Python|http|Chrome Developer Tools|Postman|HTTPie|builtwith库|python-whois库|爬虫及解析|语言基础50课:学习(10)
文章目录
-
- 原项目地址
- 其他相关资源可参考
- 第31课:网络数据采集概述
-
- 爬虫的应用领域
- 爬虫合法性探讨
-
- Robots协议
- 超文本传输协议(HTTP)
-
- 相关工具(Chrome Developer Tools、Postman、HTTPie、`builtwith`库、python-whois库)
- 爬虫的基本工作流程
- 第32课:用Python获取网络数据
-
- requests库
- 编写爬虫代码[豆瓣电影]
- 使用 IP 代理[蘑菇代理]
- 第33课:用Python解析HTML页面
-
- HTML 页面的结构
- XPath 解析
- CSS 选择器解析
- 简单的总结
- TIPS1:wireshark简介
原项目地址
Python-Core-50-Courses(https://hub.fastgit.org/jackfrued/Python-Core-50-Courses.git)
其他相关资源可参考
Python|Git remote|hosts|PyCharm常用快捷键|变量转换|命名|类型|运算符|分支|调整tab|循环:Python语言基础50课-学习记录(1)_打酱油的工程师的博客-CSDN博客(https://blog.csdn.net/Medlar_CN/article/details/129621149)
第31课:网络数据采集概述
爬虫(crawler)也经常被称为网络蜘蛛(spider),是按照一定的规则自动浏览网站并获取所需信息的机器人程序(自动化脚本代码),被广泛的应用于互联网搜索引擎和数据采集。
爬虫的应用领域
在理想的状态下,所有 ICP(Internet Content Provider)都应该为自己的网站提供 API 接口来共享它们允许其他程序获取的数据,在这种情况下就根本不需要爬虫程序。
爬虫合法性探讨
经常听人说起“爬虫写得好,牢饭吃到饱”,那么编程爬虫程序是否违法呢?关于这个问题,我们可以从以下几个角度进行解读。
- 网络爬虫这个领域目前还属于拓荒阶段,现在这个领域暂时还是灰色地带。
- “法不禁止即为许可”,如果爬虫就像浏览器一样获取的是前端显示的数据(网页上的公开信息)而不是网站后台的私密敏感信息,就不太担心法律法规的约束。
- 在爬取网站的时候,需要限制自己的爬虫遵守 Robots 协议,同时控制网络爬虫程序的抓取数据的速度;在使用数据的时候,必须要尊重网站的知识产权。
- 适当的隐匿自己的身份在编写爬虫程序时必要的,而且最好不要被对方举证你的爬虫有破坏别人动产(例如服务器)的行为。
- 不要在公网(如代码托管平台)上去开源或者展示你的爬虫代码。
Robots协议
大多数网站都会定义robots.txt文件,这是一个君子协议,并不是所有爬虫都必须遵守的游戏规则。下面以淘宝的robots.txt文件为例,看看淘宝网对爬虫有哪些限制。
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
通过上面的文件可以看出,淘宝禁止百度爬虫爬取它任何资源,因此当你在百度搜索“淘宝”的时候,搜索结果下方会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述”。百度作为一个搜索引擎,至少在表面上遵守了淘宝网的robots.txt协议,所以用户不能从百度上搜索到淘宝内部的产品信息。
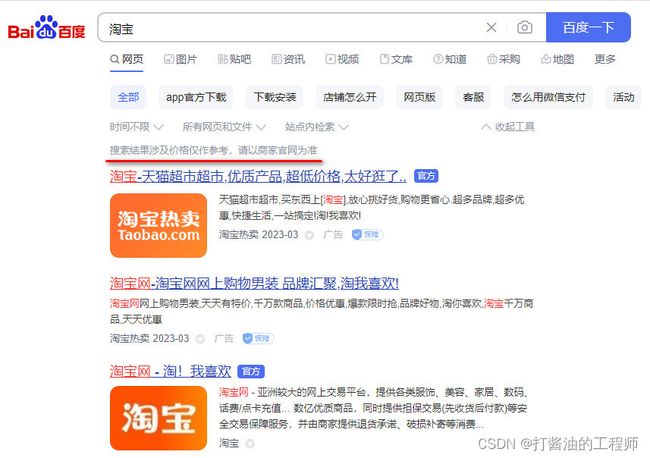
图1. 百度搜索淘宝的结果
下面是豆瓣网的robots.txt文件,大家可以自行解读,看看它做出了什么样的限制。
User-agent: *
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /forum/
Disallow: /new_subject
Disallow: /service/iframe
Disallow: /j/
Disallow: /link2/
