Apache hudi 0.10.1学习笔记之压缩Compaction(上篇)——压缩计划的生成
一、基础概念
了解过hudi的新手或者专家都知道,hudi不管是COW还是MOR表,其文件还是存储在hdfs上。因为下来介绍我在学习hudi压缩的一些东西,所以下方就以MOR表文件做下介绍。下方会由浅入深尝试说明压缩计划和压缩策略等等之间的关系。
对文件排列方面,例如FileGroup、FileSlice等概念还未学习的同学可以先从了解这个图后再继续。
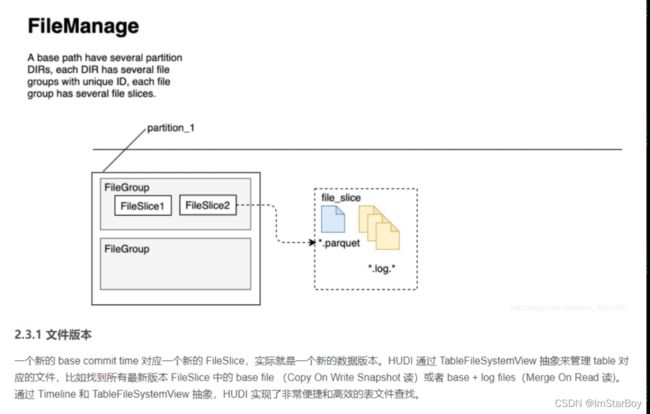
可以理解为如果数据文件(若干log和parquet文件)的instantTime一样,那么他们都属于一个fileSlice。fileSlice所以也有FileGroup来标记自己属于哪个分区和自己的ID。
首先是数据文件,分为log文件和data文件。前者是avro格式的,保存较新的数据,而后者是parquet文件,内部数据则是更早或是和log合并后的。下方以一个非压缩非clustering的表文件为例子:

basePath 就是/user/ocdp/test/hudi/mor_noComNoClu。表名字就是mor_noComNoClu。
而后面time_15min则表示hudi表各个分区目录,当前是以系统时间,每15分钟一个分区。
接下来以一个分区为例子:

上方的是log文件,下方是parquet文件。根据代码中的命名含义,parquet文件的名由4部分组成:
5eaef46b-f581-41a2-8012-c66f608b3070-0_8-514-118306_20220329133607800.parquet
即 fileId_writeToken_instantTime.parquet
fileId就是FileGroup中的ID(FileGroup的另一个组成部分为Partition也就是分区名)
writeToken暂时理解为一个随机数,他主要在执行压缩计划阶段会用。
instantTime就是时间戳,时间戳可以理解为稍后要说的元数据文件(202204xxx.deltacommit.requested)的时间戳。
parquet表示了文件里的格式,也可能在有的环境上用的是.orc 或.hfile等。
下方是该表./hoodie下的文件样例:

只有MOR表才有这种deltaCommit(COW表在这元数据目录下只有commit),xxx.request表示待执行的commit,如果xx这个instanTime出现了对应的inflight状态文件,就表示该commit正在处理。一定时间后若是出现该instanTime的.deltacommit文件,那就表示这个commit已经完成。注意这里一个deltacommit,其instantTime实际对应了若干个数据文件、例如20220419110525544.celtacommit 他对应了很多log和parquet文件。
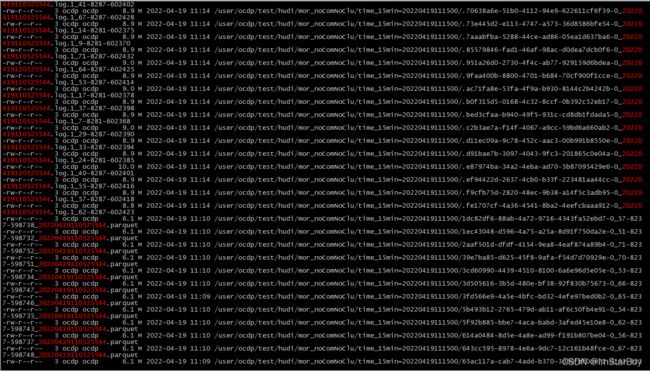
可见每个文件都比较小,不利于集群维护以及hudi查找时的效率。所以我们无论是以同步(intime)还是异步(offline)压缩,都是为了把这些打把的小文件合并成少数的大文件。
hudi自己提供了很多压缩的配置来应对使用者的需求,包括指定不同的压缩策略,压缩触发条件等等。
二、代码解读
以手动调用compactor生成一个压缩计划的方式为例。也是在yarn上生成一个spark作业。提交该作业时有很多参数,其中压缩策略、并行度、内存都是可选参数,而目标instantTime必须要给出,以及-sc表示“scheduleCompaction”也要开启(反之就是执行压缩计划而不是生成压缩计划)。

