第二章、 数据类型与变量
目录
一、字面常量
二、数据类型
2.1基本数据类型:四类八种
3.变量
3.1概念
3.2语法格式
3.2.1语法格式
3.2.2变量命名规则
阿里巴巴命名规范细节:
3.3整型变量
3.3.1整型变量
3.3.2长整型变量
3.3.3短整型变量
3.3.4字节型变量
3.4浮点型数据
3.4.1双精度浮点型
3.4.2单精度浮点型
3.5字符型变量
3.6布尔类型数据
3.7类型转换
3.7.1自动类型转换(隐式)
3.7.2强制类型转换(显式)
3.8类型提升
4.字符串类型
一、字面常量
常量:即程序运行期间,固定不变的量称为常量。例如生活中的一个礼拜七天,一年12个月等等。
在上节笔记的程序中,System.Out.println("Hello World");语句中双引号引起来的“Hello World”就是字面常量。
public static void main(String[] args) {
//整型常量
System.out.println(100);
//浮点型常量
System.out.println(3.1415926);
//字符型常量
System.out.println('A');
//布尔常量
System.out.println(true);
System.out.println(false);
//字符串常量
System.out.println("Hello World!");
}字面常量的分类:
- 字符串常量:由双引号括起来的,如上面的Hello World!
- 整形常量:程序中直接写的数字,不带小数点(100,1000);
- 浮点型常量:程序中直接写的小数。(3.1415926,2.71828);
- 字符常量:单引号括起来的单个字符:'A','b';
- 布尔常量:true和false
- 空常量:null(后面会讲)
注意:字符串、整型、浮点型、字符型、布尔类型都称作数据类型。
二、数据类型
在Java中数据类型主要分为两类:基本数据类型和引用数据类型。
2.1基本数据类型:四类八种
1.四类:整型、浮点型、字符型、布尔类型
2.八种:
public static void main(String[] args){
//1.定义byte类型的变量
//数据类型 变量名 = 数据值;
byte a = 10;
System.out.println(a);
//2.定义short类型的变量
short b = 20;
System.out.println(b);
//3.定义int类型的变量
int c = 30;
System.out.println(c);
//4.定义long类型的变量
long d = 123456789123456789L;
System.out.println(d);
//5.定义float类型的变量
float e = 10.1F;
System.out.println(e);
//6.定义double类型的变量
double f = 20.3;
System.out.println(f);
//7.定义char类型的变量
char g = 'a';
System.out.println(g);
//8.定义boolean类型的变量
boolean h = true;
System.out.println(h);
}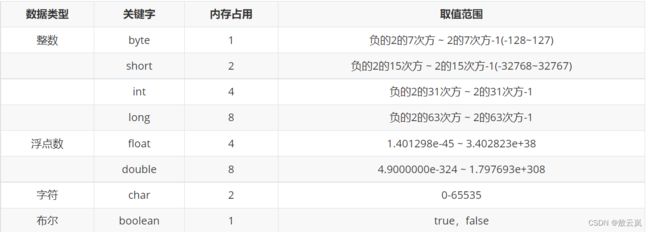
注意:
- 不论是在16位系统还是32位系统,int都占用4个字节,long都占8个字节
- 整形和浮点型都是带有符号的(不存在无符号一说)
- 整型默认为int型,浮点型默认为double
- e+38表示是乘以10的38次方,同样,e-45表示乘以10的负45次方。
- 字符串属于引用类型,后续关注博主博客
什么是字节?
