大规模C++编译性能优化系统OMAX介绍

导读:本文探索&研究了大规模C/C++服务编译性能优化相关技术,优化服务性能,降低机器成本,同时为了支持规模推广应用,降低业务线接入成本,保障优化效果,进行面向云上微服务,开展平台化优化服务系统OMAX建设,并在百度推荐系统上大规模应用,取得线上服务CPU性能优化10%+和上线速度提升40%+双收益,优化后服务运行稳定,性能收益持续。
全文11509字,预计阅读时间29分钟。
一、背景
随着大型互联网公司的业务不断发展,后端C++模块的逻辑处理越来越复杂,且参与开发人员众多,代码质量参差不齐,服务面临性能不断退化风险,大型程序模块,常见的通过代码上优化,主要存在以下问题:
-
成本高:典型推荐业务服务海量代码,逻辑功能复杂,有的往往需要深入理解业务进行优化,优化门槛高
-
效率低:模块迭代频繁,定向优化,没有一定的通用性和可持续性,往往随着迭代优化逐渐消失优势,需要不断循环往复投入开展优化
二、编译优化技术简介
编译优化技术,主要通过编译器或者优化工具框架来优化改写代码实现,实现性能提升,同时保障和未优化时功能上一致,对于代码开发者透明,这样可降低人工代码优化成本,提升优化效率,且可持续解决一类性能问题。
目前编译性能优化技术,按照编译过程来划分,主要有编译期,链接期和编译后的优化,下面简要介绍下这些优化技术特点,使用方式和优化效果等情况。
2.1 编译期
- 基础参数优化
在程序编译期间进行的优化,主要是基于编译器提供的能力,在不同的场景,综合编译时间,编译产出体积大小、性能优化幅度和CPU硬件支持等权衡选择最合适的优化参数,各参数优化汇总如下表:

优化效果:
通过测试程序(排序算法),验证下参数类优化效果,测试O3优化情况下,相比没有开优化方式,处理性能提升49%,可见参数优化简单有效。

- PGO反馈编译优化技术
FDO/AutoFDO
通过收集程序性能优化数据,编译期间结合该性能反馈数据,指导编译器进行精准优化,产出优化程序过程,根据收集性能数据方式,主要包含以下两种优化技术:

优化步骤:
FDO
1.插桩版本编译:首先编译特殊的插桩版本,这个用于采集性能数据
gcc test.c -o test_instrumented -fprofile-generate
2.数据采集:运行插桩版本的程序,程序退出后产出收集的数据test.gcda
./test_instrumented
3.编译优化:数据采集完成后,编译器基于该数据在编译器进行再次编译优化
gcc -O3 test.c -o test_fdo -fprofile-use=test.gcda
AutoFDO
1.数据采集:通过perf工具收集运行时的程序,产出性能数据perf.data
perf record -b -e br_inst_retired.near_taken:pp -- ./test
2.数据转换:结合程序,将perf.data性能数据,转换为函数信息,供后续编译器优化使用
create_gcov --binary=./test --profile=perf.data --gcov=test.gcov -gcov_version=1
3.编译优化:gcov数据准备好了,编译器基于此数据开展编译器的优化
gcc -O3 -fauto-profile=test.gcov test.c -o test_autofdo
优化效果:
通过测试程序,测试FDO和AutoFDO优化的处理性能,相对比O3基础上,FDO性能提升11.4%,AutoFDO性能提升11.5%,可以见反馈优化还能进一步提升可观的性能。

2.2 链接期
LTO
编译器在link阶段进行的优化,由于在编译尾部阶段,能够获取全部的object文件,这样可以以全局视角进行优化,进一步优化提升性能,目前主要有以下几种, GCC编译器 >=4.7, TinLTO Clang编译器

主要优化项:

优化效果:
通过测试程序,加入-flto优化,相对O3基础上,发现有8%左右性能提升

2.3 链接后
BOLT
Facebook最新开源的链接后的反馈优化技术, 基于LLVM基础框架开发,目前已合入llvm-project作为其一部分, 在其公司内部服务和大型C++程序Clang & GCC实践验证,采用反馈数据指导框架优化程序技术,执行程序bin + 反馈profile数据进行优化,优化产出新的bin,目前支持主要的X86-64 and AArch64 ELF程序格式。
主要特点:
-
对程序和GCC编译器版本要求低
-
采用perf收集性能数据,可在生产和测试环境生产优化数据,对服务影响低
-
一般的大型程序(40w+)优化速度快,实际优化过程平均4-5min,优于FDO/AutoFDO优化时长(15min+)
主要优化项:

优化步骤:
1.数据采集
通过perf工具采集程序运行时CPU LBR (branch information)事件,可通过采样频率和时间控制采集一定指令数(>=1B指令)的数据perf.data,供后续优化使用。
#非常驻服务
perf record -e cycles:u -j any,u -o perf.data -- ...
#常驻服务
perf record -F -e cycles:u -o perf.data -j any,u -a -p -- sleep
主要参数说明:
-F 采样频率
-o perf.data 输出采样文件
-p 程序进程pid
– sleep
2.数据转换
perf.data 采集好之后,使用bolt框架工具perf2bolt 进行优化数据格式转换
perf2bolt -p perf.data -o perf.fdata
3.优化处理
perf.fdata 优化数据准备好之后,使用bolt框架工具llvm-bolt 进行程序优化,产出.bolt程序
llvm-bolt -enable-bat=1 -o .bolt -data perf.fdata -align-macro-fusion=all -reorder-blocks=cache+ -reorder-functions=hfsort+ -split-functions=3 -split-all-cold -split-eh -dyno-stats -icf=1 -update-debug-sections
主要参数说明:
-enable-bat=1 支持bolt优化程序再次循环优化
-reorder-functions=hfsort+ 支持多种算法选择
-dyno-stats 指令优化统计输出
-update-debug-sections debug版本
优化效果:
Facebook数据中心服务,BOLT应用实现了高达7.0%的性能加速。开源的程序GCC和Clang编译器测试,评估表明,BOLT在FDO和LTO的基础上将程序的处理速度提高了20.4%,如果程序在构建时没有FDO和LTO,则速度将提高52.1%
通过测试程序对比,使用BOLT优化,对比O3优化提升18%性能。

三、整体技术架构方案
基于以上的编译优化技术,大规模C++系统上实践落地,面临一些问题&挑战。
-
接入成本:内部系统有大量微服务模块,代码版本和编译参数不一,开源技术至工程可实践问题,反馈优化技术数据如何收集和维护,如何高效支持复杂模块的低成本接入问题;
-
优化速度:业务迭代频繁, 如何在不影响变更上线效率前提下,保障优化效果,支持高效优化。
通过探索研究编译全流程相关的优化技术,设计通用的全流程优化解决方案,支持多种优化技术组合优化,目标实现优化效果最大化,满足多场景业务需求。
平台优化整体架构,见图1,主要包括用户接入,优化系统和数据系统,实现从业务接入至优化产出过程闭环处理,降低业务接入成本,提升优化效率。

△图____1 omax性能优化系统架构
3.1 用户接入
通过插件化方式接入后端优化服务,实现前端轻量级接入,后端复杂内部处理逻辑对业务透明,同时开放API方式兼顾其它场景接入。
3.1.1 流水线插件
百度内流水线式流程任务处理平台插件:基于现有流水线开放能力,开发优化接入插件,发布至公共插件中心供各业务线接入使用

