hadoop01--Hadoop伪分布式集群搭建
- 需要的节点:主节点为hadoop1,其他节点分别为hadoop2,hadoop3。
- 使用jdk文件:jdk-8u144-linux-x64.tar.gz-------------------链接: https://pan.baidu.com/s/1ap1NypdGaD8OoTv5cUEXxw?pwd=av48 提取码: av48
- 使用的centos:CentOS-7-x86_64-DVD-1511---------------链接: https://pan.baidu.com/s/1XQ7N2oVf6Z9ouCtpn98EVw?pwd=3i2h 提取码: 3i2h
- 使用的软件:VMware15--------------------------链接: https://pan.baidu.com/s/1Rfg6o3xCbkfY90Fkmbcu2A?pwd=7ih5 提取码: 7ih5 复制虚拟机连接工具:xshell---------------------------链接: https://pan.baidu.com/s/1Rfg6o3xCbkfY90Fkmbcu2A?pwd=7ih5 提取码: 7ih5 复制
- 需要的用户名:HadoopColony,主机名即节点名:hadoop1
【所有的节点都是在同一台母机上】
目录
一,配置Linux集群环境
1,创建用户
编辑2,添加用户的sudoers权限
3,修改主机名
4,关闭防火墙
5,更改ip
编辑6,创建资源文件
7,安装jdk
8,配置jdk环境
9,克隆虚拟机
10,修改克隆机的ip及主机名
11,配置主机ip映射
二,搭建hadoop集群
1,配置集群各节点无密钥登录
2,配置hadoop
1)安装hadoop并配置hadoop系统环境变量
2)配置jdk到hadoop,mapred,yarn上
编辑3,配置hdfs
1)修改core-site.xml 文件
编辑2)修改hdfs-site.xml文件
3)修改slaves文件
4,配置yarn
1)修改mapred-site.xml文件
2)修改yarn-site.xml文件
5,复制hadoop到其他虚拟机
1)格式化NameNode
6,启动hadoop集群
1)查看各节点启动进程
2)测试HDFS
接下来我们就需要将我们的虚拟机进行相应的创建用户名,修改主机名,按照配置jdk,克隆虚拟机等操作。
一,配置Linux集群环境
如下,我们现在使用的用户还是root用户,且主机名为localhost,现在我们来将其修改成 用户名为:HadoopColony(即hadoop集群),主机名为hadoop1

1,创建用户
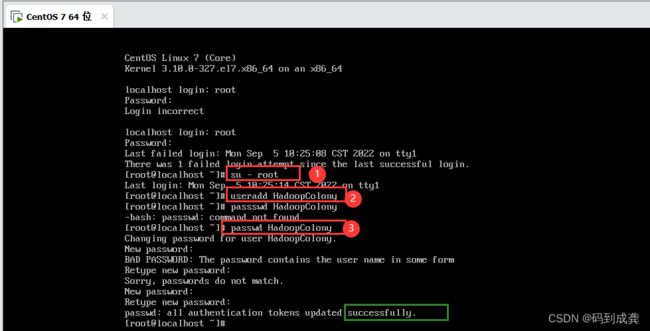 2,添加用户的sudoers权限
2,添加用户的sudoers权限
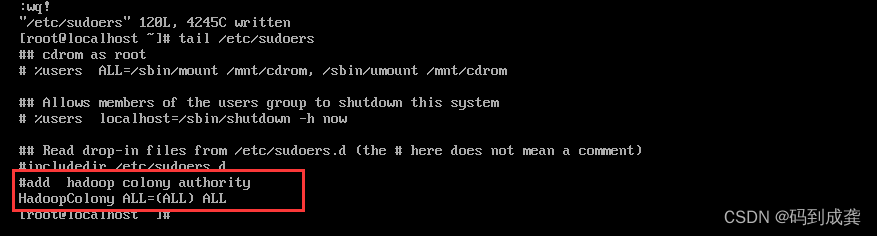
3,修改主机名
先使用su - 用户名:su - HadoopColony。
之后输入命令:sudo vi /etc/hostname→按“i”进行编辑→使用“←”,“↑”,“↓”,“→”键进行移动光标→输入完成后先按一下“esc”键退出编辑模式,输入“:wq!”即可,如下修改完成:

然后重启系统,让我们的修改生效

之后再一次登录进去就可以看到我们的修改成功了:

4,关闭防火墙

5,更改ip
在更改ip之前,请先阅读这篇文章,事先编辑一下“虚拟网络编辑器”
linux001--初次体验vmware虚拟机_码到成龚的博客-CSDN博客
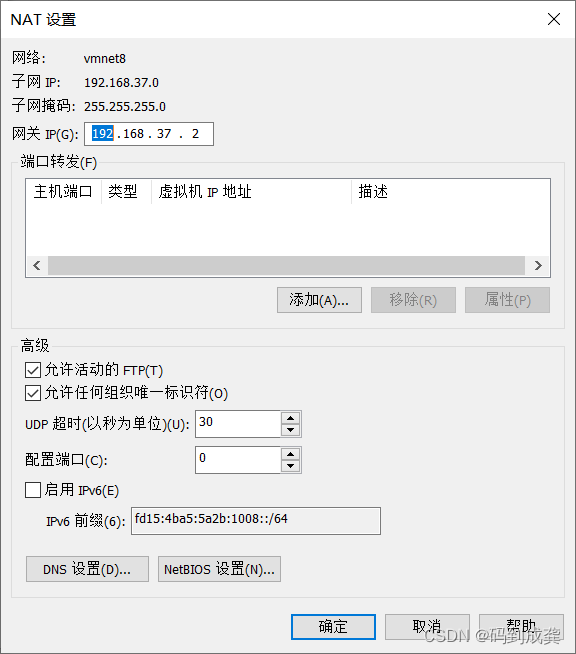
如上就是我这台电脑上的IP地址,因此我在给我的虚拟机指定ip时,前三位必须是192.168.37,后面的只要在不要超过255就行。
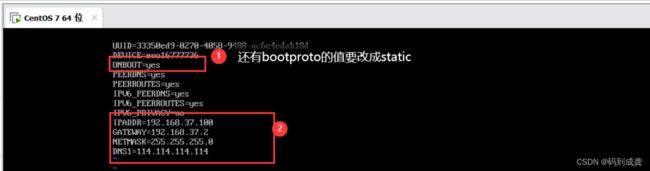
修改好网卡之后,保存退出,接着使用命令:sudo service network restart 重启网卡,让我们的修改生效,最后使用ifconfig命令来查看网络信息,如果提示没有该命令的话,就需要去使用yum下载网络工具net-tools,如下:


如上我们将虚拟机的ip地址都配置好了后,就可以使用虚拟机连接软件来连接我们的虚拟机了
 6,创建资源文件
6,创建资源文件
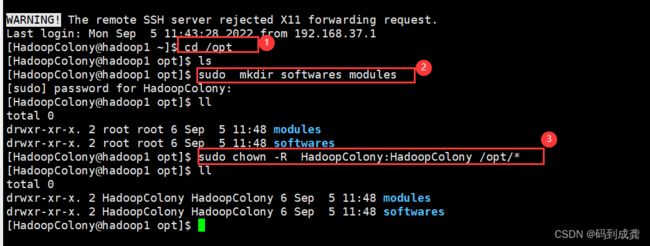
[HadoopColony@hadoop1 ~]$ cd /opt --转到存放软件的目录
[HadoopColony@hadoop1 opt]$ ls --使用ls查看当前目录有哪些文件
[HadoopColony@hadoop1 opt]$ sudo mkdir softwares modules --创建两个文件夹(目录)
[sudo] password for HadoopColony:
[HadoopColony@hadoop1 opt]$ ll --不仅显示了当前目录下有哪些文件也显示了文件的所有者和所属组
total 0
drwxr-xr-x. 2 root root 6 Sep 5 11:48 modules --现在都是默认root用户
drwxr-xr-x. 2 root root 6 Sep 5 11:48 softwares
[HadoopColony@hadoop1 opt]$ sudo chown -R HadoopColony:HadoopColony /opt/* --修改权限
[HadoopColony@hadoop1 opt]$ ll
total 0
drwxr-xr-x. 2 HadoopColony HadoopColony 6 Sep 5 11:48 modules --修改成功
drwxr-xr-x. 2 HadoopColony HadoopColony 6 Sep 5 11:48 softwares
[HadoopColony@hadoop1 opt]$
7,安装jdk
在安装之前我们需要先检查一下我们的虚拟机上是否以及安装了,避免以及安装的jdk对我们的后续操作造成影响
[HadoopColony@hadoop1 ~]$ rpm -qa | grep java --查看系统上已安装的jdk,如下显示没有
[HadoopColony@hadoop1 ~]$

