【可解释机器学习】15分钟带你了解6种可解释性机器学习框架
5分钟带你了解6种可解释性机器学习框架
- 1. 举个例子:树模型的解释性
- 2. 6种可解释性框架
-
- 2.1 SHAP
- 2.2 LIME
- 2.3 Shapash
- 2.4 InterpretML
- 2.5 ELI5
- 2.6 OmniXAI
- 参考资料
随着人工智能的发展,为了解决具有挑战性的问题,人们建立一个AI模型,输入数据,然后再输出结果。这样的AI模型越来越复杂、越来越不透明,就像一个黑匣子,能自己做出决定,但是人们并不清楚其中缘由。因此我们需要了解AI如何得出某个结论背后的原因,而不是仅仅接受一个在没有上下文或解释的情况下输出的结果。
可解释性旨在帮助人们理解:AI模型是如何学习的?在训练过程中它学到了什么?为什么这个AI模型针对一个特定输入会做出如此决策?以及这个决策是否可靠?
1. 举个例子:树模型的解释性
集成学习树模型因为其强大的非线性能力及解释性,在表格类数据挖掘等任务中应用频繁且表现优异。模型解释性对于某些领域(如金融风控)是极为看重的,对于树模型的解释性,常常可以通过输出树模型的结构或使用shap等解释性框架的方法:
- 使用Graphviz输出树结构
这里需要先安装graphviz。使用graphviz输出树结构的代码如下:
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files/Graphviz/bin/' # 安装路径
for k in range(n_estimators): # 遍历n_estimators棵树的结构
ax = lightgbm.plot_tree(lgb, tree_index=k, figsize=(30,20), show_info=['split_gain','internal_value','internal_count','internal_weight','leaf_count','leaf_weight','data_percentage'])
plt.show()

输出树的决策路径是很直接的方法,但对于大规模(树的数目>3基本就比较复杂了)的集成树模型来说,决策太过于复杂了,最终决策要每棵树累加起来,难以理解。
- 使用shap解释性框架
SHAP基于Shapley值,Shapley值是经济学家Lloyd Shapley提出的博弈论概念。它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。如下所示的几行代码就可以展示该模型的变量对于决策的影响,以Insterest历史利率为例,利率特征值越高(蓝色为低,红色为高),对应shap值越高,说明决策结果越趋近1。
安装shap:
pip install shap
SHAP代码示例:
import shap
explainer = shap.TreeExplainer(lgb)
shap_values = explainer.shap_values(pd.concat([train_x,test_x]))
shap.summary_plot(shap_values[1], pd.concat([train_x,test_x]),max_display=5,plot_size=(5,5)) # 特征重要性可视化
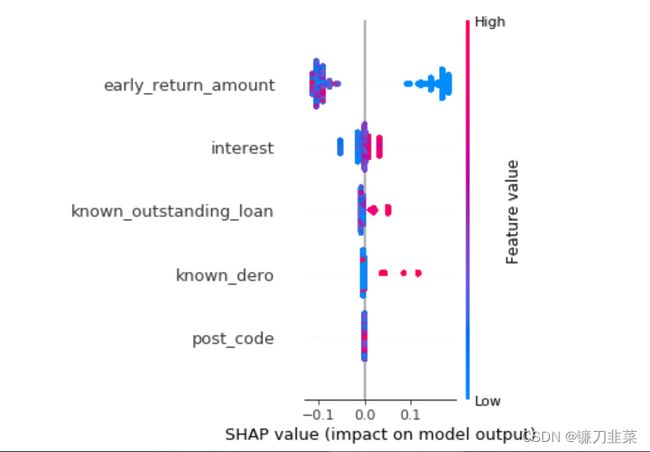
2. 6种可解释性框架
2.1 SHAP
SHapley Additive explanation (SHAP)是一种解释任何机器学习模型输出的博弈论方法。它利用博弈论中的经典Shapley值及其相关扩展将最优信贷分配与局部解释联系起来。以前写过一篇文章,用过SHAP这个库。数据集中每个特征对模型预测的贡献由Shapley值解释。
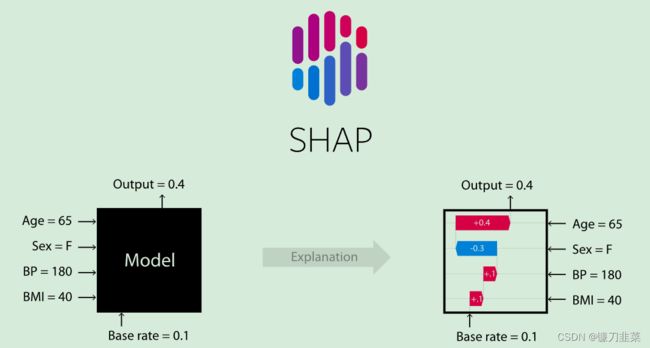
使用XGBoost的预测Boston房价的案例:
import xgboost
import shap
import pandas as pd
import numpy as np
# train an XGBoost model
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
y = raw_df.values[1::2, 2]
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])