Disallow: /recommend/
Disallow: /doubanapp/card
Disallow: /update/topic/
Disallow: /share/
Allow: /ads.txt
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap: https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /
User-agent: Mediapartners-Google
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /j/
超文本传输协议(HTTP)
在开始讲解爬虫之前,我们稍微对超文本传输协议(HTTP)做一些回顾,因为我们在网页上看到的内容通常是浏览器执行 HTML (超文本标记语言)得到的结果,而 HTTP 就是传输 HTML 数据的协议。HTTP 和其他很多应用级协议一样是构建在 TCP(传输控制协议)之上的,它利用了 TCP 提供的可靠的传输服务实现了 Web 应用中的数据交换。按照维基百科上的介绍,设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法,也就是说,这个协议是浏览器和 Web 服务器之间传输的数据的载体。关于 HTTP 的详细信息以及目前的发展状况,大家可以阅读《HTTP 协议入门》、《互联网协议入门》、《图解 HTTPS 协议》等文章进行了解。
HTTP 请求通常是由请求行、请求头、空行、消息体四个部分构成,如果没有数据发给服务器,消息体就不是必须的部分。请求行中包含了请求方法(GET、POST 等,如下表所示)、资源路径和协议版本;请求头由若干键值对构成,包含了浏览器、编码方式、首选语言、缓存策略等信息;请求头的后面是空行和消息体。
HTTP 响应通常是由响应行、响应头、空行、消息体四个部分构成,其中消息体是服务响应的数据,可能是 HTML 页面,也有可能是JSON或二进制数据等。响应行中包含了协议版本和响应状态码,响应状态码有很多种,常见的如下表所示。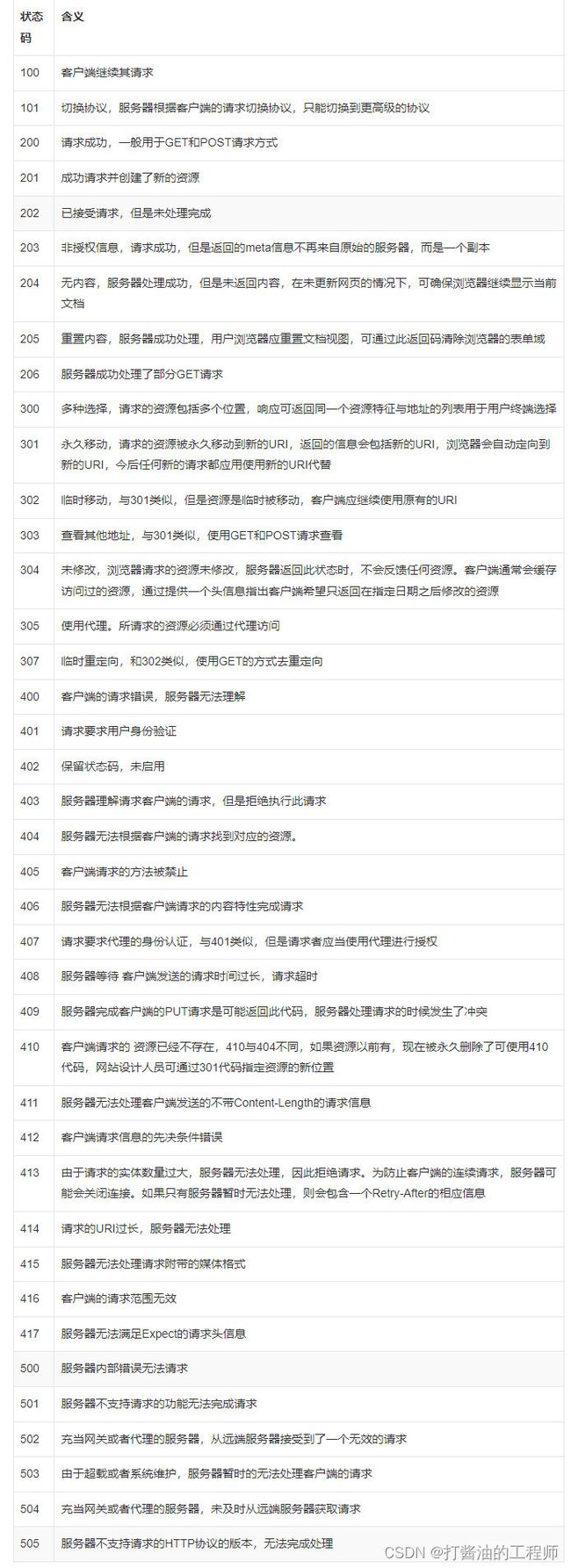
相关工具(Chrome Developer Tools、Postman、HTTPie、builtwith库、python-whois库)
下面我们先介绍一些开发爬虫程序的辅助工具,这些工具相信能帮助你事半功倍。
-
Chrome Developer Tools:谷歌浏览器内置的开发者工具。该工具最常用的几个功能模块是:
- 元素(ELements):用于查看或修改 HTML 元素的属性、CSS 属性、监听事件等。CSS 可以即时修改,即时显示,大大方便了开发者调试页面。
- 控制台(Console):用于执行一次性代码,查看 JavaScript 对象,查看调试日志信息或异常信息。控制台其实就是一个执行 JavaScript 代码的交互式环境。
- 源代码(Sources):用于查看页面的 HTML 文件源代码、JavaScript 源代码、CSS 源代码,此外最重要的是可以调试 JavaScript 源代码,可以给代码添加断点和单步执行。
- 网络(Network):用于 HTTP 请求、HTTP 响应以及与网络连接相关的信息。
- 应用(Application):用于查看浏览器本地存储、后台任务等内容,本地存储主要包括Cookie、Local Storage、Session Storage等。
-
Postman:功能强大的网页调试与 RESTful 请求工具。Postman可以帮助我们模拟请求,非常方便的定制我们的请求以及查看服务器的响应。
-
HTTPie:命令行HTTP客户端。
安装。
pip install httpie使用。
http --header https://movie.douban.com/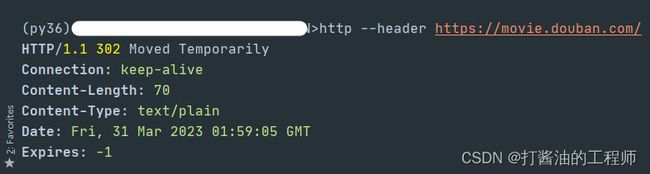
返回值:
HTTP/1.1 302 Moved Temporarily
Connection: keep-alive
