceId, serviceName);
//处理心跳
service.processClientBeat(clientBeat);
result.put(CommonParams.CODE, NamingResponseCode.OK);
if (instance.containsMetadata(PreservedMetadataKeys.HEART_BEAT_INTERVAL)) {
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL, instance.getInstanceHeartBeatInterval());
}
result.put(SwitchEntry.LIGHT_BEAT_ENABLED, switchDomain.isLightBeatEnabled());
return result;
}3.6.2 ClientBeatProcessor#run
上面的处理心跳service#processClientBeat,new了一个ClientBeatProcessor,然后丢进线程池,立即执行,所以我们看一下ClientBeatProcessor#run,他做了以下事情
- 设置最后一次心跳时间,Nacos服务端肯定还有一个定时任务去扫描这个时间,去服务端的状态修改.
- 当实例状态由不健康变为健康,设置healthy属性,并且发送udp请求,告诉其他client节点.

4.Nacos心跳保活客户端任务
上面主要介绍了服务端几个主要暴露的接口,我们还遗漏了一个点,客户端心跳上来,我们服务端还需要一个定时任务,去看一下哪一些服务是有心跳的,哪一些没心跳需要下线.
4.1 ClientBeatCheckTask
上面我们注册的时候调用了ServiceManager#registerInstance首先创建了一个空的Service存储到ServiceMap里面,然后调用addInstance.
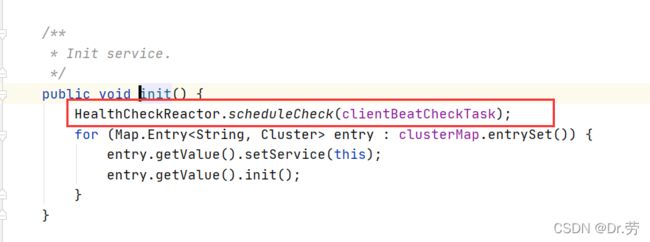
4.1.1 Service#init
上面的ServiceManager#createEmptyService会绑定listen并且最后会调用到Service#init,初始化一个定时任务ClientBeatCheckTask,所以我们得看他的run方法

4.1.2 ClientBeatCheckTask#run
这里就是心跳任务,去检查当前节点客户端的心跳.
- 如果已经一段时间没心跳,则设置健康状态为false,并且推送udp给我们的客户端其他节点
- 如果已经30秒没有收到客户端的心跳,则会调用deleteIp(instance);调用这个方法http请求,去其他Nacos服务端,修改该节点的信息,调用的DELEET /v1/ns/instance,这个接口实际上就是调用了新增的put方法,一模一样,就是修改ServiceMap,去剔除节点,并且广播给其他Nacos服务节点,这里不再展开说.
@Override
public void run() {
try {
//这里放后面讲
if (!getDistroMapper().responsible(service.getName())) {
return;
}
if (!getSwitchDomain().isHealthCheckEnabled()) {
return;
}
//获取当前Nacos服务上的所有节点
List instances = service.allIPs(true);
//检测心跳
// first set health status of instances:
for (Instance instance : instances) {
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getInstanceHeartBeatTimeOut()) {
if (!instance.isMarked()) {
if (instance.isHealthy()) {
//如果一段时间没心跳,设置健康状态为false
instance.setHealthy(false);
Loggers.EVT_LOG
.info("{POS} {IP-DISABLED} valid: {}:{}@{}@{}, region: {}, msg: client timeout after {}, last beat: {}",
instance.getIp(), instance.getPort(), instance.getClusterName(),
service.getName(), UtilsAndCommons.LOCALHOST_SITE,
instance.getInstanceHeartBeatTimeOut(), instance.getLastBeat());
getPushService().serviceChanged(service);
ApplicationUtils.publishEvent(new InstanceHeartbeatTimeoutEvent(this, instance));
}
}
}
}
if (!getGlobalConfig().isExpireInstance()) {
return;
}
// then remove obsolete instances:
for (Instance instance : instances) {
if (instance.isMarked()) {
continue;
}
//如果30秒没有心跳,则剔除节点
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getIpDeleteTimeout()) {
// delete instance
Loggers.SRV_LOG.info("[AUTO-DELETE-IP] service: {}, ip: {}", service.getName(),
JacksonUtils.toJson(instance));
//发送删除节点请求
deleteIp(instance);
}
}
} catch (Exception e) {
Loggers.SRV_LOG.warn("Exception while processing client beat time out.", e);
}
} DELETE /v1/ns/instance,剔除节点
4.1.3 ServiceManager#init同步客户端服务状态
上面心跳对比更改了healthy属性,然后30秒没收到心跳剔除节点,那么如果服务下线,没到30秒,我们在哪里同步给其他Nacos服务端呢?