字节是计算机中表示空间大小的基本单位,计算机使用二进制表示数据. 我们认为 8 个二进制位(bit) 为一个字节(Byte)。我们平时的计算机为 8GB 内存, 意思是 8G 个字节。其中 1KB = 1024 Byte, 1MB = 1024 KB, 1GB = 1024 MB。所以 8GB 相当于 80 多亿个字节。
2.2引用数据类型
后续介绍(注意:String字符串属于引用数据类型)
三、变量
3.1概念
在程序中,除了有始终不变的常量外,有些内容可能会经常改变,比如:人的年龄、身高、成绩分数、数学函数的计算结果等,对于这些经常改变的内容,在Java程序中,称为变量。而数据类型是用来定义不同种类变量的。
3.2语法格式
3.2.1语法格式
访问权限修饰符 数据类型 变量名 = 初始值;
(访问权限修饰符后续讲)
//定义了一个int型变量num,赋值为10
int num=10;
//定义了一个double型变量pi,赋值为3.14
double pi=3.14;
//定义了一个布尔类型变量flag,赋值为true
boolean flag=true;
System.out.println(num);
System.out.println(pi);
System.out.println(flag);
num=20;//num是变量,num中的值是可以修改的,注意:= 在java中表示赋值,即将20交给a,a中保
存的值就是20
System.out.println(num);
// 注意:在一行可以定义多个相同类型的变量
int b=15,c=30,d=20;
System.out.println(b);
System.out.println(c);
System.out.println(d);
//输出结果如下:
/*10
3.14
true
20
15
30
20*/3.2.2变量命名规则
!小驼峰命名法--->适用于变量名和方法名!
-
如果是一个写,比如:name单词,那么全部小
-
如果是多个单词,那么从第二个单词开始,首字母大写,比如:firstName、maxAge
!大驼峰命名法--->适用于类名!
-
如果是一个单词,那么首字母大写。比如:Demo、Test。
-
如果是多个单词,那么每一个单词首字母都需要大写。比如:HelloWorld
阿里巴巴命名规范细节:
尽量不要用拼音。但是一些国际通用的拼音可视为英文单词。
正确:alibaba、hangzhou、nanjing
错误:jiage、dazhe
平时在给变量名、方法名、类名起名字的时候,不要使用下划线或美元符号。
错误:_name
正确:name
3.3整型变量
3.3.1整型变量
// 方式一:在定义时给出初始值
int a = 10;
System.Out.println(a);
// 方式二:在定义时没有给初始值,但使用前必须设置初值
int b;
b = 10;
System.Out.println(b);
// 使用方式二定义后,在使用前如果没有赋值,则编译期间会报错
int c;
System.Out.println(c);
c = 100;
// int型变量所能表示的范围:
//Integer是int的包装类,后续讲解
System.Out.println(Integer.MIN_VALUE);
System.Out.println(Integer.MAX_VALUE);
// 注意:在定义int性变量时,所赋值不能超过int的范围
int d = 12345678901234; // 编译时报错,初值超过了int的范围注意事项:
-
int不论在何种系统下都是4个字节
-
推荐使用方式一定义,如果没有合适的初始值,可以设置为0
-
在给变量设置初始值时,值不能超过int的表示范围,否则会导致溢出
-
变量在使用之前必须要赋初值,否则编译报错
-
int的包装类型为 Integer
3.3.2长整型变量
int a = 10;
long b = 10; // long定义的长整型变量
long c = 10L; // 为了区分int和long类型,一般建议:long类型变量的初始值之后加L或者l
long d = 10l; // 一般更加以加大写L,因为小写l与1不好区分
// long型变量所能表示的范围:这个数据范围远超过 int 的表示范围. 足够绝大部分的工程场景使用.
System.Out.println(Long.MIN_VALUE);
System.Out.println(Long.MAX_VALUE);注意事项:
-
长整型变量的初始值后加L或者l,推荐加L
-
长整型不论在那个系统下都占8个字节
-
long的包装类型为Long
3.3.3短整型变量
short a = 10;
System.Out.println(a);
// short型变量所能表示的范围:
System.Out.println(Short.MIN_VALUE);
System.Out.println(Short.MAX_VALUE);注意事项:
-
short在任何系统下都占2个字节
-
使用时注意不要超过范围(一般使用比较少)
-
short的包装类型为Short
3.3.4字节型变量
byte b = 10;
System.Out.println(b);
// byte型变量所能表示的范围:
System.Out.println(Byte.MIN_VALUE);
System.Out.println(Byte.MAX_VALUE);注意事项:
-
byte在任何系统下都占1个字节
-
字节的包装类型为Byte
思考:byte、short、int、long都可以定义整形变量,为什么要给出4种不同类型呢?
