REDIS20_canal概述、工作原理、架构图、HA机制、安装、数据发送到RabbitMq
文章目录
- ①. canal概述和背景
- ②. 主从复制工作原理
- ③. canal的工作原理
- ④. Canal - 架构图
- ⑤. Canal-HA机制
- ⑥. 使用docker安装mysql
- ⑦. 使用Docker安装canal
- ⑧. canal数据发送到RabbitMq
①. canal概述和背景
-
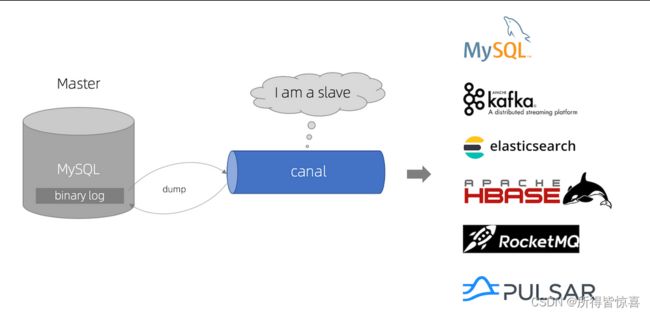
①. 简介:canal [kə’næl]水道/管道/沟渠/运河,主要用途是用于MySQL数据库增量日志数据的订阅、消费和解析,是阿里巴巴开发并开源的,采用Java语言开发
(mysql变化了,被canal组件捕获,立刻完整一致的写操作,同步给我们的redis缓存源)
-
②. 背景:早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元
-
③. 基于日志增量订阅&消费支持的业务(能干嘛):
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务cache刷新
- 带业务逻辑的增量数据处理
-
④. 当前的canal支持源端MySQL的版本包括 5.1.x,5.5.x,5.6.x,5.7.x,8.0.x
-
⑤. github地址:https://github.com/alibaba/canal
完整wiki地址:https://github.com/alibaba/canal/wiki
②. 主从复制工作原理
-
①. 当master主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中
-
②. salve从服务器会在一定时间间隔内对master主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到master主服务器的二进制事件日志发生了改变,则开始一个I/OThread请求master二进制事件日志
-
③. 同时master主服务器为每个I/OThread启动一个dumpThread,用于向其发送二进制事件日志
-
④. slave从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中
-
⑤. salve从服务器将启动SQLThread从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致
-
⑥. 最后I/OThread和SQL Thread将进入睡眠状态,等待下一次被唤醒

③. canal的工作原理
-
①. canal模拟MySQLslave的交互协议,伪装自己为MySQLslave,向MySQL master发送dump协议
-
②. MySQLmaster收到dump请求,开始推送binarylog给slave(即canal)
-
③. canal解析binarylog对象(原始为byte流),并且可以通过连接器发送到对应的消息队列等中间件中

④. Canal - 架构图
- ①. 一个server代表一个canal运行实例,对应于一个jvm,一个instance对应一个数据队列
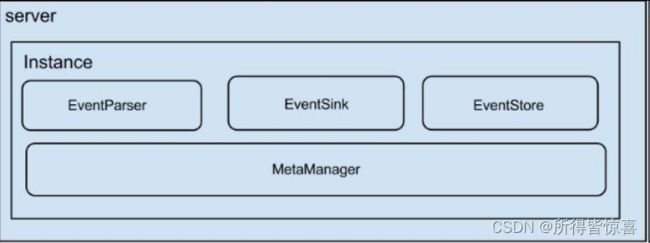
- ②. instance模块:
- eventParser :数据源接入,模拟slave协议和master进行交互,协议解析
- eventSink :Parser和Store链接器,进行数据过滤、加工、分发的工作
- eventStore :数据存储
- metaManager :增量订阅&消费信息管理器
- ③. instance是canal数据同步的核心,在一个canal实例中只有启动instace才能进行数据的同步任务。一个canal server实例中可以创建多个 Canal Instance 实例。每一个Canal Instance可以看成是对应一个MySQL实例
⑤. Canal-HA机制
-
①.所谓HA即高可用,是HighAvailable的简称。通常我们一个服务要支持高可用都需要借助于第三方的分布式同步协调服务,最常用的是zookeeper。canal实现高可用,也是依赖了zookeeper的几个特性:watcher和EPHEMERAL节点。
-
②.canal的高可用分为两部分:canalserver和canalclient
1.canalserver:为了减少对mysqldump的请求,不同server上的instance(不同server上的相同instance)要求同一时间只能有一个处于running,其他的处于standby状态,也就是说,只会有一个canalserver的instance处于active状态,但是当这个instancedown掉后会重新选出一个canalserver
2.canalclient:为了保证有序性,一份instance同一时间只能由一个canalclient进行get/ack/rollback操作,否则客户端接收无法保证有序 -
③.serverha的架构图如下:

