yolov1-yolov4
一个版本的快速实现参考
blog
yolov1 loss 详细介绍
快速回忆可以参考
yolov1-yolov4纵向比较
YoloV1
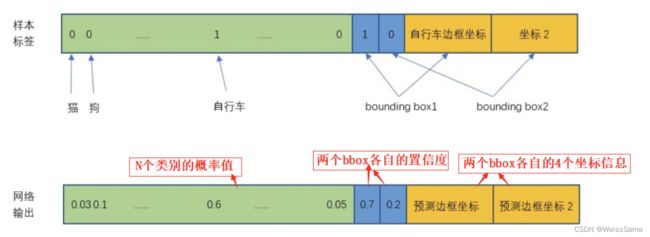
YoloV1将原始图片Resize到448x448,经过网络多次conv和pooling,最终得到的特征7x7x30;
这7x7的特征,对应的是将原图划分为7x7的网格。YoloV1要求每一个网格负责输出2个预测目标框,这两个框有它们各自的位置信息x,y,w,h和置信度conf信息。
在训练阶段
我们先计算每个GroundTruth (GT) 的中心点,确定GT的中心落在哪一个网格,那么这个GT box就由该网格负责预测(回归),网格的类就是GT的类,具体由网格中两个预测框中的哪一个预测框来回归GT box,由预测框和GT box之间的IOU决定,IoU更大的预测框负责回归该GT box。那么此时我们分配给预测框的标签是:
c o n f conf conf = P r ( O b j e c t ) P_r(Object) Pr(Object)* I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth
其中
- 如果网格中有没有GT落入,那么其中的两个预测框的conf都设置为0,负样本预测框没有类别loss和边框loss,只有置信度loss。
- 如果有GT落入该网格,那么 P r ( O b j e c t ) P_r(Object) Pr(Object)=1,预测框置信度等于 I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth ,同时该网格的类就是GT的类。
下图中,可以看到我们对输出特征维度上打的标签和真实输出。
损失函数设计如下图

