PostgreSQL 核心架构学习–以内存管理为中心
PostgreSQL 核心架构学习–以内存管理为中心
本文档主要记录在排查PostgreSQL数据库内存在大批量写时占用过高导致查询接口超时问题过程中的学习内容. 主要以内存管理为中心, 学习PostgreSQL的相关核心架构.
文章目录
- PostgreSQL 核心架构学习--以内存管理为中心
-
- 1. PostgreSQL进程结构
-
- 进程和内存架构图
- 主进程Potmaster
- 辅助进程
-
- Logger系统日志进程
- BgWriter后台写进程
- WalWriter预写式日志写进程
- PgArch归档进程
- AutoVaccum自动清理进程
- PgStat统计数据收集进程
- 2. PostgreSQL内存管理
-
- 本地存储空间
-
- Work_mem
- Maintenance_work_mem
- Temp_buffers
- 共享存储空间
-
- Share buffer pool
- WAL buffer
- Commit Log
- 3. PostgreSQL 内存调优
-
- Shared_buffers
- Work_mem
- maintenance _work_mem
- Effective_cache_size
- Temp_buffers
- 如何查看各个配置
- 性能监控工具
- 总结
1. PostgreSQL进程结构
进程和内存架构图
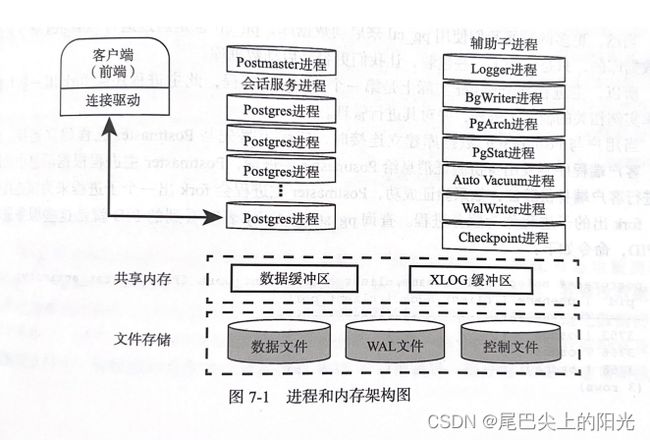
主进程Potmaster
PostgreSQL数据库的主要功能都集中在Postmaster进程中, 该程序的安装没目录的bin目录可以使用命令:
which postgres查看.
Postmaster是整个数据库实例的总控进程, 负责启动和关闭该数据库的实例. 平时我们使用的 pg_ctl命令其实也是运行 Postmaster 和 postgres命令加上合适的参数来启动数据库, 只是又做了一层包装, 方便用户操作.
Postmaster是数据库的第一个Postgre进程, 其他的辅助子进程是Postmaster fork出来的. 当用户与 PostgreSQL建立连接的时候, 实际上是先于Postmaster进程建立连接. 此时客户端程序会发出身份验证消息给Postmaster进程, 如果验证成功, Postmaster会fork出子进程来为该连接服务. fork出来的子进程被成为服务进程, 可使用命令查看:
select pid, usename,client_addr, client_port fromm pg_stat_activity;
当某个服务进程出现问题时, Postmaster主进程会自动完成系统恢复. 恢复过程中会停掉所有的服务进程, 然后进行数据库的一致性恢复, 等恢复完成之后才能接受新的连接.
辅助进程
Logger系统日志进程
在 postgresql.conf文件中将参数 logging_collect设置为: on主进程才会启动Logger辅助进程.
该辅助进程会记录Postmaster主进程和所有服务进程以及其他辅助进程的stderr输出. 在postgresql.conf文件中可以配置文件大小和存留时间. 当文件大小或存留时间等限制条件达到时, Logger就会关闭旧的日志文件, 并创建新的日志. 如果收集到装载配置文件的信号: SIGHUP, 就会检查配置文件中的配置参数 log_directory和 log_filename与当时的配置是否相同, 如果不相同则会使用新的配置.
BgWriter后台写进程
该辅助进程是将共享内存shared_buffers中的脏页写入os缓存, 进而刷新到磁盘上的进程. 该进程的刷新频率会直接影响到读写的效率. 可用 bgwriter_为前缀的相关参数控制.
WalWriter预写式日志写进程
WAL是Write Ahead Log的缩写, 即 “预写式日志”, 又有被简称为 “xlog”. WalWriter就是写WAL日志的进程. WAL日志被保存在pg_xlog下.
预写式日志就是在修改数据之前就把这些修改的操作记录到磁盘中. 好处是后续的更新实际数据的时候就不需要实时将数据持久化到文件. 如果中途机器宕机或者进程异常退出, 导致一部分脏页们没有来得及刷新到文件当中, 数据库重启后, 可以通过读取WAL日志把最后一部分日志重新执行来恢复状态.
