linux下多定时器的实现-(multimer implementation under linux)
概论
定时器属于基本的基础组件,不管是用户空间的程序开发,还是内核空间的程序开发,很多时候都需要有定时器作为基础组件的支持,但使用场景的不同,对定时器的实现考虑也不尽相同,本文讨论了在 Linux 环境下,应用层和内核层的定时器的各种实现方法,并分析了各种实现方法的利弊以及适宜的使用环境。
首先,给出一个基本模型,定时器的实现,需要具备以下几个行为,这也是在后面评判各种定时器实现的一个基本模型 [1]:
StartTimer(Interval, TimerId, ExpiryAction)
注册一个时间间隔为 Interval 后执行 ExpiryAction 的定时器实例,其中,返回 TimerId 以区分在定时器系统中的其他定时器实例。
StopTimer(TimerId)
根据 TimerId 找到注册的定时器实例并执行 Stop 。
PerTickBookkeeping()
在一个 Tick 内,定时器系统需要执行的动作,它最主要的行为,就是检查定时器系统中,是否有定时器实例已经到期。注意,这里的 Tick 实际上已经隐含了一个时间粒度 (granularity) 的概念。
ExpiryProcessing()
在定时器实例到期之后,执行预先注册好的 ExpiryAction 行为。
上面说了基本的定时器模型,但是针对实际的使用情况,又有以下 2 种基本行为的定时器:
Single-Shot Timer
这种定时器,从注册到终止,仅仅只执行一次。
Repeating Timer
这种定时器,在每次终止之后,会自动重新开始。本质上,可以认为 Repeating Timer 是在 Single-Shot Timer 终止之后,再次注册到定时器系统里的 Single-Shot Timer,因此,在支持 Single-Shot Timer 的基础上支持 Repeating Timer 并不算特别的复杂。
————————————————————————————————————————————————————————————————————————————
基于链表和信号实现定时器(2.4版内核情况下)
在 2.4 的内核中,并没有提供 POSIX timer [ 2 ]的支持,要在进程环境中支持多个定时器,只能自己来实现,好在 Linux 提供了 setitimer(2) 的接口。它是一个具有间隔功能的定时器 (interval timer),但如果想在进程环境中支持多个计时器,不得不自己来管理所有的计时器。 setitimer(2) 的定义如下:
清单 1. setitimer的原型
#include
int setitimer(int which, const struct itimerval *new_value,struct itimerval *old_value); setitimer 能够在 Timer 到期之后,自动再次启动自己,因此,用它来解决 Single-Shot Timer 和 Repeating Timer 的问题显得很简单。该函数可以工作于 3 种模式:
ITIMER_REAL 以实时时间 (real time) 递减,在到期之后发送 SIGALRM 信号
ITIMER_VIRTUAL 仅进程在用户空间执行时递减,在到期之后发送 SIGVTALRM 信号
ITIMER_PROF 进程在用户空间执行以及内核为该进程服务时 ( 典型如完成一个系统调用 ) 都会递减,与 ITIMER_VIRTUAL 共用时可度量该应用在内核空间和用户空间的时间消耗情况,在到期之后发送 SIGPROF 信号
定时器的值由下面的结构定义:
清单 2. setitimer 定时器的值定义
struct itimerval {
struct timeval it_interval; /* next value */
struct timeval it_value; /* current value */
};
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};setitimer() 以 new_value 设置特定的定时器,如果 old_value 非空,则它返回 which 类型时间间隔定时器的前一个值。定时器从 it_value 递减到零,然后产生一个信号,并重新设置为 it_interval,如果此时 it_interval 为零,则该定时器停止。任何时候,只要 it_value 设置为零,该定时器就会停止。
由于 setitimer() 不支持在同一进程中同时使用多次以支持多个定时器,因此,如果需要同时支持多个定时实例的话,需要由实现者来管理所有的实例。用 setitimer() 和链表,可以构造一个在进程环境下支持多个定时器实例的 Timer,在一般的实现中的 PerTickBookkeeping 时,会递增每个定时器的 elapse 值,直到该值递增到最初设定的 interval 则表示定时器到期。
基于链表实现的定时器可以定义为:
清单 3. 基于链表的定时器定义
typedef int timer_id;
/**
* The type of callback function to be called by timer scheduler when a timer
* has expired.
*
* @param id The timer id.
* @param user_data The user data.
* $param len The length of user data.