跳过若干调用过程,从下方开始重点介绍
ScheduleCompactionActionExecutor.java


这里就是对上方生成压缩计划时,给定的instantTime进行“合法性验证”。长话短说就是要求目标instantTime要同时满足下方两个条件。
1、目标instantTime必须大于所有activecommit时间且小于最小的inflight状态的非compaction的instantTime。这样是为了确保压缩时还有没有正常写入、清除的动作正在进行,从而影响了压缩时间范围。
2、目标instantTime必须大于所有commit、deltacommit的完成时instantTime,和现存(老的)compaction的instantTime。和上方目的类似,保证了压缩时间轴范围上的连贯性。
紧接着使用HoodieCompactionPlan plan = scheduleCompaction();去获取压缩计划,其逻辑如下:
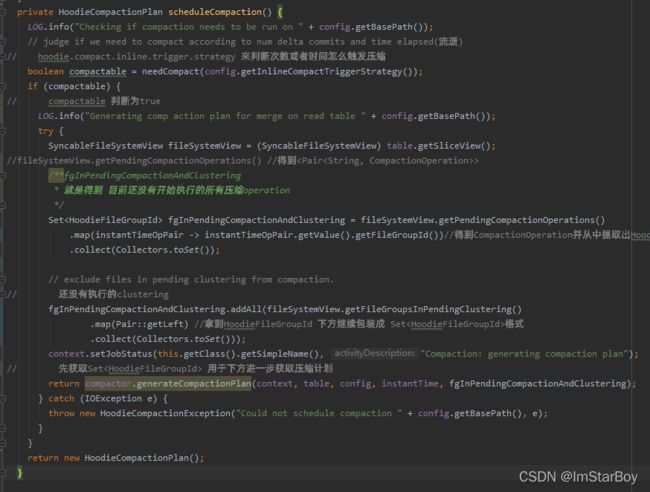
拿到一个存放“所有现有的压缩计划的operation 对应的HoodieFileGroupId”的set,叫做fgInPendingCompactionAndClustering,来继续参与下方generateCompactionPlan方法逻辑
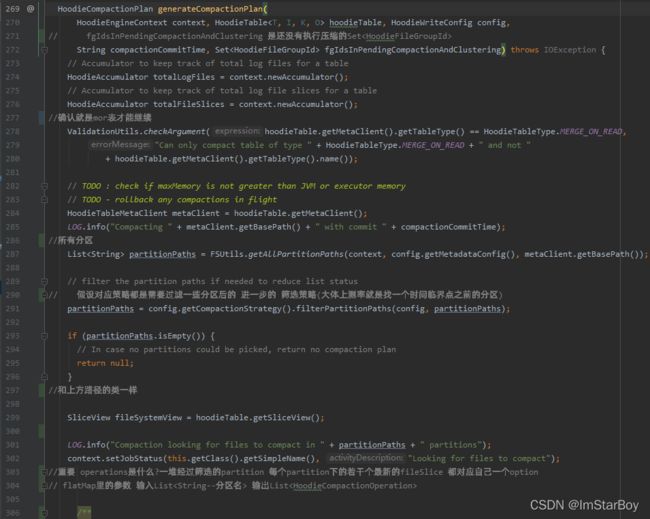 partitionPaths为所有分区的路径名,并进一步根据压缩计划所给出(或默认)的压缩策略,筛选出需要参与压缩的分区。而从下方“获取opeartion”就是更进一步探索压缩计划中的operation为何
partitionPaths为所有分区的路径名,并进一步根据压缩计划所给出(或默认)的压缩策略,筛选出需要参与压缩的分区。而从下方“获取opeartion”就是更进一步探索压缩计划中的operation为何

大致过程就是把上方筛选后的partitionPaths,经过flatmap里的方法处理每一个分区目录。处理逻辑就是每个分区目录先转换为其分区区下所有fileSlice,该分区所有flieSlice在过滤掉其中对应的HoodieFileGroupId已经出现在现存压缩计划operation中的(不在上方fgInPendingCompactionAndClustering里的),可以理解为“先前压缩计划就已经包含了的数据,本次生成压缩计划就不再包含这些”。
在经过map继续处理每一个fileSlice,把每个fileSlice的logfile和baseFile也就是所有log和parquet文件获取到,再构造成一个个新的CompactionOperation。所有新Operation需要再过滤掉其deltaFileNames为空的。
到此
Listoperations已经获取到,再经过下方步骤就能产生新的压缩计划

也就是把新生成的operations以及用户给定的writeConfig和现存的老的压缩计划,进行处理生成一个新的压缩计划。继续回到上方这里
HoodieCompactionPlan plan = scheduleCompaction();
此时构建一个新的元数据文件 :InstantTime.compaction.request(在.hoodie下),再用
table.getActiveTimeline().saveToCompactionRequested(compactionInstant,
TimelineMetadataUtils.serializeCompactionPlan(plan));
把压缩继续写入到该文件里,到此压缩计划就已生成。
补充:
1、我们压缩计划生成时,例如给定了一个压缩策略为
BoundedPartitionAwareCompactionStrategy,那么它会具体实现filterPartitionPaths方法逻辑来筛选出要参与压缩的数据分区
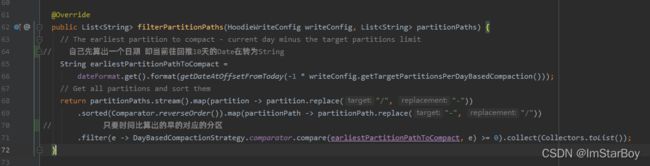
他的筛选逻辑大概就是根据给定的参数hoodie.compaction.daybased.target.partitions(default =10),然后进一步就能获取到一个过去的时间点作为阈值,然后把所有分区对应的时间拿出来跟这个标杆对比,留下只比其小的时间(更早时间)的分区作为本次压缩计划涉及范围。