java——字节跳动后端开发面经(凉凉)2021-07-06
博主最近在找暑期实习的岗位,投递了字节的java后端开发岗,今天刚面完技术面,感觉凉了。冷静下来之后还是想复盘一下这次面试的过程,给自己也给在同一条路上的其他朋友一个未来学习方向的参考。
下面就进入正式内容
首先,是万年不变的自我介绍。
然后面试官直奔主题。针对我自我介绍中提到的最近在看的一些底层的容器类。提了以下几个问题:
一、容器类
说说ArrayList是怎么实现的?
这个我在之前复习的时候是同LinkedList一起复习的,所以我当时就提出来想讲讲ArrayList跟LinkedList的区别和联系。
(注:当时只想起来前两点QAQ)
- 首先,他们的底层数据结构不同,ArrayList底层是基于数组实现的,LinkedList底层是基于链表实现的
- 由于底层数据结构不同,他们所适⽤的场景也不同,ArrayList更适合随机查找,LinkedList更适合删 除和添加,查询、添加、删除的时间复杂度不同
- 另外ArrayList和LinkedList都实现了List接⼝,但是LinkedList还额外实现了Deque接⼝,所以 LinkedList还可以当做队列来使⽤
说说数组跟ArrayList的区别
答案:
数组([]):最高效;但是其容量固定且无法动态改变;
ArrayList:容量可动态增长;但牺牲效率;
用法上: 首先使用数组,无法确定数组大小时才使用ArrayList!
说说你对HashMap的了解。
答:首先说了HashMap的底层数据结构在Jdk1.7和Jdk1.8的区别。Jdk1.7以前是数组加链表的组合,Jdk1.8以后是数组加链表加红黑树。
说说put方法的基本过程:
这里直接放上标准答案:
-
根据Key通过哈希算法与与运算得出数组下标
-
如果数组下标位置元素为空,则将key和value封装为Entry对象(JDK1.7中是Entry对象,JDK1.8中是 Node对象)并放⼊该位置
-
如果数组下标位置元素不为空,则要分情况讨论
a. 如果是JDK1.7,则先判断是否需要扩容,如果要扩容就进⾏扩容,如果不⽤扩容就⽣成Entry对 象,并使⽤头插法添加到当前位置的链表中
b. 如果是JDK1.8,则会先判断当前位置上的Node的类型,看是红⿊树Node,还是链表Node
i. 如果是红黑树Node,则将key和value封装为⼀个红黑树节点并添加到红⿊树中去,在这个过 程中会判断红⿊树中是否存在当前key,如果存在则更新value 。
ii. 如果此位置上的Node对象是链表节点,则将key和value封装为⼀个链表Node并通过尾插法插入到链表的最后位置去,因为是尾插法,所以需要遍历链表,在遍历链表的过程中会判断是否存在当前key,如果存在则更新value,当遍历完链表后,将新链表Node插入到链表中,插⼊ 到链表后,会看当前链表的节点个数,如果大于等于8,那么则会将该链表转成红黑树
iii. 将key和value封装为Node插⼊到链表或红黑树中后,再判断是否需要进⾏扩容,如果需要就 扩容,如果不需要就结束PUT⽅法。
说说你知道的HashMap解决哈希冲突的方法
1.开放地址法
2.拉链法
3. 再哈希
4.建立公共溢出区
这里贴一下大佬的博客,方便各位进一步学习:
https://blog.csdn.net/mashaokang1314/article/details/88672035
Jdk1.7之前HashMap怎么扩容的?
什么时候扩容:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值—即当前数组的长度乘以加载因子的值的时候,就要自动扩容。
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
HashMap 是线程安全的吗?为什么?
答:不是,HashMap线程不安全,HashTable 线程安全。
这个问题需要从两个方面进行回答,分别是Jdk1.7和Jdk1.8;
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
具体解答见
https://blog.csdn.net/zzu_seu/article/details/106669757
二、计算机网络
说说计算机网络分层模型
答:OIS的七层模型;数据链路层,物理层,表示层,会话层,传输层、网络层、应用层。
说说你知道的协议以及它是属于那一层的?
答:TCP,属于传输层。
说说TCP和UDP的区别?为什么UDP效率更高?
答:TCP 建立连接时双方需要互相确认,类似打电话,在专业术语中称为 3 次握手。
UDP 全称为用户数据报协议,它可以提供非连接的不可靠的点到多点的通信,所谓不可靠,在于 UDP 每一次发送数据需要绑定 IP 和端口号,但是对于已经发送出去的数据来说并不去确认,也不需要类似 TCP 的三次握手的过程,由于没有了这个过程,所以其传输效率较之 TCP 来说要高许多。
说说TCP三次握手的过程
第一次握手
客户主动(active open)去connect服务器,并且发送SYN 假设序列号为J,服务器是被动打开(passive open)
第二次握手
服务器在收到SYN后,它会发送一个SYN以及一个ACK(应答)给客户,ACK的序列号是 J+1表示是给SYN J的应答,新发送的SYN K 序列号是K。
第三次握手
客户在收到新SYN K, ACK J+1 后,也回应ACK K+1 以表示收到了,
然后两边就可以开始数据发送数据了
TCP三次握手过程中如果丢包了怎么办?
