如何估算集群所需的存储、计算资源?

编 辑:彭文华
来 源:大数据架构师(ID:bigdata_arch)
彭友们好,我是你的老彭友。最近有位朋友在群里问:怎么预估大数据集群所需的内存容量?

这个问题是大数据架构师的高频面试题,但是更关键的是在项目中更是必备的技能。因为这会涉及到服务器的选择和成本核算。
因此必须既能满足现有的需求,又不能超过,还能保证持续、稳定的使用。虽然现在有云服务器,随时可以扩容,但提需求的时候总得说一个依据,否则显得非常不专业。
今天就给大家彻底解决这个问题,文末有模板下载。

资源预估内容
虽然彭友问的是怎么估算内存的资源,但是咱得扩展一下。作为架构师/项目经理,面临的问题是一个项目要启动,我们需要申请多少资源才能满足项目需求?

如果是要解决这个问题,那么最少要从网络资源、存储、内存、CPU四个方面进行预估。
服务器资源评估的交付物是一个类似的服务器需求单:
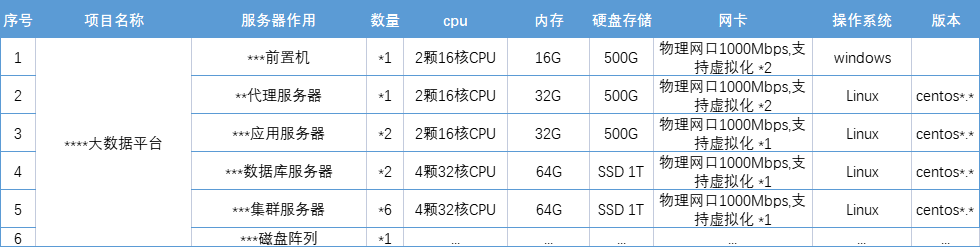
一般的时候我们评估资源有几个方法:
1、经验预估:大佬专属,看一眼需求就知道得分配多少资源;
2、参考预估:根据以前差不多项目的经验,对照参考预估;
3、技术预估:根据技术参数要求,进行细致的计算后得出。
第1、2种方法在这就不讲了,一个要牛人,一个要类似项目。这个也没法跟彭友们说呀~~~

资源预估方法论
其实就是一些预估的原则,框定大致的范围,这样也比较科学。我简单总结了几个原则,供你参考:

1、最小可用原则:就是不要胡乱拍脑袋。很多人为了免责,参数就得往高了报,造成极大的资源浪费;
2、高可靠高可用原则:访问是有波峰波谷的,我们必须要确保集群在日常正常工作的同时,能抗住波峰的流量,一般来说,波峰波谷的时间占比大概都是28分布;应用服务器也得考虑单节点故障问题;
3、可扩展原则:需要考虑集群扩展的场景,因此类似用途的服务器尽量要用相同规格;
4、便于运维:需要结合团队的实力、技能等情况综合考虑,更多的是人为的因素。
一般来说,我们需要综合考虑需求项目的所有技术参数、技术选型,综合进行规划。要画出网络拓扑图,规划每台服务器的用途,根据用途、访问需求、数据存量增量综合预估。
但是网络拓扑这个不在今天的讨论范围内,所以就略过了;技术选型情况比较多,也无法一一遍历,所以只能给一个普适性的评估方法。
彭友们在评估的时候,根据技术进行调整就行了。比如离线和实时服务器所需的资源就不一样了,离线偏重存储,实时偏重计算。

网络资源预估
网络预估的指标是TPS(Transactions Per Second 每秒处理事务数量)和QPS(Query Per Second 每秒查询数量)。大家说的吞吐量就是通过这两个指标来衡量的。
这里有一个简单的公式:
公式1:QPS = 设计并发数/平均响应时间
系统设定的同一时间并发用户访问的数量,以及系统的响应效率,决定了QPS。
现在有些项目中直接就确定了QPS、并发数、平均响应时间三个技术指标,这时候就不用算了,直接照着这个做就行。
但是也有其他情况,比如IoT的数据,这个非常规律,要么是24小时非常稳定的,要么就是非常有节奏,工作时间稳定,工作时间之外就停了;
还有互联网的情况,就比较乱了,分布的即为不均匀。基本上是早、中、晚三个高峰,要么是上午、下午、晚上三个高峰。这跟网站、APP的性质不一样而各异。
这时候我们设定一个估算方法就行了。比如按下面这个公式:
公式2:波峰QPS=(全天数据查询量*波峰数据量占比)/(每天3600秒*波峰时间)
![]()
上面的参数可以自己调整,也可以再加几个其他合理的参数就行了。大概的意思就是根据全天的数据接入需求,设定合理的假设,比如80%的数据都在20%波峰时间涌入,这样就能算出波峰QPS了。
一般情况我习惯给出三个方案:
1、高配:即抗住波峰*30%,留出余量;
2、中配:抗住波峰即可;
3、低配:抗住80%波峰;
这时候会根据系统的需求进行选择,或者参考用来进行工作量评估的三点估算法推算出一个最可能的值作为参考。
期望值:Te=(P+4M+O)/6
即:最可能的值Te=(1份最差的结果(峰值最高)+4份波峰+1份小波峰)/6
当然,上面只是参考而已,需要根据实际情况进行调整。比如有些系统实时性不是特别高,选低配就行了,没及时处理的,等波峰过了之后慢慢处理都行;
有些用户实时性要求高、敏感度高的,那就选中高配,确保波峰能过去。同时启动热点监测,跟技术的朋友一起做一个弹性扩容,确保波峰再大,都能实施扩容,确保高可靠搞可用。
我们有几个方法可以知道波峰:
1、根据设计的每天数据接入量,计算波峰QPS(公式1);
2、根据历史数据推算波峰QPS(把历史QPS拉出来看看就知道了);
3、根据并发数和平均响应时间计算QPS(公式2)。
平均响应时间可以用测试的方式得到,各种自动化测试工具都能搞定。非常简单,输入并发数,然后跑一下就能得到不同并发数下的平均响应时间。
一般来说,现在的网卡带宽都很大,费用也不贵,基本上选个千兆、万兆网卡就没问题了,有些人就说计算QPS没啥用。
但是老彭仍然建议算好QPS,因为这是后面存储、计算的根据之一。

