国产开源50亿参数新模型,合成可控性、质量实现飞跃
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
在 AI 绘画领域,很多研究者都在致力于提升 AI 绘画模型的可控性,即让模型生成的图像更加符合人类要求。前段时间,一个名为 ControlNet 的模型将这种可控性推上了新的高峰。大约在同一时间,来自阿里巴巴和蚂蚁集团的研究者也在同一领域做出了成果,本文是这一成果的详细介绍。

论文地址:https://arxiv.org/pdf/2302.09778v2.pdf
项目地址:https://github.com/damo-vilab/composer
近年来,在大数据上学习的大规模生成模型能够出色地合成图像,但可控性有限。可控图像生成的关键不仅依赖于条件,而且更重要的是依赖于组合性。后者可以通过引入巨大数量的潜在组合来指数级地扩展控制空间(例如 100 个图像,每个有 8 个表征,产生大约 100^8 种组合)。类似的概念在语言和场景理解领域得到了探索,其中的组合性被称为组合泛化,即从有限的已知成分中识别或生成潜在的无限数量的新组合的技能。
最新的一项研究提供了一种新的生成范式 —— 可以在灵活控制输出图像(如空间布局和调色板)的同时保持合成质量和模型创造力。
这项研究以组合性为核心思想,首先将图像分解为具有代表性的因子,然后以这些因子为条件训练扩散模型,对输入进行重组。在推理阶段,丰富的中间表征形式作为可组合元素,为可定制内容的创建提供了巨大的设计空间 (即与分解因子的数量成指数比例)。值得注意的是,名为 Composer 的方法支持各种级别的条件,例如将文本描述作为全局信息,将深度图和草图作为局部指导,将颜色直方图作为低级细节等。
除了提高可控性之外,该研究还确认了 Composer 可以作为通用框架,在无需再训练的情况下促进广泛的经典生成任务。
方法
本文所介绍的框架包括分解阶段(图像被分为一组独立的组件)与合成阶段(组件利用条件扩散模型重新组合)。这里首先简要介绍扩散模型和使用 Composer 实现的制导方向,然后将详细说明图像分解和合成的实现。
2.1. 扩散模型
扩散模型是一种生成模型,通过迭代去噪过程从高斯噪声中产生数据。通常使用简单的均方误差作为去噪目标:
![]()
其中,x_0 是具有可选条件 c 的训练数据,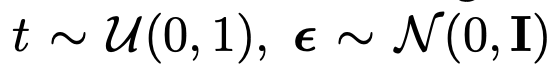 是加性高斯噪声,a_t、σ_t 是 t 的标量函数,
是加性高斯噪声,a_t、σ_t 是 t 的标量函数,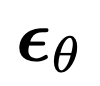 是具有可学习参数 θ 的扩散模型。无分类器引导在最近的工作中得到了最广泛的应用,用于扩散模型的条件数据采样,其中预测的噪声通过以下方式进行调整:
是具有可学习参数 θ 的扩散模型。无分类器引导在最近的工作中得到了最广泛的应用,用于扩散模型的条件数据采样,其中预测的噪声通过以下方式进行调整:
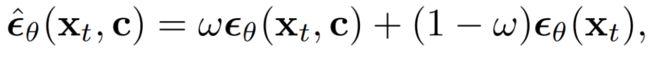
公式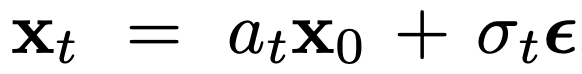 中, ω 为引导权重。DDIM 和 DPM-Solver 经常被用于加速扩散模型的采样过程。DDIM 还可以用于将样本 x_0 反推到其纯噪声潜在 x_T,从而实现各种图像编辑操作。
中, ω 为引导权重。DDIM 和 DPM-Solver 经常被用于加速扩散模型的采样过程。DDIM 还可以用于将样本 x_0 反推到其纯噪声潜在 x_T,从而实现各种图像编辑操作。
引导方向:Composer 是一个可以接受多种条件的扩散模型,可以在无分类器引导下实现各种方向:

