【CS231N笔记】P7 P8:训练神经网络
子豪兄YYDS
https://www.bilibili.com/video/BV1K7411W7So?p=7
https://www.bilibili.com/video/BV1K7411W7So?p=8
一、简介
神经网络的训练主要是包括三部分:固定性的设置、动态的训练以及评估。
固定性的设置包括激活函数的选择、预处理、权重初始化、正则化、梯度校验,这些内容在训练之前就可以确定好,在训练过程中不需要再关注这些内容。
动态的训练则包括验证集上的误差、参数的更新、超参数的寻找策略,这部分的内容在训练过程中会发生变化,所以需要在训练时进行处理。
评估则是在训练好后对模型的集成,比如说集成学习之类的。
二、激活函数
①Sigmoid激活函数
也称为挤压函数,因为这个函数可以将任何的数映射到0-1的范围内。这个激活函数可解释性好,可以类比神经细胞是否激活。但是也有三个问题,首先在输入特别小或者特别大的时候函数会出现饱和,同时也会出现梯度的消失,其次输出永远是正值,而且永远不会是0和1,这会导致更新权重时,一个神经元的所有权重要么都变大要么都变小。
具体来说,我们假设有一层的激活函数是下图的形式,这一神经元的上一层的所有神经元都是用的sigmoid激活函数。
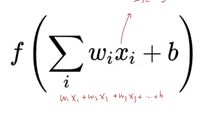
在计算梯度的时候,对这个神经元的参数来说前面的总体梯度都是一样的,而计算局部梯度时,假设对w1求偏导,那么得到的是x1,同理对wi求导得到的就是xi,而上一层采用的sigmoid函数会让所有的输出都是正数,也就是说xi都是正的,也就是说所有的偏导都是正数,局部梯度是同号的,那么全局梯度也是同号的,这会导致更新权重时所有的参数更新要么都变大要么都变小,单独摘出来两个参数画图的话可以得到下面的图:
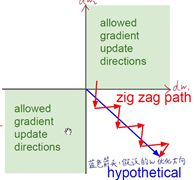
在这个图里面绿色的部分表示两个参数的更新方向,二者同增同减,只不过大小有区别,但如果更新方向是蓝色箭头所示的方向,那么整个参数就没有办法向着正确的方向更新,这个问题也称做zigzag问题。
最后,sigmoid函数由于使用了指数运算,所以会比较消耗计算资源。
②Tanh
翻译为双曲正切,这个激活函数和sigmoid很像,其实这两个激活函数可以通过缩放变换互相转换。不难看出双曲正切同样存在饱和问题,也就会带来极限情况下的梯度消失问题,但是好处输出空间关于0对称,有正有负,就不会产生zigzag问题。
③ReLU
翻译为修正线性单元,也会翻译为整流线性单元,因为这个函数将x<0的部分全部去掉了,相当于进行了一次整流。这个激活函数不会饱和,而且计算容易,几乎不占用计算资源,并且x>0的时候梯度能够得到保留,让网络的收敛速度快了很多。
但是缺点也很明显,当x<0的时候函数值恒为零,也就意味着梯度丢失,意味着一些神经元就是死的,虽然在神经网络中,但是因为输入值小于0,所以ReLU函数的结果是0,梯度也为0,因此永远不会更新。这个问题叫做dead ReLU,导致这个问题的原因主要有两个,一个是初始化不良,即我们随机初始化的时候随机的效果不太好,让输入加权求和之后的结果小于0,从而经过ReLU函数之后没法更新。另一个原因是学习率太大,导致修正的时候修正过大。解决方法是在初始化的时候在ReLU后面加一个正数的偏置项,让所有神经元至少有一个输出,之后再进行调整。
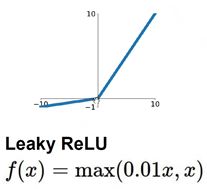
④Leaky ReLU
为了解决一般ReLU函数在x<0的时候没有梯度的问题而引进的一种改进方法,这种方法主要是修改了一下x<0的时候的表达式,加一个很小的系数,让这种情况下不一直为零,从而解决了梯度为0的问题。
⑤ELU
同样的修正ReLU还有ELU,同样是修改了x<0的情况,ELU将这部分换成了指数的表达形式,但是引入指数会导致计算量的增加。