如果使用了rpm -qa | grep java 命令后有jdk的存在,可以使用命令卸载掉:sudo rpm -e --nodeps jdk的名字。在确定了没有jdk后,接下来我们需要使用虚拟机与本机之间文件传输工具xftp或者是finalshell。如下我先使用finalshell进行文件的传输
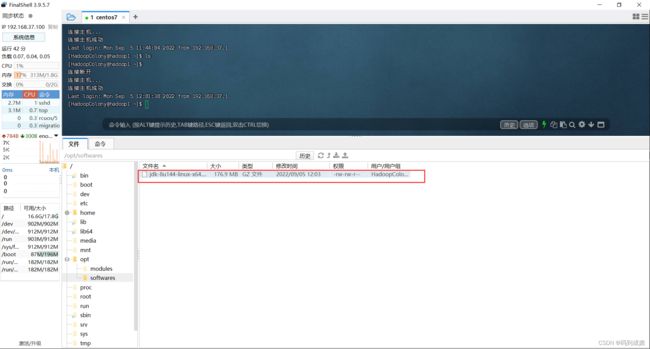
上传完成后,我们可以看到,在我们的/opt/softwares下存在了jdk文件
接下来我们就需要将/opt/softwares目录下的jdk压缩包解压到/opt/modules下
[HadoopColony@hadoop1 ~]$ cd /opt/softwares/
[HadoopColony@hadoop1 softwares]$ ll
total 181168
-rw-rw-r--. 1 HadoopColony HadoopColony 185515842 Sep 5 12:03 jdk-8u144-linux-x64.tar.gz
[HadoopColony@hadoop1 softwares]$ tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/modules/ --解压
[HadoopColony@hadoop1 softwares]$ cd ../modules/
[HadoopColony@hadoop1 modules]$ ll --查看/opt/modules目录下是否有我们的jdk文件
total 4
drwxr-xr-x. 8 HadoopColony HadoopColony 4096 Jul 22 2017 jdk1.8.0_144
[HadoopColony@hadoop1 modules]$ 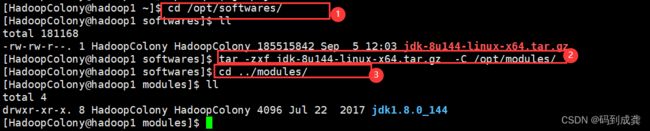
8,配置jdk环境
相信大家在使用windows操作系统学习Java语言的时候安装jdk后都需要配置jdk的环境变量的,在虚拟机上也不例外。
[HadoopColony@hadoop1 ~]$ sudo vi /etc/profile --编辑etc下的profile文件,编辑好后按esc退出
[sudo] password for HadoopColony:
[HadoopColony@hadoop1 ~]$ tail /etc/profile --最后四行为加进去的内容
unset i
unset -f pathmunge
#配置jdk的环境变量(为hadoop用户)
export JAVA_HOME=/opt/modules/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/tool.jar:$JAVA_HOME/lib/dt.jar
[HadoopColony@hadoop1 ~]$

之后我们需要去刷新一下修改的profile文件
[HadoopColony@hadoop1 ~]$ source /etc/profile --刷新/etc/profile文件
[HadoopColony@hadoop1 ~]$ java -version --显示java版本号等信息
java version "1.8.0_144" --Java安装成功
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
[HadoopColony@hadoop1 ~]$

如上配置好了jdk后,我们就可以开始克隆虚拟机了,但是需要注意的是,在克隆虚拟机之前需要先将虚拟机关闭,可以直接在xshell里面输入:sudo poweroff 来进行关机
9,克隆虚拟机
选中已经配置好jdk的虚拟机,鼠标右击,找到“管理”→“克隆”,出现如下界面之后,点击"下一步"


如上操作两次,共需要克隆两台虚拟机,如下:
10,修改克隆机的ip及主机名
修改ip地址请参考步骤4 ,修改主机名请参考步骤3。
TYPE=Ethernet
BOOTPROTO=static #引导时不使用协议,静态分配boot协议
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736 #网卡名
UUID=ef189aea-cdbd-4d76-90f1-e1e1b7a208c6
DEVICE=eno16777736 #物理设备名
ONBOOT=yes #引导时激活设备---开机自启
PEERDNS=yes
PEERROUTES=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_PRIVACY=no
IPADDR=192.168.37.100 #ip地址
GATEWAY=192.168.37.2 #网关
NETMASK=255.255.255.0 #掩码值
DNS1=114.114.114.114 #第一个代理地址
修改IP结果图

