7个Bert变种模型baseline在7个文本分类数据集上训练和测试
引入和代码项目简介
https://github.com/songyingxin/Bert-TextClassification
模型有哪些?
使用的模型有下面七个
BertOrigin,
BertCNN,
BertLSTM,
BertATT,
BertRCNN,
BertCNNPlus,
BertDPCNN
通用数据集
情感分类: 采用 IMDB, SST-2, 以及 Yelp 数据集。
IMDB: run_imdb.py,两个类别,积极评论和消极评论。 IMDB 影评数据集包含了50000 条用户评价,评价的标签分为消极和积极, 其中 IMDB 评级<5 的用户评价标注为0,即消极; IMDB 评价>=7 的用户评价标注为 1,即积极。 25000 条影评用于训练集,25,000 条用于测试集
SST-2:run_SST2.py。把文本分成积极和消极
Yelp:
run_yelp_review_full.py,5个类别,[极度不满意,有点不满意,中立,有点满意,超级满意],还是那七个模型
run_yelp_review_polarity.py,2个类别,积极和消极
问题分类: 采用 TREC 和 Yahoo! Answers 数据集。
Yahoo! Answers:run_yahoo_answers.py,10个类别。模型还是上面那7个.
Society & Culture
Science & Mathematics
Health
Education & Reference
Computers & Internet
Sports
Business & Finance
Entertainment & Music
Family & Relationships
Politics & GovernmentTREC:这个代码暂未涉及。TREC question dataset 问题数据集,任务是将一个问题分成 6 类(关于人、位置、数字信息等)TREC-6 由6个类别的问题组成,而 TREC-50 由五十个类别的问题组成。这两个版本,其训练和测试数据集 都分别包含 5452 和 500 个问题。
主题分类: 采用 AG's News,DBPedia 以及 CNews。
AG's News:run_ag_news.py。有四个类别:“World”, “Sports”, “Business”, “Sci/Tech”
DBPedia:run_dbpedia.py,14个类别,如公司、教育机构、艺术家、电影。它实际上是从维基百科项目创建的信息中提取的结构化内容集。TorchText提供的DBpedia数据集有63000个属于14个类的文本实例。它包括5600个训练实例和70000个测试实例。
CNews:
run_THUCNews.py,类别有10个,[u'房产', u'科技', u'财经', u'游戏', u'娱乐', u'时尚', u'时政', u'家居', u'教育', u'体育'],模型用的那7个
run_Multi_CNews.py,代码里没写自己有多少个类别,只用了一种模型BertHAN
上面一部分数据集的下载链接可以通过从torchtext里面的这个函数torchtext.datasets.text_classification的文本数据集的代码中找到
ref:https://pytorch.org/text/_modules/torchtext/datasets/text_classification.html
URLS = {
'AG_NEWS':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbUDNpeUdjb0wxRms',
'SogouNews':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbUkVqNEszd0pHaFE',
'DBpedia':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbQ2Vic1kxMmZZQ1k',
'YelpReviewPolarity':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbNUpYQ2N3SGlFaDg',
'YelpReviewFull':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbZlU4dXhHTFhZQU0',
'YahooAnswers':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9Qhbd2JNdDBsQUdocVU',
'AmazonReviewPolarity':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbaW12WVVZS2drcnM',
'AmazonReviewFull':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbZVhsUnRWRDhETzA'}既然模型结构都是一样的,为什么要在这么多不同的数据集上去跑代码?跑一个数据集不就行了吗?
不同的业务场景的数据有自己的特点,不同业务场景对数据的含义应该有不同的理解。
作者做实验的模型表现
在下面两个数据集上,不同模型的分数
THUCNews
model_name |
loss |
acc |
f1 |
BertOrigin(base) |
0.088 |
97.4 |
97.39 |
BertHAN |
0.103 |
97.49 |
97.48 |
SST-2
模型 |
loss |
acc |
f1 |
BertOrigin(base) |
0.17 |
94.458 |
94.458 |
BertCNN (5,6) (base) |
0.148 |
94.607 |
94.62 |
BertATT (base) |
0.162 |
94.211 |
94.22 |
BertRCNN (base) |
0.145 |
95.151 |
95.15 |
BertCNNPlus (base) |
0.16 |
94.508 |
94.51 |
代码中一些文件的含义
作者在./docs文件夹里面有三个markdown文件,记录了它做实验的过程
BertCNN.md
记录的在SST-2和CNews两个数据集上,BertBase和BertLarge两个模型 的filter大小的变动下,loss acc f1的上升和下降的趋势
Result.md
首先统计了7个文本分类数据集的 train训练集 和 dev验证集的文本长度的,最小、最大、最长(我猜作者这里想看看不同模型的表现,在不同长度的文本上的score有何区别,从而知道某个模型适合长文本分类;某个模型适合短文本分类。)
作者又显示了句子长度从 50,100,150,200一直到长度为500,每个长度的累计句子占总数的百分之多少
做了长度实验,显示了句子长度为50,100,150,200一直到长度为500情况下,每个长度的分类准确率
融入超长文本,对比分类的效果(我也不知道怎么融进去的,他实验做了一半就停了,没有结果出来)
BHNet Combining local .....
这是作者写了一半的,关于文本分类的论文,里面有写intro,回顾过去预训练模型的发展,介绍了基于BERT的文本分类,梳理了公开数据集
(1)BertLSTM
配置环境
代码发布时间2019年5月21号,各种环境和包要选在这个时间发布的
他要求用python 3.7,
我用的python3.6.1去跑,没问题,不会报错
Pytorch 版本,他没有直接说,这是提供了下面这句
Pytorch : [conda install pytorch torchvision cudatoolkit=9.0 -c pytorch](https://pytorch.org/get-started/locally/)先用torch==1.0.0 CPU版的,后面没有报错
下面这些包,只能根据发布时间向前推,最新版本那个包的版本号来知道
pip install scikit-learn=='0.20.2' (我用的版本:'0.20.2',可以跑通,后面不会报错)
pip install pytorch-pretrained-bert
# 作者把这个包的名字给错了,应该小写,不应该大写。应该是pytorch-pretrained-bert
# 这个东西的最高版本是2019年4月26日发布的,早于代码发布的日期。你先安装最高的版本,这个包有报错再安装前一个版本
pip install pytorch-pretrained-BERT
pip install numpy==1.19.5 # 我用的这个版本,不会报错。
# 这个一般不会有问题。有问题的话,再过来查
pip install tensorboardX==1.6
# 2019年1月2号发布的1.6版本
pip install tensorflow==1.13.1
# 2019年2月27日发布查一下这些包,如何导入——》导入——》导入报错,说明没装;不报错,查出版本来
# 进入环境
conda activate py361tc100数据集
你把这个数据下载sst-2: 链接:https://pan.baidu.com/s/1ax9uCjdpOHDxhUhpdB0d_g 提取码:rxbi
把SST-2这个文件夹放到这个位置“./datasets/”
run_SST2.py line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/sst_2" # 改
data_dir = "./datasets/SST-2" # bert相关的文件准备好
这里,使用了 pytorch-pretrained-BERT 这个package来加载 Bert 模型, 考虑到国内网速问题,推荐先将相关的 Bert 文件下载,主要有两种文件:
vocab.txt: 记录了Bert中所用词表
模型参数: 主要包括预训练模型的相关参数
下载链接
下面各种模型的不同,大概有下面三种分类标准
uncased和cased——case 和 uncase的区别是什么(百度就能知道)
参数量的不同:Base和large
语言:默认是纯英文的-没标注的那些就是纯英文的,也有多语种的multilingual,也有纯中文的chinese
我建议你把下面这些不同的词表下载下来看看,对比一下他们vocab.txt里面内容的区别,写一下——从这些词表的区别就可以对应上你上面说的这三种分类的维度,是什么标准的。
Bert不同语言的词表和模型文件
# vocab 文件下载
'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",
'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt",
'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt",
'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-vocab.txt",
'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-vocab.txt",
'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt",
'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
# 预训练模型参数下载
'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz",
'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz",
'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz",
'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased.tar.gz",
'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased.tar.gz",
'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased.tar.gz",
'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",这里暂时用 ”英文+uncased+base”这种模型
所以使用的vocab.txt和预训练模型参数文件选下面这两个。你先下载下来
'bert-base-uncased': " https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",
'bert-base-uncased': " https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz",
你把这两个文件放在这个位置“./datasets/bert_files/”
注意这个文件“bert-base-uncased.tar.gz”要解压出来,把解压出来的这两个文件文件放到,同目录下这个文件夹“bert-base-uncased”里面

run_SST2.py line16
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt" # 改
#bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased" # 改
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
bert_model_dir = "./datasets/bert_files/bert-base-uncased" # 改制作min数据集
运行一下
# 把--num_train_epochs 的值换成1.0,训练一次迭代就行了,epoch时间长了会时间特别长
# 虽然下面这个参数里面指定的了GPU的 id号,但是如果你的pytorch和我一样装的是CPU版的,他不会因此报错,会直接使用CPU版的pytorch
python run_SST2.py --max_seq_length=65 --num_train_epochs=1.0 --do_train --gpu_ids="1" --gradient_accumulation_steps=8 --print_step=100 你如果用SST-2全量数据集来训练的话,要好久的,大概5个小时吧(我的CPU是i7的,已经是很不错的CPU了)

