Node.js 应用开发详解01 事件循环:高性能到底是如何做到的?
在介绍 Node.js 的应用之前,我们先来讲解下 Node.js 中最基础也是最核心的部分:事件循环的原理。这一部分在面试过程中是必考的点,然而大家在网络上查找到的知识或多或少有些出入,会被误导。
所以本讲就基于 Node.js 10+ 版本,为你讲解事件循环的原理,不过要注意这个事件循环原理和浏览器的原理是不同的,Node.js 10+ 版本后虽然在运行结果上与浏览器一致,但是两者在原理上一个是基于浏览器,一个是基于 libuv 库。浏览器核心的是宏任务和微任务,而在 Node.js 还有阶段性任务执行阶段。
Node.js 事件循环
事件循环通俗来说就是一个无限的 while 循环。现在假设你对这个 while 循环什么都不了解,你一定会有以下疑问。
-
谁来启动这个循环过程,循环条件是什么?
-
循环的是什么任务呢?
-
循环的任务是否存在优先级概念?
-
什么进程或者线程来执行这个循环?
-
无限循环有没有终点?
带着这些问题,我们先来看看 Node.js 官网提供的事件循环原理图。
Node.js 循环原理
图 1 为 Node.js 官网的事件循环原理的核心流程图。

图 1 事件循环原理流程图
可以看到,这一流程包含 6 个阶段,每个阶段代表的含义如下所示。
(1)timers:本阶段执行已经被 setTimeout() 和 setInterval() 调度的回调函数,简单理解就是由这两个函数启动的回调函数。
(2)pending callbacks:本阶段执行某些系统操作(如 TCP 错误类型)的回调函数。
(3)idle、prepare:仅系统内部使用,你只需要知道有这 2 个阶段就可以。
(4)poll:检索新的 I/O 事件,执行与 I/O 相关的回调,其他情况 Node.js 将在适当的时候在此阻塞。这也是最复杂的一个阶段,所有的事件循环以及回调处理都在这个阶段执行,接下来会详细分析这个过程。
(5)check:setImmediate() 回调函数在这里执行,setImmediate 并不是立马执行,而是当事件循环 poll 中没有新的事件处理时就执行该部分,如下代码所示:
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
}, 0);
setImmediate( () => {
console.log('setImmediate 1');
});
/// 将会在 poll 阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('poll callback');
});
// 首次事件循环执行
console.log('2');
在这一代码中有一个非常奇特的地方,就是 setImmediate 会在 setTimeout 之后输出。有以下几点原因:
-
setTimeout 如果不设置时间或者设置时间为 0,则会默认为 1ms;
-
主流程执行完成后,超过 1ms 时,会将 setTimeout 回调函数逻辑插入到待执行回调函数poll 队列中;
-
由于当前 poll 队列中存在可执行回调函数,因此需要先执行完,待完全执行完成后,才会执行check:setImmediate。
因此这也验证了这句话,先执行回调函数,再执行 setImmediate。
(6)close callbacks:执行一些关闭的回调函数,如 socket.on('close', ...)。
以上就是循环原理的 6 个过程,针对上面的点,我们再来解答上面提出的 5 个疑问。
运行起点
从图 1 中我们可以看出事件循环的起点是 timers,如下代码所示:
setTimeout(() => {
console.log('1');
}, 0);
console.log('2')
在代码 setTimeout 中的回调函数就是新一轮事件循环的起点,看到这里有很多同学会提出非常合理的疑问:“为什么会先输出 2 然后输出 1,不是说 timer 的回调函数是运行起点吗?”