我们看到ServiceManager有一个init方法,并且有@PostConstruct,证明Spring启动的时候会调用这个方法,并且5秒调用一次.首先判断数据在哪个节点处理(distroMapper.responsible(groupedServiceName)可以看第5点),如果是当前节点处理,这个方法会将客户端服务信息包括健康状态拼接成字符串,同步给其他Nacos服务端,这样我们就能感应到客户端节点状态的改变.
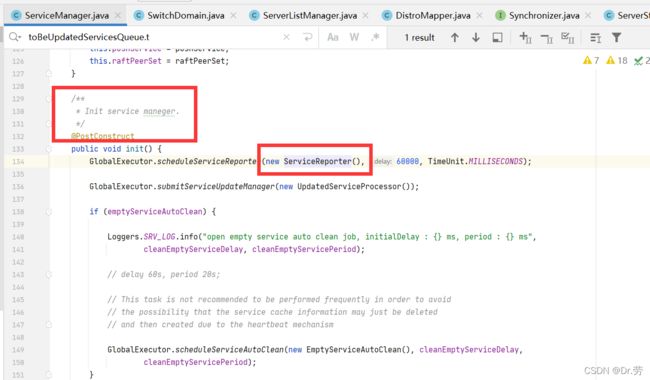
拼接需要发送的数据,包括客户端服务信息和服务的当前状态
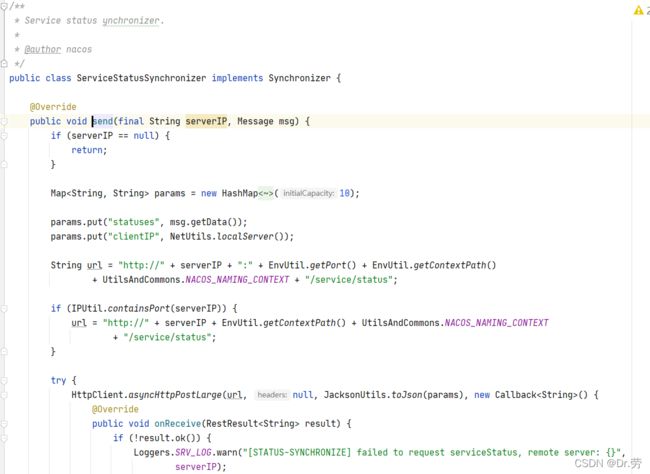
4.1.4 ServiceStatusSynchronizer#send
上面的方法会拼接最终会调用到ServiceStatusSynchronizer#send,发送http请求,POST
/v1/ns/service/status,但是失败不重试.
4.1.5 POST /v1/ns/service/status 同步客户端服务状态

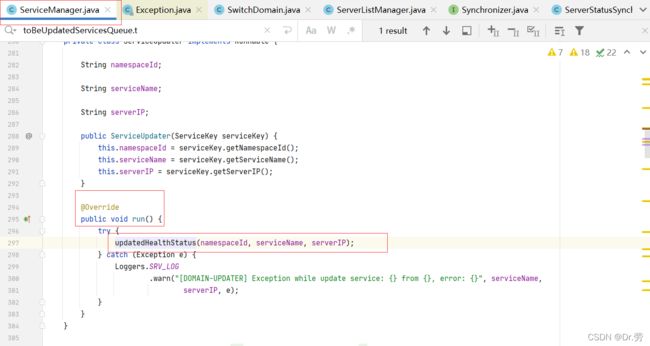
4.1.6 ServiceManager#updatedHealthStatus
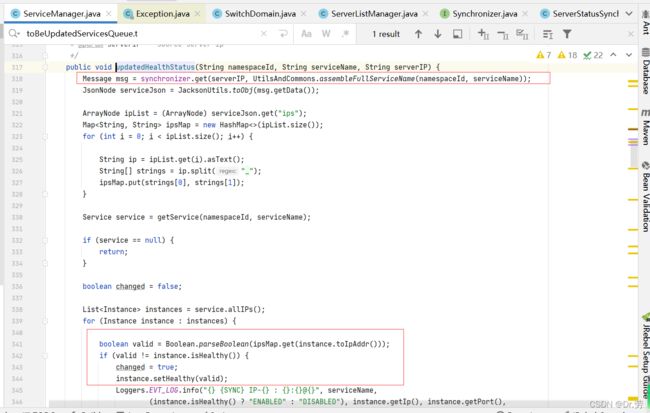
上面的接口最后会异步调用到ServiceManager#updatedHealthStatus,里面会获取发送过来的节点数据,更新healthy状态等.
