用Flink SQL流化市场数据2:盘中风险价值
本文是一个由多部分组成的系列文章的第二篇,该系列文章展示了FlinkSQL应用于市场数据的功能和可表达性。万一您错过了它,第一部分从计算流VWAP的简单情况开始。该系列的代码和数据可在github上获得。 速度在金融市场上至关重要。无论目标是最大化alpha还是最大程度地减少风险,金融技术人员都会投入大量资金,以获取有关市场状况以及行情的最新见解。事件驱动和流式处理体系结构可在事件发生时对事件进行复杂的处理,使其很自然地适合金融市场应用。
Flink SQL是一种数据处理语言,可用于事件驱动和流应用程序的快速原型设计和开发。Flink SQL将SQL的简单性和可访问性与Apache Flink(一种流行的分布式流媒体平台)的性能和可伸缩性结合在一起。借助Flink SQL,业务分析人员、开发人员和量化人员都可以快速建立流传输管道,以实时执行复杂的数据分析。
在本文中,我们将使用Simudyne开发的基于代理的模型(ABM)生成的综合市场数据。ABM并不是自上而下的方法,而是在复杂系统中对自主参与者(或代理)进行建模,例如,金融市场中的各种买卖双方。可以捕获这些交互,并可以针对许多应用程序分析生成的综合数据集,例如用于检测紧急欺诈行为的培训模型,或探索风险管理的“假设”场景。ABM生成的综合数据在历史数据不足或不可用的情况下很有用。
1 盘中VaR
风险价值(VaR)是风险管理中广泛使用的指标。它有助于识别风险敞口,为交易前的决策提供依据,并报告给监管机构进行压力测试。在给定的置信度和时间范围内,VaR将风险表示为货币金额,指示资产未来可能发生的最坏损失。例如,AAPL的1天10美元的99%VaR表示100的99倍,第二天AAPL的损失不会超过10美元。
计算股票的VaR的一种常见方法是获取历史日末收益(例如最近500个交易日的每日收盘价变化)并将其视为可能的未来收益的分布。VaR是第99个百分位数(或500天中第5个最差回报率)的最差每日收益乘以当前资产值。假设收益率服从正态分布,则计算VaR的另一种方法是将标准偏差乘以与所需置信区间相对应的z分数,在本例中,均值的99%置信区间为-2.58。将结果数字加到平均收益上,然后乘以当前资产价值即可得出VaR。
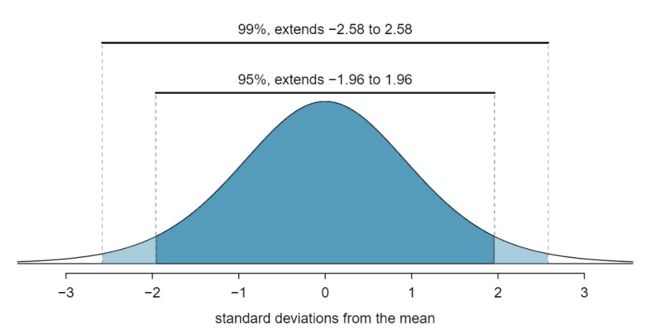
图片来源:https://spot.pcc.edu/~evega/ConfidenceIntervals.html 在大多数市场风险应用中,VaR公式是基于日末定价并每天分批计算的。自从JP Morgan在1980年代发明VaR以来,这种做法在风险管理中很普遍。从那时起,研究人员提出了用于计算日内VaR的方法[1],该方法受现代市场不断发展的结构和动态驱动:
在过去的几年中,交易速度一直在不断提高。即日交易,现在是场内交易者的专属区域,现在所有投资者都可以使用。“高频金融对冲基金”已经成为对冲基金的一个成功的新类别。因此,风险管理现在必须与市场保持同步。对于日间交易者,做市商或市场上其他活跃的经纪人,应以短于每日的时间间隔评估风险,因为他们的投资期限通常少于一天。
本文中,我们探讨了如何使用流式SQL从实时报价数据流中计算日内VaR(IVaR)。具体来说,我们将根据前5分钟的定价数据,每秒计算出99%的IVaR。在本练习中,我们将使用Simudyne生成的综合市场数据。他们为我们提供了CSV格式的1级刻度数据,以实现虚拟安全性(“ SIMUl ”):
time,sym,best_bid_prc,best_bid_vol,tot_bid_vol,num,sym,best_ask_prc,best_ask_vol,tot_ask_vol,num
2020-10-22 08:00:00.000,SIMUl,149.34,2501,17180,1,SIMUl,150.26,2501,17026,1
2020-10-22 08:00:01.020,SIMUl,149.34,2901,17580,2,SIMUl,150.26,2501,17026,1
2020-10-22 08:00:02.980,SIMUl,149.36,3981,21561,1,SIMUl,150.26,2501,17026,1
2020-10-22 08:00:05.000,SIMUl,149.36,3981,21561,1,SIMUl,149.86,2300,19326,1
2020-10-22 08:00:05.460,SIMUl,149.36,3981,21561,1,SIMUl,149.86,6279,23305,2