此时,我的16G的内存被利用了一大部分(78%),CPU的12个核的占用如下图,好几个都是比较满的
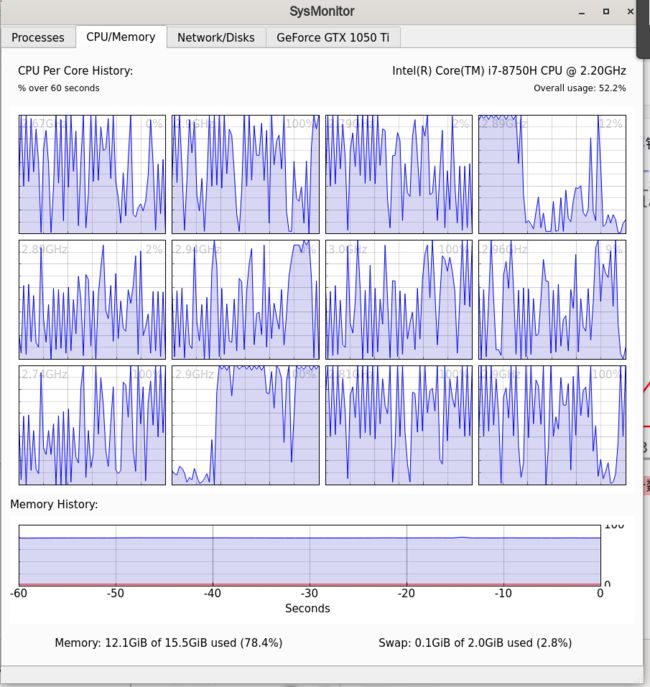
# 原来的
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/sst_2" # 改
# 正常训练应该用的数据集
# data_dir = "./datasets/SST-2" #
# 测试这7个模型是否都可以跑通,没有报错。用下面这个mini
data_dir = "./datasets/SST-2/mini"如果跑1.6万条数据,大概需要一个小时才能训练完
如果跑88条数据,大概不到一分钟就跑完了
实际这里用的数据集用的是tsv文件,而不是jsonl文件(???)
跑一下代码
python run_SST2.py --max_seq_length=65 --num_train_epochs=1.0 --do_train --gpu_ids="1" --gradient_accumulation_steps=8 --print_step=100 我在训练集里面放了一个只有88条数据的数据集,一分钟之内就跑完了。像下面这样,没有报错,可以跑通

其他六个模型能否跑通?
目前可以跑通的模型
BertLSTM——可以跑通
BertOrigin——报错了,说缺少一个文件
Traceback (most recent call last):
File "run_SST2.py", line 54, in
main(config, config.save_name, label_list)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/main.py", line 139, in main
bert_config = BertConfig(output_config_file)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py", line 175, in __init__
with open(vocab_size_or_config_json_file, "r", encoding='utf-8') as reader:
FileNotFoundError: [Errno 2] No such file or directory: '.sst_output/BertOrigin/BertOrigin/config.json' 分析一下上面这个错误是如何产生的:
python run_SST2.py运行的代码,代码里面走的过程是,(S1)先训练,(S2)根据三个条件选择是否保存模型文件(S3)拿前面保存的模型文件,去在测试集上做测试
上面报错的根本原因是是,训练的次数(训练集的数据量)无法满足(S2)里面的条件,所以导致没有保存模型文件,第三部自然也就无法读取到模型文件,自然无法完成测试
下面我们来看看,根据下面这些条件决定是否保存模型文件?什么时候保存模型文件? 这个“条件”是 在 train_evaluate.py里面定义的,需要你同时满足下面三个条件
# line 90
# step+1对gradient_accumulation_steps整除为0
if (step + 1) % gradient_accumulation_steps == 0:
# line 95
# global_step对print_step整除为0
if global_step % print_step == 0 and global_step != 0:
# line 133
# 新模型的参数的acc超过之前的我才保存,以保证存下来的都是比之前训练更好的模型
if dev_acc > best_acc:
# 我看了train_evalute.py里面定义了训练过程的这个函数train(),它在line135这里定义了何种条件下,会将模型的参数保存到本地——但是当你数据量很少(比如这里我的训练集只有88条),但是你又把“gradient_accumulation_steps”和“print_step”这两个除数特别大,比如上面你报错的这条命令 -gradient_accumulation_steps=8 --print_step=100 ,那你的除数(数据的条数)要特别大,才能让除数 除以 被除数 等于零(正好整除)
python run_SST2.py --max_seq_length=65 --num_train_epochs=2.0 --do_train --gpu_ids="1" --gradient_accumulation_steps=8 --print_step=100 那么在训练集数据量比较小的时候,你有想尽快触发条件让他保存模型,你就得让“-gradient_accumulation_steps=8 --print_step ”和“print_step” 这两个被除数尽量小,这里取1,直接解决
但是如果你不按照我这样做。你可能会这样想,那既然这个东西('.sst_output/BertOrigin/BertOrigin/config.json')没有,那我去这个文件夹(“/datasets/bert_files/bert-base-uncased”)下面把bert里面的这个的“bert_config.json”文件复制粘贴过来,改名成“config.json”。你以为这样,该有的文件,有了吧?
再次运行,报错说模型文件没有。然后,你把这个位置“/datasets/bert_files/bert-base-uncased”的这个模型文件“pytorch_model.bin”粘贴到上面那个位置('.sst_output/BertOrigin/BertOrigin/pytorch_model.bin')
然后你再次运行,就会报出一个稀奇古怪,搞了好久都没解决的报错
Traceback (most recent call last):
File "run_SST2.py", line 54, in
main(config, config.save_name, label_list)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/main.py", line 169, in main
model.load_state_dict(torch.load(output_model_file))
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/module.py", line 769, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for BertOrigin: Unexpected key(s) in state_dict: "rnn.weight_ih_l0", "rnn.weight_hh_l0", "rnn.bias_ih_l0", "rnn.bias_hh_l0", "rnn.weight_ih_l0_reverse", "rnn.weight_hh_l0_reverse", "rnn.bias_ih_l0_reverse", "rnn.bias_hh_l0_reverse", "rnn.weight_ih_l1", "rnn.weight_hh_l1", "rnn.bias_ih_l1", "rnn.bias_hh_l1", "rnn.weight_ih_l1_reverse", "rnn.weight_hh_l1_reverse", "rnn.bias_ih_l1_reverse", "rnn.bias_hh_l1_reverse".
size mismatch for classifier.weight: copying a param with shape torch.Size([2, 600]) from checkpoint, the shape in current model is torch.Size([2, 768]). 上面这个报错,由两部分组成
(1)蓝色的,是模型里面的参数这些结构,我的里面是没有的
(2)紫色的。,分类权重的维度不匹配
其实这里报错很正常。模型的参数结构不一致是因为,bert-based 和这里用的bert变种的模型结构是有很多不同的。自然结构不同,那尺寸size也肯定有很多地方是不同。
那么我后来是如何意识到,我在什么地方出错了呢?
我发现BertLSTM 的config.json和pytorch_model.bin文件是今天晚上运行代码以后自动生成的(2023年3月16日创建的)。BERT 原始的预训练模型文件的config.json和pytorch_model.bin文件,是2018年创建的。由此足以见得,这个位置(.sst_output)不应该直接拿 现成的BERT 原始的预训练模型文件的config.json和pytorch_model.bin文件 过来,而是应该,让训练的过程自己生成————然后后期做测试的过程中,在过来这里,拿模型做测试


最后用这句话训练模型
# --max_seq_length=5 # 最大句子长度,别取太长,否则占内存会很多,电脑很卡
# --num_train_epochs=1.0 # 训练一个epoch
# 没有GPU,会默认用CPU来训练
# 最后两个参数都取1,保证尽快保存模型文件。以便于后面进行测试
python run_SST2.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1可以了,现在 满足条件了。可以保存下来模型文件了。也可以后面基于这个模型文件进行测试和评估了。
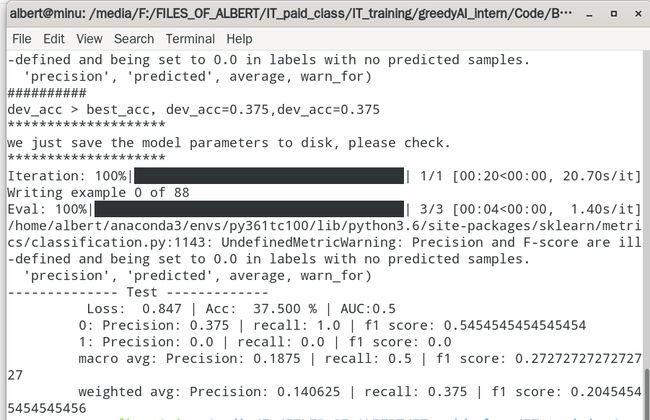
这里用来很小的一个训练集,只有88条数据,(这样训练花的时间少)

然后你去./.sst_output/BertOrigin/BertOrigin 文件夹里面找发现有刚刚保存的模型文件

其他五个模型都可以用跑通吗?
换模型的方法
run_SST2.py 的line7,,这里改
model_name = "BertOrigin"测试用的命令行代码如下
python run_SST2.py --max_seq_length=65 --num_train_epochs=1.0 --do_train --gpu_ids="1" --gradient_accumulation_steps=1 --print_step=1可训练、可测试的模型有如下
BertOrigin
BertLSTM
BertCNN
BertATT
BertRCNN
BertCNNPlus
BertDPCNN
如果跑不通,那么 保存模型的的三条件还有下面这些地方可以做改机——从而保证一定可以保存下来模型文件。
# line 90
# if (step + 1) % gradient_accumulation_steps == 0:
# 【1】变成+0 以后,第一次循环,这个条件就满足
if (step + 0) % gradient_accumulation_steps == 0:
# line 95
#if global_step % print_step == 0 and global_step != 0:
# 【2】把后面那个条件去掉。因为global_step初始化的时候为0,也就是第一批数据进来,这个条件就满足
if global_step % print_step == 0:
# line 133
# if dev_acc > best_acc:
# 【3】 从大于改成大于等于,这样如果等于的,也会保存(不过好像很鸡肋,这步改进。等于的这种可能很小的,这个地方改一点,只会多了那么小一点的可能性)
if dev_acc > best_acc:(2)THUCNews
THUCNews 数据集的文本长度大多在1000-4000之间,这对于大多数机器是不可承受的, 测试在单1080ti上, 文本长度设置为150左右已经是极限。—— THUCNews 数据集中的样本长度十分的长,上面说到 Bert 本身对于序列长度十分敏感,因此我在我单1080ti下所能支持的最大长度。这也导致运行时间的线性增加,1个epoch 大概需要1个半小时到2个小时之间
run_CNews.py
数据集,作者提供好了下载链接,下载下来
cnews: 链接:https://pan.baidu.com/s/19sOrAxSKn3jCIvbVoD_-ag 提取码:rstb 把上面这个文件夹里面的11个文件放到这个位置的这个文件夹里面"./datasets/THUCNews"
run_THUCNews.py里面这些地方改一下,改一下后面的路径
line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/THUCNews"
data_dir = "./datasets/THUCNews"这里要注意THUCNews的数据集是中文数据集,所以Bert使用的词表vocab.txt和pytorch_model.bin文件要用纯中文训练和组织出来的。按照下面这两个链接,把文件下载下来。一个是词汇表,一个是模型文件
'bert-base-chinese': " https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
'bert-base-chinese': " https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",
——这个文件"bert-base-chinese-vocab.txt"放到这个位置“./datasets/bert_files”
——在这个位置“./datasets/bert_files”,新建文件夹“bert-base-chinese”;记得上面这个有关模型文件的压缩包“bert-base-chinese.tar.gz”,你把里面两个文件解压出来也要放进这个位置“./datasets/bert_files/bert-base-chinese”
line17,bert文件位置也要这样修改
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-chinese-vocab.txt"
# 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
bert_vocab_file = "./datasets/bert_files/bert-base-chinese-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-chinese"
# 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",
bert_model_dir = "./datasets/bert_files/bert-base-chinese"我的电脑配置不行,如果用全量数据集,运行,电脑会卡死。所以必须使用一个数据条数比较少的数据集(这样训练一次时间也短,我可以快速的知道是不是所有模型都能训练和测试)
line10这样写
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/THUCNews"
# data_dir = "./datasets/THUCNews"
data_dir = "./datasets/THUCNews/mini"你自己从全量的train.tsv数据集中复制前30行(第一行是表头,实际是29条数据),然后你把这29条数据复制粘贴在同一个tsv文件里三遍,就形成了29*3=87条数据,加上第一行表头,这个tsv文件共有88行。然后你把这个tsv文件复制粘贴3遍,改下名,就形成了这三个文件 train.tsv test.tsv dev.tsv 。
这个数据集的被分类的句子都特别长,有多长呢?下面这么长。一条数据,就是一篇新闻的原文
还有数据的新闻文本,如此之长
[u'房产', u'科技', u'财经', u'游戏',
u'娱乐', u'时尚', u'时政', u'家居', u'教育', u'体育']所以送进去训练的时候,一条数据 这个句子过长,占用的内存过大了。我们这里没有那么大容量的GPU显卡,来训练这个模型(也没必要,因为这个只是做个实验,我们的目的不是来在长文本分类这个场景下训练一个更好的模型)
所以你要么把每一条文本删减成一个比较短的文本(这样处理一遍,比较花时间),要么你动一下下面这个参数,把每次读进去的句子长度做限制,一条数据只读取前5个字,5个字以外东西,别管你有多么长,一律丢掉不要。这个参数是--max_seq_length
python run_THUCNews.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1这个数据集跑通代码后,是这个样子的,他会把每个类别的都给你(我不知道为什么,这里没有算出来——一共有10个类别,我提供的这个小数据集里面所有的新闻都是 体育 这个类别的,但是下面7个类别,有三个类别没有显示)