三、操作系统
说说线程和进程的区别
进程是程序运行和资源分配的基本单位,一个程序至少有一个进程,一个进程至少有一个线程。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存资源,减少切换次数,从而效率更高。
线程是进程的一个实体,**是cpu调度和分派的基本单位,是比程序更小的能独立运行的基本单位。**同一进程中的多个线程之间可以并发执行。
谁是CPU的调度单位?
答:线程。
(线程是CPU调度和分配的基本单位,一定要和 进程是操作系统进行资源分配(包括cpu、内存、磁盘IO等)的最小单位 区别清楚。)
在引入线程的系统中,线程是调度和分派的基本单位,而进程是拥有资源的基本单位。
四、JVM
讲讲JVM中的内存模型
主要分为五个部分,方法区,堆、java栈,本地方法栈、程序计数器。
如果循环调用一个对象,那么会对哪个部分的造成影响。
答:会对栈造成影响,会造成栈溢出。对对象的引用是放在栈中,而对象的具体值是放在堆中的。
谈谈你知道的垃圾回收机制
完全忘了,答不上来
jvm垃圾回收机制
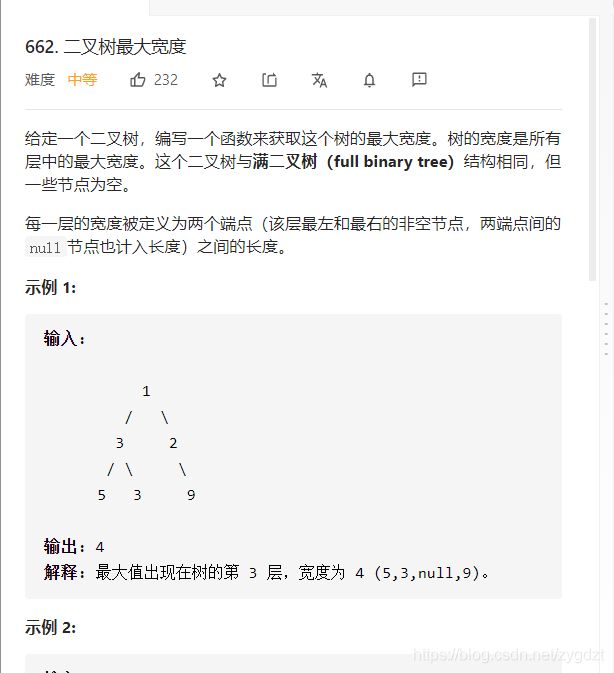
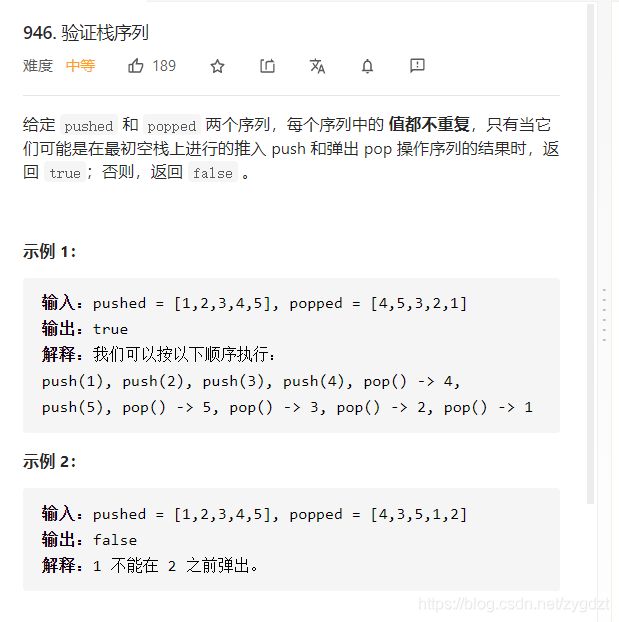
五、编程题:
直接贴上题目,题解大家自己自行去leetcode上面找吧。
反问环节
问了一下面试官,对我在技术方面有什么建议。
他说校招最看重的就是基础,对于科班出身的同学,一定要掌握好基础知识并且要增强自己的代码能力。
ok,以上就是这次面试的全部内容,后期如果还想起来别的,我还会继续补充的。希望大家面试都能有个好的结果,加油。