SeaTunnel 超大数据量数据集成平台设计
导读:本文将介绍 SeaTunnel 超大数据量的数据集成平台,主要围绕以下内容展开:
-
SeaTunnel 的设计目标
-
SeaTunnel 现状
-
SeaTunnel 整体设计
-
近期规划
分享嘉宾|高俊 白鲸开源 架构师
编辑整理|王鹏 滴滴出行
出品社区|DataFun
01
SeaTunnel 的设计目标
SeaTunnel 的目标是打造一个简单易用的、分布式可扩展的支持超大数据级的高吞吐低延时的数据集成平台,主要解决以下 4 个问题:
-
数据源多,版本间不兼容,而且不断有新的出现
-
离线同步和实时同步常被分开管理,维护困难
-
企业技术栈差异大,导致选择同步组件时需要更多的学习成本
-
数据同步需要高吞吐低时延,数据一致性要求高
02
SeaTunnel 现状

目前 SeaTunnel 支持的连接器有 50 个以上,包括 Source 有 20 多个,目标端 20 多个,Transform 有十几个。

这些连接器基本上都是批流一体的,Apache Pulsar 连接器让开发者只实现一个连接器,就可以同时支持离线同步任务和实时同步任务。同时可以支持纯流和微批两种方式。

SeaTunnel 支持多引擎,以便更好的兼容企业已有的技术生态,降低企业在数据同步场景下使用 SeaTunnel 的技术成本。主流的大数据处理引擎 SeaTunnel 都支持:包括多个版本的 Flink,Spark,以及 SeaTunnel 自己的引擎 SeaTunnel Engine。
在性能和一致性方面,SeaTunnel 具有以下特性:
-
高吞吐:SeaTunnel 支持 Source/Transform/Sink 算子的并行化处理,提高吞吐性能。
-
低延迟:基于引擎提供的实时处理或微批处理实现低延迟。
-
精确性:基于引擎提供的分布式快照算法,包括 Sink 端两阶段提交、幂等写入,Source 端的读回放等这些特性,保证数据精确处理一次(Exactly-Once)。
03
SeaTunnel 整体设计
1. 整体架构