这里有一个非常关键点,当 Node.js 启动后,会初始化事件循环,处理已提供的输入脚本,它可能会先调用一些异步的 API、调度定时器,或者 process.nextTick(),然后再开始处理事件循环。因此可以这样理解,Node.js 进程启动后,就发起了一个新的事件循环,也就是事件循环的起点。
总结来说,Node.js 事件循环的发起点有 4 个:
-
Node.js 启动后;
-
setTimeout 回调函数;
-
setInterval 回调函数;
-
也可能是一次 I/O 后的回调函数。
以上就解释了我们上面提到的第 1 个问题。
Node.js 事件循环
在了解谁发起的事件循环后,我们再来回答第 2 个问题,即循环的是什么任务。在上面的核心流程中真正需要关注循环执行的就是 poll 这个过程。在 poll 过程中,主要处理的是异步 I/O 的回调函数,以及其他几乎所有的回调函数,异步 I/O 又分为网络 I/O 和文件 I/O。这是我们常见的代码逻辑部分的异步回调逻辑。
事件循环的主要包含微任务和宏任务。具体是怎么进行循环的呢?如图 2 所示。
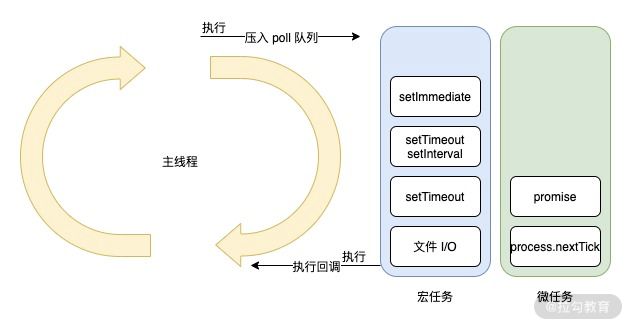
图 2 事件循环过程
在解释上图之前,我们先来解释下两个概念,微任务和宏任务。
微任务:在 Node.js 中微任务包含 2 种——process.nextTick 和 Promise。微任务在事件循环中优先级是最高的,因此在同一个事件循环中有其他任务存在时,优先执行微任务队列。并且process.nextTick 和 Promise 也存在优先级,process.nextTick 高于 Promise。
宏任务:在 Node.js 中宏任务包含 4 种——setTimeout、setInterval、setImmediate 和 I/O。宏任务在微任务执行之后执行,因此在同一个事件循环周期内,如果既存在微任务队列又存在宏任务队列,那么优先将微任务队列清空,再执行宏任务队列。这也解释了我们前面提到的第 3 个问题,事件循环中的事件类型是存在优先级。
在图 2 的左侧,我们可以看到有一个核心的主线程,它的执行阶段主要处理三个核心逻辑。
-
同步代码。
-
将异步任务插入到微任务队列或者宏任务队列中。
-
执行微任务或者宏任务的回调函数。在主线程处理回调函数的同时,也需要判断是否插入微任务和宏任务。根据优先级,先判断微任务队列是否存在任务,存在则先执行微任务,不存在则判断在宏任务队列是否有任务,有则执行。
如果微任务和宏任务都只有一层时,那么看起来是比较简单的,比如下面的例子:
const fs = require('fs');
// 首次事件循环执行
console.log('start');
/// 将会在新的事件循环中的阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
setTimeout(() => { // 新的事件循环的起点
console.log('setTimeout');
}, 0);
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('Promise callback');
});
/// 执行 process.nextTick
process.nextTick(() => {
console.log('nextTick callback');
});
// 首次事件循环执行
console.log('end');
根据上面介绍的执行过程,我们来分析下上面代码的执行过程:
-
第一个事件循环主线程发起,因此先执行同步代码,所以先输出 start,然后输出 end;
-
再从上往下分析,遇到微任务,插入微任务队列,遇到宏任务,插入宏任务队列,分析完成后,微任务队列包含:Promise.resolve 和 process.nextTick,宏任务队列包含:fs.readFile 和 setTimeout;
-
先执行微任务队列,但是根据优先级,先执行 process.nextTick 再执行 Promise.resolve,所以先输出 nextTick callback 再输出 Promise callback;
-
再执行宏任务队列,根据宏任务插入先后顺序执行 setTimeout 再执行 fs.readFile,这里需要注意,先执行 setTimeout 由于其回调时间较短,因此回调也先执行,并非是 setTimeout 先执行所以才先执行回调函数,但是它执行需要时间肯定大于 1ms,所以虽然 fs.readFile 先于 setTimeout 执行,但是 setTimeout 执行更快,所以先输出 setTimeout ,最后输出 read file success。
根据上面的分析,我们可以得到如下的执行结果:
start
end
nextTick callback
Promise callback
setTimeout
read file success
但是当微任务和宏任务又产生新的微任务和宏任务时,又应该如何处理呢?如下代码所示:
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file sync success');
});
}, 0);
/// 回调将会在新的事件循环之前
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('poll callback');
});