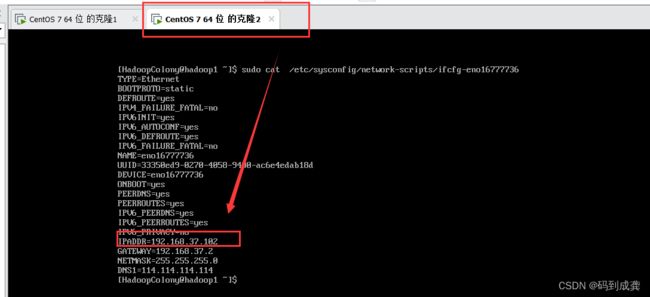
修改主机名效果图

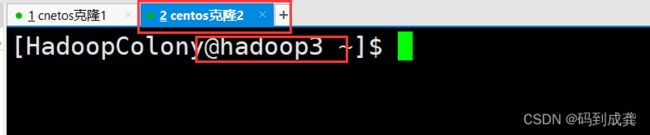
11,配置主机ip映射
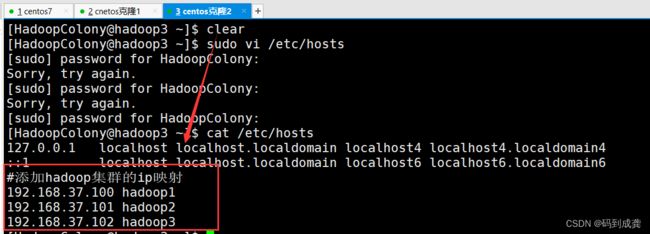
我们的虚拟机不能总是使用ip地址去查找它,也可以使用映射来进行替换查找。这个时候我们就需要去编辑/etc/hosts文件,将我们的ip地址和映射都添加到文件的末尾:
[HadoopColony@hadoop1 ~]$ sudo vi /etc/hosts
[sudo] password for HadoopColony:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#添加hadoop集群的ip映射
192.168.37.100 hadoop1
192.168.37.101 hadoop2
192.168.37.102 hadoop3


接下来我们在三个虚拟机上分别互相ping另外两台虚拟机,如果ping通的话就代表我们的映射成功
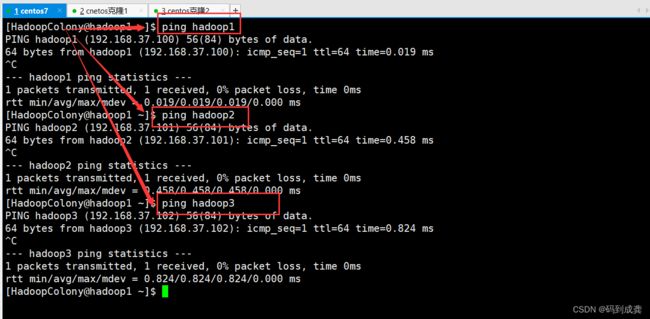
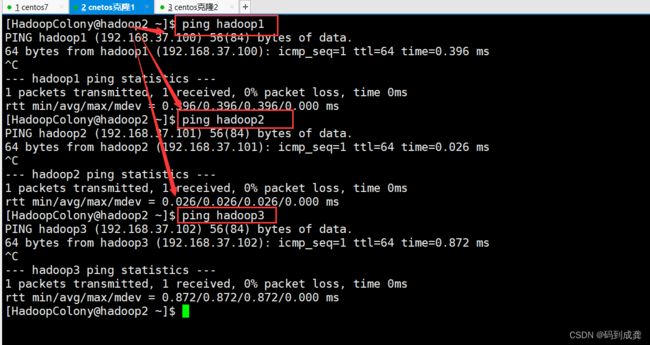
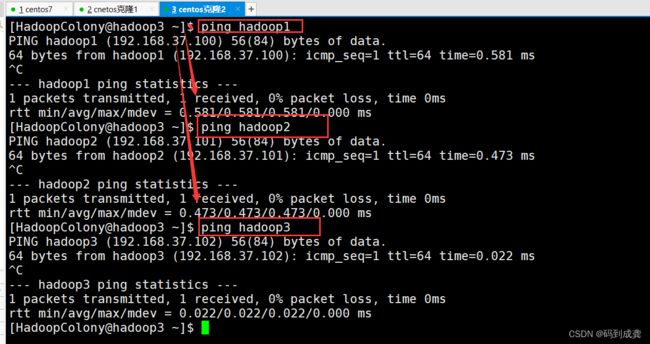
如上测试后,都能够互相ping通。接下来我们开始搭建Hadoop集群。
二,搭建hadoop集群
集群之间是需要进行信息交互的,每一台机器都会有密码,如果机器少,业务少的话,我们可以每次都输入密码,但是如果机器多,业务多,我们真的要每一次信息交互都输入密码的话,那实在是难以想象的工作量。因此集群各节点需要配置ssh无密钥登录。
1,配置集群各节点无密钥登录
[HadoopColony@hadoop1 ~]$ cd ~/.ssh --跳转到ssh目录
[HadoopColony@hadoop1 .ssh]$ ssh-keygen -t rsa --查看密钥和公钥

