实验十一 Pandas 库入门与进阶
1. 利用字典 data 和列表 labels 完成以下操作
data = {'animal':['cat','cat','snake','dog','dog','cat','snake','cat','dog','dog'],'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],'visits':[1,3,2,3,2,3,1,1,2,1],'priority':['yes',np.nan,'no','yes','no','no','no','yes','no','no']}
labels = ['a','b','c','d','e','f','g','h','i','j']
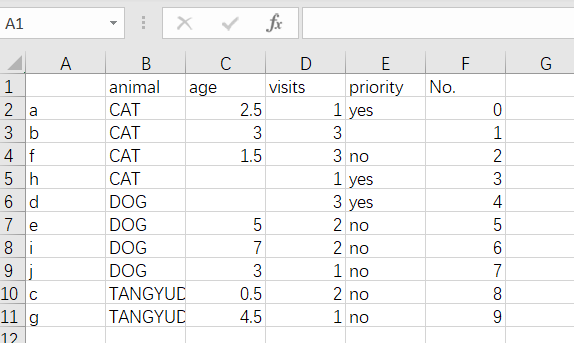
(1) 创建 DataFrame 类型 df,效果如下图:

(2)输出 df 的前三行,并选择所有 visits 属性值大于 2 的所有行
(3)输出 df 缺失值所在的行,输出'age'与'animal'两列数据
(4) 输出 animal==cat 且 age<3 的所有行,并将行为”f”列为”age”的元素值修改为 1.5
(5)计算 animal 列所有取值的出现的次数
(6)将 animal 列中所有 snake 替换为 tangyudi
(7)对 df 按列 animal 进行排序
(8)在 df 的在后一列后添加一列列名为 No.数据 0,1,2,3,4,5,6,7,8,9
(9)对 df 中的'visits'列求平均值以及乘积、和
(10)将 animal 对应的列中所有字符串字母变为大写
(11)利用浅复制方式创建 df 的副本 df2 并将其所有缺失值填充为 3
(12)利用浅复制方式创建 df 的副本 df3 并将其删除缺失值所在的行
(13)将 df 写入 animal.csv 文件
import pandas as pd
import numpy as np
data = {'animal':['cat','cat','snake','dog','dog','cat','snake','cat','dog','dog'],\
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],\
'visits':[1,3,2,3,2,3,1,1,2,1],\
'priority':['yes',np.nan,'no','yes','no','no','no','yes','no','no']}
labels = ['a','b','c','d','e','f','g','h','i','j']
df=pd.DataFrame(data,index=labels,columns=data)#创建 DataFrame 类型 df
#(1) 创建 DataFrame 类型 df,columns,index分别为指定行和列的索引值,列表类型
print(df)
print('\n')
###以下操作均改变原数组###
#(2)输出 df 的前三行,并选择所有 visits 属性值大于 2 的所有行
print(df.iloc[0:3])#输出前三行
print('\n')
print(df.loc[df['visits']>2]) #.loc[]行索引visits属性值大于2的行
print('\n')
#(3)输出 df 缺失值所在的行,输出'age'与'animal'两列数据
print(df[df.index.isnull()]) #df缺失值所在行
print('\n')
print(df[['age','animal']]) #输出age与animal两列数据
print('\n')
#(4) 输出 animal==cat 且 age<3 的所有行,并将行为”f”列为”age”的元素值修改为 1.5
print(df.loc[(df['animal']=="cat") & (df['age']<3)])
df.iloc[5,1]=1.5 #修改元素值
print('\n')
#(5)计算 animal 列所有取值的出现的次数
a=set(df['animal']) #利用集合
num1=len(a) #集合长度即为个数
print('出现次数:',num1)
print('\n')
#(6)将 animal 列中所有 snake 替换为 tangyudi
df.loc[df['animal']=='snake','animal']='tangyudi'
# loc行索引把'animal'中值为'snake'的行对应的animal替换成tangyudi
print(df)
print('\n')
#(7)对 df 按列 animal 进行排序
df=df.sort_values(by=['animal'])
#by:就是要根据哪一列排序的列名,或者是索引名,是str类型,或者是list
print(df)
print('\n')
#(8)在 df 的在后一列后添加一列列名为 No.数据 0,1,2,3,4,5,6,7,8,9
df['No.']=[0,1,2,3,4,5,6,7,8,9]
print(df)
print('\n')
#(9)对 df 中的'visits'列求平均值以及乘积、和
print("'visits'列的平均值:",df['visits'].mean())
num=1
for i in df['visits']:
num*=i
print("'visits'列的乘积:",num)
num=0
for i in df['visits']:
num+=i
print("'visits'列的和:",num)
print('\n')
#(10)将 animal 对应的列中所有字符串字母变为大写
df['animal'] = df['animal'].str.upper()
print(df)
print('\n')
#(11)利用浅复制方式创建 df 的副本 df2 并将其所有缺失值填充为 3
df2=df.copy() #复制
df2=df2.fillna(3) #df.fillna() 填充缺失值
print(df2)
print('\n')
#(12)利用浅复制方式创建 df 的副本 df3 并将其删除缺失值所在的行
df3=df.copy()
df3=df3.dropna() #df.dropna() 删除含有缺失值的行,删除含缺失值的列:(axis=1)
print(df3)
print('\n')
#(13)将 df 写入 animal.csv 文件
with open ("animal.csv","w+") as fp:
df.to_csv("animal.csv") #写入csv文件
fp.close() #可选项
(13)将df写入animal.csv文件,如下图所示:
先占个坑 以下题目回头再续
2.读取文件“haberman-kmes.dat”生成名为 dft 的 DataFrame,并进行如下操作:
(1) 列名为“Class”中取值分别将“negative”和“positive”替换为数字 0 和 1,并统计 0 和 1 各自出现的频数;
(2) 创建df的副本df2,其中df2为除了df最后一列之外的所有列;
(3) 将 df2 的每一列数据进行归一化处理,即 ![]() 其中 x 为列中的任一数据,
其中 x 为列中的任一数据,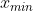 ,
,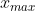 分别为列中所有数据的最大值和最小值;
分别为列中所有数据的最大值和最小值;
(4)计算 df2 行(样本或观测值)与行(样本或观测值)之间的欧式距离,并组成新的欧式距离数组 df3。
(5)将 df3 中所有的行中的数据从小到大的顺序进行排序
3.读取文件“adult.dat”生成名为 df 的 DataFrame,并进行如下操作:
(1) 删除该数据集中全部含有缺失值的行数据;
(2) 删除该数据集中重复的行数据;
(3) 按照 class 字段将该数据进行分组,并计算各组中列分别 age, Education-num,Capital-gain, Capital-loss 和 Hours-per-week 的均值和方差,并计算其余各列中不重复元素的个数以及所占的比例
(4) 将列 Age 字段取值划分为青年人(0-18)、中年人(19-45)、老年人 (45-100),并故根据该属性将该数据进行分组,然后计算各组中列分别 Education-num,Capital-gain, Capital-loss 和 Hours-per-week 的均值和方差,并计算其余各列中不重复元素的个数以及所占的比例。