mvc和mvvm的区别
前言
mvc和mvvm大概是个老生常谈的问题了,关于MVC和MVVM如此这般设计的原因以及我们应该如何思考一些相关的问题
1.在看mvc和mvvm的区别之前我们来看一下前端的发展历史
在上个世纪的1989年,欧洲核子研究中心的物理学家Tim Berners-Lee发明了超文本标记语言(HyperText Markup Language),简称HTML,并在1993年成为互联网草案。从此,互联网开始迅速商业化,诞生了一大批商业网站。
最早的HTML页面是完全静态的网页,它们是预先编写好的存放在Web服务器上的html文件。浏览器请求某个URL时,Web服务器把对应的html文件扔给浏览器,就可以显示html文件的内容了。
如果要针对不同的用户显示不同的页面,显然不可能给成千上万的用户准备好成千上万的不同的html文件,所以,服务器就需要针对不同的用户,动态生成不同的html文件。一个最直接的想法就是利用C、C++这些编程语言,直接向浏览器输出拼接后的字符串。这种技术被称为CGI:Common Gateway Interface。
很显然,像新浪首页这样的复杂的HTML是不可能通过拼字符串得到的。于是,人们又发现,其实拼字符串的时候,大多数字符串都是HTML片段,是不变的,变化的只有少数和用户相关的数据,所以,又出现了新的创建动态HTML的方式:ASP、JSP和PHP——分别由微软、SUN和开源社区开发。
在ASP中,一个asp文件就是一个HTML,但是,需要替换的变量用特殊的<%=var%>标记出来了,再配合循环、条件判断,创建动态HTML就比CGI要容易得多。
但是,一旦浏览器显示了一个HTML页面,要更新页面内容,唯一的方法就是重新向服务器获取一份新的HTML内容。如果浏览器想要自己修改HTML页面的内容,就需要等到1995年年底,JavaScript被引入到浏览器。
有了JavaScript后,浏览器就可以运行JavaScript,然后,对页面进行一些修改。JavaScript还可以通过修改HTML的DOM结构和CSS来实现一些动画效果,而这些功能没法通过服务器完成,必须在浏览器实现。
用JavaScript在浏览器中操作HTML,经历了若干发展阶段:
第一阶段,直接用JavaScript操作DOM节点,使用浏览器提供的原生API:
第二阶段,由于原生API不好用,还要考虑浏览器兼容性,jQuery横空出世,以简洁的API迅速俘获了前端开发者的芳心:
第三阶段,MVC模式,需要服务器端配合,JavaScript可以在前端修改服务器渲染后的数据。
现在,随着前端页面越来越复杂,用户对于交互性要求也越来越高,想要写出Gmail这样的页面,仅仅用jQuery是远远不够的。MVVM模型应运而生。
MVVM最早由微软提出来,它借鉴了桌面应用程序的MVC思想,在前端页面中,把Model用纯JavaScript对象表示,View负责显示,两者做到了最大限度的分离。
2.现在让我们从MVC开始
几乎所有的App都只干这么一件事:将数据展示给用户看,并处理用户对界面的操作。
MVC的思想:一句话描述就是Controller负责将Model的数据用View显示出来,换句话说就是在Controller里面把Model的数据赋值给View,比如在controller中写document.getElementById("box").innerHTML = data[”title”],只是还没有刻意建一个Model类出来而已。
M、V、C
Model(模型):是应用程序中用于处理应用程序数据逻辑的部分。
通常模型对象负责在数据库中存取数据。
比如我们人类有一双手,一双眼睛,一个脑袋,没有尾巴,这就是模型,Model定义了这个模块的数据模型。
在代码中体现为数据管理者,Model负责对数据进行获取及存放。
数据不可能凭空生成的,要么是从服务器上面获取到的数据,要么是本地数据库中的数据,
也有可能是用户在UI上填写的表单即将上传到服务器上面存放,所以需要有数据来源。
既然Model是数据管理者,则自然由它来负责获取数据。
Controller不需要关心Model是如何拿到数据的,只管调用就行了。
数据存放的地方是在Model,而使用数据的地方是在Controller,
所以Model应该提供接口供controller访问其存放的数据(通常通过.h里面的只读属性)
View(视图):是应用程序中处理数据显示的部分。
通常视图是依据模型数据创建的。
View,视图,简单来说,就是我们在界面上看见的一切。
它们有一部分是我们UI定死的,也就是不会根据数据来更新显示的,
比如一些Logo图片啊,这里有个按钮啊,那里有个输入框啊,一些显示特定内容的label啊等等;