为了避免训练集中没有一些类别的数据,我又重新从dev.tsv数据集中每个类别挑了一句话组成了下面这个覆盖十个类别的,十条数据的数据集
然后把上面这个数据集复制十遍,组成了一个100条数据的训练集
即使你把句子的最大长度调到50(这个长度跑代码,我的电脑跑会卡死的)如果只训练一个epoch的话,模型对数据的你和效果不好,跑出来,每个类别的分数都很低。比如下面这样,出来房产的precision分数为0.16以外,他各个类别的分数都接近于0

现在,我们把epoch的数量调到10,句子长度还是50(长度为50,我的电脑在运行代码的时候会卡死,建议你把长度调低到5,就不会卡死了)
python run_THUCNews.py --max_seq_length=50 --num_train_epochs=10.0 --do_train --gradient_accumulation_steps=1 --print_step=1基本上5个epoch以后,分数就很好了,acc可以到80%,甚至100%
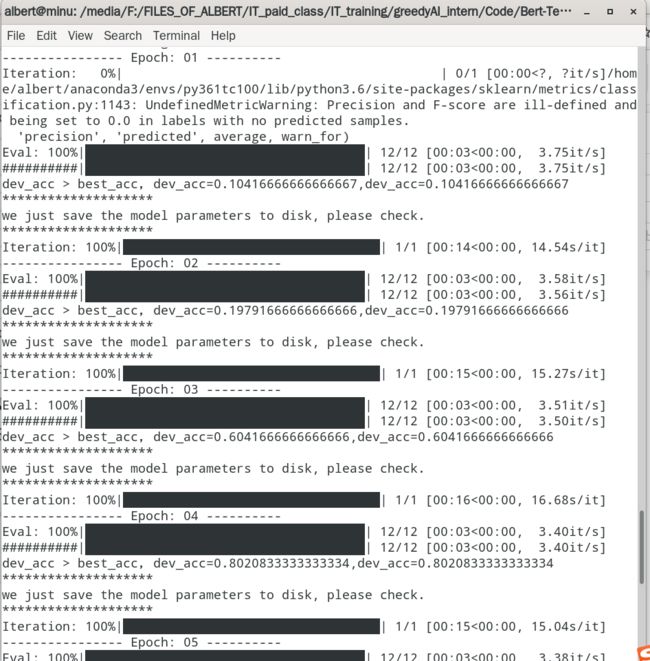
最后的训练集结果和分数。无论是总分数,还是各个类别分数都接近100%
其他模型能否跑通?
python run_THUCNews.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1能跑通的代码
BertOrigin
BertATT
BertLSTM
BertCNN(这个注意,句子长度最低是10,如果你像其他的那样把句子长度定为5,就会报下面这个奇怪的错误)
Traceback (most recent call last):
File "run_THUCNews.py", line 48, in
main(config, config.save_name, label_list)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/main.py", line 131, in main
criterion, config.gradient_accumulation_steps, device, label_list, output_model_file, output_config_file, config.log_dir, config.print_step, config.early_stop)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/train_evalute.py", line 69, in train
logits = model(input_ids, segment_ids, input_mask, labels=None)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/BertCNN/BertCNN.py", line 42, in forward
conved = self.convs(encoded_layers)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/Models/Conv.py", line 24, in forward
return [F.relu(conv(x)) for conv in self.convs]
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/Models/Conv.py", line 24, in
return [F.relu(conv(x)) for conv in self.convs]
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 187, in forward
self.padding, self.dilation, self.groups)
RuntimeError: std::exception BertRCNN
BertCNNPlus(句子长度用20,用5的话话,会报错)
BertDPCNN
(3)AG's News
run_ag_news.py
放置好数据集
数据集下载下来
URL = {"train": "https://raw.githubusercontent.com/mhjabreel/CharCnn_Keras/master/data/ag_news_csv/train.csv","test": "https://raw.githubusercontent.com/mhjabreel/CharCnn_Keras/master/data/ag_news_csv/test.csv",}将上面这个csv格式的文件,放到这个位置,这个文件夹里面“./datasets/ag_news”
这两个文件是csv文件,你需要模仿作者在SST-2数据集和THUCNews上如何把txt数据集转成同一格式的tsv文件
“TSV 是Tab-separated values的缩写,即制表符分隔值。
将上面的数据集的内容改成 每一行 原文 tab 类别标签 ,一行一条数据,这样的格式
先说一下数据的特点。 第一个逗号前面是 类别的label,第一个逗号和第二个逗号之间是新闻的标题,第二个逗号以后是新闻的原文。也就是这个数据集既可以做长文本分类(用第二个逗号后面的新闻的原文),也可以做短文本分类(用第一个逗号和第二个逗号之间的新闻标题做)

下面写一个trans.py来把数据整理成要求的tsv格式,这里用新闻标题来做分类吧。这里反正是做个实验,用过简单的意思意思就行了,即使把长文本拿过来,我也不过是取前五个字来做分类,那不是和短文本一样的。所以直接拿短文本过来训练个分类模型就行了。
新建一个trans.py文件,内容写下面这样
import csv
def trans(input_file, output_file_title,output_file_sentence):
labels = []
titles = []
sentences = []
# 打开文件
with open(input_file, 'r') as fh:
lines = fh.readlines()
print(len(lines))
for line in lines:
# 三个元素,逐个拆开
# print(line[1])
# print(line[5:-1])
# break
label, title, sentence = line.split('","')
# print(label[1:]) # 前面多个逗号——"3
# print(title) # 干干净净的,两边不多逗号——Wall St. Bears Claw Back Into the Black (Reuters)
# print(sentence[:-2]) # 结尾多个2个东西,一个是引号,还有一个换行符,所以要删除结尾的两个——Reuters - Short-sellers, Wall Street's dwindling\band of ultra-cynics, are seeing green again."
# 把数据集存进列表
labels.append(label[1:])
titles.append(title)
sentences.append(sentence[:-2])
with open(output_file_title, 'w') as f:
out_writer = csv.writer(f, delimiter='\t')
# 第一行表头,写入
out_writer.writerow(['sentence', 'label'])
print("labels:{}".format(len(labels)))
for i in range(len(labels)):
out_writer.writerow([titles[i], labels[i]])
with open(output_file_sentence, 'w') as f:
out_writer = csv.writer(f, delimiter='\t')
# 第一行表头,写入
out_writer.writerow(['sentence', 'label'])
print("labels:{}".format(len(labels)))
for i in range(len(labels)):
out_writer.writerow([sentences[i], labels[i]])
if __name__ == "__main__":
trans("train.csv", "train_title.tsv", "train_sentence.tsv")
trans("test.csv", "test_title.tsv","test_sentence.tsv")运行一下,得到四个tsv文件
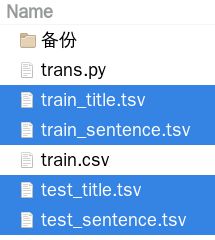
dev.tsv 直接用test.tsv复制一份,改成dev.tsv即可
这里做实验用数据量小的更合适。
创建文件夹“./datasets/ag_news/mini",在里面放三个tsv文件 train.tsv test.tsv dev.tsv,每个文件里面就是下面这些东西复制两边
sentence label
Fears for T N pension after talks 3
The Race is On: Second Private Team Sets Launch Date for Human Spaceflight (SPACE.com) 4
Ky. Company Wins Grant to Study Peptides (AP) 4
Prediction Unit Helps Forecast Wildfires (AP) 4
Calif. Aims to Limit Farm-Related Smog (AP) 4
Open Letter Against British Copyright Indoctrination in Schools 4
Loosing the War on Terrorism 4
FOAFKey: FOAF, PGP, Key Distribution, and Bloom Filters 4
E-mail scam targets police chief 4
Card fraud unit nets 36,000 cards 4
Group to Propose New High-Speed Wireless Format 4
Apple Launches Graphics Software, Video Bundle 4
Dutch Retailer Beats Apple to Local Download Market 4
Super ant colony hits Australia 4
Socialites unite dolphin groups 4
Teenage T. rex's monster growth 4
Scientists Discover Ganymede has a Lumpy Interior 4
Mars Rovers Relay Images Through Mars Express 4
Rocking the Cradle of Life 4
Storage, servers bruise HP earnings 4
IBM to hire even more new workers 4
Sun's Looking Glass Provides 3D View 4
IBM Chips May Someday Heal Themselves 4
Some People Not Eligible to Get in on Google IPO 4
Rivals Try to Turn Tables on Charles Schwab 4
News: Sluggish movement on power grid cyber security 4
Giddy Phelps Touches Gold for First Time 2
Tougher rules won't soften Law's game 2
Shoppach doesn't appear ready to hit the next level 2
Mighty Ortiz makes sure Sox can rest easy 2
They've caught his eye 2
Indians Mount Charge 2
Sister of man who died in Vancouver police custody slams chief (Canadian Press) 1
Man Sought #36;50M From McGreevey, Aides Say (AP) 1
Explosions Echo Throughout Najaf 1
Frail Pope Celebrates Mass at Lourdes 1
Venezuela Prepares for Chavez Recall Vote 1
1994 Law Designed to Preserve Guard Jobs (AP) 1
Iran Warns Its Missiles Can Hit Anywhere in Israel 1
Afghan Army Dispatched to Calm Violence 1
Johnson Helps D-Backs End Nine-Game Slide (AP) 2
Retailers Vie for Back-To-School Buyers (Reuters) 3
Politics an Afterthought Amid Hurricane (AP) 1
Spam suspension hits Sohu.com shares (FT.com) 4
Erstad's Double Lifts Angels to Win (AP) 2
Drew Out of Braves' Lineup After Injury (AP) 2
Venezuelans Flood Polls, Voting Extended 1
Dell Exits Low-End China Consumer PC Market 4
China Says Taiwan Spy Also Operated in U.S. - Media 1line10改成这样
data_dir = "./datasets/ag_news"只用标题来做实验,所以把“train_title.tsv”和“test.title.tsv”,你把这两个文件的文件名里的“_title”去掉
改一下数据的路径,run_ag_news.py
line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/ag_news"
# data_dir = "./datasets/ag_news"
data_dir = "./datasets/ag_news/mini"Bert文件的放置
使用的是这个Bert模型bert-base-uncased,这个模型的词表和模型文件之前已经下载好了,不用二次下载了
代码里的路径这样改
line18
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased"
bert_model_dir = "./datasets/bert_files/bert-base-uncased" # 改跑一下
python run_ag_news.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1可以跑通,搞这样