PgArch归档进程
WAL日志会循环使用, 即早期的WAL日志会被覆盖. PgArch归档进程会在WAL日志被覆盖之前将其备份出来. 从8.0版本之后, PostgreSQL采用 PITR(Point-In-Time-Recovery)技术. 就是在对数据库进行过一次全量的备份之后, 使用该技术可以将备份时间点之后的WAL日志通过归档进行备份, 使用数据库的全量备份再加上后续的WAL日志就可以把数据库回滚到全量备份之后的任意时间点上.
AutoVaccum自动清理进程
在PostgreSQL数据库中, 对表的DELETE操作或者其他更新操作之后磁盘并不会立刻释放或者更新, 只是会新增一行数据, 原有数据会被标记为"删除"状态. 只有在没有并发的其他事务读取这些旧数据的时候才会将其请除.
AutoVaccum进程就是进行这种请除工作的. postgresql.conf中有很多参数可以指定请除的频率和策略, 但是默认是进行自动循环请除, 所以叫做 Auto.
PgStat统计数据收集进程
该进程主要进行数据的统计收集工作. 收集的信息主要用于查询优化时的代价估算. 信息包括在一个表和索引上进行了多少此的插入, 更新, 删除操作, 磁盘读写的次数, 以及行的读次数等. 系统表 pg_statistic中可以查看这些收集信息.
2. PostgreSQL内存管理
学习资料参考:
architecture-and-tuning-memory-postgresql-databases
postgresql-out-of-memory
Tuning Your PostgreSQL Server
《PostgreSQL修炼之道》第7章+第12章
Postgres内存主要分为两大类:
- 本地存储空间:由每个后端进程分配供自己使用
- 共享存储空间: 被PostgreSQL 服务中所有的进程所共享

本地存储空间
在PostgreSQL中,每个后端进程分配本地内存用于查询处理;每个空间被划分为子空间,子空间的大小是固定的或可变的。
所有的子空间如下:
Work_mem
执行器使用此空间按ORDER by和DISTINCT操作对元组进行排序。它还使用它通过merge-join和hash-join操作来连接表。
Maintenance_work_mem
该参数用于某些类型的维护操作(VACUUM, REINDEX)。
VACUUM是指回收资源, 简单的说就是在执行delete删除操作以后,我们仅仅是为删除的记录打上标记,而并没有真正的从物理上删除,也没有释放空间。因此这部分被删除的记录虽热显示被删除了,但是其他新增记录依然不能占用其物理空间,对于这种空间的占用我们称其为HWM(最高水位线).
REINDEX使用存储在索引表中的数据重建索引,替换旧的索引的副本. 一般的原因是 “索引崩溃后恢复"或者"索引更改希望其生效”
Temp_buffers
执行器用这个空间保存一些临时表.一般保持默认数值.
共享存储空间
共享内存空间由PostgreSQL服务器在启动时分配。这个空间被划分为几个固定大小的子空间。
Share buffer pool
PostgreSQL将表和索引中的页从持久存储加载到共享缓冲池中,然后直接对它们进行操作。
WAL buffer
PostgreSQL支持WAL (Write ahead log,提前写日志)机制,确保服务器故障后数据不会丢失。WAL数据实际上是PostgreSQL中的事务日志,WAL缓冲区是WAL数据写入持久存储之前的缓冲区域。
Commit Log
提交日志(CLOG)保存所有事务的状态,是并发控制机制的一部分。提交日志分配给共享内存,并在整个事务处理过程中使用。
PostgreSQL定义了以下四种事务状态:
- IN_PROGRESS
- COMMITTED
- ABORTED
- SUB-COMMITTED
3. PostgreSQL 内存调优
Shared_buffers
此参数指定用于共享内存缓冲区的内存量。shared_buffers参数决定为服务器缓存数据专用多少内存, 相当于Oracle数据库中的SGA, shared_buffers的默认值通常是128兆字节(128MB)。
这个参数的默认值非常低,因为在一些平台(如旧的Solaris版本和SGI)上,拥有较大的值需要进行侵入性操作,比如重新编译内核。即使在现代Linux系统上,如果不先调整内核设置,内核也不可能允许将shared_buffers设置为超过32MB。
该机制在PostgreSQL 9.4及后续版本中已经改变,因此内核设置将不必调整。
如果数据库服务器上有很高的负载,那么设置一个高值将提高性能。
如果您有一个具有1GB或更多RAM的专用DB服务器,shared_buffer配置参数的合理起始值是系统中内存的25%。
默认值shared_buffers = 128 MB。修改需要重启PostgreSQL服务器。
设置shared_buffers的一般建议如下:
在2GB内存以下,将shared_buffers的值设置为系统总内存的20%。
在32GB内存以下,将shared_buffers的值设置为系统总内存的25%。
32GB以上内存,将shared_buffers的值设置为8GB
Work_mem
此参数指定写入临时磁盘文件之前,内部排序操作和哈希表所使用的内存量。如果发生了很多复杂的排序,并且你有足够的内存,那么增加work_mem参数允许PostgreSQL进行更大的内存排序,这将比基于磁盘的等效排序更快。
注意,对于复杂的查询,许多排序或散列操作可能并行运行。在开始将数据写入临时文件之前,每个操作将被允许使用与该值指定的相同多的内存。有一种可能是几个会话可能同时执行这样的操作。因此,使用的总内存可能是work_mem参数值的许多倍。
在选择正确值时请记住这一点。排序操作用于ORDER BY、DISTINCT和合并连接。哈希表用于哈希连接、基于哈希的in子查询处理和基于哈希的聚合。
参数log_temp_files可以用来记录排序、散列和临时文件,这在判断排序是否溢出到磁盘而不是内存中很有用。您可以使用EXPLAIN ANALYZE计划检查溢出到磁盘的排序。例如,在EXPLAIN ANALYZE的输出中,如果看到这样一行:“Sort Method: external merge Disk: 7528kB”,那么至少8MB的work_mem将把中间数据保存在内存中,并提高查询响应时间。
注意: 这个参数并不是总共消耗的内存, 也不是一个进程分配内存的最大值, PostgreSQL中每个HASH或者排序操作会被分配这么多内存. 如果有并发的M个进程, 每个进程有N个HASH操作, 则需要分配的内存是 M*N*work_mem, 所以不要把这个设置得太大, 容易OOM.