存储估算
存储估算分两部分:
1、存量部分;
存量部分还是比较好算的,就是得统计一下各系统的数据量就行了,最多加一个接入计划。
另外,存量数据也需要分成冷热数据,有条件的话,热数据放在SSD等高速存储里;冷数据可以扔到OSS、SAS机械硬盘,或者压缩一下,减少存储成本。如果有数据退役的管理,那么可以根据退役流程进行转录到磁带机或者直接销毁。
2、增量部分,这个需要考虑几个事情,第一个是应用系统的接入,在统计存量数据的时候顺便调研一下就好了;第二个是IoT、日志等数据源的接入。这时候就得根据QPS计算了。
一般来说,每个QPS或者IoT的数据量是相对比较恒定的,为了方便计算,我们假定是每条数据10kb。
那么每天的数据量就是:
![]()
10KB*10000000条*3个备份=288GB
上面的几个参数都可以进行调整,比如每条数据的大小可能根本不用10kb,备份也不用3个,2个就行了等等。如果是流式数据,还要加一个保留数据的时间参数,比如保留最近3天的数据,就再*3就行了。
这个时候就可以计算集群中每台服务器的存储要求了。比如我们计算出来存量10000G,日增量100G,集群中datanode一共10台,那么每台1T(1024G)就只能刚刚够放存量的。
而每台2T,则可以用(10台*2048G-10000G)/100G=104天。我们按照需求进行规划、调整即可。如果是云服务器,可以整个半年的量,实时监测,提前增量即可;如果是物理服务器,可以增设磁盘阵列,也可以满足需求。
我们监测的时候设一根报警线就行,一般来说,存储的预警值是80%,预留20%空间,及时扩容即可。

内存及CPU估算
这个得完全根据技术方案来。离线和实时不一样,增量和全量也不一样,ETL、预计算、跑模型都不一样。
有些要把大量数据放内存里,非常吃内存,有些要开N个线程,疯狂吃CPU。比如ClickHouse相对来说就比较吃CPU,对CPU的要求就要高一些。
这里举几个例子:
Kafka内存预估:

假设我们只有10个Topic,每个Topic有5个Partition,但是需要存3个副本,有3台kafka服务器,常驻内存只要最近的30%,那么:
(10Topic*5Partition*3副本*1G文件*0.3内存)/3台服务器=15G。我们选择16G很危险,建议选用32G内存即可。
Flink内存预估:

假设我们QPS1000次/秒,Flink窗口设为5分钟,每条数据10KB,那么可得出所需内存为3GB。
离线计算内存预估

假设我们有10T的全量数据,每天增100G,离线数据其实不会一次性把所有数据入内存计算,所以比例会少很多。按这个计算,我们所需的内存是:
(10T+100G)*0.02入内存占比/6台服务器,每台服务器需要34GB的内存,这个很尴尬,要么加几台服务器,要么选64G的内存,要么降低我们入驻内存的比率,或者通过合理的流程削峰填谷。
至于CPU的预估,一般按照CPU:内存1:2、1:4(推荐)的比例直接算出来就行了。
64G的内存,选择16core就够了。除非是ClickHouse或者开N个线程的特别吃CPU的组件,可以放大一些,按1:2比例,选32core的。
以上是单独预估的。但是作为架构师,需要全盘考虑。存储的还得考虑NameNode和DataNode的区别,ZooKeeper等管理组件和其他组件共用服务器的情况,实时、离线任务一起跑的情况、热点应对等各类情况,这就不再细说了。
扩展阅读:公众号“大数据架构师”后台回复“资源预估”即可下载【服务器资源申请单模板、QPS、存储、内存、CPU预估公式.xlxs】。

更多精彩:
一口气说透中台--给你架构师的视角
到底什么是大数据架构?????
架构图到底怎么画?老彭带你走一波!
【附下载】实时数仓架构设计与选型
一口气说穿数据中台-给你架构师的视角
![]()
排版 | 老彭
审校 | 老彭 主编 | 老彭