可以跑通的模型
BertLSTM
BertOrigin
BertCNN(句子长度调到10就足够了)
BertATT
BertRCNN
BertCNNPlus(句子长度最低15,否则会报错)
BertDPCNN
(4)DBPedia
数据集
通过下面两个链接,可以找到数据集的下载链接
ref:https://www.jianshu.com/p/2167e3149ebf
ref:https://pytorch.org/text/_modules/torchtext/datasets/text_classification.html
'DBpedia':'https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbQ2Vic1kxMmZZQ1k',数据集下载下来,里面有这样四个文件
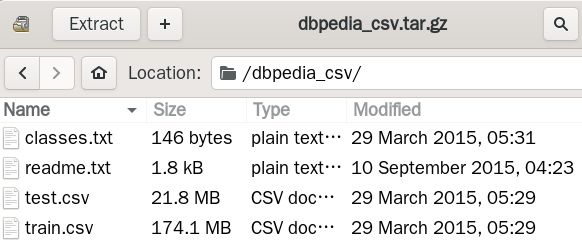
全部拿过来,放到这个文件夹里面“./datasets/dbpedia”
数据集一共14个类别,如下
Company
EducationalInstitution
Artist
Athlete
OfficeHolder
MeanOfTransportation
Building
NaturalPlace
Village
Animal
Plant
Album
Film
WrittenWork原始数据集是这样组织的
数据集是Wikipedia的百科词条数据,在此基础上做了加工加工
每一行是一条数据,一条数据有两个逗号,第一个逗号以前的是label,这里是1。label有1-14,一共14个类别的label(这是维基百科上对这个词条属于什么类别的分类)。第一个逗号和第二个逗号之间的是,实体的名字,这里做分类,不需要用到这个实体的名字(就是wiki上词条的名字),第二个逗号到最后是,我们要来分类的长句子(这其实是,维基百科上对这个词条的解释)

转换成作者规定 tsv格式 ,每行都是这样组织的 sentence tab label
在数据集文件夹里面创建“trans.py”这个文件,并在里面写入下面这段代码
import csv
def trans(input_file, output_file_sentence):
labels = []
entities = []
sentences = []
# 打开文件
with open(input_file, 'r') as fh:
lines = fh.readlines()
print(len(lines))
for line in lines:
label, entity, sentence = line.split(',"')
# print(label) # 拆出来就是一个干净的数字,比如1
# print(entity[:-1]) # 实体名字的后面多个引号,比如Henkel"
# print(sentence[:-2]) # 结尾多个2个东西,一个是引号,还有一个换行符,所以要删除结尾的两个—
# break
# 把数据集存进列表
labels.append(label)
entities.append(entity[:-1])
sentences.append(sentence[:-2])
with open(output_file_sentence, 'w') as f:
out_writer = csv.writer(f, delimiter='\t')
# 第一行表头,写入
out_writer.writerow(['sentence', 'label'])
print("labels:{}".format(len(labels)))
for i in range(len(labels)):
out_writer.writerow([sentences[i], labels[i]])
if __name__ == "__main__":
trans("train.csv", "train.tsv")
trans("test.csv", "test.tsv")运行 trans.py,此时就生成了代码要求格式的tsv格式

路径改一下
line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/dbpedia"
data_dir = "./datasets/dbpedia"BERT文件放置
BERT用的这个bert-base-uncased,之前下载了,不必重复安装
line17
# bert-base
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased"
bert_model_dir = "./datasets/bert_files/bert-base-uncased"做一个mini的很小的数据集,
方便快速测试每个模型是否都能跑
为了保证训练集里面每个列表都包含,我从测试集中抽出了下面14条数据。然后重复10次组成了一个数据集,一共141行。然后备份三份 改名成 train.tsv test.tsv dev.tsv
sentence label
TY KU /taɪkuː/ is an American alcoholic beverage company that specializes in sake and other spirits. The privately-held company was founded in 2004 and is headquartered in New York City New York. While based in New York TY KU's beverages are made in Japan through a joint venture with two sake breweries. Since 2011 TY KU's growth has extended its products into all 50 states. 1
The Mennonite Brethren Collegiate Institute (MBCI) is an independent middle and high school located in Winnipeg Manitoba Canada. It was founded in 1945. It has approximately 580 students from Grade 6 to Grade 12. 2
Guy Adams (born 6 January 1976) is an English author comedian and actor possibly best known for the novel The World House. He has also written a BBC Books Torchwood novel The House That Jack Built. 3
Armando Enrique Polo (born 2 April 1990 in Panama City) is a Panamanian football striker who currently plays in Panama for Chepo F.C. 4
Patrick Goodchild Halpin (born January 18 1953) was the fifth County Executive of Suffolk County New York elected in 1987. He served one term from 1988 through 1991 when he was defeated by Robert J. Gaffney. 5
MAZ-203 is a low-floor city bus. It is a representative of second generation of MAZ city buses being a successor of MAZ-103. It has been built since 2006 there are over 100 models built already. MAZ 203 can be found in Poland Ukraine Russia and Romania. 6
The Boston Pre-Release Center is a minimum security correctional facility located on Canterbury Street in Roslindale Massachusetts. The current facility opened in 2003 and it is under the jurisdiction of the Massachusetts Department of Correction. 7
The Valea Merelor River or Pârâul Luna is a tributary of the Pârâul Mic in Romania. 8
Kovačići (Serbian: Ковачићи) is a village in the municipality of Nevesinje Bosnia and Herzegovina. 9
Ananteris pydanieli is a species of scorpion from Brazilian Amazonia. It is a member of the Buthidae family. 10
Bunium is a genus of flowering plants in the Apiaceae with 45 to 50 species. 11
Someday We'll Look Back is an album by American country singer Merle Haggard released in 1971. It reached #4 on the Billboard Country album chart and #108 on the Pop album chart. The lead-off singles were Someday We'll Look Back which peaked at #2 and Carolyn which reached #1. 12
My Michael (Hebrew: מיכאל שלי translit. Michael Sheli) is a 1976 Israeli drama film directed by Dan Wolman based on the novel by Amos Oz. It was selected as the Israeli entry for the Best Foreign Language Film at the 48th Academy Awards but was not accepted as a nominee. 13
Pinheads and Patriots: Where You Stand in the Age of Obama is a best-selling book of political commentary by American journalist Bill O'Reilly published in 2010. 14然后数据集路径改一下
line11
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/dbpedia"
# data_dir = "./datasets/dbpedia"
data_dir = "./datasets/dbpedia/mini"运行一下
python run_dbpedia.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1跑通了是这样
其他六个模型都可以跑通吗?
可以跑通的模型有下面这些
BertLSTM
BertOrigin
BertCNN(最低长度是10)
BertATT
BertRCNN
BertCNNPlus(最低长度11)
BertDPCNN
(5)IMDB
数据集
跟数据集使用相关的一些帖子
TensorFlow里面下载IMDB数据集的函数tf.keras.datasets.imdb.load_data,函数这样使用 https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb/load_dataTensorFlow里面下载IMDB数据集的函数tf.keras.datasets.imdb.load_data,函数这样使用 https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb/load_dataTensorFlow里面下载IMDB数据集的函数tf.keras.datasets.imdb.load_data,函数这样使用https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb/load_data,这个函数的定义
为了搞清楚是不是用的数据量大了(大到一定程度),才会执行模型保存的命令 https://github.com/keras-team/keras/blob/v2.11.0/keras/datasets/imdb.py#L29-L169
TextCNN实现imdb数据集情感分类任务 https://blog.csdn.net/qq_38901850/article/details/125176659
tensorflow 教程 文本分类 IMDB电影评论 https://www.bbsmax.com/A/qVdeRmGpzP/
实际的话用这个下载地址:https://ai.stanford.edu/~amaas/data/sentiment/
下载下来的文件有点复杂,和之前见到数据集格式不太一样,这里简单介绍一下这些数据是怎么组织的,每个东西是什么含义
整个数据集中出现的所有词组成了一个词汇表,这个表就是imdb.vocab。后面如果你需要的话,可以拿着词汇表里的词,和这些词在词表中的位置索引,来进行编码,也就是我们说的positional encoding位置编码.但是这里我们暂时不用这种编码方式。
README这文件里面是整个数据集的介绍。
train test里面自然就是我们心心念念的 训练集和测试集。只不过,这两个文件夹里面存储的并不是两个txt或者csv文件,而是一堆文件和三个文件夹
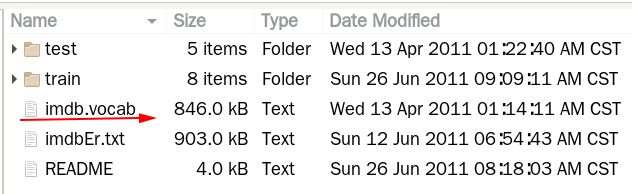
只不过train和test里面文件和文件夹很多,下面我逐一介绍各自的含义。下面这些介绍都是阅读README这个文档以后了解到的信息。
数据集一共5w条数据,训练集和测试集各2.5w条。训练集和测试集里面都有两个文件夹,分别是pos和neg。训练集中,被判定为情绪积极的有1.25w条,消极的1.25w条。(标签是平衡的,这一点很好。积极和消极这两个标签的样本数量完全一样。)测试集中亦如是。
每一部电影的影评收集的数量都不超过30条,因为对于同一部电影的评价大多是线性相关的,收集超过30条了,也没多大的意义。——训练集和测试集的电影没有重合,这样就避免了模型在训练集的时候记住了对这部电影的情感倾向,在测试集直接背诵出训练集里对这部电影的情感倾向。
在原始的IMDB数据集中,评分小于4分(满分10分)的归为了negative,评分大于7分的归类为positive,4-7分中间的这些模棱两可的,分类成积极消极,难度很高,因此在情感分析这个数据集中就把这类评分比较中性neutral的给排除了。
在训练集文件夹里有一个unsup的文件夹,这是给unsupervise无监督学习的模型准备的数据集,评分大于5分和评分小于等于5分的review影评的个数是个偶数even number。
训练集和(./train)测试集(./test)里面都有积极评论(pos文件夹)和消极评论(neg文件夹)。pos和neg文件夹打开,里面是1.25w个txt文件。txt文件的命名方式有讲究,格式是 [id]_[rating].,txt。举个例子,比如你打开“/datasets/imdb/train/pos”,第一个txt文件是“0_9.txt”,0就是这个review独一无二的id,9就是这个review的评分,这里是9分,正好大于7,果真是positive的review。你打开“/datasets/imdb/train/unsup”这文件夹,发现id各自都有,只是评分全部是0,这是因为这是一个无监督数据集,自然把评分这种label移除了,所以格式上是0分。