上面的解释显示,每个特征都有促进模型输出从基本值(我们传递的训练数据集的平均模型输出)推向模型输出的功能。推动预测更高的功能以红色显示,较低预测的人以蓝色为蓝色。可视化相同解释的另一种方法是使用force plot:
# visualize the first prediction's explanation with a force plot
shap.initjs()
shap.plots.force(shap_values[0])

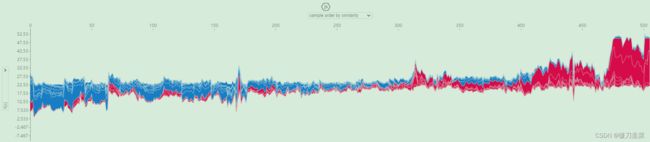
如果我们采用许多力图解释,例如上面所示的解释,将它们旋转90度,然后水平堆叠,我们可以看到整个数据集的解释(在笔记本中,此图是互动的):
# visualize all the training set predictions
shap.initjs()
shap.plots.force(shap_values)
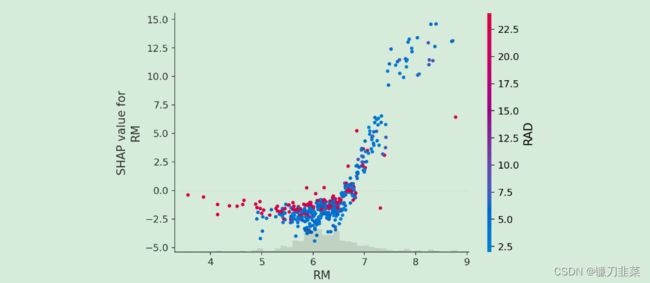
为了了解单个特征如何影响模型的输出,我们可以绘制该特征的SHAP value vs数据集中所有示例的feature的SHAP value。由于 SHAP 值代表feature对模型输出变化的贡献,因此下面的图表代表预测房价随 RM (一个地区每个房子的平均房间数)变化的变化。单个RM值的垂直扩散表示与其他特征的相互作用效应。为了帮助揭示这些交互,我们可以通过另一个feature进行着色。如果我们将整个解释张量传递给color参数,则散点图将选择最佳feature。在这种情况下,它选择了RAD(通往放射状高速公路的可达性指数),因为这突出表明,对于RAD值高的地区,平均每间房屋的房间数量对房价的影响较小。
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap.initjs()
shap.plots.scatter(shap_values[:,"RM"], color=shap_values)
为了了解哪些feature对模型最重要,我们可以为每个样本绘制每个特征的SHAP值。下图根据所有样本的SHAP值大小之和对特征进行排序,并使用SHAP值来显示每个特征对模型输出的影响分布。该颜色表示特征值(红色高,蓝色低)。例如,这表明高LSTAT(人口地位较低%)会降低预测房价。
# summarize the effects of all the features
shap.plots.beeswarm(shap_values)

我们也可以只取每个特征的SHAP值的平均绝对值来获得标准条形图(为多类输出生成堆叠条形图):
shap.plots.bar(shap_values)

2.2 LIME
在可解释性领域,最早出名的方法之一是LIME。它可以帮助解释机器学习模型正在学习什么以及为什么他们以某种方式预测。Lime目前支持对表格的数据,文本分类器和图像分类器的解释。
知道为什么模型会以这种方式进行预测对于调整算法是至关重要的。借助LIME的解释,能够理解为什么模型以这种方式运行。如果模型没有按照计划运行,那么很可能在数据准备阶段就犯了错误。

使用pip安装LIME:
pip install lime
2.3 Shapash
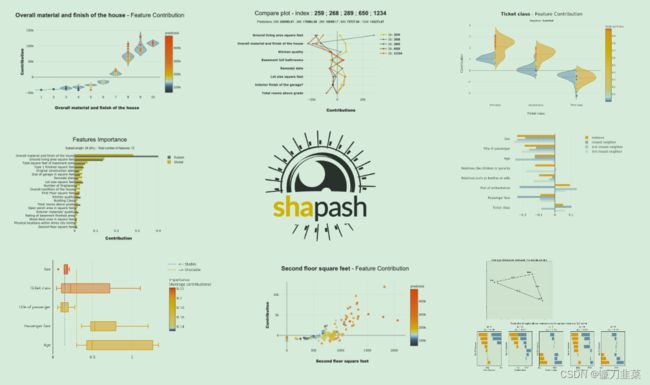
“Shapash是一个使机器学习对每个人都可以进行解释和理解Python库。Shapash提供了几种类型的可视化,显示了每个人都能理解的明确标签。数据科学家可以更轻松地理解他们的模型并分享结果。最终用户可以使用最标准的摘要来理解模型是如何做出判断的。”
Shapash库可以生成交互式仪表盘,并收集了许多可视化图表。与SHAP/LIME解释性有关。它可以使用SHAP/Lime作为后端,也就是说它只提供了更好看的图表。