有一部分是会根据数据来显示内容的,比如tableView来显示好友列表啊,
这个tableView的显示内容肯定是根据数据来显示的。
我们使用MVC解决问题的时候,通常是解决这些根据数据来显示内容的视图。
Controller(控制器):是应用程序中处理用户交互的部分。
通常控制器负责从视图读取数据,控制用户输入,并向模型发送数据。
Controller是MVC中的数据和视图的协调者,也就是在Controller里面把Model的数据赋值给View来显示
(或者是View接收用户输入的数据然后由Controller把这些数据传给Model来保存到本地或者上传到
服务器)。
综合以上内容,实际上你应该可以通过面向对象的基本思想来推导出controller出现的原因:我们所有的App都是界面和数据的交互,所以需要类来进行界面的绘制,于是出现了View,需要类来管理数据于是出现了Model。我们设计的View应该能显示任意的内容比如页面中显示的文字应该是任意的而不只是某个特定Model的内容,所以我们不应该在View的实现中去写和Model相关的任何代码,如果这样做了,那么View的可扩展性就相当低了。而Model只是负责处理数据的,它根本不知道数据到时候会拿去干啥,可能拿去作为算法噼里啪啦去了,可能拿去显示给用户了,它既然无法接收用户的交互,它就不应该去管和视图相关的任何信息,所以Model中不应该写任何View相关代码。然而我们的数据和界面应该同步,也就是一定要有个地方要把Model的数据赋值给View,而Model内部和View的内部都不可能去写这样的代码,所以只能新创造一个类出来了,取名为Controller。
3.下面来看这张图
斯坦福大学公开课上的这幅图来说明,这可以说是最经典和最规范的MVC标准
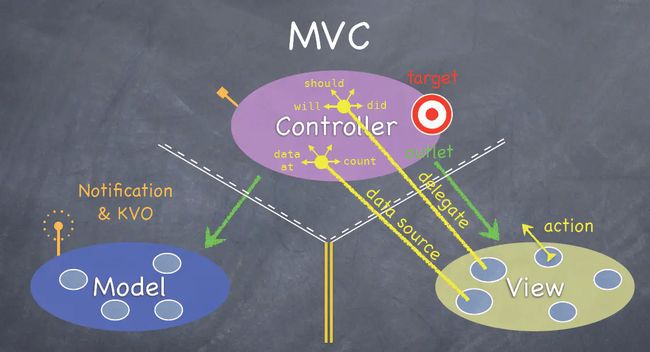
mvc.png
这张图把MVC分为三个独立的区域,并且中间用了一些线来隔开。很有意思的设计,因为这些线似乎出现在了驾校科目一的内容中,你瞧C和V以及C和M之间的白线,一部分是虚线一部分是实线对吧,这就表明了引用关系:C可以直接引用V和M,而V和M不能直接引用C,至少你不能显式的在V和M的代码中去写和C相关的任何代码,而V和M之间则是双黄线,没错,它们俩谁也不能引用谁,你既不能在M里面写V,也不能在V里面写M。哦,上面的描述有点小小的问题,你不是“不能”这样写,而是“不应该”这样写,没人能阻止你在写代码的时候在一个M里面去写V,但是一旦你这样做了,那么你就违背了MVC的规范,你就不是在使用MVC了,所以这算是MVC的一个必要条件:使用MVC –> M里面没有V的代码。所以M里面没有V的代码就是使用MVC的必要条件。
View和Controller的交互
按钮点击事件,是View来接收的,但是处理这个事件的应该是Controller,所以View把这个事件传递给了Controller,如何传递的呢,见图,看到View上面的action没有,这就是事件,看到Controller上面的target没有,这就是靶子,View究竟要把事件传递给谁,它被规定了传递给靶子,Controller实际上就是靶子。只是View只负责传递事件,不负责关心靶子是谁。就像你是一个负责运货的少年,你唯一知道的是你要把货(action)交给上头(开发者)告诉你的那个收货的人(target),至于那个收货的人是警察还是怪兽,你都不需要关心。这是V和C的一种交互方式,叫做target-action。所以你看,这张图简直就是神来之笔,旁边还栩栩如生的画出了V对C的另一种传值:协议-委托。委托有两种:代理和数据源。什么是代理,就是专门处理should、will、did事件的委托,什么是数据源,就是专门处理data、count等等的委托。
Model和Controller的交互
M是干嘛的?上面说了,M就是数据管理者,你可以理解为它直接和数据库打交道。这里的数据库可能是本地的,也可能是服务器上的,M会从数据库获取数据,也可能把数据上传给数据库。M也将提供属性或者接口来供C访问其持有的数据。我们就拿一个简单的需求作为例子,假如我想在一个模块中显示一段文字,这段文字是从网上获取下来的。
那么使用MVC的话,在C中肯定需要一个UILabel(V)作为属性来显示这段文字,而这段文字由谁来获取呢,肯定是由M来获取了。而获取的地方在哪里呢?通常在C的生命周期里面,所以往往是在C的一个生命周期方法比如viewDidLoad里面调用M获取数据的方法来获取数据。现在问题来了,M获取数据的方法是异步的网络请求,网络请求结束后,C才应该用请求下来的数据重新赋值给V,现在的问题是,C如何知道网络请求结束了?