SeaTunnel 整体架构分为以下几个部分:
-
数据源:用于从各种数据源中读取数据,包含了目前所有常见的数据库,湖和仓库,以及国内外的 SaaS 服务。
-
目标端:主要负责往目标端写入数据,包含了目前常见的数据库、湖、仓,以及国内外的 SaaS 服务。
-
数据处理引擎:SeaTunnel 默认使用自己的引擎 SeaTunnel Engine 同步数据,同时也支持使用 Spark/Flink。
-
基于这些连接器,有一个转化端,把连接器转化为适应不同引擎运行的 Connector。
-
Table API:为了降低上层的使用难度和提高通用性,提供了 Table API,基于 Table API 上层用户可以做Web端或者以 Table API 的形式创建应用。
2. 执行流程
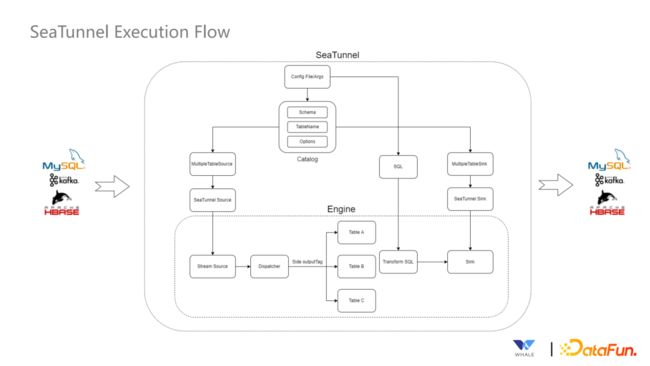
SeaTunnel 的执行流程如上图所示,最上面是 SeaTunnel 内部 SQL 和API 的定义,基于这些定义生成连接器,然后将连接器和 Job 提交到对应的引擎上进行处理,最终数据通过Sink写入目标端。
3. 连接器内部运行策略
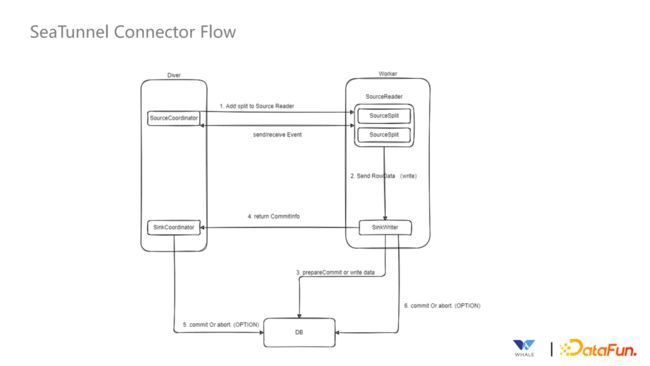
SeaTunnel Driver 端运行着 SourceCoordinator 和 SinkCoordinator协调器,Worker 端运行着 SourceReader 和 SinkWriter。SourceReader 对读取 SoureSplit 分片中数据,读取完后发送给 SinkWriter,SinkWriter 按照 SinkCoordinator 中的逻辑执行状态的存储、两阶段提交等操作,保证数据的一致性。
4. 独立 API
SeaTunnel 专为数据集成场景设计了独立 API,独立 API 是与引擎解藕的,主要有以下 4 个特点:
-
多引擎支持:通过定义一套 SeaTunnel 自己的 API,解决以往针对不同的处理引擎需要写两套不同的 Connector 的问题,实现一套代码可在不同的引擎上执行。
-
多版本支持:通过 Translation 层将 Connector 与引擎解藕,解决以往为了支持底层引擎一个新的版本,大部分 Connector 都需要修改代码的问题。
-
流批一体:统一了流和批的处理 API,新的 Connector 只需要按 API 实现一次,即可同 时支持流处理和批处理下的数据集成。
-
JDBC 多复用/数据库日志多表解析:支持多表或整库同步,解决 JDBC 连接过多的问题;支持多表或整库数据库日志读取解析,解决 CDC 多表同步场景下需要重复解析日志的问题。
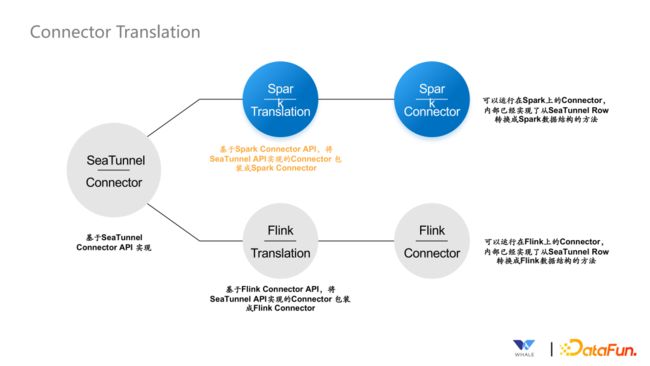
5. Connector Translation
Connector Translation 层将 Connector 与引擎解藕,解决以往为了支持底层引擎一个新的版本,大部分 Connector 都需要修改代码的问题,下图展示了基于 Connector Translation 机制的 SeaTunnel Connector 是如何转换成不同的引擎执行的:
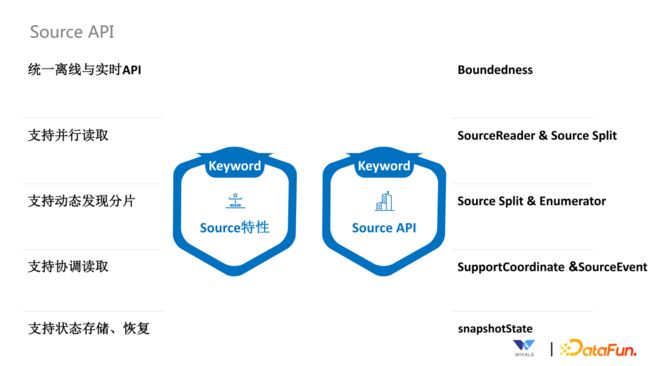
6. Source API