2020-10-22 08:00:05.580,SIMUl,149.36,3981,21561,1,SIMUl,149.86,6279,23305,2
2020-10-22 08:00:06.680,SIMUl,149.36,3981,21561,1,SIMUl,149.86,6279,23305,2
2020-10-22 08:00:07.140,SIMUl,149.74,582,22143,1,SIMUl,149.86,6279,23305,2
2020-10-22 08:00:07.600,SIMUl,149.74,582,22143,1,SIMUl,149.86,2044,19070,1
2020-10-22 08:00:08.540,SIMUl,149.74,582,22143,1,SIMUl,149.86,2044,19070,1
级别1的报价数据在给定的即时时间内传达了证券交易簿中的最佳买入价和最佳卖出价。我们主要关注交易品种和时间戳,以及市场中间价,我们可以通过平均最佳买入价和要价来获取中间价。为了使Flink SQL处理此数据,我们首先通过以下语句声明一个流表:
event_time TIMESTAMP(3),
symbol STRING,
best_bid_prc DOUBLE,
best_bid_vol INT,
tot_bid_vol INT,
num INT,
sym2 STRING,
best_ask_prc DOUBLE,
best_ask_vol INT,
tot_ask_vol INT,
num2 INT,
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECONDS
) WITH (
'connector' = 'filesystem',
'path' = '/path/to/varstream/data/l1_raw',
'format' = 'csv'
) ;
2 Flink SQL中的时间序列采样
为了计算IVaR,我们需要在过去5分钟内分配每秒回报(中间价格与前一秒的变化百分比)。如果我们将L1数据视为一个时间序列,则需要每秒采样一次中间价格。实现此目的的一种方法是向前填充:每秒采样的中间价格是该秒之前或该秒之前的最后观察到的中间价格。
本能地,我们可以尝试使用翻滚窗口来执行此操作,就像我们在第一部分中计算VWAP所做的那样。但是,此方法将不起作用。考虑下面的滚动窗口查询:
SELECT
symbol,
TUMBLE_START (event_time, INTERVAL '1' SECOND) AS start_time,
TUMBLE_ROWTIME (event_time, INTERVAL '1' SECOND) AS row_time,
LAST_VALUE (best_bid_prc) AS best_bid_prc,
LAST_VALUE (best_ask_prc) AS best_ask_prc
FROM
l1
GROUP BY
TUMBLE (event_time, INTERVAL '1' SECOND), symbol
LIMIT 20
滚动窗口可能会导致间隙,如下所示。

该查询在8 : 00: 03,8 : 00 :04和8:00:13没有产生任何记录。这是因为在源L1数据中,在第二个时间间隔内没有事件。潜在地,可以通过使用跳跃窗口来解决此问题,并具有足够的回溯期以确保在此期间观察到一个事件:
SELECT
symbol,
HOP_START (event_time, INTERVAL '1' SECOND, INTERVAL '120' SECONDS) AS start_time,
HOP_ROWTIME (event_time, INTERVAL '1' SECOND, INTERVAL '120' SECONDS) AS row_time,
LAST_VALUE (best_bid_prc) AS best_bid_prc,
LAST_VALUE (best_ask_prc) AS best_ask_prc
FROM
l1
GROUP BY
HOP (event_time, INTERVAL '1' SECOND, INTERVAL '120' SECONDS), symbol
LIMIT 20
不幸的是,上述查询无法运行,因为在编写本文时,LAST_VALUE函数不适用于跳跃窗口。Flink社区正在致力于修复(FLINK-20110)。同时,我们提出了一种不依赖于跳变窗口或回溯期的解决方法。
首先,我们得出每行的有效时间范围(开始和结束时间):
CREATE VIEW l1_times AS
SELECT
symbol,