5. DistroFilter和@CanDistro Nacos服务端路由
之前我们提到AP模式下,distro协议对于每一台机器都是平等的,会请求到任意一台机器,如果我的Order服务,第一次心跳被Nacos1处理,第二次心跳被Nacos2处理,但是我们看了上面心跳接口的逻辑是没有同步给其他Nacos服务端节点的,那么整个集群的心跳是不是乱的,这样我的心跳保活客户端任务怎么判断?
5.1DistroFilter
实际上通过我们的观察所有对于ServiceMap的修改的接口上面都带了一个@CanDistro的注解.然后我们全局搜这个注解发现他在DistroFilter里面使用到了,Filter会在我们请求之前拦截.
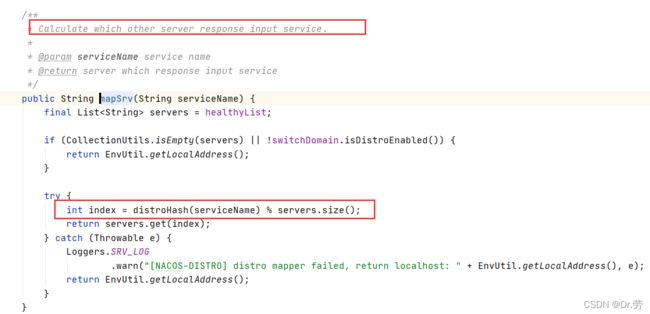
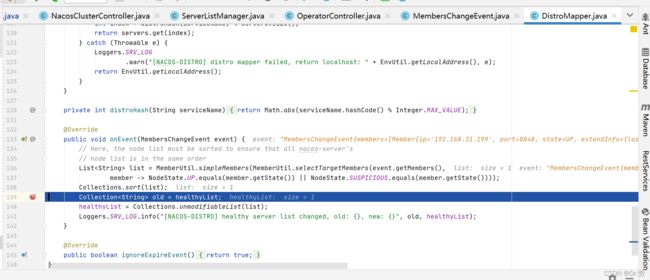
DistroFilter#mapSrv
根据服务名称Hash,再对我们服务器数量求模,计算出我当前的服务应该属于哪一台Nacos去处理.这个Servers.size是动态的,Nacos服务端集群之间会有心跳去保活.如果不属于我这台Nacos服务去处理,则路由到其他服务,否则由本服务处理.这里看出为了减轻单节点压力,对于Nacos客户端请求都是分散在集群的节点中.
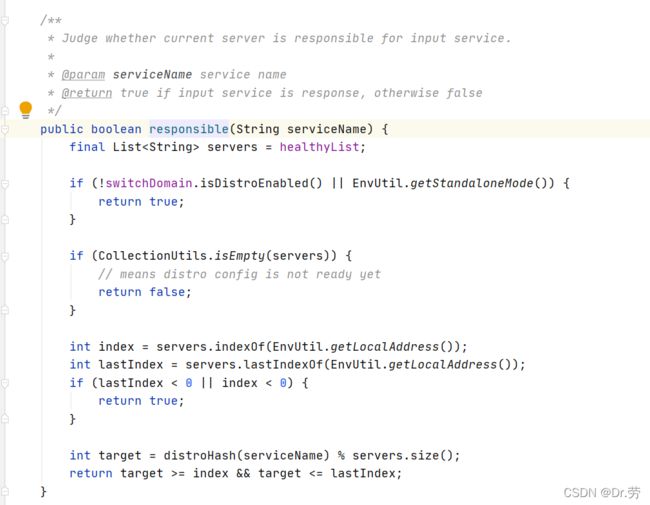
distroMapper#responsible(groupedServiceName)
这个方法是判断当前实例是否当前节点处理.但是这样做有一个缺点就是:Nacos如果扩容,或者某个节点宕机,所有的service都可能会迁移到别的机器,会很耗费资源.据说2.0使用grpc长连接解决了这个问题.