然后把训练集和测试集里面,所有的 积极文件夹里面的txt文件内容读出来,然后合并成一个txt文件,最终训练集一个txt文件,测试集一个txt文件,每个文件里既有积极的,也得有消极的。
遍历train和test文件夹中的 pos和neg文件夹,遍历里面的每一个txt文件,把每一个txt文件里面的文本内容拿到,然后逐行写入本地的一个tsv文件,如果积极的就 在结尾加一 一个tab、一个1,如果消极,就在结尾加一个tab 一个0
代码如下
# 从原始的txt文件中取数据出来。train的 pos和neg放一起,test的 pos和neg放在一起
def pos_neg_in_one(input,output_file):
# 把表头写入进去
with open(output_file, 'w') as f: # w是覆盖式写入
out_writer = csv.writer(f, delimiter='\t') # 每行输入进去的两个元素用tab隔开
out_writer.writerow(['sentence', 'label'])
input1 = input+"/"+"pos";label=1
iter_count = 1
for root, dirs, files in os.walk(input1):
# print(root) # 输入进来的这个路径
# print(dirs) # 当前目录下所有的文件夹的列表
# print(files) # 这个出来是所有文件名的那个列表
for file in files:
with open(input1 + "/" + file, 'r') as fh:
sentence = fh.readlines()[0] # 这是影评的文本内容
# fh.readlines()返回的是一个列表,只有一行的话,列表里只有一个元素,有很多行的话,列表里就有很多个元素。这里是一个元素,取出来,用索引
# 增量写入到一个tsv文件里面
# print(sentence,"\t")
with open(output_file, 'a') as f: # 据说这里改成"a",就是增量写入;如果是w就是覆盖之前的内容,来写入
out_writer = csv.writer(f, delimiter='\t') # 每行输入进去的两个元素用tab隔开
out_writer.writerow([sentence, label])
# if iter_count >= 11:
if iter_count >= float("inf"):
break
iter_count+=1
input2 = input+"/"+"neg";label=0
iter_count = 1
for root, dirs, files in os.walk(input2):
# print(root) # 输入进来的这个路径
# print(dirs) # 当前目录下所有的文件夹的列表
# print(files) # 这个出来是所有文件名的那个列表
for file in files:
with open(input2 + "/" + file, 'r') as fh:
sentence = fh.readlines()[0] # 这是影评的文本内容
# fh.readlines()返回的是一个列表,只有一行的话,列表里只有一个元素,有很多行的话,列表里就有很多个元素。这里是一个元素,取出来,用索引
# 增量写入到一个tsv文件里面
# print(sentence,"\t")
with open(output_file, 'a') as f: # 据说这里改成"a",就是增量写入;如果是w就是覆盖之前的内容,来写入
out_writer = csv.writer(f, delimiter='\t') # 每行输入进去的两个元素用tab隔开
out_writer.writerow([sentence, label])
# if iter_count >= 11:
if iter_count >= float("inf"):
break
iter_count+=1
pos_neg_in_one(input="./train",output_file="./train.tsv")
pos_neg_in_one(input="./test",output_file="./test.tsv")运行一下得到两个整理好的tsv文件,文本都挺长的2.5万条文本,一个训练集就30MB