类比生活中衣服的尺码
3.4浮点型数据
3.4.1双精度浮点型
double d = 3.14;
System.Out.println(d);
//------------------
int a = 1;
int b = 2;
System.out.println(a / b); // 输出 0.5 吗?在 Java 中, int 除以 int 的值仍然是 int(会直接舍弃小数部分)。如果想得到 0.5, 需要使用 double 类型计算
double a = 1.0;
double b = 2.0;
System.out.println(a / b); // 输出0.5double num = 1.1;
System.out.println(num * num); // 输出1.21吗?
// 执行结果
1.2100000000000002注意事项:
-
double在任何系统下都占8个字节
-
浮点数与整数在内存中的存储方式不同,不能单纯使用 幂函数的形式来计算(详细看博主的C原反补博客)
-
double的包装类型为Double
-
double 类型的内存布局遵守 IEEE 754 标准(和C语言一样), 尝试使用有限的内存空间表示可能无限的小数, 势必会存在一定的精度误差,因此浮点数是个近似值,并不是精确值。
3.4.2单精度浮点型
float num = 1.0f; // 写作 1.0F 也可以
System.out.println(num);float 类型在 Java 中占四个字节, 同样遵守 IEEE 754 标准. 由于表示的数据精度范围较小, 一般在工程上用到浮点数都优先考虑 double, 不太推荐使用 float. float的包装类型为Float。
3.5字符型变量
char c1 = 'A'; // 大写字母
char c2 = '1'; // 数字字符
System.out.println(c1);
System.out.println(c2);
//A
//1
// 注意:java中的字符可以存放整形
char c3 = '帅';
System.out.println(c3);注意事项:
-
ava 中使用 单引号 + 单个字母 的形式表示字符字面值。
-
计算机中的字符本质上是一个整数. 在 C 语言中使用 ASCII 表示字符, 而 Java 中使用 Unicode 表示字符. 因此一个字符占用两个字节, 表示的字符种类更多, 包括中文
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
- 在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。
- UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式
- 例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:char data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97};//UTF-8编码
char16_t data_utf16[]={0x6C49,0x5B57}; //UTF-16编码
char32_t data_utf32[]={0x00006C49,0x00005B57};//UTF-32编码这里用char、char16_t、char32_t分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以char、char16_t、char32_t作为编码单位。(注: char16_t 和 char32_t 是 C++ 11 标准新增的关键字。如果你的编译器不支持 C++ 11 标准,请改用 unsigned short 和 unsigned long。)“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个char16_t,大小是4个字节。“汉字”的UTF-32编码需要两个char32_t,大小是8个字节。根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。
感兴趣的同学可以了解一下UTF-8编码和GBK编码
char ch = '呵';
System.out.println(ch);执行 javac 的时候可能出现以下错误:
Test.java:3: 错误: 未结束的字符文字
char ch = '鍛?';
^
//因为编码规则的不同导致报错此时我们在执行 javac 时加上 -encoding UTF-8 选项即可
javac -encoding UTF-8 Test.java
//可以解决问题注意:char的包装类型为Character
3.6布尔类型数据
布尔类型常用来表示真假
boolean b = true;
System.out.println(b);
b = false;
System.out.println(b);注意事项:
-
boolean 类型的变量只有两种取值, true 表示真, false 表示假
-
Java 的 boolean 类型和 int 不能相互转换, 不存在 1 表示 true, 0 表示 false 这样的用法
-
boolean的包装类型为Boolean
boolean value = true;
System.out.println(value + 1);
// 代码编译会出现如下错误
Test.java:4: 错误: 二元运算符 '+' 的操作数类型错误
System.out.println(value + 1);
^
第一个类型: boolean
第二个类型: int
1 个错误Java虚拟机规范中,并没有明确规定boolean占几个字节,也没有专门用来处理boolean的字节码指令,在Oracle公司的虚拟机实现中,boolean占1个字节