*/
typedef int timer_expiry(timer_id id, void *user_data, int len);
/**
* The type of the timer
*/
struct timer {
LIST_ENTRY(timer) entries;/**< list entry */
timer_id id; /**< timer id */
int interval; /**< timer interval(second) */
int elapse; /**< 0 -> interval */
timer_expiry *cb; /**< call if expiry */
void *user_data; /**< callback arg */
int len; /**< user_data length */
};定时器的时间间隔以 interval 表示,而 elapse 则在 PerTickBookkeeping() 时递增,直到 interval 表示定时器中止,此时调用回调函数 cb 来执行相关的行为,而 user_data 和 len 为用户可以传递给回调函数的参数。
所有的定时器实例以链表来管理:
清单 4. 定时器链表
/**
* The timer list
*/
struct timer_list {
LIST_HEAD(listheader, timer) header; /**< list header */
int num; /**< timer entry number */
int max_num; /**< max entry number */
void (*old_sigfunc)(int); /**< save previous signal handler */
void (*new_sigfunc)(int); /**< our signal handler */
struct itimerval ovalue; /**< old timer value */
struct itimerval value; /**< our internal timer value */
};清单 5. 定时器链表的创建和Destroy
/**
* Create a timer list.
*
* @param count The maximum number of timer entries to be supported initially.
*
* @return 0 means ok, the other means fail.
*/
int init_timer(int count)
{
int ret = 0;
if(count <=0 || count > MAX_TIMER_NUM) {
printf("the timer max number MUST less than %d.\n", MAX_TIMER_NUM);
return -1;
}
memset(&timer_list, 0, sizeof(struct timer_list));
LIST_INIT(&timer_list.header);
timer_list.max_num = count;
/* Register our internal signal handler and store old signal handler */
if ((timer_list.old_sigfunc = signal(SIGALRM, sig_func)) == SIG_ERR) {
return -1;
}
timer_list.new_sigfunc = sig_func;
/*Setting our interval timer for driver our mutil-timer and store old timer value*/
timer_list.value.it_value.tv_sec = TIMER_START;
timer_list.value.it_value.tv_usec = 0;
timer_list.value.it_interval.tv_sec = TIMER_TICK;
timer_list.value.it_interval.tv_usec = 0;
ret = setitimer(ITIMER_REAL, &timer_list.value, &timer_list.ovalue);
return ret;
}
/**
* Destroy the timer list.
*
* @return 0 means ok, the other means fail.
*/
int destroy_timer(void)
{
struct timer *node = NULL;
if ((signal(SIGALRM, timer_list.old_sigfunc)) == SIG_ERR) {
return -1;
}
if((setitimer(ITIMER_REAL, &timer_list.ovalue, &timer_list.value)) < 0) {
return -1;
}
while (!LIST_EMPTY(&timer_list.header)) { /* Delete. */
node = LIST_FIRST(&timer_list.header);
LIST_REMOVE(node, entries);
/* Free node */
printf("Remove id %d\n", node->id);
free(node->user_data);
free(node);
}
memset(&timer_list, 0, sizeof(struct timer_list));
return 0;
}
添加定时器的动作非常的简单,本质只是一个链表的插入而已:
清单 6. 向定时器链表中添加定时器
/**
* Add a timer to timer list.
*
* @param interval The timer interval(second).
* @param cb When cb!= NULL and timer expiry, call it.
* @param user_data Callback's param.
* @param len The length of the user_data.
*
* @return The timer ID, if == INVALID_TIMER_ID, add timer fail.
