计算梯度:网络的前向与反向传播 和 优化方法:更新模型参数的方法
我们一同学习了损失函数的概念以及一些常用的损失函数。你还记得我们当时说的么:模型有了损失函数,才能够进行学习。那么问题来了,模型是如何通过损失函数进行学习的呢?
在接下来,我们将会学习前馈网络、导数与链式法则、反向传播、优化方法等内容,掌握了这些内容,我们就可以将模型学习的过程串起来作为一个整体,彻底搞清楚怎样通过损失函数训练模型。
下面我们先来看看最简单的前馈网络。
前馈网络
前馈网络,也称为前馈神经网络。顾名思义,是一种“往前走”的神经网络。它是最简单的神经网络,其典型特征是一个单向的多层结构。简化的结构如下图:
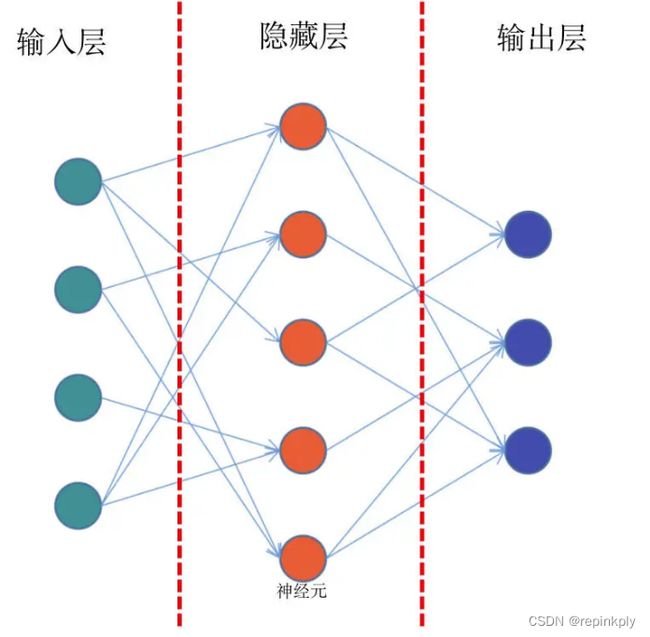
结合上面的示意图,我带你具体看看前馈网络的结构。这个图中,你会看到最左侧的绿色的一个个神经元,它们相当于第 0 层,一般适用于接收输入数据的层,所以我们把它们叫做输入层。
比如我们要训练一个 y=f(x) 函数的神经网络,x 作为一个向量,就需要通过这个绿色的输入层进入模型。那么在这个网络中,输入层有 5 个神经元,这意味着它可以接收一个 5 维长度的向量。
结合图解,我们继续往下看,网络的中间有一层红色的神经元,它们相当于模型的“内部”,一般来说对外不可见,或者使用者并不关心的非结果部分,我们称之为隐藏层。在实际的网络模型中,隐藏层会有非常多的层数,它们是网络最为关键的内部核心,也是模型能够学习知识的关键部分。
在图的右侧,蓝色的神经元是网络的最后一层。模型内部计算完成之后,就需要通过这一层输出到外部,所以也叫做输出层。
需要说明的是,神经元之间的连线,表示神经元之间连接的权重,通过权重就会知道网络中每个节点的重要程度。
那么现在我们回头再来看看前馈神经网络这个名字,是不是就很好理解了。在前馈网络中,数据从输入层进入到隐藏层的第一层,然后传播到第二层,第三层……一直到最后通过输出层输出。数据的传播是单向的,无法后退,只能前行。
反向传播
反向传播算法(Backpropagation)是目前训练神经网络最常用且最有效的算法。模型就是通过反向传播的方式来不断更新自身的参数,从而实现了“学习”知识的过程。
反向传播的主要原理是:
前向传播:数据从输入层经过隐藏层最后输出,其过程和之前讲过的前馈网络基本一致。计算误差并传播:计算模型输出结果和真实结果之间的误差,并将这种误差通过某种方式反向传播,即从输出层向隐藏层传递并最后到达输入层。
迭代:在反向传播的过程中,根据误差不断地调整模型的参数值,并不断地迭代前面两个步骤,直到达到模型结束训练的条件。
其中最重要的环节有两个:一是通过某种方式反向传播;二是根据误差不断地调整模型的参数值。
这两个环节,我们统称为优化方法,一般而言,多采用梯度下降的方法。这里就要使用到导数、梯度和链式法则相关的知识点,梯度下降我们将在下节课详细展开。
反向传播的数学推导以及证明过程是非常复杂的,在实际的研发过程中反向传播的过程已经被 PyTorch、TensorFlow 等深度学习框架进行了完善的封装,所以我们不需要手动去写这个过程。不过作为深度学习的研发人员,你还是需要深入了解这个过程的运转方式,这样才能搞清楚深度学习中模型具体是如何学习的。