使用:ssh-copy-id 主机名 命令将该节点的公钥信息复制并追加到指定节点的授权文件中
【需要注意的是,自己的公钥信息也要就行复制】
[HadoopColony@hadoop1 ~]$ ssh-copy-id hadoop1 --将hadoop1的公钥信息复制并追加到节点的授权文件中
The authenticity of host 'hadoop1 (192.168.37.100)' can't be established.
ECDSA key fingerprint is 95:7f:45:c8:4c:07:6c:89:e5:2b:6f:ec:1e:fa:7f:7e.
Are you sure you want to continue connecting (yes/no)? es
Please type 'yes' or 'no': yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
HadoopColony@hadoop1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added. --添加成功
[HadoopColony@hadoop1 ~]$ ssh-copy-id hadoop2 --将hadoop2的公钥信息复制并追加到节点的授权文件中
The authenticity of host 'hadoop2 (192.168.37.101)' can't be established.
ECDSA key fingerprint is 95:7f:45:c8:4c:07:6c:89:e5:2b:6f:ec:1e:fa:7f:7e.
Are you sure you want to continue connecting (yes/no)? es^H^H^H
Please type 'yes' or 'no': yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
HadoopColony@hadoop2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop2'"
and check to make sure that only the key(s) you wanted were added. --添加成功
[HadoopColony@hadoop1 ~]$ ssh-copy-id hadoop3 --将hadoop3的公钥信息复制并追加到节点的授权文件中
The authenticity of host 'hadoop3 (192.168.37.102)' can't be established.
ECDSA key fingerprint is 95:7f:45:c8:4c:07:6c:89:e5:2b:6f:ec:1e:fa:7f:7e.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
HadoopColony@hadoop3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop3'"
and check to make sure that only the key(s) you wanted were added. --添加成功
剩下的两个从节点按照相同的步骤进行即可:【依旧是那句话:hadoo1也要复制公钥信息到自己hadoo1上】
hadoop2:
[HadoopColony@hadoop2 .ssh]$ ssh-copy-id hadoop1
Are you sure you want to continue connecting (yes/no)? yes
...
Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added.
[HadoopColony@hadoop2 .ssh]$ ssh-copy-id hadoop3
Are you sure you want to continue connecting (yes/no)? yes
...
Now try logging into the machine, with: "ssh 'hadoop3'"
and check to make sure that only the key(s) you wanted were added.
hadoop3:
[HadoopColony@hadoop3 .ssh]$ ssh-copy-id hadoop2
Are you sure you want to continue connecting (yes/no)? yes
...
Now try logging into the machine, with: "ssh 'hadoop2'"
and check to make sure that only the key(s) you wanted were added.
[HadoopColony@hadoop3 .ssh]$ ssh-copy-id hadoop1
Are you sure you want to continue connecting (yes/no)? yes
...
Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added.接下来我们开始测试无密钥登录
[HadoopColony@hadoop1 ~]$ ssh hadoop3 --hadoop1→hadoop3 √1
Last login: Mon Sep 5 17:32:22 2022 from hadoop2
[HadoopColony@hadoop3 ~]$ ssh hadoop1 --hadoop3→hadoop1 √3
Last failed login: Mon Sep 5 17:55:16 CST 2022 from hadoop3 on ssh:notty
There was 1 failed login attempt since the last successful login.
Last login: Mon Sep 5 17:44:01 2022 from 192.168.37.1
[HadoopColony@hadoop1 ~]$ ssh hadoop2 --hadoop1→hadoop2 √1
Last login: Mon Sep 5 17:44:25 2022 from 192.168.37.1
[HadoopColony@hadoop2 ~]$ ssh hadoop1 --hadoop2→hadoop1 √2
Last login: Mon Sep 5 17:58:41 2022 from hadoop3
[HadoopColony@hadoop1 ~]$ ssh hadoop3 --hadoop1→hadoop3 √1
Last login: Mon Sep 5 17:45:03 2022 from 192.168.37.1
[HadoopColony@hadoop3 ~]$ ssh hadoop1 --hadoop1→hadoop2 √3
Last login: Mon Sep 5 17:59:05 2022 from hadoop2
[HadoopColony@hadoop1 ~]$
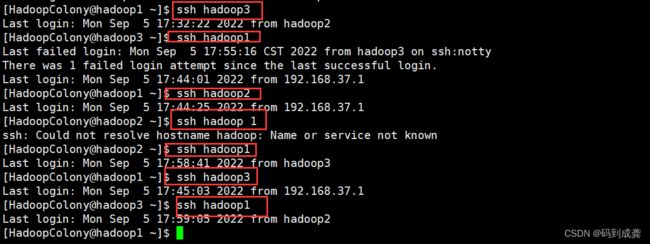 从上面我们可以看到hadoop1到hadoop2,hadoop3都可以实现无密钥登录
从上面我们可以看到hadoop1到hadoop2,hadoop3都可以实现无密钥登录
[HadoopColony@hadoop2 ~]$ ssh hadoop1
Last login: Mon Sep 5 18:08:36 2022 from hadoop2
[HadoopColony@hadoop1 ~]$ ssh hadoop2
Last login: Mon Sep 5 18:08:45 2022 from hadoop1
[HadoopColony@hadoop2 ~]$ ssh hadoop3
Last login: Mon Sep 5 17:59:20 2022 from hadoop1
[HadoopColony@hadoop3 ~]$
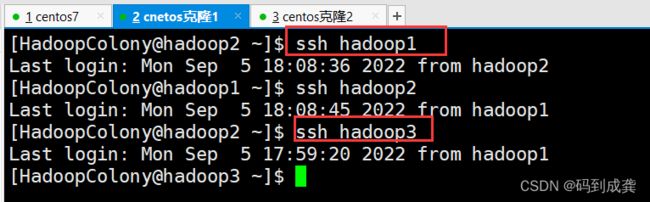 hadoop2到hadoop1,hadoop3也可以无密钥登录
hadoop2到hadoop1,hadoop3也可以无密钥登录
[HadoopColony@hadoop3 .ssh]$ ssh hadoop1
Last login: Mon Sep 5 18:08:57 2022 from hadoop2
[HadoopColony@hadoop1 ~]$ ssh hadoop3
Last login: Mon Sep 5 18:09:07 2022 from hadoop2
[HadoopColony@hadoop3 ~]$ ssh hadoop2
Last login: Mon Sep 5 18:09:03 2022 from hadoop1
[HadoopColony@hadoop2 ~]$