△图____2 流水线pipeline接入优化插件
主要能力:
-
独立建设优化阶段:接入阶段见图2,作为流水线一个阶段插入,将所有的优化收敛到此阶段,整体支持灵活动态热插拔,功能开启和关闭可一键控制。
-
核心多产品优化机制:多产品概念,主要是这样一种开发和上线模式,基于同一套代码库,通过派生生成不同的配置,实现不同服务功能,广泛应用于不同的产品需求中,提升架构&代码能力复用。如何优化此类常见的迭代模式,设计基于流水线的多产品优化机制,用于一条流水线,兼容优化每个产品的产出,并保障各自的优化版本部署隔离控制。
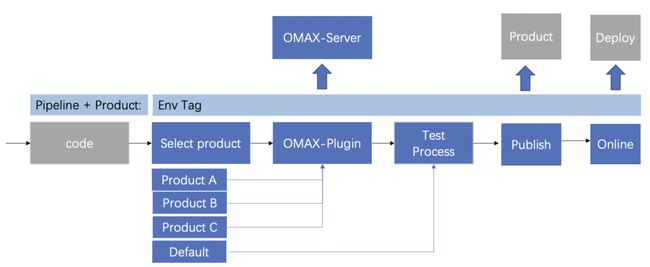
△图3 多产品优化机制
多产品机制见图3,主要由基于流水线任务处理的前端各插件,omax优化插件, 测试任务,发布插件,上线插件等,联动后端优化系统omax-server,上线系统,产品库等,通过唯一产品标识(流水线名+产品),串联该产品的优化,发布和上线相关处理流程。
1)产品选择阶段:通过列表方式选择,支持默认方式(提供选择不做优化),字段需要唯一,实践中我们以app上线模板名称为标识,后续阶段依赖此选择,做进一步串联处理。
2)优化插件处理阶段:插件将产品&流水线信息传递至后端服务,通过产品信息获取对应的优化数据,进行优化处理,并发布至产品库,返回发布地址至插件端生效,供后续测试和发布阶段处理。
3)测试&准入阶段:根据产品标识信息,选择相应的词表和测试策略,进行服务的功能、性能和稳定性测试。
4)发布阶段:设计防退化机制,该阶段将优化的唯一tag信息写入产品库产品的meta信息中,标记为优化版本,通过与上线平台tower制定校验规则,保障优化版本匹配上线,防止上线平台误选未优化或者其它产品版本上线,导致性能退化。
5)上线阶段:在流水线上线阶段,如果产品标识和上线模板匹配,不用再次选择上线模板,直接跳过选择模板过程发单上线,简化上线流程。
3.1.2 API接入
流水线之外,还提供原生的API接入,支持其它场景的接入需求,如编译和线下测试平台等,主要包含接口:触发任务的执行,查询当前任务状态,取消当前正在执行的任务等接口,通过HTTP方式,携带注册认证信息,与后端优化服务进行交互。
3.2 优化系统
优化系统作为服务提供者,支持优化的高效运转,主要从这几个方面来设计考虑:
-
动态弹性扩展:分布式任务调度运行框架设计,支持资源横向扩展,解决多任务处理负载问题,支持云上部署;
-
快速开发框架:通过设计分层的开发架构机制,将架构和业务功能解耦,业务开发支持python和shell等脚本语言方式,实现测试同学也能快速入手开发,降低开发门槛,提升对业务快速适配能力。
优化系统主要包含以下几个核心部分:
-
Webserver是OMax系统后端server的入口,主要功能是解析请求参数,并对一些参数配置进行DB (数据库)读取或写入操作,最后将包含Worker所需完整参数的请求转发给TaskManager。
-
TaskManager是一个分布式任务调度系统,支持多任务并行处理、动态横向扩缩容,通过webserver对外提供服务入口,TaskManager接收到webserver的请求后会分配一个Worker来处理具体业务;
-
Worker是具体业务的实际执行者,它由dispatcher和任务执行单元组成,dispatcher依据请求参数的不同,将不同请求分发到不同的任务执行单元上,任务执行单元支持横向或纵向扩展,可以快速接入新的业务需求,计划的任务执行单元有性能优化,发布,优化数据格式转换、监控和定时任务等。
3.3 数据系统
数据系统承担对所有优化任务的数据供给功能,数据的稳定,准确与否直接影响性能的优化情况,所有数据系统的设计上主要从数据准确性,产出能力,数据管理能力等方面考虑,开展相应的建设。
数据系统主要由采集端模块Sample、数据转换、数据管理等几部分构成。通过在实例粒度上部署采集Sample (非常驻进程,没有采集任务时不消耗任何资源),将采集到的数据传输到存储服务,远程采集的具体实例、采集周期以及采集时间点都由任务中控控制,并且支持不同服务的个性化配置,然后数据转换任务进行perf数据至profile优化数据格式转换,最终对数据打上版本信息,存储入库,供优化任务拉取处理。核心主要包括以下三部分:
-
数据采集:线上数据 + 线下数据(构造+引流),满足全方位的数据需求,支持多场景业务;
-
数据转换:实时+例行转换,兼顾性能、效率和资源消耗,覆盖全场景业务
-
数据管理:数据版本管理,支持数据按版本优化,同时满足异常时回滚需求,提升优化兼容能力。
3.4 系统报警监控机制
整个优化服务的平稳运行,离不开完善的监控报警机制,通过自身架构任务分发机制和处理能力,建设自闭环的监控机制,辅助机器人巡检能力,及时感知优化和数据的异常处理情况,方便运维及时进行相关的异常排查处理,保障系统稳定运行。主要从以下三个核心方面,保障优化系统的服务质量。
-
数据规模:例行的数据采集规模覆盖度监控任务,保障优化精度,天级汇总优化数据生产和优化处理运行情况,消息群和邮件通知;
-
指令数覆盖:优化规模指令数不足拦截机制;
-
任务异常:架构通过唯一ID标识任务运行标识,中间处理过程可追溯,异常时消息群和邮件及时通知。
四、关键技术
4.1 组合叠加优化
通过在优化的编译期,链接期和链接后三个阶段,各种采用相应的优化技术,综合叠加优化,实现最大化的优化效果,流水线主要优化过程见图4。