*/
timer_id add_timer(int interval, timer_expiry *cb, void *user_data, int len)
{
struct timer *node = NULL;
if (cb == NULL || interval <= 0) {
return INVALID_TIMER_ID;
}
if(timer_list.num < timer_list.max_num) {
timer_list.num++;
} else {
return INVALID_TIMER_ID;
}
if((node = malloc(sizeof(struct timer))) == NULL) {
return INVALID_TIMER_ID;
}
if(user_data != NULL || len != 0) {
node->user_data = malloc(len);
memcpy(node->user_data, user_data, len);
node->len = len;
}
node->cb = cb;
node->interval = interval;
node->elapse = 0;
node->id = timer_list.num;
LIST_INSERT_HEAD(&timer_list.header, node, entries);
return node->id;
}
清单 7. 信号处理函数驱动定时器
/* Tick Bookkeeping */
static void sig_func(int signo)
{
struct timer *node = timer_list.header.lh_first;
for ( ; node != NULL; node = node->entries.le_next) {
node->elapse++;
if(node->elapse >= node->interval) {
node->elapse = 0;
node->cb(node->id, node->user_data, node->len);
}
}
}它主要是在每次收到 SIGALRM 信号时,执行定时器链表中的每个定时器 elapse 的自增操作,并与 interval 相比较,如果相等,代表注册的定时器已经超时,这时则调用注册的回调函数。
上面的实现,有很多可以优化的地方:考虑另外一种思路,在定时器系统内部将维护的相对 interval 转换成绝对时间,这样,在每 PerTickBookkeeping 时,只需将当前时间与定时器的绝对时间相比较,就可以知道是否该定时器是否到期。这种方法,把递增操作变为了比较操作。并且上面的实现方式,效率也不高,在执行 StartTimer,StopTimer,PerTickBookkeeping 时,算法复杂度分别为 O(1),O(n),O(n),可以对上面的实现做一个简单的改进,在 StartTimer 时,即在添加 Timer 实例时,对链表进行排序,这样的改进,可以使得在执行 StartTimer,StopTimer,PerTickBookkeeping 时,算法复杂度分别为 O(n),O(1),O(1) 。改进后的定时器系统如下图 1:
图 1. 基于排序链表的定时器

————————————————————————————————————————————————————————————————————————————
基于2.6版本内核定时器的实现(Posix实时定时器)
Linux 自 2.6 开始,已经开始支持 POSIX timer [ 2 ]所定义的定时器,它主要由下面的接口构成 :
清单 8. POSIX timer接口
#include
#include
int timer_create(clockid_t clockid, struct sigevent *evp,
timer_t *timerid);
int timer_settime(timer_t timerid, int flags,
const struct itimerspec *new_value,
struct itimerspec * old_value);
int timer_gettime(timer_t timerid, struct itimerspec *curr_value);
int timer_getoverrun(timer_t timerid);
int timer_delete(timer_t timerid); 这套接口是为了让操作系统对实时有更好的支持,在链接时需要指定 -lrt 。
timer_create(2): 创建了一个定时器。
timer_settime(2): 启动或者停止一个定时器。
timer_gettime(2): 返回到下一次到期的剩余时间值和定时器定义的时间间隔。出现该接口的原因是,如果用户定义了一个 1ms 的定时器,可能当时系统负荷很重,导致该定时器实际山 10ms 后才超时,这种情况下,overrun=9ms 。
timer_getoverrun(2): 返回上次定时器到期时超限值。
timer_delete(2): 停止并删除一个定时器。
上面最重要的接口是 timer_create(2),其中,clockid 表明了要使用的时钟类型,在 POSIX 中要求必须实现 CLOCK_REALTIME 类型的时钟。 evp 参数指明了在定时到期后,调用者被通知的方式。该结构体定义如下 :
清单 9. POSIX timer接口中的信号和事件定义
union sigval {
int sival_int;
void *sival_ptr;
};
struct sigevent {
int sigev_notify; /* Notification method */
int sigev_signo; /* Timer expiration signal */
union sigval sigev_value; /* Value accompanying signal or
passed to thread function */
void (*sigev_notify_function) (union sigval);
/* Function used for thread
notifications (SIGEV_THREAD) */
void *sigev_notify_attributes;
/* Attributes for notification thread
(SIGEV_THREAD) */