默认值为work_mem = 4MB。
设置work_mem的一般建议如下:
- 从低值开始:32-64MB
- 然后在日志中寻找“临时文件”行
- 设置为最大临时文件的2-3倍
maintenance _work_mem
该参数指定维护操作(如VACUUM、CREATE INDEX和ALTER TABLE ADD FOREIGN KEY)所使用的最大内存量。由于数据库会话一次只能执行其中一个操作,而PostgreSQL安装中并没有许多操作同时运行,因此将maintenance_work_mem的值设置为明显大于work_mem是安全的。
设置较大的值可以提高清空和恢复数据库转储的性能。
有必要记住,当autovacuum运行时,可能会分配最多autovacuum_max_workers倍的内存,因此注意不要将默认值设置得太高。
maintenance_work_mem默认值为64MB。
设置maintenance_work_mem的一般建议如下:
- 设置系统内存的10%,最大1GB
- 如果你有真空问题,也许你可以把它设置得更高
Effective_cache_size
应该将effecve_cache_size设置为操作系统和数据库本身可用于磁盘缓存的内存的估计值。这是关于你期望在操作系统和PostgreSQL缓冲缓存中有多少可用内存的指南,而不是分配。
PostgreSQL查询计划器使用这个值来确定它所考虑的计划是否适合RAM。如果它设置得太低,索引可能不会以您期望的方式用于执行查询。由于大多数Unix系统在缓存时相当积极,专用数据库服务器上至少50%的可用RAM将充满缓存的数据。
对于effecve_cache_size的一般建议如下:
- 将该值设置为可用的文件系统缓存的数量
- 如果您不知道,可以将该值设置为系统总内存的50%
- 默认值为effecve_cache_size = 4GB。
Temp_buffers
此参数设置每个数据库会话使用的临时缓冲区的最大数量。会话本地缓冲区仅用于访问临时表。此参数的设置可以在单独的会话中更改,但只能在会话中第一次使用临时表之前更改。
PostgreSQL数据库利用这个内存区域来保存每个会话的临时表,当连接关闭时,这些临时表将被清除。
默认值为temp_buffer = 8MB。
如何查看各个配置
- 首先进入pg, 查看conf文件位置:
select name,setting from pg_settings where category='File Locations';

- postgresql.conf 和 postgresql.auto.conf
这个配置文件,主要包含着一些通用的设置,算是最重要的配置文件。不过从9.4版本开始,postgresql 引入了一个新的配置文件 postgresql.auto.conf 在存在相同配置的情况下系统先执行 auto.conf 这个文件,换句话说 auto.conf 配置文件优先级高于 conf 文件 。值得注意的是 auto.conf这个文件必须在 psql 中使用 alter system 来修改,而conf可以直接在文本编辑器中修改。
-
修改参数
alter system set shared_buffers=131072; alter system set max_worker_processes=104;执行完sql后重启pg即可.
性能监控工具
我主要使用的监控工具是 “普罗米修斯” 在Grafana上直接查看Docker的内存占用和I/O情况. 但是该方法的缺点在于只能看到整体的内存占用, 但是无法看到每个任务的状态和单独的进程大小以及内存使用情况, 所以又引入了pg_top工具.
安装命令
sudo apt-get install pgtop
运行命令
pg_top -U postgres -d diaoyucheng-graphinfo -h 192.168.xx.xx -p xxxx -W -s 1 -o res -I -c
所有的参数含义可查看:
pg_top 参数和内容含义
问题:
RES的监控不准. 只能监控到SELECT语句, INSERT语句RES一直是 0KB.
总结
没有一个总的参数可以直接限制pg的内存总用量, 见: limiting-the-total-memory-usage-of-postgresql
但是可以根据自己查询的特点: 比如多ORDER BY, 多SORT等调整相应的参数来获得更好的性能.