hadoop3到hadoop1,hadoop2也可以实现无密钥登录
2,配置hadoop
1)安装hadoop并配置hadoop系统环境变量
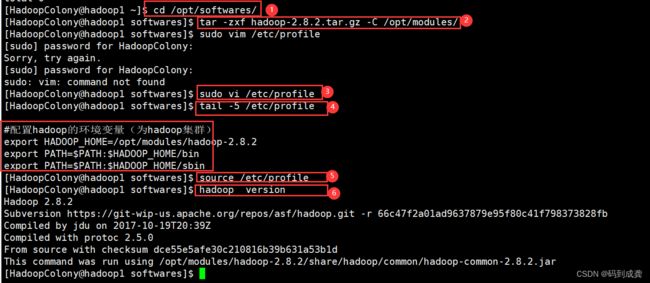
[HadoopColony@hadoop1 ~]$ cd /opt/softwares/ --跳转到softwares目录下
[HadoopColony@hadoop1 softwares]$ tar -zxf hadoop-2.8.2.tar.gz -C /opt/modules/ --解压hadoop文件到modules目录
[HadoopColony@hadoop1 softwares]$ sudo vi /etc/profile --修改profile文件,将hadoop的路径配置上去
[HadoopColony@hadoop1 softwares]$ tail -5 /etc/profile --显示配置进去的Hadoop路径
#配置hadoop的环境变量(为hadoop集群)
export HADOOP_HOME=/opt/modules/hadoop-2.8.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[HadoopColony@hadoop1 softwares]$ source /etc/profile --刷新文件,使我们的修改生效
[HadoopColony@hadoop1 softwares]$ hadoop version --查看hadoop版本
Hadoop 2.8.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 66c47f2a01ad9637879e95f80c41f798373828fb
Compiled by jdu on 2017-10-19T20:39Z
Compiled with protoc 2.5.0
From source with checksum dce55e5afe30c210816b39b631a53b1d
This command was run using /opt/modules/hadoop-2.8.2/share/hadoop/common/hadoop-common-2.8.2.jar
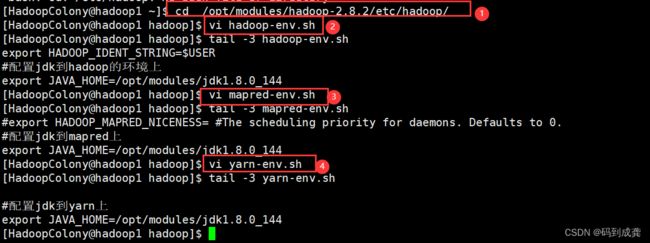
2)配置jdk到hadoop,mapred,yarn上
[HadoopColony@hadoop1 ~]$ cd /opt/modules/hadoop-2.8.2/etc/hadoop/ --转到hadoop的安装路径
[HadoopColony@hadoop1 hadoop]$ vi hadoop-env.sh --配置hadoop环境
[HadoopColony@hadoop1 hadoop]$ tail -3 hadoop-env.sh --显示配置信息
export HADOOP_IDENT_STRING=$USER
#配置jdk到hadoop的环境上
export JAVA_HOME=/opt/modules/jdk1.8.0_144
[HadoopColony@hadoop1 hadoop]$ vi mapred-env.sh --配置mapred环境
[HadoopColony@hadoop1 hadoop]$ tail -3 mapred-env.sh
#export HADOOP_MAPRED_NICENESS= #The scheduling priority for daemons. Defaults to 0.
#配置jdk到mapred上
export JAVA_HOME=/opt/modules/jdk1.8.0_144
[HadoopColony@hadoop1 hadoop]$ vi yarn-env.sh --配置yarn环境
[HadoopColony@hadoop1 hadoop]$ tail -3 yarn-env.sh
#配置jdk到yarn上
export JAVA_HOME=/opt/modules/jdk1.8.0_144
 3,配置hdfs
3,配置hdfs
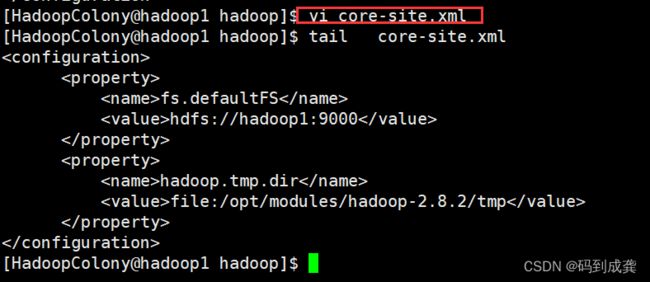
1)修改core-site.xml 文件
[HadoopColony@hadoop1 hadoop]$ vi core-site.xml
