python笔记—>网页爬虫
目录
一、了解网页结构
1、网页源代码
1、查看网页源代码以百度为例
2、解读网页源代码
二、requests模块使用方法
1、获取静态网页源代码
2、获取动态加载的数据
1、以豆瓣排行榜为例
2、爬取排行榜数据
一、了解网页结构
1、网页源代码
1、查看网页源代码以百度为例

按快捷键f12
 然后点击
然后点击
然后点击网页上任意位置
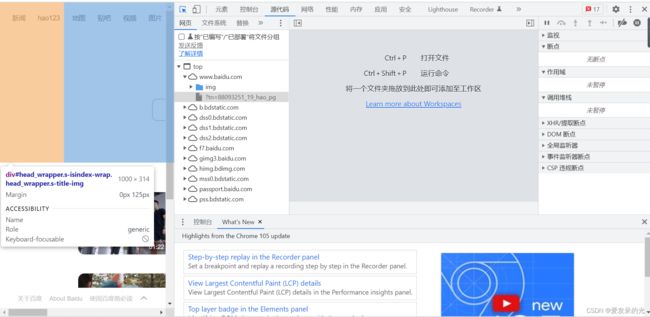 即可弹出网页源代码
即可弹出网页源代码
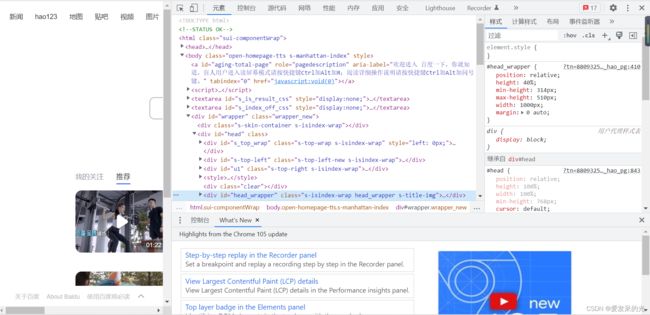
2、解读网页源代码
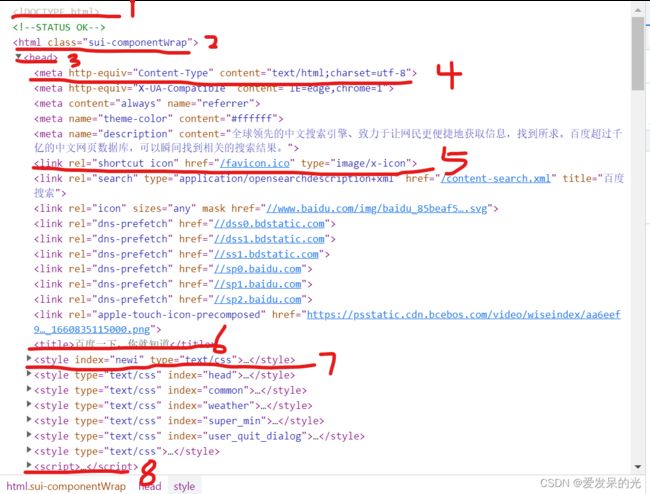
1、 用来告知 Web 浏览器页面使用了哪种 HTML 版本。
2、定义一个 HTML 文档。
3、
定义关于文档的信息。4、定义关于 HTML 文档的元信息。
5、定义文档与外部资源的关系。
6、
©2017 Baidu 使ç¨ç¾åº¦åå¿è¯» æè§åé¦ äº¬ICPè¯030173å· 
2、获取动态加载的数据
1、以豆瓣排行榜为例
豆瓣电影分类排行榜 - 剧情片
按f12后按f5刷新并点击Fectch/XHR
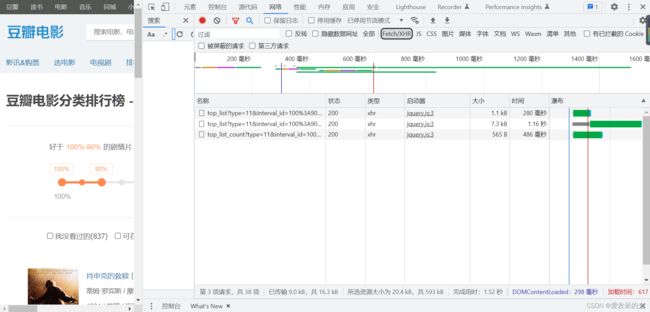
然后点击第二条
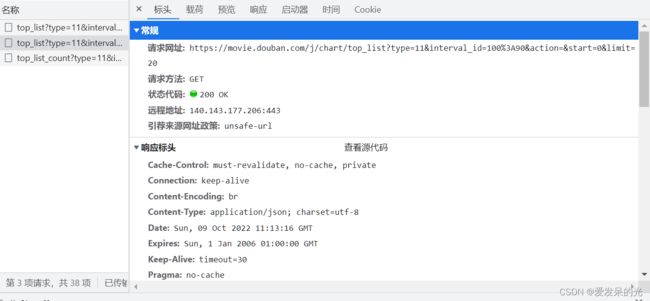
获取url为 'https://movie.douban.com/j/chart/top_list'
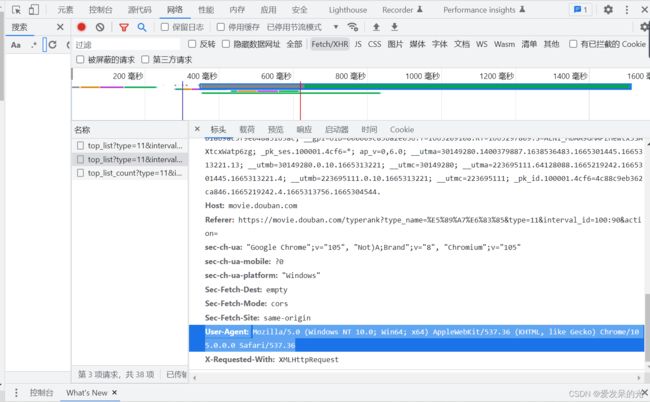
下拉找到user-Argent
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
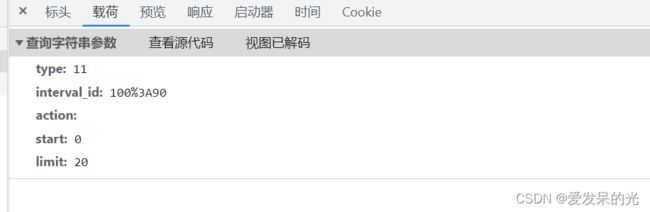
获取params数据
type=11&interval_id=100%3A90&action=&start=0&limit=20
完整代码如下
import requests
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
url='https://movie.douban.com/j/chart/top_list'
params={'type':'11','interval_id':'100:90','start':'0','limit':'1'}
response=requests.get(url,headers=headers,params=params)