3.7类型转换
Java 作为一个强类型编程语言, 当不同类型之间的变量相互赋值的时候, 会有教严格的校验
int a = 10;
long b = 100L;
b = a; // 可以通过编译
a = b; // 编译失败在Java中,当参与运算数据类型不一致时,就会进行类型转换。Java中类型转换主要分为两类:自动类型转换(隐式) 和 强制类型转换(显式)。
3.7.1自动类型转换(隐式)
自动类型转换即:代码不需要经过任何处理,在代码编译时,编译器会自动进行处理。特点:数据范围小的转为数据范围大的时会自动进行。
System.Out.println(1024); // 整型默认情况下是int
System.Out.println(3.14); // 浮点型默认情况下是double
int a = 100;
long b = 10L;
b = a; // a和b都是整形,a的范围小,b的范围大,当将a赋值给b时,编译器会自动将a提升为long类型,然后赋值
a = b; // 编译报错,long的范围比int范围大,会有数据丢失,不安全
float f = 3.14F;
double d = 5.12;
d = f; // 编译器会将f转换为double,然后进行赋值
f = d; // double表示数据范围大,直接将float交给double会有数据丢失,不安全
byte b1 = 100; // 编译通过,100没有超过byte的范围,编译器隐式将100转换为byte
byte b2 = 257; // 编译失败,257超过了byte的数据范围,有数据丢失3.7.2强制类型转换(显式)
强制类型转换:当进行操作时,代码需要经过一定的格式处理,不能自动完成。特点:数据范围大的到数据范围小的
int a = 10;
long b = 100L;
b = a; // int-->long,数据范围由小到大,隐式转换
a = (int)b; // long-->int, 数据范围由大到小,需要强转,否则编译失败
float f = 3.14F;
double d = 5.12;
d = f; // float-->double,数据范围由小到大,隐式转换
f = (float)d; // double-->float, 数据范围由大到小,需要强转,否则编译失败
a = d; // 报错,类型不兼容
a = (int)d; // int没有double表示的数据范围大,需要强转,小数点之后全部丢弃
byte b1 = 100; // 100默认为int,没有超过byte范围,隐式转换
byte b2 = (byte)257; // 257默认为int,超过byte范围,需要显示转换,否则报错
boolean flag = true;
a = flag; // 编译失败:类型不兼容
flag = a; // 编译失败:类型不兼容注意事项:
-
不同数字类型的变量之间赋值, 表示范围更小的类型能隐式转换成范围较大的类型
-
如果需要把范围大的类型赋值给范围小的, 需要强制类型转换, 但是可能精度丢失
-
将一个字面值常量进行赋值的时候, Java 会自动针对数字范围进行检查
-
强制类型转换不一定能成功,不相干的类型不能互相转换
3.8类型提升
不同类型的数据之间相互运算时,数据类型小的会被提升到数据类型大的
1.int与long之间:int会被提升为long
int a = 10;
long b = 20;
int c = a + b; // 编译出错: a + b==》int + long--> long + long 赋值给int时会丢失数据
long d = a + b; // 编译成功:a + b==>int + long--->long + long 赋值给long2.byte与byte的运算
byte a = 10;
byte b = 20;
byte c = a + b;
System.out.println(c);
// 编译报错
Test.java:5: 错误: 不兼容的类型: 从int转换到byte可能会有损失
byte c = a + b;
^
//修改---->
byte a = 10;
byte b = 20;
byte c = (byte)(a + b);
System.out.println(c);结论: byte 和 byte 都是相同类型, 但是出现编译报错. 原因是, 虽然 a 和 b 都是 byte, 但是计算 a + b 会先将 a和 b 都提升成 int, 再进行计算, 得到的结果也是 int, 这是赋给 c, 就会出现上述错误。由于计算机的 CPU 通常是按照 4 个字节为单位从内存中读写数据. 为了硬件上实现方便, 诸如 byte 和 short这种低于 4 个字节的类型, 会先提升成 int, 再参与计算
注意:对于 short, byte 这种比 4 个字节小的类型, 会先提升成 4 个字节的 int , 再运算
4.字符串类型
(关注后续博客,重点讲解字符串)简单介绍---
public static void main(String[] args) {
String s1 = "hello";
String s2 = " world";
System.out.println(s1);
System.out.println(s2);
System.out.println(s1+s2); // s1+s2表示:将s1和s2进行拼接
}1.int 转成 String
int num = 10;
// 方法1
String str1 = num + "";
// 方法2
String str2 = String.valueOf(num);2.String 转成 int
String str = "100";
int num = Integer.parseInt(str);