做一个微缩版mini数据集
数据集的label必须既有1,也有0,各自占一半,各10条数据。然后把这些数据复制粘贴四份,就是一个80条数据的一个平衡数据集了.
sentence label
I went and saw this movie last night after being coaxed to by a few friends of mine. I'll admit that I was reluctant to see it because from what I knew of Ashton Kutcher he was only able to do comedy. I was wrong. Kutcher played the character of Jake Fischer very well, and Kevin Costner played Ben Randall with such professionalism. The sign of a good movie is that it can toy with our emotions. This one did exactly that. The entire theater (which was sold out) was overcome by laughter during the first half of the movie, and were moved to tears during the second half. While exiting the theater I not only saw many women in tears, but many full grown men as well, trying desperately not to let anyone see them crying. This movie was great, and I suggest that you go see it before you judge. 1
"Actor turned director Bill Paxton follows up his promising debut, the Gothic-horror ""Frailty"", with this family friendly sports drama about the 1913 U.S. Open where a young American caddy rises from his humble background to play against his Bristish idol in what was dubbed as ""The Greatest Game Ever Played."" I'm no fan of golf, and these scrappy underdog sports flicks are a dime a dozen (most recently done to grand effect with ""Miracle"" and ""Cinderella Man""), but some how this film was enthralling all the same.
The film starts with some creative opening credits (imagine a Disneyfied version of the animated opening credits of HBO's ""Carnivale"" and ""Rome""), but lumbers along slowly for its first by-the-numbers hour. Once the action moves to the U.S. Open things pick up very well. Paxton does a nice job and shows a knack for effective directorial flourishes (I loved the rain-soaked montage of the action on day two of the open) that propel the plot further or add some unexpected psychological depth to the proceedings. There's some compelling character development when the British Harry Vardon is haunted by images of the aristocrats in black suits and top hats who destroyed his family cottage as a child to make way for a golf course. He also does a good job of visually depicting what goes on in the players' heads under pressure. Golf, a painfully boring sport, is brought vividly alive here. Credit should also be given the set designers and costume department for creating an engaging period-piece atmosphere of London and Boston at the beginning of the twentieth century.
You know how this is going to end not only because it's based on a true story but also because films in this genre follow the same template over and over, but Paxton puts on a better than average show and perhaps indicates more talent behind the camera than he ever had in front of it. Despite the formulaic nature, this is a nice and easy film to root for that deserves to find an audience." 1
"As a recreational golfer with some knowledge of the sport's history, I was pleased with Disney's sensitivity to the issues of class in golf in the early twentieth century. The movie depicted well the psychological battles that Harry Vardon fought within himself, from his childhood trauma of being evicted to his own inability to break that glass ceiling that prevents him from being accepted as an equal in English golf society. Likewise, the young Ouimet goes through his own class struggles, being a mere caddie in the eyes of the upper crust Americans who scoff at his attempts to rise above his standing.
What I loved best, however, is how this theme of class is manifested in the characters of Ouimet's parents. His father is a working-class drone who sees the value of hard work but is intimidated by the upper class; his mother, however, recognizes her son's talent and desire and encourages him to pursue his dream of competing against those who think he is inferior.
Finally, the golf scenes are well photographed. Although the course used in the movie was not the actual site of the historical tournament, the little liberties taken by Disney do not detract from the beauty of the film. There's one little Disney moment at the pool table; otherwise, the viewer does not really think Disney. The ending, as in ""Miracle,"" is not some Disney creation, but one that only human history could have written." 1
I saw this film in a sneak preview, and it is delightful. The cinematography is unusually creative, the acting is good, and the story is fabulous. If this movie does not do well, it won't be because it doesn't deserve to. Before this film, I didn't realize how charming Shia Lebouf could be. He does a marvelous, self-contained, job as the lead. There's something incredibly sweet about him, and it makes the movie even better. The other actors do a good job as well, and the film contains moments of really high suspense, more than one might expect from a movie about golf. Sports movies are a dime a dozen, but this one stands out.
This is one I'd recommend to anyone. 1
"Bill Paxton has taken the true story of the 1913 US golf open and made a film that is about much more than an extra-ordinary game of golf. The film also deals directly with the class tensions of the early twentieth century and touches upon the profound anti-Catholic prejudices of both the British and American establishments. But at heart the film is about that perennial favourite of triumph against the odds.
The acting is exemplary throughout. Stephen Dillane is excellent as usual, but the revelation of the movie is Shia LaBoeuf who delivers a disciplined, dignified and highly sympathetic performance as a working class Franco-Irish kid fighting his way through the prejudices of the New England WASP establishment. For those who are only familiar with his slap-stick performances in ""Even Stevens"" this demonstration of his maturity is a delightful surprise. And Josh Flitter as the ten year old caddy threatens to steal every scene in which he appears.
A old fashioned movie in the best sense of the word: fine acting, clear directing and a great story that grips to the end - the final scene an affectionate nod to Casablanca is just one of the many pleasures that fill a great movie." 1
"I saw this film on September 1st, 2005 in Indianapolis. I am one of the judges for the Heartland Film Festival that screens films for their Truly Moving Picture Award. A Truly Moving Picture ""...explores the human journey by artistically expressing hope and respect for the positive values of life."" Heartland gave that award to this film.
This is a story of golf in the early part of the 20th century. At that time, it was the game of upper class and rich ""gentlemen"", and working people could only participate by being caddies at country clubs. With this backdrop, this based-on-a-true-story unfolds with a young, working class boy who takes on the golf establishment and the greatest golfer in the world, Harry Vardon.
And the story is inspirational. Against all odds, Francis Ouimet (played by Shia LaBeouf of ""Holes"") gets to compete against the greatest golfers of the U.S. and Great Britain at the 1913 U.S. Open. Francis is ill-prepared, and has a child for a caddy. (The caddy is hilarious and motivational and steals every scene he appears in.) But despite these handicaps, Francis displays courage, spirit, heroism, and humility at this world class event.
And, we learn a lot about the early years of golf; for example, the use of small wooden clubs, the layout of the short holes, the manual scoreboard, the golfers swinging with pipes in their mouths, the terrible conditions of the greens and fairways, and the play not being canceled even in torrential rain.
This film has stunning cinematography and art direction and editing. And with no big movie stars, the story is somehow more believable.
This adds to the inventory of great sports movies in the vein of ""Miracle"" and ""Remember the Titans.""
FYI - There is a Truly Moving Pictures web site where there is a listing of past winners going back 70 years." 1
"Maybe I'm reading into this too much, but I wonder how much of a hand Hongsheng had in developing the film. I mean, when a story is told casting the main character as himself, I would think he would be a heavy hand in writing, documenting, etc. and that would make it a little biased.
But...his family and friends also may have had a hand in getting the actual details about Hongsheng's life. I think the best view would have been told from Hongsheng's family and friends' perspectives. They saw his transformation and weren't so messed up on drugs that they remember everything.
As for Hongsheng being full of himself, the consistencies of the Jesus Christ pose make him appear as a martyr who sacrificed his life (metaphorically, of course, he's obviously still alive as he was cast as himself) for his family's happiness. Huh?
The viewer sees him at his lowest points while still maintaining a superiority complex. He lies on the grass coming down from (during?) a high by himself and with his father, he contemplates life and has visions of dragons at his window, he celebrates his freedom on a bicycle all while outstretching his arms, his head cocked to the side.
It's fabulous that he's off of drugs now, but he's no hero. He went from a high point in his career in acting to his most vulnerable point while on drugs to come back somewhere in the middle.
This same device is used in Ted Demme's ""Blow"" where the audience empathizes with the main character who is shown as a flawed hero.
However, ""Quitting"" (""Zuotian"") is a film that is recommended, mostly for its haunting soundtrack, superb acting, and landscapes. But, the best part is the feeling that one gets when what we presume to be the house of Jia Hongsheng is actually a stage setting for a play. It makes the viewer feel as if Hongsheng's life was merely a play told in many difficult parts." 1
I felt this film did have many good qualities. The cinematography was certainly different exposing the stage aspect of the set and story. The original characters as actors was certainly an achievement and I felt most played quite convincingly, of course they are playing themselves, but definitely unique. The cultural aspects may leave many disappointed as a familiarity with the Chinese and Oriental culture will answer a lot of questions regarding parent/child relationships and the stigma that goes with any drug use. I found the Jia Hongsheng story interesting. On a down note, the story is in Beijing and some of the fashion and music reek of early 90s even though this was made in 2001, so it's really cheesy sometimes (the Beatles crap, etc). Whatever, not a top ten or twenty but if it's on the television, check it out. 1
This movie is amazing because the fact that the real people portray themselves and their real life experience and do such a good job it's like they're almost living the past over again. Jia Hongsheng plays himself an actor who quit everything except music and drugs struggling with depression and searching for the meaning of life while being angry at everyone especially the people who care for him most. There's moments in the movie that will make you wanna cry because the family especially the father did such a good job. However, this movie is not for everyone. Many people who suffer from depression will understand Hongsheng's problem and why he does the things he does for example keep himself shut in a dark room or go for walks or bike rides by himself. Others might see the movie as boring because it's just so real that its almost like a documentary. Overall this movie is great and Hongsheng deserved an Oscar for this movie so did his Dad. 1
"""Quitting"" may be as much about exiting a pre-ordained identity as about drug withdrawal. As a rural guy coming to Beijing, class and success must have struck this young artist face on as an appeal to separate from his roots and far surpass his peasant parents' acting success. Troubles arise, however, when the new man is too new, when it demands too big a departure from family, history, nature, and personal identity. The ensuing splits, and confusion between the imaginary and the real and the dissonance between the ordinary and the heroic are the stuff of a gut check on the one hand or a complete escape from self on the other. Hongshen slips into the latter and his long and lonely road back to self can be grim.
But what an exceptionally convincing particularity, honesty, and sensuousness director Zhang Yang, and his actors, bring to this journey. No clichés, no stereotypes, no rigid gender roles, no requisite sex, romance or violence scenes, no requisite street language and, to boot, no assumed money to float character acts and whims.
Hongshen Jia is in his mid-twenties. He's a talented actor, impressionable, vain, idealistic, and perhaps emotionally starved. The perfect recipe for his enablers. Soon he's the ""cool"" actor, idolized by youth. ""He was hot in the early nineties."" ""He always had to be the most fashionable."" He needs extremes, and goes in for heavy metal, adopts earrings and a scarf. His acting means the arts, friends--and roles, But not the kind that offer any personal challenge or input. And his self-criticism, dulled by the immediacy of success, opens the doors to an irrational self-doubt, self-hatred-- ""I didn't know how to act"" ""I felt like a phony""--and to readily available drugs to counter them. He says ""I had to get high to do what director wanted."" So, his shallow identity as an actor becomes, via drugs, an escape from identity.
Hongshen's disengagement from drugs and his false life is very gradual, intermittent--and doggedly his own. Solitude, space, meditative thinking, speech refusal, replace therapy. The abstract is out. And a great deal of his change occurs outdoors---not in idealized locations but mainly on green patches under the freeways, bridges, and high-rises of Beijing. The physicality is almost romantic, but is not. The bike rides to Ritan Park, the long spontaneous walks, the drenching sun and rain, grassy picnics, the sky patterns and kites that absorb his musing are very specific. He drifts in order to arrive, all the while picking up cues to a more real and realistic identity. ""I started to open up"" he says of this period in retrospect. And the contact seems to start with his lanky body which projects a kind of dancer's positioning (clumsy, graceful, humorous, telling) in a current circumstance. If mind or spirit is lacking, his legs can compel him to walk all night.
Central to his comeback is the rejection of set roles. To punctuate his end to acting and his determination to a new identity, he smashes his videos and TV, and bangs his head till bloody against his ""John Lennon Forever"" poster. He has let down his iconic anti-establishment artist---but he's the only viable guide he knows. He even imagines himself as John's son (Yoko Ono), and adopts his ""Mother Mary"" as an intercessor in his ""hour of darkness"" and ""time of trouble."" (the wrenching, shaking pain in the park--hallucinatory and skitzoid ordeals) ""Music is so much more real than acting"" he says. And speaks of Lennon's influence as ""showing me a new way."" In the mental institute, the life-saving apples (resistance, nourishment) reflect Lennon's presence, as does Hongshen's need to re-hang his hero's poster in his redecorated room.
If Lennon's influence is spiriting, Hongshen's father's influence is grounding. Although father and son are both actors and users (drugs and drink), it is Fegsen's differences from his son that underwrites his change. For the father is more secure in himself: he accepts that he's Chinese, a peasant in a line of peasants, a rural theater director. And he exercises control over both his habit and his emotions. It's this recognizable identity that drives Hongshen to treat him like a sounding board, sometimes with anger and rage, sometimes with humor (the blue jeans, Beatles) and passivity. In his most crazed, and violent exchange with his father in which he accuses him of being a liar, and a fake, he exposes more of himself than his father: ""all the acts I acted before were bullshit... life is bullshit."" And to Hongshen's emphatic ""you are NOT my father,"" he softly replies, ""why can't a peasant be your father?""
Under these two teachers and with much additional help from his mother, sister, friends, inmates at the rehab inst., he makes some tangible connection to a real (not whole) self. As the long term drug effects recede, so does his old identity. Indebtedness replaces pride, trust distrust. Integrity banishes his black cloud. All his edges soften. ""You are just a human being"" he repeats endlessly after being released from the strap-down incurred for refusing medicine. Back home, lard peasant soap is fine with him now. And his once ""rare and true friendships"" begin again as is so evident in the back to poignant back-to-back fence scene with his musician buddy. Hongshen says of this movie: ""it's a good chance to think about my life."" And I might add, become a New Actor, one bound to art and life. Like Lennon, he has gained success without a loss of identity." 1
Once again Mr. Costner has dragged out a movie for far longer than necessary. Aside from the terrific sea rescue sequences, of which there are very few I just did not care about any of the characters. Most of us have ghosts in the closet, and Costner's character are realized early on, and then forgotten until much later, by which time I did not care. The character we should really care about is a very cocky, overconfident Ashton Kutcher. The problem is he comes off as kid who thinks he's better than anyone else around him and shows no signs of a cluttered closet. His only obstacle appears to be winning over Costner. Finally when we are well past the half way point of this stinker, Costner tells us all about Kutcher's ghosts. We are told why Kutcher is driven to be the best with no prior inkling or foreshadowing. No magic here, it was all I could do to keep from turning it off an hour in. 0
This is an example of why the majority of action films are the same. Generic and boring, there's really nothing worth watching here. A complete waste of the then barely-tapped talents of Ice-T and Ice Cube, who've each proven many times over that they are capable of acting, and acting well. Don't bother with this one, go see New Jack City, Ricochet or watch New York Undercover for Ice-T, or Boyz n the Hood, Higher Learning or Friday for Ice Cube and see the real deal. Ice-T's horribly cliched dialogue alone makes this film grate at the teeth, and I'm still wondering what the heck Bill Paxton was doing in this film? And why the heck does he always play the exact same character? From Aliens onward, every film I've seen with Bill Paxton has him playing the exact same irritating character, and at least in Aliens his character died, which made it somewhat gratifying...
Overall, this is second-rate action trash. There are countless better films to see, and if you really want to see this one, watch Judgement Night, which is practically a carbon copy but has better acting and a better script. The only thing that made this at all worth watching was a decent hand on the camera - the cinematography was almost refreshing, which comes close to making up for the horrible film itself - but not quite. 4/10. 0
First of all I hate those moronic rappers, who could'nt act if they had a gun pressed against their foreheads. All they do is curse and shoot each other and acting like cliché'e version of gangsters.
The movie doesn't take more than five minutes to explain what is going on before we're already at the warehouse There is not a single sympathetic character in this movie, except for the homeless guy, who is also the only one with half a brain.
Bill Paxton and William Sadler are both hill billies and Sadlers character is just as much a villain as the gangsters. I did'nt like him right from the start.
The movie is filled with pointless violence and Walter Hills specialty: people falling through windows with glass flying everywhere. There is pretty much no plot and it is a big problem when you root for no-one. Everybody dies, except from Paxton and the homeless guy and everybody get what they deserve.
The only two black people that can act is the homeless guy and the junkie but they're actors by profession, not annoying ugly brain dead rappers.
Stay away from this crap and watch 48 hours 1 and 2 instead. At lest they have characters you care about, a sense of humor and nothing but real actors in the cast. 0
Not even the Beatles could write songs everyone liked, and although Walter Hill is no mop-top he's second to none when it comes to thought provoking action movies. The nineties came and social platforms were changing in music and film, the emergence of the Rapper turned movie star was in full swing, the acting took a back seat to each man's overpowering regional accent and transparent acting. This was one of the many ice-t movies i saw as a kid and loved, only to watch them later and cringe. Bill Paxton and William Sadler are firemen with basic lives until a burning building tenant about to go up in flames hands over a map with gold implications. I hand it to Walter for quickly and neatly setting up the main characters and location. But i fault everyone involved for turning out Lame-o performances. Ice-t and cube must have been red hot at this time, and while I've enjoyed both their careers as rappers, in my opinion they fell flat in this movie. It's about ninety minutes of one guy ridiculously turning his back on the other guy to the point you find yourself locked in multiple states of disbelief. Now this is a movie, its not a documentary so i wont waste my time recounting all the stupid plot twists in this movie, but there were many, and they led nowhere. I got the feeling watching this that everyone on set was sord of confused and just playing things off the cuff. There are two things i still enjoy about it, one involves a scene with a needle and the other is Sadler's huge 45 pistol. Bottom line this movie is like domino's pizza. Yeah ill eat it if I'm hungry and i don't feel like cooking, But I'm well aware it tastes like crap. 3 stars, meh. 0
Brass pictures (movies is not a fitting word for them) really are somewhat brassy. Their alluring visual qualities are reminiscent of expensive high class TV commercials. But unfortunately Brass pictures are feature films with the pretense of wanting to entertain viewers for over two hours! In this they fail miserably, their undeniable, but rather soft and flabby than steamy, erotic qualities non withstanding.
Senso '45 is a remake of a film by Luchino Visconti with the same title and Alida Valli and Farley Granger in the lead. The original tells a story of senseless love and lust in and around Venice during the Italian wars of independence. Brass moved the action from the 19th into the 20th century, 1945 to be exact, so there are Mussolini murals, men in black shirts, German uniforms or the tattered garb of the partisans. But it is just window dressing, the historic context is completely negligible.
Anna Galiena plays the attractive aristocratic woman who falls for the amoral SS guy who always puts on too much lipstick. She is an attractive, versatile, well trained Italian actress and clearly above the material. Her wide range of facial expressions (signalling boredom, loathing, delight, fear, hate ... and ecstasy) are the best reason to watch this picture and worth two stars. She endures this basically trashy stuff with an astonishing amount of dignity. I wish some really good parts come along for her. She really deserves it. 0
"A funny thing happened to me while watching ""Mosquito"": on the one hand, the hero is a deaf-mute and the director is totally unable to make us understand why he does what he does (mutilating mannequins...er, excuse me, corpses) through his images. On the other hand, the English version at least is very badly dubbed. So I found myself wishing there had been both more AND less dialogue at the same time! This film is stupid (funny how this guy has access to every graveyard and mortuary in his town) and lurid (where would we be in a 70s exploitationer without our gratuitous lesbian scene?). Not to mention the ""romantic"" aspect (oh, how sweet!)...Miss it. (*)" 0
This German horror film has to be one of the weirdest I have seen.
I was not aware of any connection between child abuse and vampirism, but this is supposed based upon a true character.
Our hero is deaf and mute as a result of repeated beatings at the hands of his father. he also has a doll fetish, but I cannot figure out where that came from. His co-workers find out and tease him terribly.
During the day a mild-manner accountant, and at night he breaks into cemeteries and funeral homes and drinks the blood of dead girls. They are all attractive, of course, else we wouldn't care about the fact that he usually tears their clothing down to the waist. He graduates eventually to actually killing, and that is what gets him caught.
Like I said, a very strange movie that is dark and very slow as Werner Pochath never talks and just spends his time drinking blood. 0
"Being a long-time fan of Japanese film, I expected more than this. I can't really be bothered to write to much, as this movie is just so poor. The story might be the cutest romantic little something ever, pity I couldn't stand the awful acting, the mess they called pacing, and the standard ""quirky"" Japanese story. If you've noticed how many Japanese movies use characters, plots and twists that seem too ""different"", forcedly so, then steer clear of this movie. Seriously, a 12-year old could have told you how this movie was going to move along, and that's not a good thing in my book.
Fans of ""Beat"" Takeshi: his part in this movie is not really more than a cameo, and unless you're a rabid fan, you don't need to suffer through this waste of film.
2/10" 0
"""Tokyo Eyes"" tells of a 17 year old Japanese girl who falls in like with a man being hunted by her big bro who is a cop. This lame flick is about 50% filler and 50% talk, talk, and more talk. You'll get to see the less than stellar cast of three as they talk on the bus, talk and play video games, talk and get a haircut, talk and walk and walk and talk, talk on cell phones, hang out and talk, etc. as you read subtitles waiting for something to happen. The thin wisp of a story is not sufficient to support a film with low end production value, a meager cast, and no action, no romance, no sex or nudity, no heavy drama...just incessant yadayadayada'ing. (C-)" 0
Wealthy horse ranchers in Buenos Aires have a long-standing no-trading policy with the Crawfords of Manhattan, but what happens when the mustachioed Latin son falls for a certain Crawford with bright eyes, blonde hair, and some perky moves on the dance floor? 20th Century-Fox musical has a glossy veneer yet seems a bit tatty around the edges. It is very heavy on the frenetic, gymnastic-like dancing, exceedingly thin on story. Betty Grable (an eleventh hour replacement for Alice Faye) gives it a boost, even though she's paired with leaden Don Ameche (in tan make-up and slick hair). Also good: Charlotte Greenwood as Betty's pithy aunt, a limousine driver who's constantly asleep on the job, and Carmen Miranda playing herself (who else?). The stock shots of Argentina far outclass the action filmed on the Fox backlot, and some of the supporting performances are quite awful. By the time of the big horserace finale, most viewers will have had enough. *1/2 from **** 0数据集路径修改
ine9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/imdb"
data_dir = "./datasets/imdb/mini"BERT配置文件
用的是bert-base-uncased,之前下载了、用了,不必重复下载
line18
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased"
bert_model_dir = "./datasets/bert_files/bert-base-uncased"跑一下吧
python run_imdb.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1可以跑通
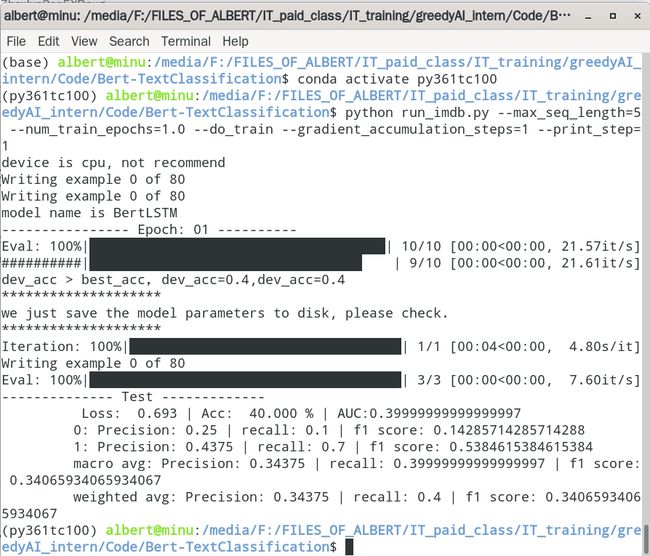
其他七个模型可以跑通吗?
所有模型都被保存在这个文件夹“/.imdb_output”
可以跑通的模型
BertLSTM
BertOrigin
BertCNN(最小长度为10)
BertATT
BertRCNN
BertCNNPlus(最小长度11)
BertDPCNN
BertDPCNN
(6)run_Multi_CNews.py
数据集和bert文件
数据集路径,line7
# data_dir = "/search/hadoop02/suanfa/songyingxin/data/cnews"
data_dir = "./datasets/THUCNews/mini"line15
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-chinese-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-chinese-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-chinese"
bert_model_dir = "./datasets/bert_files/bert-base-chinese"跑一下代码
python run_Multi_CNews.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1报错,说没有这个包(作者的这个代码里确实没有这个包)
Traceback (most recent call last):
File "run_Multi_CNews.py", line 2, in
from multi_main import main
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/multi_main.py", line 19, in
from Utils.train_evalute import train, evaluate
ModuleNotFoundError: No module named 'Utils.train_evalute' “multi_main.py”line19,这样改
# from Utils.train_evalute import train, evaluate
from train_evalute import train, evaluate然后报这个错,问我要json文件。
Traceback (most recent call last):
File "run_Multi_CNews.py", line 26, in
model_times, NewsProcessor)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/multi_main.py", line 63, in main
config.data_dir, tokenizer, processor, config.max_seq_length, config.train_batch_size, "train", config.max_sentence_num)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/Utils/MultiSentences_utils.py", line 168, in load_data
examples = processor.get_train_examples(data_dir, max_sentence_num)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/Processors/MultiNewsProcessor.py", line 18, in get_train_examples
self._read_json(os.path.join(data_dir, "train.json")), "train", max_sentence_num)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/Processors/MultiSentenceProcessor.py", line 27, in _read_json
with open(input_file, "r", encoding='utf-8') as f:
FileNotFoundError: [Errno 2] No such file or directory: './datasets/THUCNews/mini/train.json' 但是我不知道,要以什么样的格式来组织json文件。就此作罢。作者也一点介绍也没有。
(7)Yahoo_Answers
数据集
'YahooAnswers':' https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9Qhbd2JNdDBsQUdocVU',
下载下来