print(response.json())[{'rating': ['9.7', '50'], 'rank': 1, 'cover_url': 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg', 'is_playable': True, 'id': '1292052', 'types': ['犯罪', '剧情'], 'regions': ['美国'], 'title': '肖申克的救赎', 'url': 'https://movie.douban.com/subject/1292052/', 'release_date': '1994-09-10', 'actor_count': 25, 'vote_count': 2710318, 'score': '9.7', 'actors': ['蒂姆·罗宾斯', '摩根·弗里曼', '鲍勃·冈顿', '威廉姆·赛德勒', '克兰西·布朗', '吉尔·贝罗斯', '马克·罗斯顿', '詹姆斯·惠特摩', '杰弗里·德曼', '拉里·布兰登伯格', '尼尔·吉恩托利', '布赖恩·利比', '大卫·普罗瓦尔', '约瑟夫·劳格诺', '祖德·塞克利拉', '保罗·麦克兰尼', '芮妮·布莱恩', '阿方索·弗里曼', 'V·J·福斯特', '弗兰克·梅德拉诺', '马克·迈尔斯', '尼尔·萨默斯', '耐德·巴拉米', '布赖恩·戴拉特', '唐·麦克马纳斯'], 'is_watched': False}]
2、爬取排行榜数据
import requests
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
url='https://movie.douban.com/j/chart/top_list'
params={'type':'11','interval_id':'100:90','start':'0','limit':'20'}
response=requests.get(url,headers=headers,params=params)
content=response.json()
for i in content:
title=i['title']
score=i['score']
print(title,':',score)肖申克的救赎 : 9.7
霸王别姬 : 9.6
美丽人生 : 9.6
辛德勒的名单 : 9.6
控方证人 : 9.6
阿甘正传 : 9.5
这个杀手不太冷 : 9.4
千与千寻 : 9.4
泰坦尼克号 : 9.4
盗梦空间 : 9.4
星际穿越 : 9.4
忠犬八公的故事 : 9.4
大闹天宫 : 9.4
十二怒汉 : 9.4
无间道 : 9.3
海上钢琴师 : 9.3
楚门的世界 : 9.3
末代皇帝 : 9.3
活着 : 9.3
放牛班的春天 : 9.3