[HadoopColony@hadoop1 hadoop]$ cat core-site.xml
...
fs.defaultFS
hdfs://hadoop1:9000
hadoop.tmp.dir
file:/opt/modules/hadoop-2.8.2/tmp
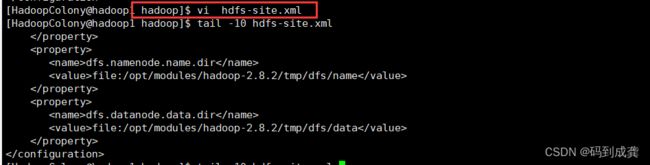
 2)修改hdfs-site.xml文件
2)修改hdfs-site.xml文件
[HadoopColony@hadoop1 hadoop]$ vi hdfs-site.xml
[HadoopColony@hadoop1 hadoop]$ tail -18 hdfs-site.xml
#配置Hadoop集群所需
dfs.replication
2
dfs.permissions.enabled
false
dfs.namenode.name.dir
file:/opt/modules/hadoop-2.8.2/tmp/dfs/name
dfs.datanode.data.dir
file:/opt/modules/hadoop-2.8.2/tmp/dfs/data
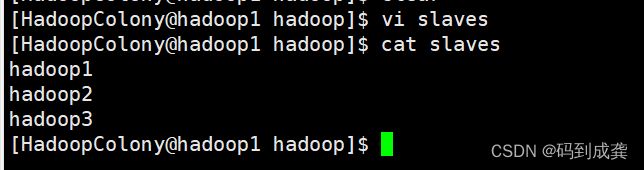
3)修改slaves文件
[HadoopColony@hadoop1 hadoop]$ vi slaves
[HadoopColony@hadoop1 hadoop]$ cat slaves
hadoop1
hadoop2
hadoop3
4,配置yarn
1)修改mapred-site.xml文件
[HadoopColony@hadoop1 hadoop]$ ls
capacity-scheduler.xml hadoop-metrics2.properties httpfs-signature.secret log4j.properties ssl-client.xml.example
configuration.xsl hadoop-metrics.properties httpfs-site.xml mapred-env.cmd ssl-server.xml.example
container-executor.cfg hadoop-policy.xml kms-acls.xml mapred-env.sh yarn-env.cmd
core-site.xml hdfs-site.xml kms-env.sh mapred-queues.xml.template yarn-env.sh
hadoop-env.cmd httpfs-env.sh kms-log4j.properties mapred-site.xml.template yarn-site.xml
hadoop-env.sh httpfs-log4j.properties kms-site.xml slaves
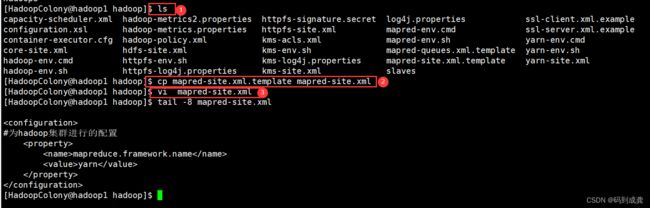
[HadoopColony@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[HadoopColony@hadoop1 hadoop]$ vi mapred-site.xml
[HadoopColony@hadoop1 hadoop]$ tail -8 mapred-site.xml
#为hadoop集群进行的配置
mapreduce.framework.name
yarn
2)修改yarn-site.xml文件
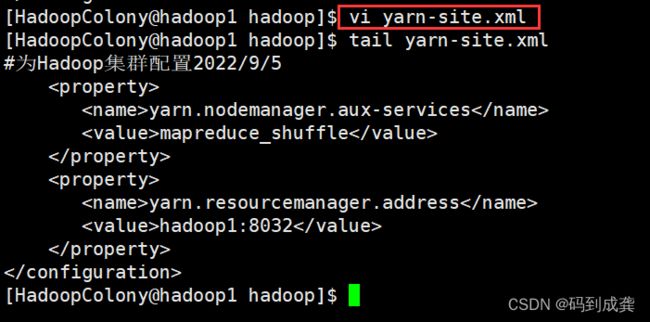
[HadoopColony@hadoop1 hadoop]$ vi yarn-site.xml
[HadoopColony@hadoop1 hadoop]$ tail yarn-site.xml
#为Hadoop集群配置2022/9/5
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
hadoop1:8032
5,复制hadoop到其他虚拟机
[HadoopColony@hadoop1 modules]$ scp -r hadoop-2.8.2 HadoopColony@hadoop2:/opt/modules/
[HadoopColony@hadoop1 modules]$ scp -r hadoop-2.8.2 HadoopColony@hadoop3:/opt/modules/
(这个需要2~3分,可去泡一杯咖啡)