⑥Maxout
这个激活函数有些奇怪,它是增加了k个神经元,也就是增加了k套权重,利用这新增的k套权重,计算出了k个输出值,选这k个中的最大值作为最终的输出值。
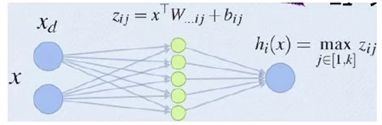
这种方法引入了新的神经元,改变了神经网络的结构,实际上是一种特殊的激活函数。
对于这些激活函数,使用ReLU时需要小心学习率过大带来的deadReLU问题,可以使用tanh但是不要寄予太大希望,不要在中间层轻易使用sigmoid函数。
三、数据预处理
数据预处理也称为特征工程,是十分重要的一部分,这个部分需要因地制宜,根据数据的特征和问题的内容来确定处理的方法。
常用的一种数据预处理的方法是数据的标准化,就是概率论里面将正态分布转换为标准正态分布的方法,减去均值再除以标准差,这样处理之后就可以得到服从标准正态分布的数据。

从图像里也可以看出,一开始的数据偏离原点而且分散不均匀,在减去均值之后,数据的分布就向中心位置靠拢了,再除以样本的标准差之后,数据就更加密集了,相比于原始数据,处理过后的数据更加密集而且分布也更加合理。
另一种方法叫做主成分分析,也叫做线性降维投影,选出原始数据中方差变化最大的方向作为第一主成分,对应的是协方差矩阵的主特征向量,之后选第一主成分的垂线方向作为第二主成分,对应协方差矩阵的次特征向量,按这两个方向投影,就可以更换数据的分布。
图中绿色的部分就是线性降维投影之后的结果,可以看见整个数据相当于转了转,让变化最大和变化最小的两个方向变成坐标轴的方向。蓝色的部分是除以标准差之后的结果,相当于又进行了一次处理,让分布更加的密集。
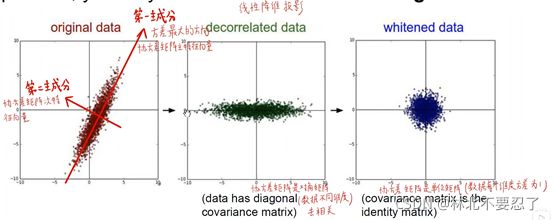
可以看出两次的调整都是将原本的数据调整到关于原点对称并且十分密集的程度,这种方法主要是为了降低损失函数对权重矩阵细小变化的敏感程度,当数据偏离原点而且十分分散的时候,对于权重矩阵的一点修改就可能导致损失函数产生很大的变化,采用数据的正则化,让数据移动到合适的位置,就可以降低敏感程度,从而在调整权重时可以适当调大学习率,也不会产生太大的波动。
四、权值初始化
权重初始化的主要目的,是为了让数据更好地分布,如果数据大量集中在一个部位,很可能导致梯度丢失,从而无法更新前面的权值。
权重可以通过梯度下降进行修正,但是初始化的结果可以影响到修正的花费时间,如果初始化结果很烂,那么修正到收敛耗费的时间也会很久。假设一个极限的情况,就是让同一层的所有的权重都为同一个常数,那么在前向传播和反向优化的过程中,所有节点的操作是完全一样的,这就相当于一层只有一个节点,就算有再多,输出的结果都是一样的,相当于只学习到了一个特制,也就是只有那么一个节点在工作。
在初始化时可以采用标准正态分布的方法,利用numpy里面的randn函数去产生一个符合输入输出的权重矩阵,这样的到的权重矩阵每个元素都符合标准正态分布,最后将权重矩阵同时乘以一个小数来进行一定程度的缩放。
在这种情况下,我们假设激活函数采用tanh,那么输出的结果也会根据前面的小数的变化而变化,当数比较小时,比如说取0.01,数据经过加权求和后会集中在0的附近,会因为取值为零在计算局部梯度的时候出现梯度丢失的现象,数比较大时,比如说取0.05,数据就集中在饱和的位置也就是±1处,会因为tanh函数的性质在计算全局梯度的时候出现梯度丢失。


这两张图正好是小数为0.01和0.05的时候的每一层的输出结果,对于前者,大量的输出趋向于0,这会导致在计算权重的局部梯度时,得到的局部梯度也就是上一层的输出会是0,这会导致梯度丢失,对于后者,大量的值趋向于饱和,这会导致计算全局梯度时结果为零进而导致梯度丢失。
可以看出,前面用于缩放的小数无论是过大还是过小都是不合适的,也就是说缩放需要进行,但是缩放到什么程度是个很重要的问题。为了解决这个问题,科学家引入了xavier方法。

