Flink的部署介绍
local-cluster模式
Flink中的Local-cluster(本地集群)模式,主要用于测试, 学习。
1.flink官网下载 Apache Flink: Stateful Computations over Data Streams
2.解压至工具目录,将其复制并改名为flink-local
3.把上个文章中的无界流处理wordcount的API打包为jar包传入flink-local目录
4.启动本地集群
bin/start-cluster.sh5.在hadoop102中启动netcat
nc -lk 99996.命令行提交Flink应用
bin/flink run -m hadoop102:8081 -c com.hpu.flink.wd_test.stream_test02 ./flink_test-1.0-SNAPSHOT.jar 7.在浏览器中输入http://hadoop102:8081/查看应用执行情况,也可以在log文件中.out文件查看
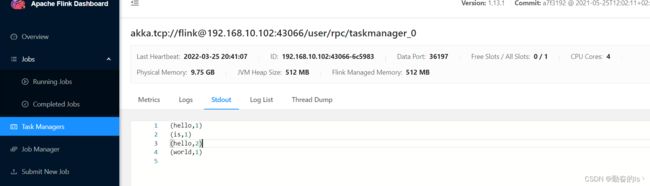
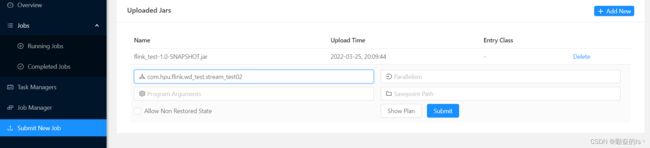
8.也可以在WEB UI提交应用
Standalone模式
Standalone模式又叫独立集群模式。
1.解压至工具目录,将其复制并改名为flink-standalone
2.修改配置文件:flink-conf.yaml
jobmanager.rpc.address: hadoop1023.修改配置文件:workers
hadoop102
hadoop103
hadoop1044.把上个文章中的无界流处理wordcount的API打包为jar包传入flink-local目录
5.启动本地集群
启动bin/start-cluster.sh
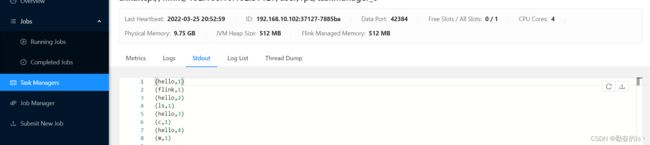
bin/flink run -m hadoop102:8081 -c com.hpu.flink.wd_test.stream_test02 ./flink_test-1.0-SNAPSHOT.jar5.查看结果与local方式一致,可以在网页提交任务
Yarn模式
独立部署(Standalone)模式由Flink自身提供计算资源,无需其他框架提供资源,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是Flink主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成更靠谱。
把Flink应用提交给Yarn的ResourceManager, Yarn的ResourceManager会申请容器从Yarn的NodeManager上面. Flink会创建JobManager和TaskManager在这些容器上。Flink会根据运行在JobManger上的job的需要的slot的数量动态的分配TaskManager资源
1.解压至工具目录,将其复制并改名为flink-yarn
2.配置环境变量export HADOOP_CLASSPATH=`hadoop classpath`
3.开启任务 bin/flink run -t yarn-per-job -c com.hpu.flink.wd_test.stream_test02 flink_test-1.0-SNAPSHOT(开启监听)
4.点击applicationMaster进入UI界面

3种部署模式
Session-Cluster,Application Mode和Per-Job-Cluster
Session-Cluster
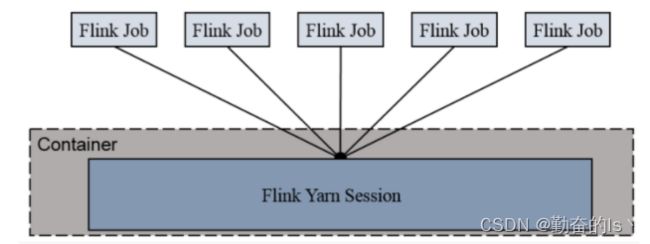
Session模式:适合需要频繁提交的多个小job,并且执行时间都不长,因为flink会在yarn中启动一个session集群,这个集群主要用来申请资源的,后续提交的其他作业,都会直接提交到这个session集群中,不需要频繁创建flink集群,这样效率会变高,但是,作业之间相互不隔离。
Session-Cluster模式需要先启动Flink集群,向Yarn申请资源。以后提交任务都向这里提交。这个Flink集群会常驻在yarn集群中,除非手动停止。
在向Flink集群提交Job的时候, 如果资源被用完了,则新的Job不能正常提交.
缺点: 如果提交的作业中有长时间执行的大作业, 占用了该Flink集群的所有资源, 则后续无法提交新的job。所以, Session-Cluster适合那些需要频繁提交的多个小Job, 并且执行时间都不长的Job.
Per-Job-Cluster

每提交一个job会在yarn中启动一个flink集群,并且这些作业是相互隔离的,同时main方法是在本地上运行。
一个Job会对应一个Flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Application Mode
每提交一个任务(application)可能会包含多个job,一个application对应一个flink集群,main方法是在集群中运行。
Application Mode会在Yarn上启动集群, 应用jar包的main函数(用户类的main函数)将会在JobManager上执行. 只要应用程序执行结束, Flink集群会马上被关闭. 也可以手动停止集群.
与Per-Job-Cluster的区别:就是Application Mode下, 用户的main函数是在集群中执行的,并且当一个application中有多个job的话,per-job模式则是一个job对应一个yarn中的application,而Application Mode则这个application中对应多个job。