/**
* Distro filter.
*
* @author nacos
*/
public class DistroFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain)
throws IOException, ServletException {
// proxy request to other server if necessary:
if (method.isAnnotationPresent(CanDistro.class) && !distroMapper.responsible(groupedServiceName)) {
//省略代码
//根据ServiceName,hash找到我这个客户端应该被集群中哪个Nacos服务端去处理
final String targetServer = distroMapper.mapSrv(groupedServiceName);
List headerList = new ArrayList<>(16);
Enumeration headers = req.getHeaderNames();
while (headers.hasMoreElements()) {
String headerName = headers.nextElement();
headerList.add(headerName);
headerList.add(req.getHeader(headerName));
}
//计算出targetServer,直接请求去targetServer
RestResult result = HttpClient
.request("http://" + targetServer + req.getRequestURI(), headerList, paramsValue, body,
PROXY_CONNECT_TIMEOUT, PROXY_READ_TIMEOUT, Charsets.UTF_8.name(), req.getMethod());
String data = result.ok() ? result.getData() : result.getMessage();
}
} DistroFilter#mapSrv
根据服务名称Hash,再对我们服务器数量求模,计算出我当前的服务应该属于哪一台Nacos去处理.这个Servers.size是动态的,Nacos服务端集群之间会有心跳去保活.
5.2 ClientBeatCheckTask#run
我们再看回上面的对客户端的心跳保活任务,这个DistroMapper#responsible,会计算服务名出当前定时任务需不需要执行,假如order服务是我这台nacos服务执行的,就执行心跳保活任务,并且如果状态改变,同步给其他服务,如果不是我这台服务执行,则return;

DistroMapper#responsible
6. Nacos服务端之间的心跳任务
.上面我们说到如果是更改serviceMap的请求,会根据服务名称路由到对应的服务节点去处理.他根据服务名称hash再模服务器数量,既然这里有服务器数量这个变量,我们Nacos服务直接必定还有一个心跳任务,不然服务与服务直接怎么能知道相互之间的状态,万一有一台Nacos服务挂了,这个服务器数量变量也需要变.
6.1serverListManager#init
Spring启动的时候会执行@PostConstruct的方法,所以会执行serverListManager#init,里面往线程池放了一个任务ServerStatusReporter,2秒执行一次,去同步Nacos服务端之间的状态