这个方法是在随机生成的梯度矩阵上同时除以一个输入维度的开平方来表示缩放程度,而不是直接乘以一个人为指定的小数,也就是让初始化的权重根据输入的维度来变化,输入的维度很大,那就让权重矩阵缩小的多一些,反过来输入维度很小,权重矩阵缩小的就小一些。

可以看见经过处理之后,数据不再集中在0或者饱和点,而是很均匀地分布在-1到1之间,这样就避免了梯度丢失的问题。
如果将激活函数换成ReLU,那么结果也会发生变化,由于ReLU函数整流的特点,大量的负值的输出结果会变成0,这一点是ReLU作为激活函数不可避免的问题,但是从图里也可以看出越来越多的正值也在靠近0,这些数据都会导致导致梯度丢失的问题,所以这时候xavier就不管用了。为此引入了kaiming初始化。

kaiming初始化是乘以一个小数换为乘以2/Din的开根号。

更换xavier初始化之后,效果如下:

可以看出虽然大量负值依然被投射到了0的位置,但是正值并没有完全被投影到0,这对于ReLU就已经是很大的改进了。
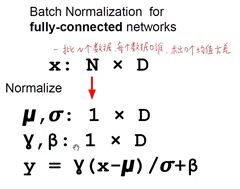
五、Batch Normalization
在实际的模型训练中,我们更希望每一层结果是均匀地分布在0周围,而不是全集中在一个部分,也就是希望数据满足标准正态分布,一种方法是强行正则化,也就叫batch normalization,通过减去期望除以标准差来构造标准正态分布。
这里利用到了前面的mini batch的思想,每个batch里面有N个D维的特征向量,这些向量可以拼出来一个N×D的矩阵,讲这个矩阵的每一列都进行标准正态分布的处理,得到的就是强行处理后的特征矩阵。

但有时候这种强行操作的效果并不好,因此又引入了两个参数γβ,让强行处理后的结果再进行处理:
![]()
这个是训练阶段的batch normalization,也就是让对每个batch进行处理。而在测试阶段,用训练时的总均值和总方差去代替minibatch的均值和方差,也就是用全部数据的均值和方差去代替训练阶段每个batch的均值方差。
采用这种batch normalization的方法,主要目的是为了把数据拉平,让数据不要集中在一起,从而让梯度更好地暴露出来。
对于这个例子,一个batch中有N个D维向量,组成了一个N×D的矩阵,这个矩阵经过计算,会得到D个均值和方差,也就是数据在每一维上的均值和方差,之后在每一维度上学得一个γβ,也就是学习到D个γβ,最终组合成上图所示的样子。

而在卷积神经网络中,每个batch实际上是N个图片,用C个卷积核生成C个高H宽W的特征图,在进行batch normalization时同样道理也会学到C个均值方差,这个时候的均值方差代表的是每个特征图的均值方差,而不再是单独一个维度上的均值方差,同理也会在每个特征图上学得一个γβ,最后组成上图的形式。
Batch normalization一般单独拿出来作为一层,叫做BN层,一般放在非线性层之前,采用BN层,主要作用是将数据分开,从而可以加快收敛、改善梯度、降低对初始化的敏感程度、一定程度上还有正则化的作用,但是需要注意训练和测试的时候使用的均值和方差是不同的。但是需要注意训练过程和测试过程的均值和方差是不同的。