pid_t sigev_notify_thread_id;
/* ID of thread to signal (SIGEV_THREAD_ID) */
};其中,sigev_notify 指明了通知的方式 :
SIGEV_NONE
当定时器到期时,不发送异步通知,但该定时器的运行进度可以使用 timer_gettime(2) 监测。
SIGEV_SIGNAL
当定时器到期时,发送 sigev_signo 指定的信号。
SIGEV_THREAD
当定时器到期时,以 sigev_notify_function 开始一个新的线程。该函数使用 sigev_value 作为其参数,当 sigev_notify_attributes 非空,则制定该线程的属性。注意,由于 Linux 上线程的特殊性,这个功能实际上是由 glibc 和内核一起实现的。
SIGEV_THREAD_ID (Linux-specific)
仅推荐在实现线程库时候使用。
如果 evp 为空的话,则该函数的行为等效于:sigev_notify = SIGEV_SIGNAL,sigev_signo = SIGVTALRM,sigev_value.sival_int = timer ID 。
由于 POSIX timer [ 2 ]接口支持在一个进程中同时拥有多个定时器实例,所以在上面的基于 setitimer() 和链表的 PerTickBookkeeping 动作就交由 Linux 内核来维护,这大大减轻了实现定时器的负担。由于 POSIX timer [ 2 ]接口在定时器到期时,有更多的控制能力,因此,可以使用实时信号避免信号的丢失问题,并将 sigev_value.sival_int 值指定为 timer ID,这样,就可以将多个定时器一起管理了。需要注意的是,POSIX timer [ 2 ]接口只在进程环境下才有意义 (fork(2) 和 exec(2) 也需要特殊对待 ),并不适合多线程环境。与此相类似的,Linux 提供了基于文件描述符的相关定时器接口:
清单 10. linux提供的基于文件描述符的定时器接口
#include
int timerfd_create(int clockid, int flags);
int timerfd_settime(int fd, int flags,
const struct itimerspec *new_value,
struct itimerspec *old_value);
int timerfd_gettime(int fd, struct itimerspec *curr_value); ————————————————————————————————————————————————————————————————————————————
最小堆实现的定时器
最小堆指的是满足除了根节点以外的每个节点都不小于其父节点的堆。这样,堆中的最小值就存放在根节点中,并且在以某个结点为根的子树中,各节点的值都不小于该子树根节点的值。一个最小堆的例子如下图 2:
图 2. 最小堆
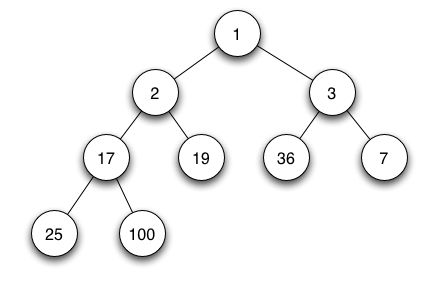
一个最小堆,一般支持以下几种操作:
Insert(TimerHeap, Timer): 在堆中插入一个值,并保持最小堆性质,具体对应于定时器的实现,则是把定时器插入到定时器堆中。根据最小堆的插入算法分析,可以知道该操作的时间复杂度为 O(lgn) 。
Minimum(TimerHeap): 获取最小堆的中最小值;在定时器系统中,则是返回定时器堆中最先可能终止的定时器。由于是最小堆,只需返回堆的 root 即可。此时的算法复杂度为 O(1) 。
ExtractMin(TimerHeap): 在定时器到期后,执行相关的动作,它的算法复杂度为 O(1) 。
最小堆本质上是一种最小优先级队列 (min-priority queue) 。定时可以作为最小优先级队列的一个应用,该优先级队列把定时器的时间间隔值转化为一个绝对时间来处理,ExtractMin 操则是在所有等待的定时器中,找出最先超时的定时器。在任何时候,一个新的定时器实例都可通过 Insert 操作加入到定时器队列中去。
在 pjsip 项目的基础库 pjlib 中,有基于最小堆实现的定时器,它主要提供了以下的几个接口:
清单 11. pjlib提供的基于最小堆的定时器接口
/**
* Create a timer heap.
*/
PJ_DECL(pj_status_t) pj_timer_heap_create( pj_pool_t *pool,
pj_size_t count,
pj_timer_heap_t **ht);
/**
* Destroy the timer heap.
*/
PJ_DECL(void) pj_timer_heap_destroy( pj_timer_heap_t *ht );
/**
* Initialize a timer entry. Application should call this function at least
* once before scheduling the entry to the timer heap, to properly initialize
* the timer entry.
*/
PJ_DECL(pj_timer_entry*) pj_timer_entry_init( pj_timer_entry *entry,
int id,
void *user_data,
pj_timer_heap_callback *cb );
/**
* Schedule a timer entry which will expire AFTER the specified delay.
*/
PJ_DECL(pj_status_t) pj_timer_heap_schedule( pj_timer_heap_t *ht,
pj_timer_entry *entry,
const pj_time_val *delay);
/**
* Cancel a previously registered timer.
*/
PJ_DECL(int) pj_timer_heap_cancel( pj_timer_heap_t *ht,
pj_timer_entry *entry);
/**
* Poll the timer heap, check for expired timers and call the callback for
* each of the expired timers.
