随机森林(RFC)实现模型优化与特征提取
随机森林既可以进行分类也可以进行回归预测,这里通过随机森林(RFC)模型对汽油辛烷值RON进行特征提取与模型优化。
一、导入相关的数据库
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier #随机森林用于分类
from sklearn.ensemble import RandomForestRegressor #随机森林用于回归
from sklearn.model_selection import train_test_split #划分训练集与测试集
from sklearn import metrics
from sklearn.metrics import r2_score #用于模型拟合优度评估
import numpy as np
import pandas as pd #读取数据二、数据预处理
2.1 读取数据
df_2=pd.read_csv("辛烷值数据.csv",encoding="gbk")
df_head()部分数据格式展示如下可以看到数据为83列,具体1个标签值,82个特征,,这里,产品辛烷值RON作为数据标签,其余作为特征,由于特征过多,需要对对特征进行降维提取。

2.2 数据划分
#将数据分为训练和测试集
train_labels = df_2.iloc[:,0] #数据标签
train_features= df_2.iloc[:,1:] #数据特征
feature_list = list(train_features.columns) #数据特征名称
train_features = np.array(train_features) #格式转换
#划分训练集与测试集
train_features, test_features, train_labels, test_labels = train_test_split(train_features, train_labels, test_size = 0.25, random_state = 42)三、模型构建
3.1构建初步随机森林模型
#构造随机森林模型
rf=RandomForestRegressor(n_estimators = 1000,oob_score = True,n_jobs = -1,random_state =42,max_features='auto',min_samples_leaf = 12)
rf.fit(train_features,train_labels) #模型拟合
predictions= rf.predict(test_features) #预测
print("train r2:%.3f"%r2_score(train_labels,rf.predict(train_features))) #评估
print("test r2:%.3f"%r2_score(test_labels,predictions))初步构造未提取特征之前的随机森林模型,测试集与训练集结果展示如下:
![]()
可以看到,模型拟合训练集比测试集程度好,说明模型拟合程度待优化,这里通过网格搜索方法实现模型参数的优化。
3.2 GridSearch实现参数调优
from sklearn.model_selection import GridSearchCV
#GridSearch网格搜索 进行参数调优
rfc=RandomForestRegressor()
param = {"n_estimators": range(1,20),"min_samples_leaf": range(1,20)} #要调优的参数
gs = GridSearchCV(estimator=rfc,param_grid=param,cv=5)
gs.fit(train_features,train_labels) #调优拟合参数调优后就是进行模型最优参数导出
#导出调参后最优参数
best_score=gs.best_score_
best_params=gs.best_params_
print(best_score,best_params,end='\n')![]()
可以看到,模型拟合分数为0.6,再次对模型进行拟合查看参数调优后的效果。
#最优参数再次进行模型评估
rf=RandomForestRegressor(n_estimators = 16,oob_score = True,n_jobs = -1,random_state =42,max_features='auto',min_samples_leaf = 1)
rf.fit(train_features,train_labels)
predictions= rf.predict(test_features)
print("train r2:%.3f"%r2_score(train_labels,rf.predict(train_features)))
print("test r2:%.3f"%r2_score(test_labels,predictions)) ![]()
可以看到,模型的训练集拟合优度大幅度提升,测试集模型额拟合优度也有明显额提升,但幅度不大。
四、特征提取
这里影响辛烷值RON的特征很多,有82个,但并不是每个特征对辛烷值RON都有影响,特征过多在模型拟合的过程中会使得模型过于复杂,训练时间长,结果不理想,因此,需要对数据特征进行提取,选取对辛烷值RON影响程度大的特征。
4.1 获取影响辛烷值的特征重要性
importances = list(rf.feature_importances_) #辛烷值RON影响因素的重要性
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list,importances)] #将相关变量名称与重要性对应
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True) #排序
[print('Variable: {:12} Importance: {}'.format(*pair)) for pair in feature_importances] #输出特征影响程度详细数据部分特征的重要性得分展示如下

4.2 可视化
#绘图
f,ax = plt.subplots(figsize = (13,8)) #设置图片大小
x_values = list(range(len(importances)))
plt.bar(x_values,importances, orientation = 'vertical', color = 'r',edgecolor = 'k',linewidth =0.2) #绘制柱形图
# Tick labels for x axis
plt.xticks(x_values, feature_list, rotation='vertical',fontsize=8)
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');各特征重要性柱形图展示
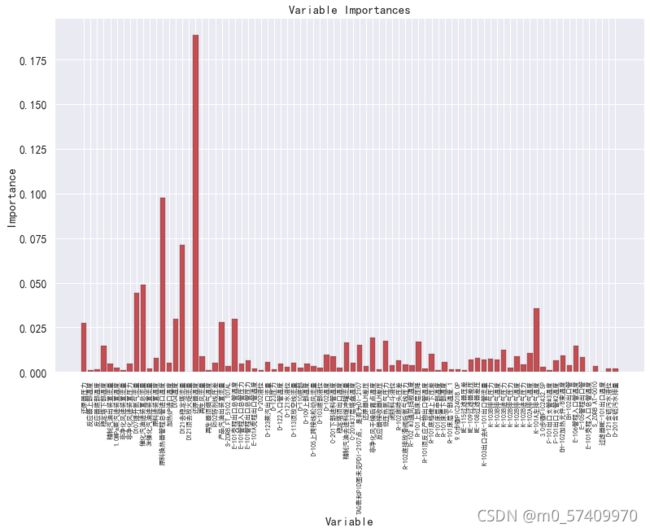
为了更加系统的看数据的影响重要性程度,这里将其做成表格形式展示
# 以二维表格形式显示
importances_df = pd.DataFrame()
importances_df["特征名称"]=feature_list
importances_df["特征重要性"]=importances
p=importances_df.sort_values("特征重要性",ascending=False)
print(importances_df)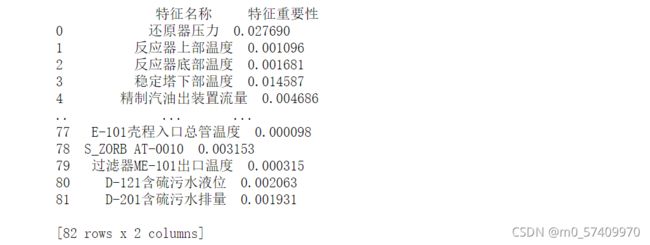
根据需要,这里选择15个特征变量,并最终作为辛烷值RON的特征
lost_result=list(p['特征名称'][:15]) #数据排名前15个的特征
u=df_2.loc[:,lost_result]
print(u)将数据保存为csv格式
u.to_csv("最终提取数据变量.csv",encoding="gbk",header=True,index=False)好啦,数据特征提取就写到这里,作为一个小白一直都在摸索的过程中,同时也记录自己每一次的学习进步,分享这些希望可以给到像我一样有需要的人,希望这些可以帮助到你,谢谢!