- 第一行:bounding box的中心点定位误差,8维的localization error和20维的classification error同等重要显然是不合理的。所以添加 λ c o o r d \lambda_{coord} λcoord=5,K是原文中的S,M是原文中的B,都是常数,i代表了网格的个数,j代表了一个网格中box个数, I i j o b j I_{ij}^{obj} Iijobj非0即1,挑选出负责预测的bbox 。
- 第二行,bounding box宽高定位误差,根号的目的是让小目标和大目标对loss的贡献差别不太大。
- 第三行,网格中有两个bbox,一个负责检测物体,另一个物体不负责检测物体。第三行中 C i C_i Ci是负责检测物体的box的预测置信度,越接近1越好, C ^ i \hat{C}_{i}^{} C^i是标签值,等于 P r ( O b j e c t ) P_r(Object) Pr(Object)* I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth,网格中有物体则 P r ( O b j e c t ) P_r(Object) Pr(Object)=1,注意不代表是哪一类物体,预测属于哪一类物体在第五行。
- 第四行,不负责检测物体的box的置信度误差, λ n o o b j \lambda_{noobj} λnoobj=0.5,负样本较多,所以加入这个参数。 I i j n o o n j I_{ij}^{noonj} Iijnoonj 非0即1,没有object的时候等于1。 C i C_i Ci是box的置信度,越接近1越好, C ^ i \hat{C}_{i}^{} C^i是标签值,等于0,这里负样本有两种,第一类:是负责预测物体的网格中置信度较低,被晒除了。第二类:该网格本身就不负责预测物体,预测出没有用的box。
- 第五行,负责检测物体的网格的分类误差。 P ^ i ( c ) \hat{P}_{i}^{}(c) P^i(c)是标注的该类物体的概率, P i ( c ) 是预测置信度,越接近 1 越好。 P_i(c)是预测置信度,越接近1越好。 Pi(c)是预测置信度,越接近1越好。
在C>0的位置计算分类损失,在最大IoU的位置计算contain_loss和定位损失。较小IoU的位置计算not_contain_loss,在c<0的位置计算nooobj_loss,要给正样本的损失加一个大一点的权重。
在测试阶段
YoloV1采用类和置信度分开预测的方法,由两者乘积决定预测框最终的置信度,送入NMS的就是这个最终置信度;而faster cnn是直接在类别预测中,包含了置信度预测。YoloV1对类别的预测是由网格来决定,进一步说,是由网格中置信度较大的那一个预测框来决定。另一个IoU较小的框不参与类的预测。这也是为什么特征图最终维度是7x7x( 2x(4+1) + 20) 而不是 7x7( 2x(4+1+20) ),也就是说如果多个物体出现在同一个网格内,那YoloV1只能负责预测其中的一个类概率最大的物体,这是一个比较大的缺点,导致了YoloV1的召回率低。
上面是3.9号更新
由于不同大小的边界框对预测偏差的敏感度不同,小的边界框对预测偏差的敏感度更大。为了均衡不同尺寸边界框对预测偏差的敏感度的差异。作者巧妙的对边界框的 w,h 取根号值再求 L2 loss. YOLO 中更重视坐标预测,赋予坐标损失更大的权重,记为 coord,在 pascal voc 训练中 coodd=5 ,classification error 部分的权重取 1。
某边界框的置信度定义为:某边界框的 confidence = 该边界框存在某类对象的概率 pr (object) 该边界框与该对象的 ground truth 的 IOU 值* ,若该边界框存在某个对象 pr (object)=1 ,否则 pr (object)=0 。由于一幅图中大部分网格中是没有物体的,这些网格中的边界框的 confidence 置为 0,相比于有物体的网格,这些不包含物体的网格更多,对梯度更新的贡献更大,会导致网络不稳定。为了平衡上述问题,**YOLO 损失函数中对没有物体的边界框的 confidence error 赋予较小的权重,记为 noobj,对有物体的边界框的 confidence error 赋予较大的权重。在 pascal VOC 训练中 noobj=0.5 ,**有物体的边界框的 confidence error 的权重设为 1.
YoloV1的缺点
相比较于faster rcnn这种根据海量anchor来预测偏移量的模型【学习的是平移和尺度变换的参数】,yolov1的目的是直接学习xywh的坐标,学习的难度比较大,召回率低。
YoloV2
网络改动,不用yolov1中类似googlenet的结构,改用了darknet19,用global average pooling取代了全连接层,一方面减少参数避免过拟合,另一方面使得输入不必固定size。darknet中大量使用1x1卷积来降低通道数,以降低模型计算量和参数数目。另外图像输入大小在yolov1中是224x224,而yolov2为了使用高分辨率,将输入从224变成448,而另一方面,为了使得输出的feature map是奇数[保证最终有一个中心位置,对预测物体有极大帮助],又将输入从448变成416,所以最终的feature map大小是416/32=13 x 13

- Batch Normalization
YoloV2在每个conv层之后加入bn层,同时去掉了最后的dropout 。map提高2%
下面是我写的文章,包含对BN的详细解释。
文章链接点我 - 通过k-means聚类得到最佳anchor个数 。
经过对VOC数据集和COCO数据集中bbox的k-means聚类分析,将anchor机制中原本惯用的 9 anchor 法则 删减为仅保留最常出现的 5 anchor 。其中,狭长型的anchor是被保留的主体。即,先验的anchor box是通过IoU聚类得到的. - Anchors机制
Yolov1中grid预测物体属于哪个类的概率,而grid的box预测物体的置信度。 而Yolov2中去掉了grid预测类的作用 P r ( C l a s s i ∣ O b j e c t ) P_r(Class_i|Object) Pr(Classi∣Object),不过grid用来设定anchor,而anchor生成的预测框用来预测类别。
需要注意的是,下图中yolov1的box的xywh代表的是直接的坐标值,而yolov2中box的xywh代表的是 t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th,它们需要和anchor做一定的变换才能得到预测框的位置。

上图提到了 t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th,那么下图中代表了 t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th到真正预测框的变换,这里 C x , C y C_x, C_y Cx,Cy是C点的坐标,C点是该grid左上角的坐标,
Anchor box:下图的黑色虚线框, p h p_h ph 和 p w p_w pw代表它的长宽。
BoundingBox:下图蓝色框, b h b_h bh和 b w b_w bw代表它的长宽。
下图中的σ定义为sigmoid激活函数,这里用sigmoid函数是为了让预测框的中心位置位于grid中,这种对偏移量的约束一定程度上保证了训练时间减少,加快收敛。

参考
yolov2 anchor+特征融合
faster rcnn+yolov1+yolov2
yolov4全面详解