MIN (event_time) OVER w AS start_time,
CAST (event_time AS TIMESTAMP) AS end_time,
FIRST
FIRST_VALUE (best_ask_prc) OVER w AS ask_price
FROM l1
WINDOW w AS (
PARTITION BY symbol
ORDER BY event_time
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
)
;
*请注意使用MIN(event_time)而不是FIRST_VALUE(event_time)-当前,FIRST_VALUE函数不支持TIMESTAMP类型。
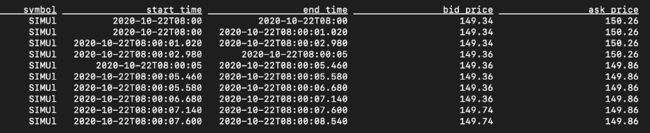
该视图在保留前一行的同时流式传输数据,并发出前一行的字段值以及当前行的event_time作为有效结束时间。针对该视图的查询将产生以下内容,该结果显示每行(第一行除外)现在具有包含的开始时间和排除的结束时间。
为了每秒发出一行,我们编写了一组用户定义的表函数(UDTF)。您可以在此处查看代码。该项目提供了有关如何构建二进制文件(.jar文件)以及如何将其与Flink SQL一起使用的简要说明。您需要发出CREATE FUNCTION语句来注册每个UDTF,然后才能在查询中使用它们:
CREATE FUNCTION fill_sample_per_day AS 'varstream.FillSample$PerDayFunction' LANGUAGE JAVA ;
CREATE FUNCTION fill_sample_per_hour AS 'varstream.FillSample$PerHourFunction' LANGUAGE JAVA ;
CREATE FUNCTION fill_sample_per_minute AS 'varstream.FillSample$PerMinuteFunction' LANGUAGE JAVA ;
CREATE FUNCTION fill_sample_per_second AS 'varstream.FillSample$PerSecondFunction' LANGUAGE JAVA ;
在查询中,UDTF具有以下语法:
fill_sample_by_timeunit (start_time, end_time, frequency)
时间单位可以是日、小时、分钟或秒。开始时间和排他性结束时间标记每行的有效时间,频率指示给定的天、小时、分钟或秒采样次数。因此,频率为6的fill_sample_by_hour将每10分钟采样一次(:00,:10,:20,:30,:40和:50)。调用fill_sample_by_minute具有60的频率是功能上相同fill_sample_by_second一个的频率。但是,由于UDTF实现的内部原因,by_second变体的性能会更好。
现在,我们可以创建一个每秒对流进行采样的视图。注意使用的INNER JOIN LATERAL TABLE ,这确保了所发射的行将由UDTF输出进行控制:
CREATE VIEW l1_sample AS
SELECT
symbol,
start_time,
end_time,
sample_time,
bid_price,
ask_price,
(bid_price + ask_price) / 2 AS mid_price
FROM l1_times AS l1
INNER JOIN LATERAL TABLE (fill_sample_per_minute (l1.start_time, l1.end_time, 60))
AS T(sample_time) ON TRUE
;
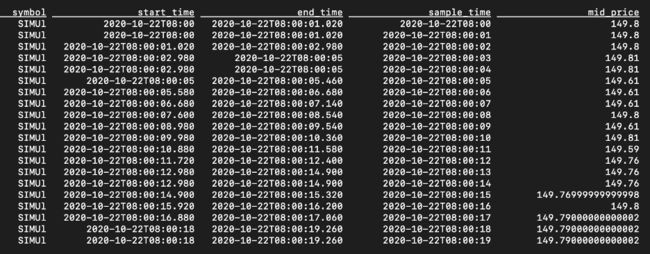
SELECT symbol, start_time, end_time, sample_time, mid_price FROM l1_sample ;
查询此视图将产生以下结果。
3 计算流内盘中VaR
现在我们有一个以秒为中间值采样的时间序列,我们可以开始计算流IVaR了。首先,我们需要计算每秒的回报,这就是当前价格减去之前的价格。为了得出先前的价格,我们再次使用OVER WINDOW语法:
CREATE VIEW l1_sample_prev AS
SELECT
symbol,
start_time,
sample_time,
mid_price,
FIRST_VALUE (mid_price) OVER w AS prev_price