里面这个四个东西放到这个位置“./datasets/yahoo_answers”
训练集和测试集都是csv文件,组织形式如下
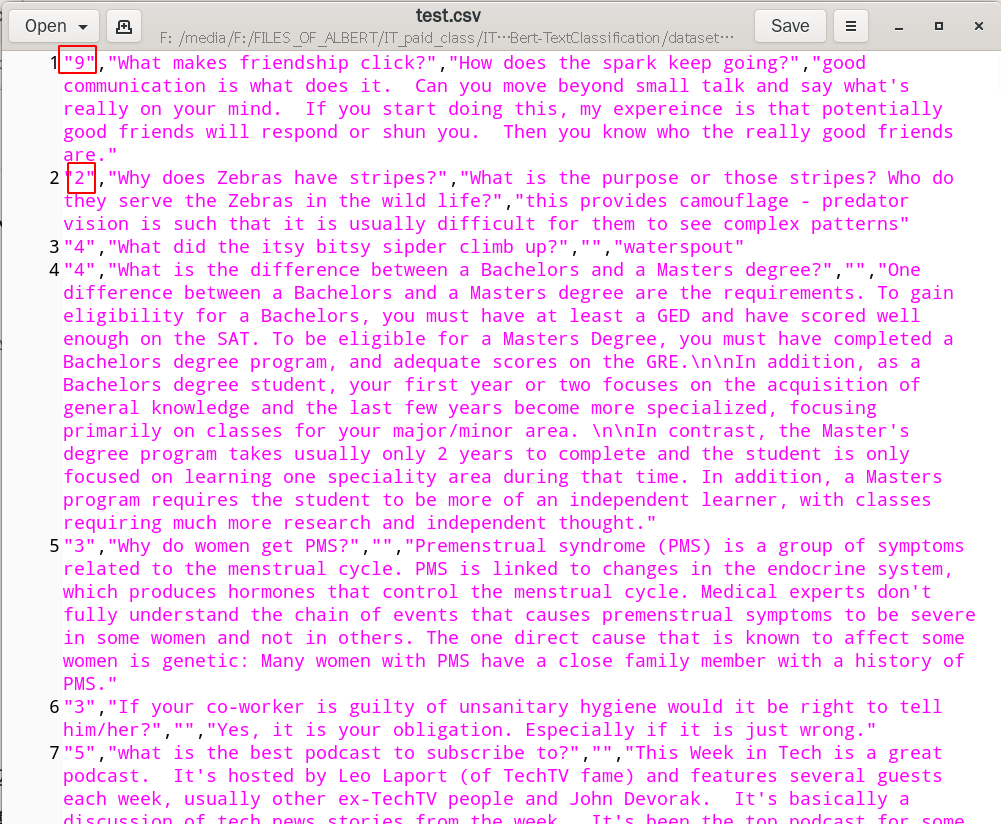
一行一条数据,每行第一个元素是标签类别,第2个元素是问题,第三个元素是回答
请你模仿对AG‘news数据的处理方法,处理这个数据集
import csv
def trans(input_file,output_file_sentence):
labels = []
titles = []
sentences = []
# 打开文件
with open(input_file, 'r') as fh:
lines = fh.readlines()
print(len(lines))
iter_count =1
for line in lines:
label = int(line[1])
sentence = line[5:-2]
# print(label)
# print(sentence)
# 把数据集存进列表
labels.append(label)
sentences.append(sentence)
# if iter_count > 11:
if iter_count > float("inf"):
break
iter_count += 1
# 把完整的句子写入
with open(output_file_sentence, 'w') as f:
out_writer = csv.writer(f, delimiter='\t')
# 第一行表头,写入
out_writer.writerow(['sentence', 'label'])
print("labels:{}".format(len(labels)))
for i in range(len(labels)):
out_writer.writerow([sentences[i], labels[i]])
if __name__ == "__main__":
trans("train.csv", "train.tsv")
trans("test.csv", "test.tsv")网上的分析:报错原因:模型的网络对不上正在加载的网络,建议检查__init__(),看缺了或多了某些网络结构
line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/yahoo_answers"
data_dir = "./datasets/yahoo_answers"做个mini数据集
line10
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/yahoo_answers"
data_dir = "./datasets/yahoo_answers/mini"加载BERT模型相关文件
用的这个bert-base-uncased
line18
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased"
bert_model_dir = "./datasets/bert_files/bert-base-uncased"跑一下代码
python run_yahoo_answers.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1可以跑通,长这样