Content-Length: 70
Content-Type: text/plain
Date: Fri, 31 Mar 2023 01:59:05 GMT
Expires: -1
Keep-Alive: timeout=30
Location: https://m.douban.com/movie/
Server: dae
Set-Cookie: bid=9Vk******; Expires=Sat, 30-Mar-24 01:59:05 GMT; Domain=.douban.com; Path=/
Strict-Transport-Security: max-age=15552000
X-Content-Type-Options: nosniff
X-DAE-App: movie
X-DAE-Instance: default
X-DOUBAN-NEWBID: 9VkfN******* -
builtwith库:识别网站所用技术的工具。安装。
pip install builtwith使用。
import ssl import builtwith ssl._create_default_https_context = ssl._create_unverified_context print(builtwith.parse('http://www.bootcss.com/')) #{'web-servers': ['Nginx'], 'javascript-frameworks': ['Lo-dash', 'Moment.js', 'React', 'Underscore.js', 'Vue.js', 'Zepto', 'jQuery'], 'web-frameworks': ['Twitter Bootstrap']} -
python-whois库:查询网站所有者的工具。安装。
pip3 install python-whois使用。
import whois print(whois.whois('https://www.bootcss.com'))打印值:
{ "domain_name": [ "BOOTCSS.COM", "bootcss.com" ], "registrar": "DNSPod, Inc.", "whois_server": "whois.dnspod.com", "referral_url": null, "updated_date": [ "2022-04-11 15:50:09", "2022-04-11 23:50:09" ], "creation_date": "2012-11-12 03:49:52", "expiration_date": "2028-11-12 03:49:52", "name_servers": [ "NS1.ALIDNS.COM", "NS2.ALIDNS.COM", "ns1.alidns.com", "ns2.alidns.com" ], "status": [ "ok https://icann.org/epp#ok", "ok https://www.icann.org/epp#ok" ], "emails": "[email protected]", "dnssec": "unsigned", "name": "REDACTED FOR PRIVACY", "org": "REDACTED FOR PRIVACY", "address": "REDACTED FOR PRIVACY", "city": "REDACTED FOR PRIVACY", "state": null, "zipcode": "REDACTED FOR PRIVACY", "country": "CN" }
爬虫的基本工作流程
一个基本的爬虫通常分为数据采集(网页下载)、数据处理(网页解析)和数据存储(将有用的信息持久化)三个部分的内容,当然更为高级的爬虫在数据采集和处理时会使用并发编程或分布式技术,这就需要有调度器(安排线程或进程执行对应的任务)、后台管理程序(监控爬虫的工作状态以及检查数据抓取的结果)等的参与。
爬虫的工作流程
- 设定抓取目标(种子页面/起始页面)并获取网页。
