通过构建一个顺序表——教你计算时间复杂度和空间复杂度(含递归)
目录
引言
时间复杂度的基本知识
大O的渐进表示法
空间复杂度的基础知识
顺序表
初始化
销毁
检查空间
显示顺序表
指定位置插入数据
尾部插入数据
头部插入数据
指定位置删除数据
寻找数据的位置
基于斐波那契数递归的空间复杂度和时间复杂度
引言
我们在评估一个算法好坏的时候,往往使用算法效率作为指标。
算法效率分析分为两种:第一种是时间效率,第二种是空间效率。时间效率被称为时间复杂度,而空间效率被称作空间复杂度。 时间复杂度主要衡量的是一个算法的运行速度,而空间复杂度主要衡量一个算法所需要的额外空间。这篇博客将会手把手构建一个顺序表,在具体的代码中帮助理解一段代码的时间和空间复杂度。
在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
时间复杂度的基本知识
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
大O的渐进表示法
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们使用大O的渐进表示法。
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
接下来我们来看看一段代码:
// 请计算一下Func1基本操作执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}通过计算,我们可以得出++count被执行的次数是N^2+2*N+10,但是使用大O的渐进表示法以后,Func1的时间复杂度为O(N^2)。
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
这时,我们一律采用最坏情况。
空间复杂度的基础知识
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度 。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
接下来让我们看一个简单的例子:
// 计算Fibonacci的空间复杂度?
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i ] = fibArray[ i - 1] + fibArray [i - 2];
}
return fibArray ;
}动态开辟了N个空间,空间复杂度为 O(N)。
顺序表
#pragma once
#include
#include
#include
typedef int SLDateType;
typedef struct SeqList
{
SLDateType* a;
size_t size;
size_t capacity; // unsigned int
}SeqList;
// 对数据的管理:增删查改
void SeqListInit(SeqList* ps);
void SeqListDestroy(SeqList* ps);
void SeqListPrint(SeqList* ps);
void SeqListPushBack(SeqList* ps, SLDateType x);
void SeqListPushFront(SeqList* ps, SLDateType x);
void SeqListPopFront(SeqList* ps);
void SeqListPopBack(SeqList* ps);
// 顺序表查找
int SeqListFind(SeqList* ps, SLDateType x);
// 顺序表在pos位置插入x
void SeqListInsert(SeqList* ps, size_t pos, SLDateType x);
// 顺序表删除pos位置的值
void SeqListErase(SeqList* ps, size_t pos); 我们可以看到,顺序表的头文件组成比较简单,由一个指针和两个变量管理顺序表。指针指向动态开辟的内存块,一个capacity表示可以存放的数据的数量,也就是内存块的大小,size表示已经存放的数据数量。
剩下的是管理内存块的函数的声明,让我们一个个分析过去:
初始化
void SeqListInit(SeqList* ps)
{
assert(ps);
ps->a = (SLDateType*)malloc(10 * sizeof(SLDateType));
ps->size = 0;
ps->capacity = 10;
}第一个初始化比较简单,语句执行了三次,时间复杂度为O(1),动态开辟了10 * sizeof(SLDateType)个字节的空间,空间复杂度也是O(1)。
销毁
void SeqListDestroy(SeqList* ps)
{
assert(ps);
ps->size = 0;
ps->capacity = 0;
free(ps->a);
ps->a = NULL;
}销毁顺序表,时间复杂度O(1),空间复杂度O(1)。
检查空间
void SeqListCheck(SeqList* ps)
{
assert(ps);
if (ps->size == ps->capacity)