FROM l1_sample
WINDOW w AS (
PARTITION BY symbol
ORDER BY start_time
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
)
;
为了获得第99个百分位数的回报,我们计算了过去300行的回溯窗口中的回报(以百分比表示),这是因为我们每秒采样的时间为5分钟。我们还计算了同一窗口的平均收益率和标准差。
CREATE VIEW l1_stddev AS
SELECT
symbol,
start_time,
sample_time,
mid_price,
(mid_price - prev_price) / prev_price AS pct_return,
AVG (mid_price) OVER lookback AS avg_price,
AVG ((mid_price - prev_price) / prev_price) OVER lookback AS avg_return,
STDDEV_POP ((mid_price - prev_price) / prev_price) OVER lookback AS stddev_return
FROM l1_sample_prev
WINDOW lookback AS (
PARTITION BY symbol
ORDER BY start_time
ROWS BETWEEN 300 PRECEDING AND CURRENT ROW
)
;
有了这些信息,我们可以通过将标准偏差与-2.58的Z得分相乘并将该数字加到平均收益中来得出第99个百分位数的最差收益。这在下面显示为var99_return。处于风险中的实际价值是当前中间价格乘以var99_return。在下面的查询中,我们希望显示该资产的99%可能的最差未来价格,因此我们将当前价格(mid_price)乘以1 + var99_return。
CREATE VIEW l1_var99 AS
SELECT
*,
avg_return - 2.58 * stddev_return AS var99_return,
mid_price * (1 + (avg_return - 2.58 * stddev_return)) AS var99_price
FROM
l1_stddev
;
SELECT symbol, sample_time, mid_price, var99_price FROM l1_var99

4 结论
随着高频交易和小型交易崩溃变得越来越普遍[2],了解盘中市场风险可能会像理解一个人的盘中风险一样有益,尤其是在使用高频算法时。幸运的是,借助像Flink这样的现代流媒体平台,以及像Flink SQL这样的易于使用的流编程语言,我们可以快速构建健壮的管道,以在市场数据实时到达时计算日内风险度量。 我们希望本系列文章能鼓励您尝试将Flink SQL用于流式市场数据应用程序。在下一部分中,我们将向您展示如何使用即将发布的Cloudera SQL Stream Builder版本(Cloudera Streaming Analytics 1.4版的一部分)尝试这些示例。 感谢Tim Spann,Felicity Liu,Jiyan Babaie-Harmon,Roger Teoh,Justin Lyon和Richard Harmon对这项工作的贡献。
5 引文
[1] Dionne,Georges和Duchesne,Pierre和Pacurar,Maria,使用逐笔交易数据并将其应用于多伦多证券交易所,其当日风险值(Ivar)(2005年12月13日)。在SSRN上可用:https ://ssrn.com/abstract=868594或http://dx.doi.org/10.2139/ssrn.868594
[2] Bayraktar,Erhan和Munk,Alexander,Mini-Flash Crash,模型风险和最佳执行力(2017年5月27日)。在SSRN上可用:https ://ssrn.com/abstract=2975769或http://dx.doi.org/10.2139/ssrn.2975769
原文作者:Patrick Angeles& Krishnen Vytelingum
原文链接:https://blog.cloudera.com/streaming-market-data-with-flink-sql-part-ii-intraday-value-at-risk/
关注微信公共号了解更多信息: 
本文由 mdnice 多平台发布