- 当服务器无法访问时,按照指定的重试次数尝试重新下载页面。
- 在需要的时候设置用户代理或隐藏真实IP,否则可能无法访问页面。
- 对获取的页面进行必要的解码操作然后抓取出需要的信息。
- 在获取的页面中通过某种方式(如正则表达式)抽取出页面中的链接信息。
- 对链接进行进一步的处理(获取页面并重复上面的动作)。
- 将有用的信息进行持久化以备后续的处理。

第32课:用Python获取网络数据
requests库
按照官方网站的解释,requests是基于 Python 标准库进行了封装,简化了通过 HTTP 或 HTTPS 访问网络资源的操作。上课我们提到过,HTTP 是一个请求响应式的协议,当我们在浏览器中输入正确的 URL(通常也称为网址)并按下 Enter 键时,我们就向网络上的 Web 服务器发送了一个 HTTP 请求,服务器在收到请求后会给我们一个 HTTP 响应。在 Chrome 浏览器中的菜单中打开“开发者工具”切换到“Network”选项卡就能够查看 HTTP 请求和响应到底是什么样子的,如下图所示。
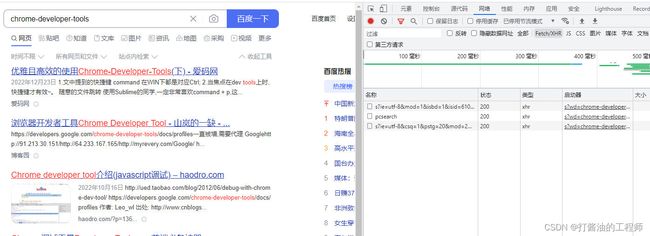
通过requests库,我们可以让 Python 程序向浏览器一样向 Web 服务器发起请求,并接收服务器返回的响应,从响应中我们就可以提取出想要的数据。浏览器呈现给我们的网页是用 HTML 编写的,浏览器相当于是 HTML 的解释器环境,我们看到的网页中的内容都包含在 HTML 的标签中。在获取到 HTML 代码后,就可以从标签的属性或标签体中提取内容。下面例子演示了如何获取网页 HTML 代码,我们通过requests库的get函数,获取了搜狐首页的代码。
import requests
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
print(resp.text)
说明:上面代码中的变量
resp是一个Response对象(requests库封装的类型),通过该对象的status_code属性可以获取响应状态码,而该对象的text属性可以帮我们获取到页面的 HTML 代码。
由于Response对象的text是一个字符串,所以我们可以利用之前讲过的正则表达式的知识,从页面的 HTML 代码中提取新闻的标题和链接,代码如下所示。
import re
import requests
pattern = re.compile(r'')
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
all_matches = pattern.findall(resp.text)
for href, title in all_matches:
print(href)
print(title)
除了文本内容,我们也可以使用requests库通过 URL 获取二进制资源。下面的例子演示了如何获取百度 Logo 并保存到名为baidu.png的本地文件中。可以在百度的首页上右键点击百度Logo,并通过“复制图片地址”菜单项获取图片的 URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png')
with open('baidu.png', 'wb') as file:
file.write(resp.content)

说明:
Response对象的content属性可以获得服务器响应的二进制数据。
requests库非常好用而且功能上也比较强大和完整,具体的内容我们在使用的过程中为大家一点点剖析。想解锁关于requests库更多的知识,可以阅读它的官方文档。
编写爬虫代码[豆瓣电影]
接下来,我们以“豆瓣电影”为例,为大家讲解如何编写爬虫代码。按照上面提供的方法,我们先使用requests获取到网页的HTML代码,然后将整个代码看成一个长字符串,这样我们就可以使用正则表达式的捕获组从字符串提取我们需要的内容。下面的代码演示了如何从豆瓣电影获取排前250名的电影的名称。豆瓣电影Top250的页面结构和对应代码如下图所示,可以看出,每页共展示了25部电影,如果要获取到 Top250 数据,我们共需要访问10个页面,对应的地址是https://movie.douban.com/top250?start=xxx,这里的xxx如果为0就是第一页,如果xxx的值是100,那么我们可以访问到第五页。为了代码简单易读,我们只获取电影的标题和评分。