-
④.上图具体步骤如下:
- canalserver要启动某个canalinstance时都先向zookeeper进行一次尝试启动判断(实现:创建EPHEMERAL节点,谁创建成功就允许谁启动);
- 创建zookeeper节点成功后,对应的canalserver就启动对应的canalinstance,没有创建成功的canalinstance就会处于standby状态
- 一旦zookeeper发现canalserverA创建的instance节点消失后,立即通知其他的canalserver再次进行步骤1的操作,重新选出一个canalserver启动instance
- canalclient每次进行connect时,会首先向zookeeper询问当前是谁启动了canalinstance,然后和其建立链接,一旦链接不可用,会重新尝试connect
⑥. 使用docker安装mysql
- ①. 拉取镜像,运行mysql容器
# 1.安装mysql
sudo docker pull mysql:5.7
# --name指定容器名字 -v目录挂载 -p指定端口映射 -e设置mysql参数 -d后台运行
sudo docker run -p 3306:3306 --name mysql \
-v /mydata/mysql/log:/var/log/mysql \
-v /mydata/mysql/data:/var/lib/mysql \
-v /mydata/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
# 查看容器实列,进入容器
docker ps
docker exec -it mysql/容器ID /bin/bash 使用守护式进程
- ②. 因为有目录映射,所以我们可以直接在镜像外执行,开启binlog日志
# 因为有目录映射,所以我们可以直接在镜像外执行
vi /mydata/mysql/conf/my.cnf
# 开启binlog日志:目录为docker里的目录
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
log-bin=/var/lib/mysql/mysql-bin
# server_id 需保证唯一,不能和 canal 的 slaveId 重复
server-id=123456
binlog_format=row
- ③. 开启binlog日志后,要记得重启容器
docker restart 容器Id
-
④. 设置mysql开机自启 : docker update mysql --restart=always
-
⑤. 由于要用到canal,所以这里提前创建canal账号,并且授权处理,查看binlog日志
# 创建用户并赋予权限:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
# 刷新
flush privileges;
# 查看binlog日志
show variables like 'log_bin';
# 查看权限
SELECT * FROM mysql.user;


⑦. 使用Docker安装canal
- ①. 安装canal
# 1. 拉取canal镜像
docker pull canal/canal-server:v1.1.5
# 2. 创建一个容器
docker run --name canal -d canal/canal-server:v1.1.5
# 3. 复制容器中的配置文件到本地
mkdir /mydata/canal
docker cp canal:/home/admin/canal-server/conf/canal.properties /mydata/canal/canal.properties
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /mydata/canal/instance.properties
# 4. 删除掉刚刚启动的容器
docker rm -f 容器id
# 5. 开启容器(要进行修改配置)
docker run --name canal -p 11111:11111 \
-v /mydata/canal/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-v /mydata/canal/canal.properties:/home/admin/canal-server/conf/canal.properties \
-d canal/canal-server:v1.1.5
- ②. 安装rabbitmq(由于后面我们需要将canal数据写入到rabbitmq)
#指定版本,该版本包含了web控制页面
docker pull rabbitmq:management
#方式一:默认guest 用户,密码也是 guest
docker run -d --name rabbitmq -p 15672:15672 -p 5672:5672 rabbitmq:management