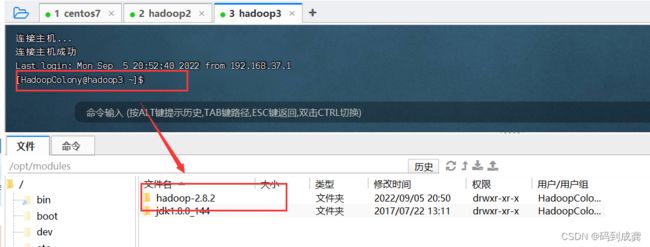
如上,安全复制hadoop文件成功,接下来我们需要格式化我们的NameNode。
1)格式化NameNode
[HadoopColony@hadoop1 modules]$ hadoop namenode -format
...
22/09/05 20:56:48 INFO common.Storage: Storage directory /opt/modules/hadoop-2.8.2/tmp/dfs/name has been successfully formatted. --出现这一行表示格式化成功
...![]()

6,启动hadoop集群
[HadoopColony@hadoop1 modules]$ cd /opt/modules/hadoop-2.8.2/tmp/dfs/name/current --查看初始化后的文件
[HadoopColony@hadoop1 current]$ ls --(里面存储了hdfs的元数据。)
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
[HadoopColony@hadoop1 current]$ start-all.sh

或者是在sbin目录下打开集群:

1)查看各节点启动进程
hadoop1:
[HadoopColony@hadoop1 current]$ cd /opt/modules/hadoop-2.8.2/sbin
[HadoopColony@hadoop1 sbin]$ jps
30483 ResourceManager
30614 NodeManager
30235 SecondaryNameNode
30077 DataNode
29966 NameNode
30910 Jps
hadoop2:
[HadoopColony@hadoop2 ~]$ jps
13010 DataNode
13250 Jps
13115 NodeManager
[HadoopColony@hadoop2 ~]$
hadoop3:
[HadoopColony@hadoop3 ~]$ jps
10016 NodeManager
9910 DataNode
10153 Jps
[HadoopColony@hadoop3 ~]$ 如上就配置成功了,如果不放心的话可以再使用hdfs来进行查看
2)测试HDFS
[HadoopColony@hadoop1 ~]$ hdfs dfs -mkdir /hello2022
[HadoopColony@hadoop1 ~]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - HadoopColony supergroup 0 2022-09-05 22:12 /hello2022
[HadoopColony@hadoop1 ~]$

以下为在外部查看,即使用浏览器的方式:
可以直接使用:http://ip地址:50070
打开浏览器→输入‘http://ip地址:50070’→回车→找到‘Utilities’点击→选择‘Browse the file system ’→就可以看到我们新建的文件了。
http://192.168.37.100:50070/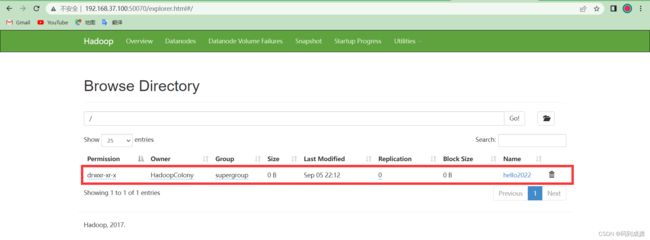
如果觉得使用ip地址太长太麻烦了也可以使用:http://主机名:50070【但是这个需要提前在母机的hosts文件里面进行IP地址映射才能够使用】
该hosts文件位于:C:\Windows\System32\drivers\etc\hosts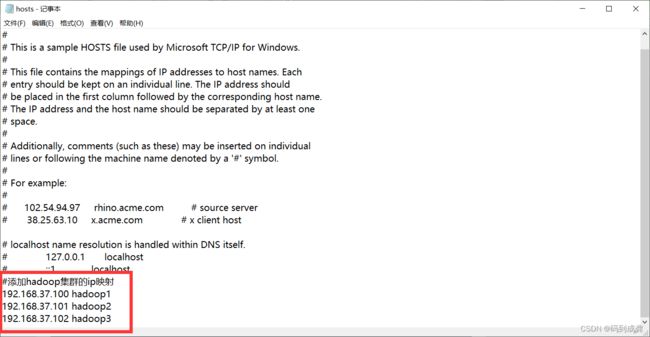
【值得注意的是如果我们使用普通用户的形式打开该文件并进行编辑的话是无用的,没法保存,因此我们需要先使用“管理员身份”打开我们的记事本】


如上就是配置一个主节点,两个子节点的hadoop集群,如果有问题的请在评论区回复。