import random
import re
import time
import requests
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出不是浏览器而阻止我们的请求。
# 通过get函数的headers参数设置User-Agent的值,具体的值可以在浏览器的开发者工具查看到。
# 用爬虫访问大部分网站时,将爬虫伪装成来自浏览器的请求都是非常重要的一步。
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
)
# 通过正则表达式获取class属性为title且标签体不以&开头的span标签并用捕获组提取标签内容
pattern1 = re.compile(r'([^&]*?)')
titles = pattern1.findall(resp.text)
# 通过正则表达式获取class属性为rating_num的span标签并用捕获组提取标签内容
pattern2 = re.compile(r'')
ranks = pattern2.findall(resp.text)
# 使用zip压缩两个列表,循环遍历所有的电影标题和评分
for title, rank in zip(titles, ranks):
print(title, rank)
# 随机休眠1-5秒,避免爬取页面过于频繁
time.sleep(random.random() * 4 + 1)
说明:通过分析豆瓣网的robots协议,我们发现豆瓣网并不拒绝百度爬虫获取它的数据,因此我们也可以将爬虫伪装成百度的爬虫,将
get函数的headers参数修改为:headers={'User-Agent': 'BaiduSpider'}。
使用 IP 代理[蘑菇代理]
让爬虫程序隐匿自己的身份对编写爬虫程序来说是比较重要的,很多网站对爬虫都比较反感的,因为爬虫会耗费掉它们很多的网络带宽并制造很多无效的流量。要隐匿身份通常需要使用商业 IP 代理(如蘑菇代理、芝麻代理、快代理等),让被爬取的网站无法获取爬虫程序来源的真实 IP 地址,也就无法简单的通过 IP 地址对爬虫程序进行封禁。
下面以蘑菇代理为例,为大家讲解商业 IP 代理的使用方法。首先需要在该网站注册一个账号,注册账号后就可以购买相应的套餐来获得商业 IP 代理。作为商业用途,建议大家购买不限量套餐,这样可以根据实际需要获取足够多的代理 IP 地址;作为学习用途,可以购买包时套餐或根据自己的需求来决定。蘑菇代理提供了两种接入代理的方式,分别是 API 私密代理和 HTTP 隧道代理,前者是通过请求蘑菇代理的 API 接口获取代理服务器地址,后者是直接使用统一的入口(蘑菇代理提供的域名)进行接入。
下面,我们以HTTP隧道代理为例,为大家讲解接入 IP 代理的方式,大家也可以直接参考蘑菇代理官网提供的代码来为爬虫设置代理。
import requests
APP_KEY = 'Wnp******************************XFx'
PROXY_HOST = 'secondtransfer.moguproxy.com:9001'
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 需要在HTTP请求头设置代理的身份认证方式
headers={
'Proxy-Authorization': f'Basic {APP_KEY}',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4'
},
# 设置代理服务器
proxies={
'http': f'http://{PROXY_HOST}',
'https': f'https://{PROXY_HOST}'
},
verify=False
)
pattern1 = re.compile(r'([^&]*?)')