△图4 组合叠加优化
4.1.1 编译期
- 基础参数优化
工程实践:
1.优化参数选择:
O系列: 生产环境主要使用-O3优化,开发调试使用-Og方式,保障调试体验下具备一定的性能提升。
CPU指令集:通过cpu-z工具获取支持的CPU型号,可选择使用开启编译指令mmx, sse, avx的程序版本。
代码生成:静态库fno-pic,目前存在不少静态库依赖库使用fpic场景,进行编译适配,提升整体性能。
2.最大化优化效果:
大型服务主要由主模块+依赖模块构成,独立功能模块便于代码间复用,提升程序健壮性和开发效率,但是参数优化一般只在主模块配置,这样依赖模块不生效,影响整体优化效果。
通过联合编译平台,实现全局参数配置生效编译方式,将优化参数携带到所有模块参与编译,如GO3 开启全局03优化, 实现全模块优化效果。
- PGO反馈编译优化技术-FDO/AutoFDO
工程实践:
1.FDO
应用程序要求:目前随程序启动常驻线程较多,大多没有退出处理,有的主要通过_exit(0)等方式退出,由于优化数据产出依赖程序优雅退出,所以需要对程序启动的线程做退出处理。
编译器要求:建议GCC>=8.2以上,编译要求两次编译代码及其依赖版本保持一致。
2.AutoFDO
应用程序要求:实际大型程序编译,涉及依赖模块众多,有的以编译好的.a或so形式引入,这样参与编译优化时,存在一些编译优化失败,建议尽量源码形式参与编译,提升优化覆盖面,减少异常编译优化错误。
编译器要求:建议GCC>=8.2以上。
4.1.2 链接期
LTO
工程实践:
应用程序要求:接入简单,编译时添加链接参数-flto参数即可,针对FDO编译添加"-fprofile-correction"选项纠正多线程收集的数据一致性问题;
编译器要求:建议GCC>=8.2以上,相对gcc ld链接器,提升优化速度可使用llvm的lld link器替换。
4.1.3 链接后
BOLT
工程实践
1. 应用适配:对于GCC8 添加编译参数 -freorder-blocks-and-partition,对依赖模块尽量要求以源码方式参与编译,如果存在对应库优化失败,通过添加编译参数重新编译即可。
2. 开源BOLT工具深度优化改造:从开源至实践面临一些可用性和易用性问题,我们通过研究框架,开展深入改造,以满足工程实践要求,主要包括以下核心方面。
-
支持>=10G以上优化数据处理,提升对海量数据的适配,满足大量规模服务数据优化需求
-
优化对perf采集的大数据量>=5G+ 至优化profile数据格式解析,并行化改造处理,提升优化速度
-
完善关键优化路径调试信息,方便快速调试和定位优化失败问题,解决依赖兼容高效定位问题
3. 线上环境数据采集适配
- perf对采集CPU硬件事件支持,通过机器生效以下配置,支持主要的lbr事件采集
1.修改不重启机器,立即生效:
echo -1 > /proc/sys/kernel/perf_event_paranoid
2.设置永久生效(防止机器重启失效)
/etc/sysctl.conf
kernel.perf_event_paranoid = -1
3.提升软限大小设置
/etc/security/limits.conf
*soft nofile 65535
*hard nofile 65535
- 规模数据采集验证
统计机器CPU型号,按照类型收集采样数据,测试不同型号和及其合并后,采样数据和热点函数对应情况
4.2 异步+同步优化模式
异步优化, 兼容性能和优化速度,提升实践落地可用性,满足大部分业务高频迭代场景的需求, 见图5,主要包含以下几个部分:
-
解耦反馈优化数据产出和优化过程使用,优化和数据准备独立开展,通过数据引用关联,提升优化速度(40min->5min)
-
线上生产环境+规模批量收集数据,提升优化的准确性,解决采样概率上的丢失和覆盖不足问题,提升优化效果
-
优化数据定时和例行同步生产,不断接近同步优化的效果,提升优化效果
此外流水线场景下,还支持同步优化,并给异步贡献优化数据,满足实践中实时优化的需求,追求最大优化