除此之外其实还有很多种的normalization:
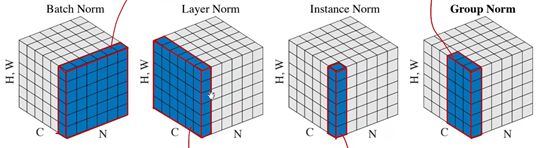
上面这张图是将特征图的长宽压缩到了一个纬度里面,第一个图表示的是BN,其中的红色区域表示的是mini batch中N个图片用同样的卷积核卷积特征图,对这些特征图计算均值方差从而完成batch normalization。第二个图表示的是LN,图中的红色区域表示mini batch中第一个图片的全部卷积核计算得到的特征图,对这些特征图计算均值方差来完成normalization,也就是用每一张图片产生的全部特征图来normalization。第三张图表示的是IN,红色区域表示的是mini batch中一张图的一个特征图,单独计算这个图的方差均值再进行normalization,也就是一个特征图一个操作。最后一个图表示的是GN,其中红色区域是一个图片的某些卷积核产生的特征图,用这些特征图计算均值方差来进行normalization。
六、梯度下降优化器
使用传统的随机梯度下降的时候,有时会在梯度较大的方向上发生震荡,就像下面图里这样,这种情况下减小学习率并不会带来特别好的解决效果,因为减小了学习率会让两个方向的分量同时且同规模减小,从而产生不了好的效果。
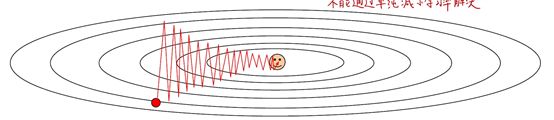
另外在高维空间中会存在局部最优点和鞍点,一旦陷入了局部最优点,按照梯度下降法的内容是无法离开的,会被困在局部最优点。
对于最基本的随机梯度下降,我们可以看作是一个人在一步一步地走路,注意一定是一步一步前进,每走一步就停下,然后根据当前的梯度最大的方向确定下一步该往哪里走。这种思路是不考虑之前的移动方向对接下来移动的影响,因为我们是一步一步走的,每次都完全停下来。
一种改进策略就是在SGD随机梯度下降的基础上增加动量。首先初始化一个动量为0,依然计算梯度方向,然后同时考虑动量和梯度方向作为更新的方向。

这是加动量之后的计算方法,可以看出,现在移动的方向就变成了vx,而vx不仅考虑了梯度方向,还加上了一个rho控制的动量方向,根据rho参数的大小,对vx的影响也是不一样的,这个时候整个更新就像是一个人跑步下山,必然会根据梯度的方向跑,但是还会受到自身惯性带来的影响。
但是这种考虑上一个时刻方向的方式也会带来很明显的缺点,就是会出现惯性问题,会到达原本不该到达的地方,只有冲过了才能反向回来。这带来的明显问题就是收敛时间的增加,会让到达最小值的时间增加。
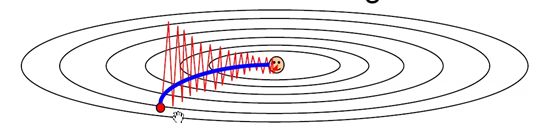
可以看见增加了动量之后,更新的方向就不会出现单独SGD时的迈步过大的问题。动量在这里起到了一个平均、平滑的作用。
基于动量的方法,又延伸出了一种预知的方法,完全基于梯度的更新策略实际上是向着速度和梯度的矢量和方向去移动,而基于预知的方法考虑的是速度和下一个时刻梯度的矢量和方向。
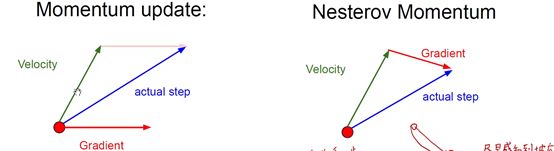
这种基于预知的梯度的名字叫Nesterov Momentum,简写是NAG,翻译一下的话前面这个词实在是翻译不出来,有道显示是一个俄语单词,这里干脆就叫毛子动量。毛子动量主要是更改了一般动量的梯度,这种方法属于向前看一步,计算梯度的位置不是当前所在的位置,而是按照当前速度方向,下一个时刻所在的位置的梯度,相当于预测了下一个时刻的梯度。
采用这种方式,主要是为了改善基于动量的方法中冲过头的问题,利用毛子方法,可以提前感知到到达了梯度小的位置,从而早点刹车,就不会冲过头了。

从代码可以看出,对比只考虑动量的方法,在更新方向时梯度的部分变成了当前时刻xt加上当前时刻的速度方向乘以控制参数,这样做相当于计算了下一个时刻的梯度,对应下面的图示:

可以看见,在xt点的时候,速度方向是绿色的方向,红色的是下一个时刻的梯度方向,利用这两个方向,合成出的是紫色的方向,也就是移动的方向,在这个方向上移动,得到的是下一个时刻的位置xt+1,重复这个过程直到到达极小值点。
上面的两种方法都是基于动量的优化策略,还有一种优化策略是增加惩罚项,这种方法叫做AdaGrada。因为一般的SGD是在梯度较大的地方出现震荡,那么按照这个思路,在梯度大的地方增加惩罚项,让这个时候的更新值变小,就可以防止迈步过大的问题。