titles = pattern1.findall(resp.text)
pattern2 = re.compile(r'')
ranks = pattern2.findall(resp.text)
for title, rank in zip(titles, ranks):
print(title, rank)
说明:上面的代码需要修改
APP_KEY为自己创建的订单对应的Appkey值,这个值可以在用户中心用户订单中查看到。蘑菇代理提供了免费的 API 代理和 HTTP 隧道代理试用,但是试用的代理接通率不能保证,建议大家还是直接购买一个在自己支付能力范围内的代理服务来体验。另注:蘑菇代理目前已经停止服务了,大家可以按照上面讲解的方式使用其他商业代理即可。
第33课:用Python解析HTML页面
HTML 页面的结构
我们在浏览器中打开任意一个网站,然后通过鼠标右键菜单,选择“显示网页源代码”菜单项,就可以看到网页对应的 HTML 代码。
代码的第1行是文档类型声明,第2行的标签是整个页面根标签的开始标签,最后一行是根标签的结束标签。标签下面有两个子标签和,放在标签下的内容会显示在浏览器窗口中,这部分内容是网页的主体;放在标签下的内容不会显示在浏览器窗口中,但是却包含了页面重要的元信息,通常称之为网页的头部。HTML 页面大致的代码结构如下所示。
标签、层叠样式表(CSS)、JavaScript 是构成 HTML 页面的三要素,其中标签用来承载页面要显示的内容,CSS 负责对页面的渲染,而 JavaScript 用来控制页面的交互式行为。要实现 HTML 页面的解析,可以使用 XPath 的语法,它原本是 XML 的一种查询语法,可以根据 HTML 标签的层次结构提取标签中的内容或标签属性;此外,也可以使用 CSS 选择器来定位页面元素,就跟用 CSS 渲染页面元素是同样的道理。
XPath 解析
XPath 是在 XML(eXtensible Markup Language)文档中查找信息的一种语法,XML 跟 HTML 类似也是一种用标签承载数据的标签语言,不同之处在于 XML 的标签是可扩展的,可以自定义的,而且 XML 对语法有更严格的要求。XPath 使用路径表达式来选取 XML 文档中的节点或者节点集,这里所说的节点包括元素、属性、文本、命名空间、处理指令、注释、根节点等。下面我们通过一个例子来说明如何使用 XPath 对页面进行解析。
Harry Potter
29.99
Learning XML
39.95
对于上面的 XML 文件,我们可以用如下所示的 XPath 语法获取文档中的节点。
| 路径表达式 | 结果 |
|---|---|
/bookstore |
选取根元素 bookstore。注意:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
//book |
选取所有 book 子元素,而不管它们在文档中的位置。 |
//@lang |
选取名为 lang 的所有属性。 |
/bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素。 |
/bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素。 |
/bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
//title[@lang] |
选取所有拥有名为 lang 的属性的 title 元素。 |
//title[@lang='eng'] |
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
/bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
/bookstore/book[price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
XPath还支持通配符用法,如下所示。
| 路径表达式 | 结果 |
|---|---|
/bookstore/* |
选取 bookstore 元素的所有子元素。 |
//* |
选取文档中的所有元素。 |
//title[@*] |
选取所有带有属性的 title 元素。 |
如果要选取多个节点,可以使用如下所示的方法。
| 路径表达式 | 结果 |
|---|---|
//book/title | //book/price |
选取 book 元素的所有 title 和 price 元素。 |
//title | //price |
选取文档中的所有 title 和 price 元素。 |
/bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
说明:上面的例子来自于“菜鸟教程”网站上的 XPath 教程,有兴趣的读者可以自行阅读原文。
当然,如果不理解或不熟悉 XPath 语法,可以在浏览器的开发者工具中按照如下所示的方法查看元素的 XPath 语法,下图是在 Chrome 浏览器的开发者工具中查看豆瓣网电影详情信息中影片标题的 XPath 语法。
[外链图片转存中…(img-yFxgktyC-1680235905964)]
实现 XPath 解析需要三方库lxml 的支持,可以使用下面的命令安装lxml。
pip install lxml
下面我们用 XPath 解析方式改写之前获取豆瓣电影 Top250的代码,如下所示。
from lxml import etree
import requests
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
headers={'User-Agent': 'BaiduSpider'}
)
tree = etree.HTML(resp.text)
# 通过XPath语法从页面中提取电影标题
title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]')
# 通过XPath语法从页面中提取电影评分
rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]')
for title_span, rank_span in zip(title_spans, rank_spans):
print(title_span.text, rank_span.text)
CSS 选择器解析
对于熟悉 CSS 选择器和 JavaScript 的开发者来说,通过 CSS 选择器获取页面元素可能是更为简单的选择,因为浏览器中运行的 JavaScript 本身就可以document对象的querySelector()和querySelectorAll()方法基于 CSS 选择器获取页面元素。在 Python 中,我们可以利用三方库beautifulsoup4或pyquery来做同样的事情。Beautiful Soup 可以用来解析 HTML 和 XML 文档,修复含有未闭合标签等错误的文档,通过为待解析的页面在内存中创建一棵树结构,实现对从页面中提取数据操作的封装。可以用下面的命令来安装 Beautiful Soup。
pip install beautifulsoup4
下面是使用bs4改写的获取豆瓣电影Top250电影名称的代码。
import bs4
import requests
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
headers={'User-Agent': 'BaiduSpider'}
)
# 创建BeautifulSoup对象
soup = bs4.BeautifulSoup(resp.text, 'lxml')
# 通过CSS选择器从页面中提取包含电影标题的span标签
title_spans = soup.select('div.info > div.hd > a > span:nth-child(1)')
# 通过CSS选择器从页面中提取包含电影评分的span标签
rank_spans = soup.select('div.info > div.bd > div > span.rating_num')
for title_span, rank_span in zip(title_spans, rank_spans):
print(title_span.text, rank_span.text)
关于 BeautifulSoup 更多的知识,可以参考它的官方文档。
简单的总结
下面我们对三种解析方式做一个简单比较。
| 解析方式 | 对应的模块 | 速度 | 使用难度 |
|---|---|---|---|
| 正则表达式解析 | re |
快 | 困难 |
| XPath 解析 | lxml |
快 | 一般 |
| CSS 选择器解析 | bs4或pyquery |
不确定 | 简单 |
TIPS1:wireshark简介
原文链接
wireshark是捕获机器上的某一块网卡的网络包,当你的机器上有多块网卡的时候,你需要选择一个网卡。
wireshark能获取HTTP,也能获取HTTPS,但是不能解密HTTPS,所以wireshark看不懂HTTPS中的内容。如果是处理HTTP,HTTPS 还是用Fiddler, 其他协议比如TCP,UDP 就用wireshark。