⑧. canal数据发送到RabbitMq
- ①. 修改conf/canal.properties配置
[root@canalstudy ~]# cd /mydata/canal/
[root@canalstudy canal]# ls
canal.properties instance.properties
[root@canalstudy canal]# pwd
/mydata/canal
[root@canalstudy canal]# ll
总用量 12
-rwxrwxrwx. 1 500 499 6317 3月 27 21:47 canal.properties
-rwxrwxrwx. 1 500 499 2114 3月 27 21:44 instance.properties
[root@canalstudy canal]#
# 指定模式
canal.serverMode = rabbitMQ
# 指定实例,多个实例使用逗号分隔: canal.destinations = example1,example2
canal.destinations = example
# rabbitmq 服务端 ip
rabbitmq.host = 127.0.0.1
# rabbitmq 虚拟主机
rabbitmq.virtual.host = /
# rabbitmq 交换机
rabbitmq.exchange = xxx
# rabbitmq 用户名
rabbitmq.username = xxx
# rabbitmq 密码
rabbitmq.password = xxx
rabbitmq.deliveryMode =
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
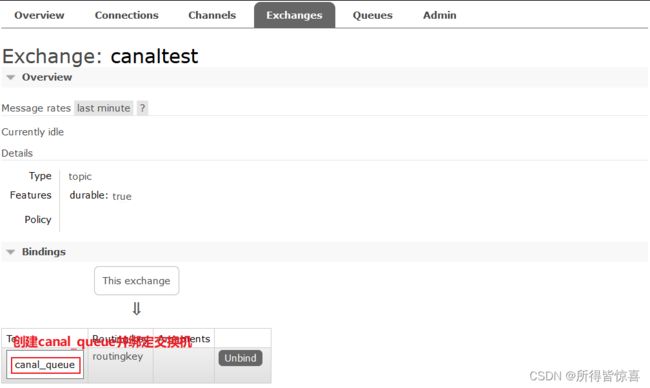
rabbitmq.host =192.168.68.156
rabbitmq.virtual.host =/
rabbitmq.exchange =canaltest
rabbitmq.username =guest
rabbitmq.password =guest
rabbitmq.deliveryMode =
- ②. 修改实例配置文件 conf/example/instance.properties
#配置 slaveId,自定义,不等于 mysql 的 server Id 即可
canal.instance.mysql.slaveId=10
# 数据库地址:配置自己的ip和端口
canal.instance.master.address=ip:port
# 数据库用户名和密码
canal.instance.dbUsername=xxx
canal.instance.dbPassword=xxx
# 指定库和表
canal.instance.filter.regex=.*\\..* // 这里的 .* 表示 canal.instance.master.address 下面的所有数据库
# mq config
# rabbitmq 的 routing key
canal.mq.topic=xxx
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=10
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=192.168.68.156:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=routingkey
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
- ③. 创建表,新增两条数据,发现这个时候已经同步到了rabbitmq
CREATE TABLE `product_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`price` decimal(10,4) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
`update_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
INSERT INTO cheetah.product_info
(id, name, price, create_date, update_date)
VALUES(1, '从你的全世界路过', 14.0000, '2020-11-21 21:26:12', '2021-03-27 22:17:39');
INSERT INTO cheetah.product_info
(id, name, price, create_date, update_date)
VALUES(2, '乔布斯传', 25.0000, '2020-11-21 21:26:42', '2021-03-27 22:17:42');

{"data":[{"id":"3","name":"java开发22","price":"87.0","create_date":"2021-03-27 22:43:31","update_date":"2021-03-27 22:43:34"}],"database":"canaldb","es":1680100917000,"id":1,"isDdl":false,"mysqlType":{"id":"bigint(20)","name":"varchar(255)","price":"decimal(10,4)","create_date":"datetime","update_date":"datetime"},"old":[{"name":"java开发1"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"name":12,"price":3,"create_date":93,"update_date":93},"table":"product_info","ts":1680100924309,"type":"UPDATE"}
- ④. 如何查找到canal日志,进行容器,/home/admin/canal-server/logs/example
/home/admin/canal-server/logs/canal
[root@canalstudy canal]# docker exec -it ac0485115df2 /bin/bash
[root@ac0485115df2 admin]# cd /home/admin/canal-server/logs/example
[root@ac0485115df2 example]# ll
total 12
drwxr-xr-x. 2 admin admin 4096 Mar 29 20:28 2023-03-27
-rw-r--r--. 1 admin admin 1537 Mar 29 20:28 example.log
-rw-r--r--. 1 admin admin 533 Mar 29 21:11 meta.log
[root@ac0485115df2 example]#

[root@ac0485115df2 logs]# ll
total 16
drwxr-xr-x. 3 admin admin 4096 Mar 29 20:27 canal
drwxr-xr-x. 3 admin admin 4096 Mar 29 21:13 example
[root@ac0485115df2 logs]# cd canal/
[root@ac0485115df2 canal]# ll
total 12
drwxr-xr-x. 2 admin admin 4096 Mar 29 20:27 2023-03-27
-rw-r--r--. 1 admin admin 4071 Mar 29 20:28 canal.log
-rw-r--r--. 1 admin admin 1017 Mar 29 20:28 canal_stdout.log
[root@ac0485115df2 canal]# cat canal
cat: canal: No such file or directory
[root@ac0485115df2 canal]# cat canal.log
![]()