△图5 omax高效性能优化模式
4.3 快速上线
在取得最大性能优化的同时,还可以通过release和debug优化模式,优化缩减程序bin体积大小,提升上线时候部署速度,通过建立快速上线机制,实现业务快速接入,见图6。
-
omax后台优化服务,扩展支持两种release和debug版本优化产出,优化缩减体积大小,同时支持异常core时debug信息查看;
-
支持通用的strip裁剪模式,实现普通未使用优化服务,也都可接入使用快速上线能力;
-
release和debug版本建立版本映射,线上服务使用release,查core拉取对应debug版本解析。
主要处理过程:
快速上线:上线发布产出时,支持同时产出debug和release版本,两者建立映射关系,通过release优化发布包中添加debug-meta的信息,用于线上异常core时,拉取debug版本, 使用gdb查看堆栈和函数信息。
一键debug:提供debug版本快捷拉取机制,由于debug版本体积较大,对于线上场景成功拉取后,根据登录和超时状态,实现debug文件自动清理退场,保障线上环境安全。

△图6 快速上线和简化查core机制
4.4 性能数据仓库
基于线上性能采集数据通路和反馈数据技术使用到的profile性能数据,建立长期可记录、可追踪的性能退化分析数据仓库,见图7,用于进一步性能优化分析,指导代码改进优化,主要包含以下部分。
-
perf性能优化数据热点分析,指导代码层面的分析优化;
-
程序调用cpu火焰图&指令miss数据,用于发现和优化程序热点调用函数栈问题
-
mem指令miss数据,用于分析内存性能问题。

△图7 线上服务性能数据仓库机制
五、落地&收益情况
目前该平台在百度核心推荐系统全面落地,覆盖推荐系统所有主要模块,优化云上微服务容器数万级以上,实现CPU优化10%+,时延降低5%+,上线速度提升40%+,发布包大小减少10倍+,服务运行稳定,性能收益持续,有力支撑服务大量的优化需求,降本增效,支撑业务高速发展。
作为后续,本项目也在不断探索大规模C++服务开发的最佳实践,也欢迎志同道合者共同探讨。
六、参考资料
【1】Maksim Panchenko, Rafael Auler, Bill Nell, Guilherme Ottoni. BOLT: A Practical Binary Optimizerfor Data Centers and Beyond. Facebook, Inc.
【2】Dehao Chen,David Xinliang Li,Tipp Moseley. AutoFDO: Automatic Feedback-DirectedOptimization for Warehouse-Scale Applications. Google Inc.
【3】https://github.com/facebookincubator/BOLT/tree/main/bolt
【4】https://github.com/google/autofdo
【5】https://github.com/VictorRodriguez/autofdo_tutorial
【6】https://gcc.gnu.org/wiki/AutoFDO/Tutorial
【7】https://clang.llvm.org/docs/ThinLTO.html#introduction
【8】https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
推荐阅读:
移动端异构运算技术-GPU OpenCL 编程(基础篇)
云原生赋能开发测试
基于Saga的分布式事务调度落地
Spark离线开发框架设计与实现
爱番番微前端框架落地实践