6.1.1 ServerStatusSynchronizer#send
上面的定时任务最终会调用到ServerStatusSynchronizer#send,发送http请求
GET /v1/ns/operator/server/status
6.1.2 GET /v1/ns/operator/server/status
这个接口以后将会被移除,这个接口主要用于更新Nacos服务的最新一次心跳,并且更新服务信息
6.1.3 ServerMemberManager#MemberInfoReportTask,服务端心跳保活任务
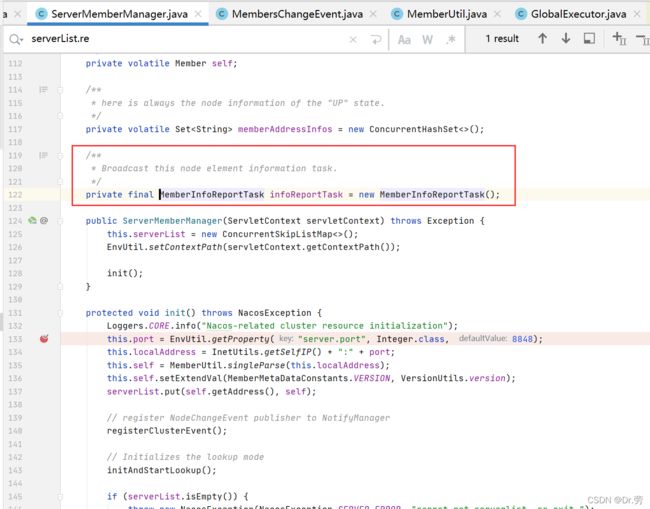
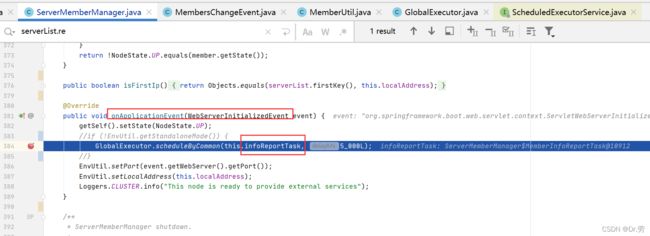
单单有心跳了还不行,我们还需要一个定时任务去维护这个心跳,把一段时间没有心跳的节点剔除掉,我们会发现ServerMemberManager初始化的时候初始化了一个MemberInfoReportTask,并且在ServerMemberManager#onApplicationEvent,触发了tomcat启动完成的一个方法,里面判断,如果不是以单节点启动,就定时执行ServerMemberManager#MemberInfoReportTask
6.1.4 MemberInfoReportTask
MemberInfoReportTask继承了task,所以每一次执行完都会执行after方法,MemberInfoReportTask重写了after方法,每2秒执行一次,去请求除了自己的节点的所有Nacos服务端节点,如果成功则比对Nacos服务端其他节点有没有更变状态,失败则重试,一定次数之后剔除对应的Nacos服务端节点,并且修改触发MembersChangeEvent事件,然后触发DistroMapper#onEvent事件,DistroMapper就是用于计算服务节点的
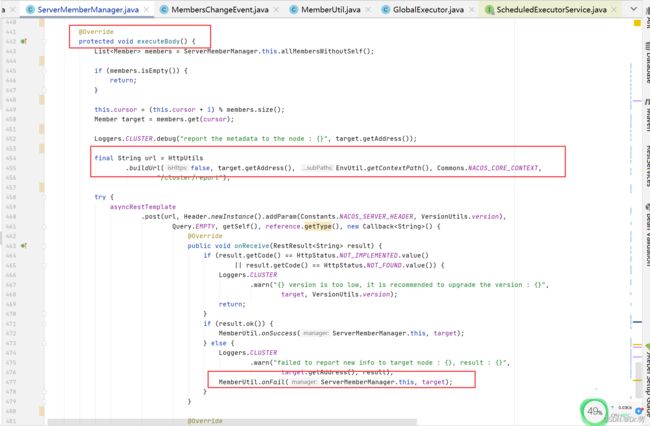
DistroMapper#onEvent
7.Nacos服务端启动拉取数据与扩容
当我有一台Nacos服务端挂了,然后再启动,或者有一台新的节点加入我的集群,新加入节点需要手动修改我们的cluster.conf文件,一旦修改了,Nacos服务会监控到这个文件的修改我们的member;我新节点肯定需要去拉取数据,这个时候如果某一些客户端节点在注册,我可能拉取的是老数据,但是没关系,客户端注册完之后还是需要对每一个member进行广播,并且还有一个DistroVerifyExecuteTask,这个任务会不断往其他Nacos服务按节点发送我当前负责的节点,其他节点收到后,会进行校验和同步修改,达到最终一致;
例如我Nacos 1只负责处理order服务,Nacos2负责处理user服务,Nacos3负责product和store服务的处理,各自节点上面的数据肯定是完整的,就算数据丢失或者不完整,客户端心跳上来也会补齐,即使Nacos现在进行扩容或者索容了,期间产生数据的不一致,后面客户端心跳上来也会补齐对应节点的数据.现在多了Nacos4,可能就由Nacos4处理store服务了,这样所有store服务的注册心跳都转移到了Nacos4,现在Nacos 1负责处理order服务,Nacos2负责处理user服务,Nacos3负责product,Nacos4负责store服务,每一个节点他们负责的客户端服务的数据肯定是最新的.