上面我们共同了解了前馈网络、导数、梯度、反向传播等概念。但是距离真正完全了解神经网络的学习过程,我们还差一个重要的环节,那就是优化方法。只有搞懂了优化方法,才能做到真的明白反向传播的具体过程。
我们就来学习一下优化方法,为了让你建立更深入的理解,后面我还特意为你准备了一个例子,把这三节课的所有内容串联起来。
用下山路线规划理解优化方法
深度学习,其实包括了三个最重要的核心过程:模型表示、方法评估、优化方法。我们上节课学习的内容,都是为了优化方法做铺垫。
优化方法,指的是一个过程,这个过程的目的就是,寻找模型在所有可能性中达到评估效果指标最好的那一个。我们举个例子,对于函数 f(x),它包含了一组参数。
这个例子中,优化方法的目的就是找到能够使得 f(x) 的值达到最小值对应的权重。换句话说,优化过程就是找到一个状态,这个状态能够让模型的损失函数最小,而这个状态就是模型的权重。
常见的优化方法种类非常多,常见的有梯度下降法、牛顿法、拟牛顿法等,涉及的数学知识也更是不可胜数。同样的,PyTorch 也将优化方法进行了封装,我们在实际开发中直接使用即可,节省了大量的时间和劳动。
不过,为了更好地理解深度学习特别是反向传播的过程,我们还是有必要对一些重要的优化方法进行了解。我们这节课要学习的梯度下降法,也是深度学习中使用最为广泛的优化方法。
梯度下降其实很好理解,我给你举一个生活化的例子。假期你跟朋友去爬山,到了山顶之后忽然想上厕所,需要尽快到达半山腰的卫生间,这时候你就需要规划路线,该怎么规划呢?
在不考虑生命危险的情况下,那自然是怎么快怎么走了,能跳崖我们绝不走平路,也就是说:越陡峭的地方,就越有可能快速到达目的地。
所以,我们就有了一个送命方案:每走几步,就改变方向,这个方向就是朝着当前最陡峭的方向,即坡度下降最快的方向行走,并不断重复这个过程。这就是梯度下降的最直观的表示了。
在上节课中我们曾说过:梯度向量的方向即为函数值增长最快的方向,梯度的反方向则是函数减小最快的方向。
梯度下降,就是梯度在深度学习中最重要的用途了。下面我们用相对严谨的方式来表述梯度下降。
在一个多维空间中,对于任何一个曲面,我们都能够找到一个跟它相切的超平面。这个超平面上会有无数个方向(想想这是为什么?),但是这所有的方向中,肯定有一个方向是能够使函数下降最快的方向,这个方向就是梯度的反方向。每次优化的目标就是沿着这个最快下降的方向进行,就叫做梯度下降。
具体来说,在一个三维空间曲线中,任何一点我们都能找到一个与之相切的平面(更高维则是超平面),这个平面上就会有无穷多个方向,但是只有一个使曲线函数下降最快的梯度。再次叨叨一遍:每次优化就沿着梯度的反方向进行,就叫做梯度下降。使什么函数下降最快呢?答案就是损失函数。
这下你应该将几个知识点串联起来了吧:为了得到最小的损失函数,我们要用梯度下降的方法使其达到最小值。这两节课的最终目的,就是让你牢牢记住这句话。
我们继续回到刚才的例子。

图中红色的线路,是一个看上去还不错的上厕所的路线。但是我们发现,还有别的路线可选。不过,下山就算是不要命地跑,也得讲究方法。