这里我们一定要换一种角度去思考,我们进一步考虑M和V之间的关系:它们应该是一种同步的关系,也就是,不管任何时刻,只要M的值发生改变,V的显示就应该发生改变(显示最新的M的内容)。所以我们可以关注M的值改变,而不用关心M的网络请求是否结束了。实际上C根本不知道M从哪去拿的数据,C的责任是负责把M最新的数据赋值给V。所以C应该关注的事件是:M的值是否发生了变化。
4.MVVM
MVVM的诞生
就像我们之前分析MVC是如何合理分配工作的一样,我们需要数据所以有了M,我们需要界面所以有了V,而我们需要找一个地方把M赋值给V来显示,所以有了C,然而我们忽略了一个很重要的操作:数据解析。在MVC出生的年代,手机APP的数据往往都比较简单,没有现在那么复杂,所以那时的数据解析很可能一步就解决了,所以既然有这样一个问题要处理,而面向对象的思想就是用类和对象来解决问题,显然V和M早就被定义死了,它们都不应该处理“解析数据”的问题,理所应当的,“解析数据”这个问题就交给C来完成了。而现在的手机App功能越来越复杂,数据结构也越来越复杂,所以数据解析也就没那么简单了。如果我们继续按照MVC的设计思路,将数据解析的部分放到了Controller里面,那么Controller就将变得相当臃肿。还有相当重要的一点:Controller被设计出来并不是处理数据解析的。1、管理自己的生命周期;2、处理Controller之间的跳转;3、实现Controller容器。这里面根本没有“数据解析”这一项,所以显然,数据解析也不应该由Controller来完成。那么我们的MVC中,M、V、C都不应该处理数据解析,那么由谁来呢?这个问题实际上在面向对象的时候相当好回答:既然目前没有类能够处理这个问题,那么就创建一个新的类出来解决不就好了?所以我们聪明的开发者们就专门为数据解析创建出了一个新的类:ViewModel。这就是MVVM的诞生。
如何实现MVVM
搞清楚了MVVM为什么会出现,将对于你理解如何实现MVVM有极大的帮助。在我们开始着手实现MVVM之前,我先简单提一下之前遗留的一个问题:为什么MVVM这个名字里面,没有Controller的出现(为什么不叫MVCVM,C去哪了)。本来这个问题应该在实现后再来解释,但是我们这里是教学,为了让大家更好的明白我们接下来的思想,所以这里要提前解释一下这个结论:Controller的存在感被完全的降低了。我们在待会实现MVVM的时候你就能体会到了,这里请先把这个结论印在脑海当中:Controller的存在感被完全的降低了、Controller的存在感被完全的降低了、Controller的存在感被完全的降低了。
好的,我们终于要开始着手实现MVVM了。如果你已经搞懂了MVC,那么用MVVM实现一个相同的功能将会变得非常简单。你只需要记住两点:1、Controller的存在感被完全的降低了;2、VM的出现就是Controller存在感降低的原因。
Controller存在感降低的原因
在MVVM中,Controller不再像MVC那样直接持有Model了。想象Controller是一个Boss,数据是一堆文件(Model),如果现在是MVC,那么数据解析(比如整理文件)需要由Boss亲自完成,然而实际上Boss需要的仅仅是整理好的文件而不是那一堆乱七八糟的整理前的文件。所以Boss招聘了一个秘书,现在Boss就不再需要管理原始数据(整理之前的文件)了,他只需要去找秘书:你帮我把文件整理好后给我。那么这个秘书就首先去拿到文件(原始数据),然后进行整理(数据解析),接下来把整理的结果给Boss。所以秘书就是VM了,并且Controller(Boss)现在只需要直接持有VM而不需要再持有M了。如果再进一步理解C、VM、M之间的关系:因为Controller只需要数据解析的结果而不关心过程,所以就相当于VM把“如何解析Model”给封装起来了,C甚至根本就不需要知道M的存在就能把工作做好,前提它需要持有一个VM。那么我们MVVM中的持有关系就是:C持有VM,VM持有M。这里有一个比较争议的地方:C该不该持有M。我的答案是不该。为什么呢,因为C持有M没有任何意义。就算C直接拿到了M的数据,它还是要去让VM进行数据解析,而数据解析就需要M,那么直接让VM持有M而C直接持有VM就足够了。最后再分享一个我在实现MVVM中的一个技巧,也谈不上是技巧吧,算是一种必要的思想:一旦在实现Controller的过程中遇到任何跟Model(或者数据)相关的问题,就找VM要答案。这个思想待会我们会在实现代码的时候用到。