使用Shapash库创建的交互式仪表板:
2.4 InterpretML
InterpretML是一个开源的Python包,它向研究人员提供机器学习可解释性算法。InterpretML支持训练可解释模型(glassbox),以及解释现有的ML管道(blackbox)。
InterpretML展示了两种类型的可解释性:glassbox模型——为可解释性设计的机器学习模型(如:线性模型、规则列表、广义可加模型)和blackbox可解释性技术——用于解释现有系统(如:部分依赖,LIME)。

使用统一的API并封装多种方法,拥有内置的、可扩展的可视化平台,该包使研究人员能够轻松地比较可解释性算法。InterpretML还包括了explanation Boosting Machine的第一个实现,这是一个强大的、可解释的、glassbox模型,可以像许多黑箱模型一样精确。
一个Glassbox Module例子,首先加载数据:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data",
header=None)
df.columns = [
"Age", "WorkClass", "fnlwgt", "Education", "EducationNum",
"MaritalStatus", "Occupation", "Relationship", "Race", "Gender",
"CapitalGain", "CapitalLoss", "HoursPerWeek", "NativeCountry", "Income"
]
train_cols = df.columns[0:-1]
label = df.columns[-1]
X = df[train_cols]
y = df[label]
seed = 42
np.random.seed(seed)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=seed)
然后,训练一个Glassbox模型。Glassbox模型被设计成完全可解释的,并且经常提供与最先进的方法相似的精确度。InterpretML允许使用scikit学习界面来训练许多最新的glassbox模型。
from interpret.glassbox import ExplainableBoostingClassifier
ebm = ExplainableBoostingClassifier()
ebm.fit(X_train, y_train)

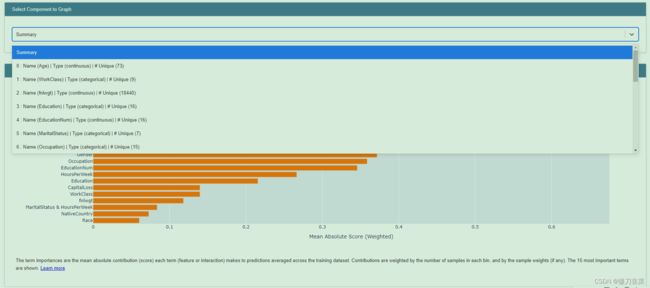
第三,对Glassbox进行解释。Glassbox模型可以在全局(整体行为)和局部(个体预测)两个层面上提供解释。
全局解释(Global explanations)有助于理解模型认为什么是重要的,以及识别其决策中的潜在缺陷(即种族偏见)。
from interpret import set_visualize_provider
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider())
from interpret import show
ebm_global = ebm.explain_global()
show(ebm_global)
局部解释(Local explanations)显示了单个预测是如何做出的。对于glassbox 模型,这些解释是准确的——它们完美地描述了模型是如何做出决定的。这些解释有助于向最终用户描述哪些因素对预测最有影响。
ebm_local = ebm.explain_local(X_test[:5], y_test[:5])
show(ebm_local,0)

如果有多个模型解释,可以按下面方式进行比较:
show([logistic_regression_global, decision_tree_global])

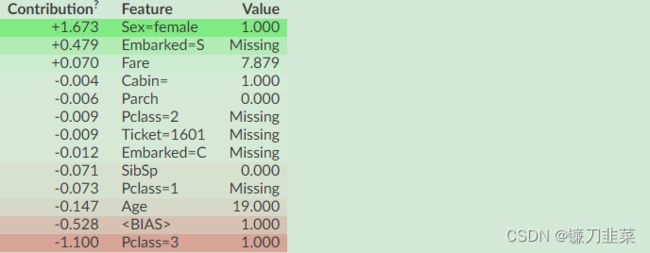
2.5 ELI5
ELI5是一个可以帮助调试机器学习分类器并解释它们的预测的Python库。目前支持以下机器学习框架:scikit-learn、XGBoost、LightGBM、CatBoost、Keras。
ELI5有两种主要的方法来解释分类或回归模型:
- 检查模型参数并说明模型是如何全局工作的;
- 检查模型的单个预测并说明什么模型会做出这样的决定。
2.6 OmniXAI
OmniXAI (Omni explained AI的简称),是Salesforce最近开发并开源的Python库。它提供全方位可解释的人工智能和可解释的机器学习能力来解决实践中机器学习模型在产生中需要判断的几个问题。对于需要在ML过程的各个阶段解释各种类型的数据、模型和解释技术的数据科学家、ML研究人员,OmniXAI希望提供一个一站式的综合库,使可解释的AI变得简单。

以下是OmniXAI提供的与其他类似库的对比:

下面是一个OmniXAI的Dashboard Demo:

参考资料
- 树模型决策的可解释性与微调(Python)
- 详解Python的可解释机器学习库:SHAP
- 基于ELI5使用解读LIME算法以及实战案例
- 6个机器学习可解释性框架
- Unpack Local Model Interpretation for GBDT
- SHAP
- LIME
- Shapash
- InterpretML
- ELI5
- OmniXAI