可以看见计算梯度的部分并没有产生变化,变化的是后面的惩罚项,也就是分母的部分,这个部分是对所有之前位置梯度的平方的求和,也就是说之前到达的点的梯度越大,乘法也就越大,更新的值也就越小,从而防止出现震荡。
但是惩罚项也会越来越大,到了最后会导致每次都迈步很小,几乎没有更新,也就是长时间后更新量会衰减到0。
为了解决这个问题,又引入了RMSProp优化器,这个优化器也叫做削弱的AdaGrad
,它本质上还是增加惩罚项,但惩罚项变了,变成下面的格式:
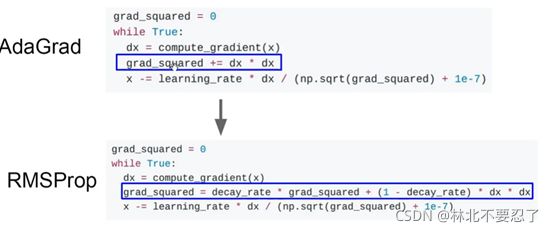
它将累加的方法换了,增加了一个衰减量,每次综合考虑这次的更新和前面的累积
,从而防止长时间的累积带来的影响。
将这两个思路融合在一起,也就是同时考虑动量和惩罚项,得到的就是Adam算法:
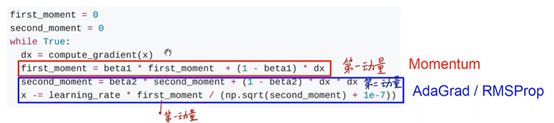
第一动量和前面的动量,而第二动量是利用第一动量经过惩罚项处理得到的动量,用这个动量去更新位置,得到的就是新的位置。
对于这个算法,上面的式子中可以看出,两个动量初始值都是0,这意味着需要经过几轮更新动量才会到达一个比较大的程度,或者说是能够用于更新的程度。为了加快这个过程,在一开始就有一个比较大的值,我们增加了一个偏差处理。