所以每个Nacos节点,会把自己处理的数据同步到别的节点,别的节点就可以根据同步的数据进行校 验,然后修改和同步.DistroVerifyExecuteTask可以参考Nacos 2.0源码分析-Distro协议详解 - 不会发芽的种子 - 博客园
对应上面标题2的每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据一致性。
7.1 DistroProtocol#startLoadTask服务启动拉取节点任务
当我们服务启动的时候我们会注入DistroProtocol这个bean,他的构建方法会调用DistroProtocol#startLoadTask.

7.1.1 DistroLoadDataTask#run
上面那个方法最终会调用DistroLoadDataTask#run,然后调用DistroLoadDataTask#loadAllDataSnapshotFromRemote,最终会调用NamingProxy#getAllData,http请求去其中一个Nacos服务节点拉取客户端的服务列表,
GET v1/ns/distro/datums然后保存到本地return.

DistroLoadDataTask#loadAllDataSnapshotFromRemote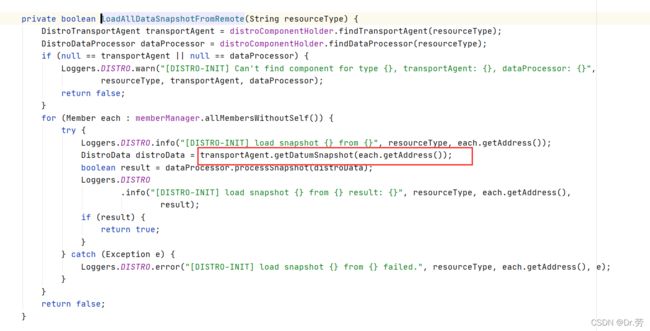
 NamingProxy#getAllData,http请求去其中一个Nacos服务节点拉取客户端的服务列表调用GET /v1/ns/distro/datums
NamingProxy#getAllData,http请求去其中一个Nacos服务节点拉取客户端的服务列表调用GET /v1/ns/distro/datums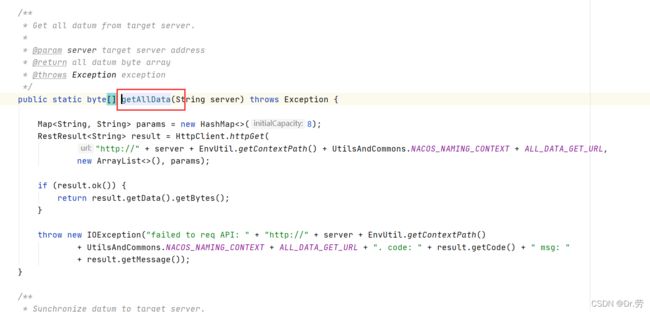
7.2 GET /v1/ns/distro/datums
拉取本地的内存中的服务列表节点返回
8. 附上整体源码的阅读流程图
9.自我总结
- 里面用了很多异步,模块化,队列,使代码解耦和提高吞吐量,这是我们平常写业务代码所涉及不了的知识盲点
- DistroMapper很巧妙的解决了没有Leader下,每个节点都是平等的,但是不同的客户端根据路由到不同的Nacos服务端去处理,减轻了单点的压力
- 但是Nacos服务端扩容,或者某个节点宕机,所有的service都可能会迁移到别的机器,这个时候可能会有一定的资源损耗.
- Distro通过不断的重试和定时任务,使整个集群达到最终一致
- 熟悉了一个注册中心他的整体流程,他所需要的功能
- 服务端更新serviceMap的时候写时复制真是一种巧妙的设计
- 自己读过一遍的源码,再去细细品味,而且读提高了自己的源码能力,能从很多切入点去知道源码他做了什么事情.
- 源码阅读真是难度挺大,希望自己可以坚持,这篇博文应该也没啥人能看到最后,当做自己第一次深入阅读开源中间件源码的一个开始.
参考:Nacos AP模型原理。_无能力者只知抱怨-CSDN博客_ap模型
nacos高可用(图解+秒懂+史上最全)_架构师尼恩-CSDN博客_nacos 高可用模式
Nacos 2.0源码分析-Distro协议详解 - 不会发芽的种子 - 博客园