Source API 主要包括 Source 连接器和 Source API,下图是 Source的特性与实现 Source 特性的 Source API 的对应关系:
-
统一离线与实时 API:通过 Boundedness API 实现
-
支持并行读取:通过 SourceReader & Source Split API 实现
-
支持动态发现分片:通过 Source Split & Enumerator API 实现。比如我们在 Source 端想基于正则表达式读取 Kafka Topic,如果有新的 Topic 被创建,正则表达式将这个 Topic 匹配之后就可以进行数据读取。这个功能就可以通过 Source Split & Enumerator API 来实现
-
支持协调读取:主要 CDC 场景下使用。比如除了从批量同步切换到实时增量同步,这个过程就需要 SupportCoordinate &SourceEvent 协调读取这套 API 来参与
-
支持状态存储、恢复:为了能够实现数据的精确一致消费、重启恢复,需要支持状态存储、恢复,这个功能主要是通过 SnapshotState API 来实现
7. Source Connector
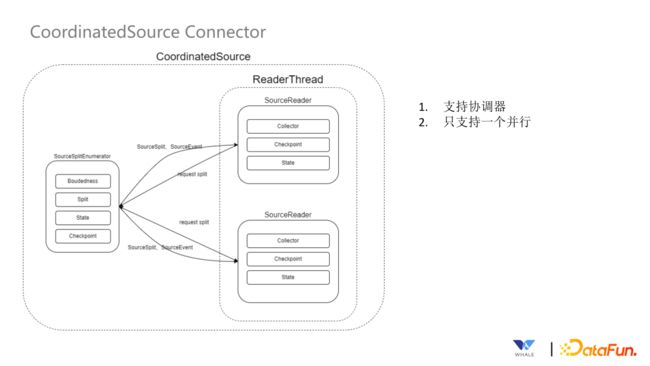
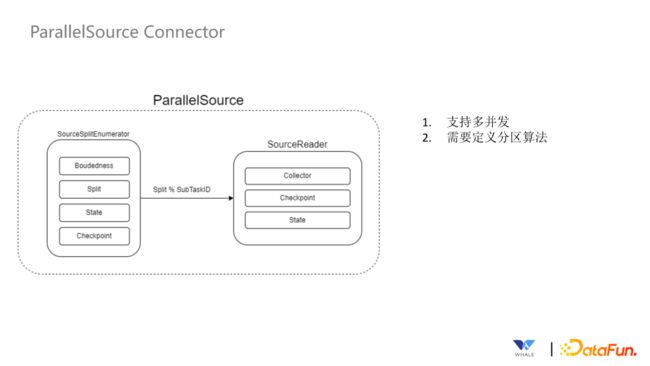
Source Connector 有两种,分别是 CoordinatedSource Connector 和ParallelSource Connector。
CoordinatedSource Connector 支持协调器,通过事件的方式将 Split 发送给 SourceReader,目前只支持一个并发。
ParallelSource Connector 支持多并发,需要定义分区算法规则让协调器知道分片应该发送给哪个 SourceReader。
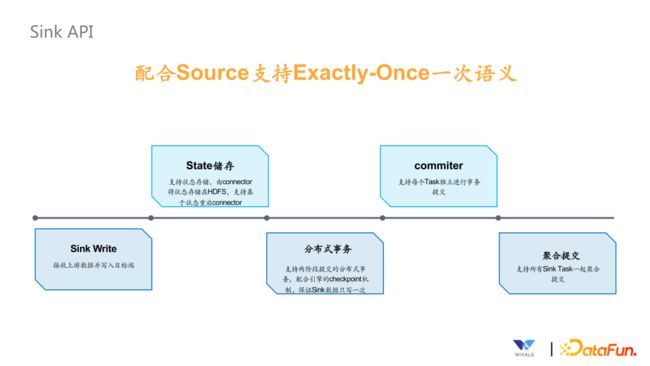
8. Sink API
Sink API 的主要目标是配合 Source 支持 Exactly-Once 一次语义,主要有以下 5 个部分:
-
Sink Write: 接受上游数据并写入目标端。
-
State 储存:依赖底层的分布式快照算法的状态通知机制,比如Flink在做分布式快照时,会有一些事件的通知, Sink 连接器接收到这些事件通知后,将状态存储在存储 HDFS,同时支持基于状态重启 Connector。
-
分布式事务:支持两阶段提交的分布式事务,配合引擎的 Checkpoint 机制,保证 Sink 数据只写一次。
-
Commiter:支持每个 Task 独立进行事务提交,常用于 Flink 的场景。
-
聚合提交:支持所有 Sink Task 一起聚合提交,常用于 Spark 的场景。
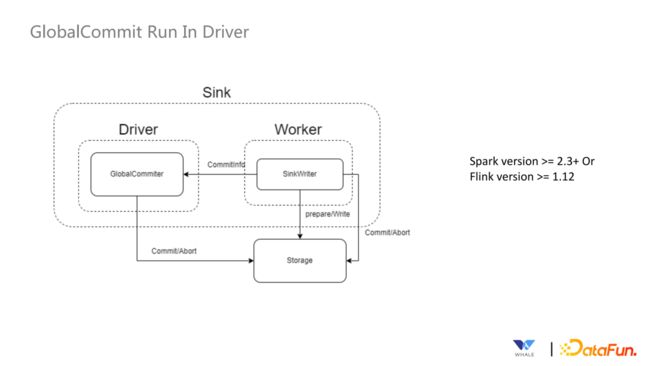
9. GlobalCommit Run In Driver
GlobalCommit 的第一种模式是 Commit 运行在 Driver 端,SinkWriter运行在 Worker 端,通过 Driver 端和 Worker 端的通信来进行协调,该模式的运行机制如下:
第二种模式是 Commit 和 SinkWriter 都运行在 Worker 端,这种模式是为了适配 Flink version <= 1.11 这种情况,Spark 不支持该模式,该模式运行机制如下:

第三种模式是每个 Task 直接进行 Commit,不需要进行聚合,Flink 的所有版本都支持这种模式,Spark 不支持:

10. SeaTunnel Table & Catalog API
这些 API 是面向应用的 API,目的是简化同步作业配置,提供可视化作业配置的基础。主要有以下四个方面的 API:
-
数据源管理:SeaTunnel 定义了一套 API 来支持创建数据源插件,基于 SPI 实现后即可集成该数据源的配置、连接测试工作。
-
元数据获取:支持获取数据源的表结构(库名、表名、字段名、字段类型等),方便可视化的配置同步作业的源和目标域的表名映射,字段映射等。
-
数据类型定义:由于需要支持多引擎,所有连接器中都使用SeaTunnel的格式,在 Connector Translation 会转换为对应引擎的格式。
-
连接器创建:SeaTunnel提供了一套 API 用于创建自动获取信息创建 Source、Sink 等实例。
04
近期规划
最后介绍一下 SeaTunnel 的近期规划。
SeaTunnel 作为一个数据集成平台,将不断专注于解决数据集成领域的需求和问题。我们希望支持数据源的数量更多,数据同步的性能更快,在易用性方面更好用,从这三方面不断迭代优化,以满足更多的用户需求。
1. V2 版本连接器数量翻一倍
-
所有 Spark、Flink 连接器升级到 V2 版本
-
连接器总数今年翻一倍,达到 80 以上
2. 发布 SeaTunnel Web 模块
-
提供可视化作业管理
-
支持编程式和引导式作业配置
-
实现内部调度,以及第三方调度的集成
3. 发布 SeaTunnel Engine
-
更省资源,将 JDBC 共享,节省连接数量,并且在执行端实现绿色线程、线程共享等技术,从而达到节省资源的目的
-
更细粒度的容错,实现基于 Pipeline 级别的调度和容错
-
更快
SeaTunnel Connector 接入激励计划是最近社区在做的一个活动。基于SeaTunnel Connector API 来实现,目前已经收集了 105 个数据源,当贡献者 PR 完成合并后,根据难易程度和优先级,会得到一些奖励。活动的目的是完善 SeaTunnel 生态。欢迎大家参与。

05
问答环节
Q1:在 Flink 实时同步下,可以做 Checkpoint 处理吗?
A1:可以。API 设计的时候考虑到了 Flink 分布式快照的机制,SeaTunnel可以完美兼容 Flink 分布式快照的流程。
Q2:DolphinScheduler 是怎么支持 SeaTunnel 的?
A2:DolphinScheduler 已经支持 SeaTunnel 的任务,即将发布的SeaTunnel Web 上的调度系统也会支持 DolphinScheduler。
今天的分享就到这里,谢谢大家。