增加了偏差处理之后可以看到,参与更新的量由动量变成了偏差,而偏差在计算过程中兼顾了动量和轮次,所以能够在轮次较少的时候起一个扩大的作用,从而避免了一开始移动过小的现象。
七、学习率
学习率也叫做步长,可以看作是训练过程中向着目标方向移动的距离,这个学习率不能过大也不能过小,过大了会导致震荡现象,过小了虽然可以收敛但是速度会很慢,需要让学习率在一个正确的范围内。
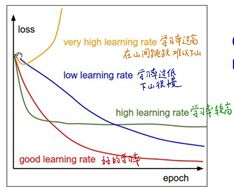
其实学习率的设置不一定要是一个固定值,学习率完全可以是一个变化值,比如说在刚开始的时候设置一个稍微大一点的学习率,随着训练的推进,换用更小的学习率从而一点点逼近最优值。
在ResNet中设置的就是学习率周期性折减,每训练30轮学习率就乘以0.1。
也可以用余弦形式来减小学习率,公式如下:
随着训练轮次的增加,cos值不断减小,从而让学习率也不断减小。
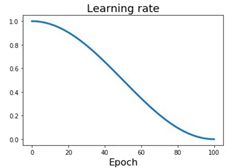
也可以使用各种函数的方法来降低学习率:
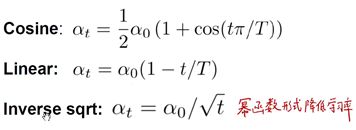
其实大多数的学习率设定都是先大后小,刚开始训练时大步向前,快速向正确方向前进,后期换成小碎步,一点点逼近更加优秀的点。
八、二维优化
到目前为止前面讲的全都是一阶的优化算法,使用的随机梯度下降或者说各种各样的优化方法,用到的梯度本质上都是一阶导数。这种优化的思路实际上是将损失函数在某处线性化,用切线方向的变化代替本身的变化,从而让点向着损失函数变小的方向去移动。
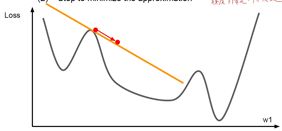
但实际上我们可以结合二阶导数去更好地近似,也就是使用二阶优化算法。
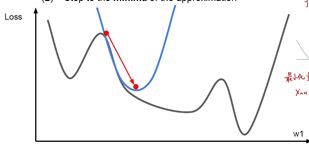
使用二阶优化算法的灵魂在于使用牛顿法,要求函数的最值,可以求导数为0的点,这个点对应的值至少也是个极值,也就是说要最小化函数值,就找导函数等于零的点,也就是方程导函数等于0的根,这个时候就会用到二阶导数。
关于牛顿法,之前整理的放在这里:
在这种方法下,就不需要设置学习率,每次的更新都是直接计算得出来的,并不是向梯度下降法那样向着一个方向移动一段距离。梯度下降属于典型的一阶收敛,只考虑当前坡度最大的方向,而牛顿法属于二阶优化,它还考虑了走一步之后坡度是否会变得更大。虽然二阶优化效果好,但是当参数过多的时候,海森矩阵的逆矩阵运算会很困难,所以一般在深度学习中不使用二阶优化算法。
九、正则化
防止过拟合是训练过程中很重要的一个步骤,出现过拟合之后会导致在训练集上的正确率提高,但是在测试集上的正确率反而会下降,也就是学到了太多没有用的东西。
过拟合是随着训练推进而产生的,所以一种解决办法是提前结束训练,在还没有出现过拟合之前就停止。此外,还可以使用集成学习的方法,训练多个模型最后投票决定结果,从而防止过拟合的发生。
前面提到过的正则化项也可以用来防止过拟合,也就是在损失函数后面加一个正则化项,用来惩罚结果过于依赖较少依据的模型。
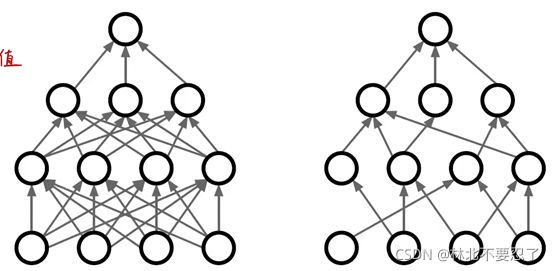
还有一种正则化的方法是Dropout,也就是训练过程中每一步随机杀死一部分神经元,让其前向传播和反向传播都停止,相当于没有这个神经元,在下一轮训练中这部分神经元复活,重新确定哪些被杀死。
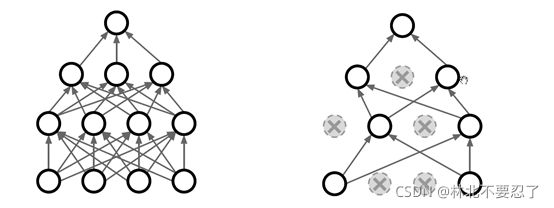
Dropout可以防止过拟合,主要是因为它打破了神经元直接的联合适应性,拿之前看无人驾驶原理与实践的时候的例子,把许多车的图片送入网络训练,如果里面大量的图片都是黑色的汽车,那么网络内部的神经元可能会产生一种依赖,比如说有四个轮子且是黑色的才是车,但从人的角度看,黑色并不是判断车的依据,这只是数据不完善导致的错误的依赖。而Dropout就可以打破这一点,通过随机掐死神经元,让一部分神经元可以独当一面,从而防止过拟合。
还有一种解释是Dropout起到了模型集成的作用,每次掐死神经元的概率是二分之一,相当于每个神经元都可以等概率地存在两种状态,那么对于有N个神经元的网络,就会有二的N次方种模型,而这么多模型被集成在了一起,所以过拟合就可以被防止。
只有在训练时才会采用Dropout,而在测试时我们希望所有的神经元都可以参与运算,所以并不使用Dropout。
还有数据增强方向的解释以及知识丢失方面的解释,都可以用来解释Dropout防止过拟合的作用。数据增强是说,我们随机杀死一部分神经元,相当于一部分神经元的输入输出为0,而世界上数据那么多,总有一个数据可以让输入后的处理和杀死神经元后的网络一样,所以我们杀死神经元,相当于增加了许多没有的数据,从而避免过拟合。而知识丢失就更容易解释了,过拟合是学习到了过多的知识,那么我随机丢弃一部分,不就相当于避免了过拟合。
还有一种和Dropout很像的防止过拟合的方法叫做Drop Connect,是随机切断神经元的输入,训练过程随机杀死输入,但是不杀死神经元,依然让神经元有输出。
十、超参数的选择
首先校验初始的损失函数值,之后再小数据集上尝试看会不会过拟合,如果小数据集上能够过拟合,那么在大的数据集上也会有比较好的效果,之后尝试学习率,一点点减小学习率,并且及时观察损失函数的图线,防止过拟合或者陷入局部最小值。