c_1 和 c_2 是两组条件。c_1 和 c_2 的不同选择表征对条件的不同强调。
(c_2 \ c_1) 内的条件强调为 ω, (c_1 \ c_2) 内的条件抑制为 (1−ω), c1∩c2 内的条件的指导权重为 1.0.。双向指导:通过使用条件 c_1 将图像 x_0 反转到潜在的 x_T,然后使用另一个条件 c_2 从 x_T 采样,研究能够使用 Composer 以一种解纠缠的方式操作图像,其中操作方向由 c_2 和 c_1 之间的差异来定义。
分解
研究将图像分解为捕捉图像各个方面的去耦表征,并且描述了该任务中使用的八种表征,这几种表征都是在训练过程中实时提取的。
说明(Caption):研究直接使用图像 - 文本训练数据中的标题或描述信息(例如,LAION-5B (Schuhmann et al., 2022))作为图像说明。当注释不可用时,还可以利用预训练好的图像说明模型。研究使用预训练的 CLIP ViT-L /14@336px (Radford et al., 2021) 模型提取的句子和单词嵌入来表征这些标题。
语义和风格(Semantics and style):研究使用预先训练的 CLIP ViT-L/14@336px 模型提取的图像嵌入来表征图像的语义和风格,类似于 unCLIP。
颜色(Color):研究使用平滑的 CIELab 直方图表征图像的颜色统计。将 CIELab 颜色空间量化为 11 个色调值,5 个饱和度和 5 个光值,使用平滑 sigma 为 10。经验所得,这样设置的效果更好。
草图(Sketch):研究应用边缘检测模型,然后使用草图简化算法来提取图像的草图。草图捕捉图像的局部细节,具有较少的语义。
实例(Instances):研究使用预训练的 YOLOv5 模型对图像应用实例分割来提取其实例掩码。实例分割掩码反映了视觉对象的类别和形状信息。
深度图(Depthmap):研究使用预训练的单目深度估计模型来提取图像的深度图,大致捕捉图像的布局。
强度(Intensity):研究引入原始灰度图像作为表征,迫使模型学习处理颜色的解纠缠自由度。为了引入随机性,研究统一从一组预定义的 RGB 通道权重中采样来创建灰度图像。
掩码(Masking):研究引入图像掩码,使 Composer 能够将图像生成或操作限制在可编辑的区域。使用 4 通道表征,其中前 3 个通道对应于掩码 RGB 图像,而最后一个通道对应于二进制掩码。
需要注意的是,虽然本文使用上述八种条件进行了实验,但用户可以使用 Composer 自由定制条件。
构成
研究使用扩散模型从一组表征中重新组合图像。具体来说,研究利用 GLIDE 架构并修改其调节模块。研究探索了两种不同的机制来根据表征调整模型:
全局调节:对于包括 CLIP 句子嵌入、图像嵌入和调色板在内的全局表征,研究将它们投影并添加到时间步嵌入中。此外,研究还将图像嵌入和调色板投射到八个额外的 token 中,并将它们与 CLIP 词嵌入连接起来,然后将其用作 GLIDE 中交叉注意的上下文,类似于 unCLIP 。由于条件要么是相加的,要么可以在交叉注意中选择性地掩盖,所以在训练和推理期间可以直接放弃条件,或者引入新的全局条件。
局部化调节:对于局部化表征,包括草图、分割掩码、深度映射、强度图像和掩码图像,研究使用堆叠卷积层将它们投射到与噪声潜在 x_t 具有相同空间大小的均维嵌入中。然后计算这些嵌入的和,并将结果连接到 x_t,然后将其输入到 UNet。由于嵌入是可添加的,因此很容易适应缺失的条件或合并新的局部化条件。
联合训练策略:设计一种联合训练策略,使模型能够从各种条件组合中学习解码图像,这一点很重要。研究对几种配置进行了实验,并确定了一个简单而有效的配置,其中对每个条件使用独立的退出概率为 0.5,删除所有条件的概率为 0.1,保留所有条件的概率为 0.1。对于强度图像使用 0.7 的特殊退出概率,因为它们包含了关于图像的绝大多数信息,并且在训练过程中可能会弱化其他条件。
基本扩散模型产生 64 × 64 分辨率的图像。为了生成高分辨率图像,研究训练了两个无条件扩散模型用于上采样,分别将图像从 64 × 64 提升到 256 × 256,以及从 256 × 256 提升到 1024 × 1024 分辨率。上采样模型的架构是从 unCLIP 修改的,其中研究在低分辨率层中使用更多通道,并引入自注意块来扩大容量。此外还引入了一个可选的先验模型,该模型从字幕生成图像嵌入。根据经验,先验模型能够在特定的条件组合下提高生成图像的多样性。
实验
变体:使用 Composer 可以创建与给定图像相似的新图像,但通过对其表征的特定子集所进行的条件反射在某些方面有些不同。通过仔细选择不同表征的组合,人们可以灵活地控制图像变化的范围 (图 2a)。在纳入更多的条件后,研究所介绍的方法比仅以图像嵌入为条件的 unCLIP 生成变体:使用 Composer 可以创建与给定图像相似的新图像,但通过对其表征的特定子集进行条件反射,在某些方面有所不同。通过仔细选择不同表征的组合,人们可以灵活地控制图像变化的范围 (图 2a)。在纳入更多的条件后,研究所介绍的方法比仅以图像嵌入为条件的 unCLIP 的重建准确率更高。






© The Ending
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
计算机视觉研究院亲自体验ChatGPT的感受,太疯狂了!
用于吸烟行为检测的可解释特征学习框架(附论文下载)
图像自适应YOLO:恶劣天气下的目标检测(附源代码)
新冠状病毒自动口罩检测:方法的比较分析(附源代码)
NÜWA:女娲算法,多模态预训练模型,大杀四方!(附源代码下载)
实用教程详解:模型部署,用DNN模块部署YOLOv5目标检测(附源代码)
LCCL网络:相互指导博弈来提升目标检测精度(附源代码)