{
SLDateType* temp = (SLDateType*)realloc(ps->a, 2 * ps->capacity * sizeof(SLDateType));
if (temp == NULL)
{
perror("capacity is not enough:");
}
ps->a = temp;
ps->capacity *= 2;
}
}这里时间复杂度比较简单,还是O(1),空间复杂度由于不知道capacity是多少,按最坏情况处理,是O(N)。
显示顺序表
void SeqListPrint(SeqList* ps)
{
assert(ps);
for (size_t i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}这里开辟了一个变量空间,空间复杂度为O(1),由于不确定size的大小,按照最坏情况计算,时间复杂度为O(N)。
指定位置插入数据
void SeqListInsert(SeqList* ps, size_t pos, SLDateType x)
{
assert(ps);
assert(pos <= ps->size);
SeqListCheck(ps);
size_t cur = ps->size;
while (cur > pos)
{
ps->a[cur] = ps->a[cur - 1];
--cur;
}
ps->a[cur] = x;
ps->size++;
}我们虽然看到内部就创建了一个变量,但是它调用了SeqListCheck(ps)这个函数的空间复杂度是O(N),计算空间复杂度应该加上,也是O(N),由于不知道pos和size,按照最坏的情况,时间复杂度为O(N)。
尾部插入数据
void SeqListPushBack(SeqList* ps, SLDateType x)
{
SeqListInsert(ps, ps->size, x);
}是指定位置插入的一个特殊情况,调用了SeqListCheck(ps)这个函数的空间复杂度是O(N),由于pos和size之间差值为0,按照最坏的情况,时间复杂度为O(1)。
头部插入数据
void SeqListPushFront(SeqList* ps, SLDateType x)
{
SeqListInsert(ps, 0, x);
}是指定位置插入的一个特殊情况,调用了SeqListCheck(ps)这个函数的空间复杂度是O(N),由于pos和size之间差值为size,按照最坏的情况,时间复杂度为O(N)。
指定位置删除数据
void SeqListErase(SeqList* ps, size_t pos)
{
assert(ps);
assert(pos < ps->size);
size_t cur = pos;
while(cur < ps->size - 1)
{
ps->a[cur] = ps->a[cur + 1];
++cur;
}
--(ps->size);
}这里开辟了一个变量空间,空间复杂度为O(1),由于不确定size和pos,按照最坏情况计算,时间复杂度为O(N)。
寻找数据的位置
int SeqListFind(SeqList* ps, SLDateType x)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
if (x == ps->a[i])
{
return i;
}
}
return -1;
}这里开辟了一个变量空间,空间复杂度为O(1),由于不确定是否存在,按照最坏情况计算,时间复杂度为O(N)。
基于斐波那契数递归的空间复杂度和时间复杂度
对于递归,情况就有一点点复杂,下面是一个求斐波那契数的函数:
long long Fibonacci(size_t n)
{
if(n==0)
return NULL;
if(n < 3)
return 1;
return Fibonacci(n - 1) + Fibonacci(n - 2);
}在内部调用了自己,我们知道每调用一次函数,函数的执行次数就加一次,以N= 6为例,我们来看看它的代码执行情况:
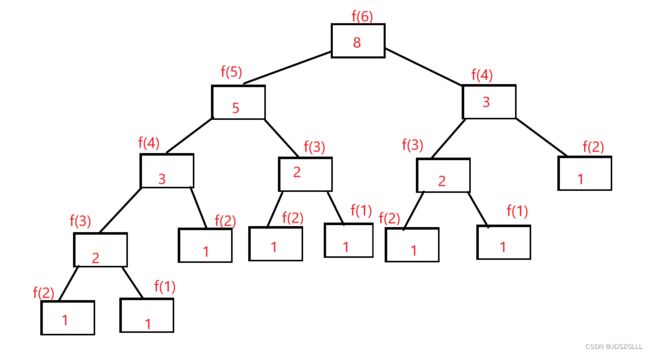
我们可以从图中看到,调用的函数不断地分出去,最后计算时间复杂度像是一个等比数列相加,虽然在右边缺了一块,但是对于总体来说影响不大。所以可以比较直观地得出,时间复杂度为O(n^2)。
接下来是计算空间复杂度,可能有人会说了,空间复杂度还有什么好算的,一眼就看出来和时间复杂度一样是 O(n^2)。
我们看到上面的图,非常直观,调用了那么多次的函数,理所当然地认为空间复杂度和时间是一样的。
这就完美地调入了习惯性的陷阱了:
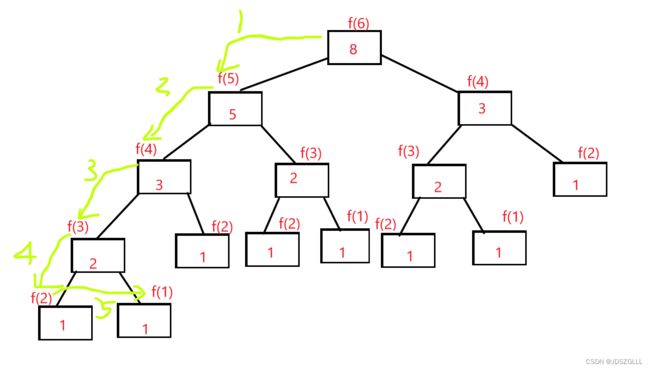
要解释清楚,需要同学们掌握一些关于函数栈帧的知识。
计算失误的同学,以为函数调用的空间开辟是像上面这张图一样的,在第四步调用函数之后又开辟了新的函数栈帧。但是我们知道函数栈帧不仅仅是会开辟的,还是会释放的,在执行完毕之后,开辟的空间就还给系统了。
所以真实的情况应该是这样的:

第五步是销毁函数,之后再开辟新的空间,且一次最多开辟n个函数栈帧,空间复杂度是O(n)。
关注我,关注我,帅哥美女。