*/
PJ_DECL(unsigned) pj_timer_heap_poll( pj_timer_heap_t *ht,
pj_time_val *next_delay);————————————————————————————————————————————————————————————————————————————
基于时间轮(timing-wheel)方式实现的定时器
时间轮 (Timing-Wheel) 算法类似于一以恒定速度旋转的左轮手枪,枪的撞针则撞击枪膛,如果枪膛中有子弹,则会被击发;与之相对应的是:对于 PerTickBookkeeping,其最本质的工作在于以 Tick 为单位增加时钟,如果发现有任何定时器到期,则调用相应的 ExpiryProcessing 。设定一个循环为 N 个 Tick 单元,当前时间是在 S 个循环之后指向元素 i (i>=0 and i<= N - 1),则当前时间 (Current Time)Tc 可以表示为:Tc = S*N + i ;如果此时插入一个时间间隔 (Time Interval) 为 Ti 的定时器,设定它将会放入元素 n(Next) 中,则 n = (Tc + Ti)mod N = (S*N + i + Ti) mod N = (i + Ti) mod N 。如果我们的 N 足够的大,显然 StartTimer,StopTimer,PerTickBookkeeping 时,算法复杂度分别为 O(1),O(1),O(1) 。在 [5] 中,给出了一个简单定时器轮实现的定时。下图 3 是一个简单的时间轮定时器:
图 3. 简单的时间轮
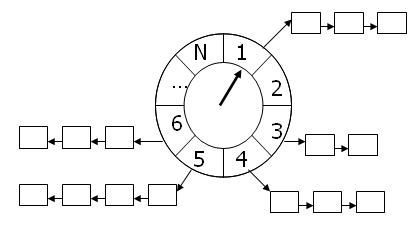
如果需要支持的定时器范围非常的大,上面的实现方式则不能满足这样的需求。因为这样将消耗非常可观的内存,假设需要表示的定时器范围为:0 – 2^3-1ticks,则简单时间轮需要 2^32 个元素空间,这对于内存空间的使用将非常的庞大。也许可以降低定时器的精度,使得每个 Tick 表示的时间更长一些,但这样的代价是定时器的精度将大打折扣。现在的问题是,度量定时器的粒度,只能使用唯一粒度吗?想想日常生活中常遇到的水表,如下图 4:
图 4. 水表

在上面的水表中,为了表示度量范围,分成了不同的单位,比如 1000,100,10 等等,相似的,表示一个 32bits 的范围,也不需要 2^32 个元素的数组。实际上,Linux 的内核把定时器分为 5 组,每组的粒度分别表示为:1 jiffies,256 jiffies,256*64 jiffies,256*64*64 jiffies,256*64*64*64 jiffies,每组中桶的数量分别为:256,64,64,64,64,这样,在 256+64+64+64+64 = 512 个桶中,表示的范围为 2^32 。有了这样的实现,驱动内核定时器的机制也可以通过水表的例子来理解了,就像水表,每个粒度上都有一个指针指向当前时间,时间以固定 tick 递增,而当前时间指针则也依次递增,如果发现当前指针的位置可以确定为一个注册的定时器,就触发其注册的回调函数。 Linux 内核定时器本质上是 Single-Shot Timer,如果想成为 Repeating Timer,可以在注册的回调函数中再次的注册自己。内核定时器如下图 5:
图 5. linux时间轮
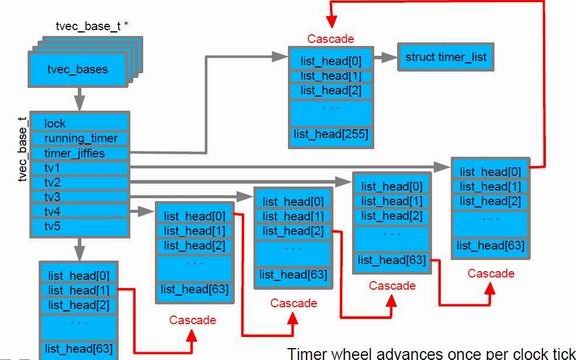
————————————————————————————————————————————————————————————————————————————
结论
由上面的分析,可以看到各种定时器实现算法的复杂度:
表 1. 定时器实现的算法复杂度
| 实现方式 | StartTimer | StopTimer | PerTickBookkeeping |
| 基于链表 | O(1) | O(n) | O(n) |
| 基于排序链表 | O(n) | O(1) | O(1) |
| 基于最小堆 | O(lgn) | O(1) | O(1) |
| 基于时间轮 | O(1) | O(1) | O(1) |
如果需要能在线程环境中使用的定时器,对于基于链表的定时器,可能需要很小心的处理信号的问题;而 POSIX timer [ 2 ]接口的定时器,只具有进程的语义,如果想在多线程环境下也 n 能使用,可以使用 Linux 提供的 timerfd_create(2) 接口。如果需要支持的定时器数量非常的大,可以考虑使用基于最小堆和时间轮的方式来实现。
————————————————————————————————————————————————————————————————————————————
Linux 下定时器的实现方式分析