其他六个模型可以跑通吗?
可以跑通的模型
BertLSTM
BertOrigin
BertCNN(最低句子长度为10)
BertATT
BertRCNN
BertCNNPlus
BertDPCNN(句子长度为5可以,长度为11会报下面这个尺寸不匹配的错误)
Traceback (most recent call last):
File "run_yahoo_answers.py", line 51, in
main(config, config.save_name, label_list)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/main.py", line 131, in main
criterion, config.gradient_accumulation_steps, device, label_list, output_model_file, output_config_file, config.log_dir, config.print_step, config.early_stop)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/train_evalute.py", line 69, in train
logits = model(input_ids, segment_ids, input_mask, labels=None)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/IT_training/greedyAI_intern/Code/Bert-TextClassification/BertDPCNN/BertDPCNN.py", line 69, in forward
logits = self.classifier(x)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/modules/linear.py", line 67, in forward
return F.linear(input, self.weight, self.bias)
File "/home/albert/anaconda3/envs/py361tc100/lib/python3.6/site-packages/torch/nn/functional.py", line 1354, in linear
output = input.matmul(weight.t())
RuntimeError: size mismatch, m1: [12800 x 2], m2: [200 x 10] at /opt/conda/conda-bld/pytorch-cpu_1544218188686/work/aten/src/TH/generic/THTensorMath.cpp:940 (8)YelpReviewFull
数据集
'YelpReviewFull': https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbZlU4dXhHTFhZQU0“”
转成tsv格式,用和“Yahoo_Answers”一样的方法转成作者要求的tsv格式
import csv
def trans(input_file,output_file_sentence):
labels = []
titles = []
sentences = []
# 打开文件
with open(input_file, 'r') as fh:
lines = fh.readlines()
print(len(lines))
iter_count =1
for line in lines:
label = int(line[1])
sentence = line[5:-2]
# print(label)
# print(sentence)
# 把数据集存进列表
labels.append(label)
sentences.append(sentence)
# if iter_count > 11:
if iter_count > float("inf"):
break
iter_count += 1
# 把完整的句子写入
with open(output_file_sentence, 'w') as f:
out_writer = csv.writer(f, delimiter='\t')
# 第一行表头,写入
out_writer.writerow(['sentence', 'label'])
print("labels:{}".format(len(labels)))
for i in range(len(labels)):
out_writer.writerow([sentences[i], labels[i]])
if __name__ == "__main__":
trans("train.csv", "train.tsv")
trans("test.csv", "test.tsv")line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/yelp_review_full"
data_dir = "./datasets/yelp_review_full"bert相关文件
line18
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased"
bert_model_dir = "./datasets/bert_files/bert-base-uncased"换成mini数据集,尽快看看各种数据集能否跑通?
line11
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/yelp_review_full"
# data_dir = "./datasets/yelp_review_full"
data_dir = "./datasets/yelp_review_full/mini"100条数据不够保存模型的迭代次数的,180条就够了
跑一下试试
python run_yelp_review_full.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1可以跑通
其他六个模型试试
可以跑通的模型
BertLSTM
BertOrigin
BertCNN
BertATT
BertRCNN
BertCNNPlus
BertDPCNN
(9)YelpReviewPolarity
数据集
'YelpReviewPolarity':' https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbNUpYQ2N3SGlFaDg',
转成tsv文件
import csv
def trans(input_file,output_file_sentence):
labels = []
titles = []
sentences = []
# 打开文件
with open(input_file, 'r') as fh:
lines = fh.readlines()
print(len(lines))
iter_count =1
for line in lines:
label = int(line[1])
sentence = line[5:-2]
# print(label)
# print(sentence)
# 把数据集存进列表
labels.append(label)
sentences.append(sentence)
# if iter_count > 11:
if iter_count > float("inf"):
break
iter_count += 1
# 把完整的句子写入
with open(output_file_sentence, 'w') as f:
out_writer = csv.writer(f, delimiter='\t')
# 第一行表头,写入
out_writer.writerow(['sentence', 'label'])
print("labels:{}".format(len(labels)))
for i in range(len(labels)):
out_writer.writerow([sentences[i], labels[i]])
if __name__ == "__main__":
trans("train.csv", "train.tsv")
trans("test.csv", "test.tsv")创建mini数据集
line9
# data_dir = "/search/hadoop02/suanfa/songyingxin/SongWork/PaperDataset/yelp_review_polarity"
data_dir = "./datasets/yelp_review_polarity/mini"配置bert文件
用的这个bert-base-uncased
# bert-base
# bert_vocab_file = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased-vocab.txt"
bert_vocab_file = "./datasets/bert_files/bert-base-uncased-vocab.txt"
# bert_model_dir = "/search/hadoop02/suanfa/songyingxin/pytorch_Bert/bert-base-uncased"
bert_model_dir = "./datasets/bert_files/bert-base-uncased"跑一下
python run_yelp_review_polarity.py --max_seq_length=5 --num_train_epochs=1.0 --do_train --gradient_accumulation_steps=1 --print_step=1可以跑通
其他六个模型试试
目前可以跑通的模型
BertLSTM
BertOrigin
BertCNN
BertATT
BertRCNN
BertCNNPlus
BertDPCNN