// 首次事件循环执行
console.log('2');
在上面代码中,有 2 个宏任务和 1 个微任务,宏任务是 setTimeout 和 fs.readFile,微任务是 Promise.resolve。
-
整个过程优先执行主线程的第一个事件循环过程,所以先执行同步逻辑,先输出 2。
-
接下来执行微任务,输出 poll callback。
-
再执行宏任务中的 fs.readFile 和 setTimeout,由于 fs.readFile 优先级高,先执行 fs.readFile。但是处理时间长于 1ms,因此会先执行 setTimeout 的回调函数,输出 1。这个阶段在执行过程中又会产生新的宏任务 fs.readFile,因此又将该 fs.readFile 插入宏任务队列。
-
最后由于只剩下宏任务了 fs.readFile,因此执行该宏任务,并等待处理完成后的回调,输出 read file sync success。
根据上面的分析,我们可以得出最后的执行结果,如下所示:
2
poll callback
1
read file success
read file sync success
在上面的例子中,我们来思考一个问题,主线程是否会被阻塞,具体我们来看一个代码例子:
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
sleep(10000)
console.log('sleep 10s');
}, 0);
/// 将会在 poll 阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
console.log('2');
/// 函数实现,参数 n 单位 毫秒 ;
function sleep ( n ) {
var start = new Date().getTime() ;
while ( true ) {
if ( new Date().getTime() - start > n ) {
// 使用 break 实现;
break;
}
}
}
我们在 setTimeout 中增加了一个阻塞逻辑,这个阻塞逻辑的现象是,只有等待当次事件循环结束后,才会执行 fs.readFile 回调函数。这里会发现 fs.readFile 其实已经处理完了,并且通知回调到了主线程,但是由于主线程在处理回调时被阻塞了,导致无法处理 fs.readFile 的回调。因此可以得出一个结论,主线程会因为回调函数的执行而被阻塞,这也符合图 2 中的执行流程图。
如果把上面代码中 setTimeout 的时间修改为 10 ms,你将会优先看到 fs.readFile 的回调函数,因为 fs.readFile 执行完成了,并且还未启动下一个事件循环,修改的代码如下:
setTimeout(() => { // 新的事件循环的起点
console.log('1');
sleep(10000)
console.log('sleep 10s');
}, 10);
最后我们再来回答第 5 个问题,当所有的微任务和宏任务都清空的时候,虽然当前没有任务可执行了,但是也并不能代表循环结束了。因为可能存在当前还未回调的异步 I/O,所以这个循环是没有终点的,只要进程在,并且有新的任务存在,就会去执行。
实践分析
了解了整个原理流程,我们再来实践验证下 Node.js 的事件驱动,以及 I/O 到底有什么效果和为什么能提高并发处理能力。我们的实验分别从同步和异步的代码性能分析对比,从而得出两者的差异。
Node.js 不善于处理 CPU 密集型的业务,就会导致性能问题,如果要实现一个耗时 CPU 的计算逻辑,处理方法有 2 种:
-
直接在主业务流程中处理;
-
通过网络异步 I/O 给其他进程处理。
接下来,我们用 2 种方法分别计算从 0 到 1000000000 之间的和,然后对比下各自的效果。
主流程执行
为了效果,我们把两部分计算分开,这样能更好地形成对比,没有异步驱动计算的话,只能同步的去执行两个函数 startCount 和 nextCount,然后将两部分计算结果相加。
const http = require('http');
/**
*
* 创建 http 服务,简单返回
*/
const server = http.createServer((req, res) => {
res.write(`${startCount() + nextCount()}`);
res.end();
});
/**
* 从 0 计算到 500000000 的和
*/
function startCount() {
let sum = 0;
for(let i=0; i<500000000; i++){
sum = sum + i;
}
return sum;
}
/**
* 从 500000000 计算到 1000000000 之间的和
*/
function nextCount() {
let sum = 0;
for(let i=500000000; i<1000000000; i++){
sum = sum + i;
}
return sum;
}
/**
*
* 启动服务
*/
server.listen(4000, () => {
console.log('server start http://127.0.0.1:4000');
});
接下来使用下面命令启动该服务:
node sync.js
启动成功后,再在另外一个命令行窗口执行如下命令,查看响应时间,运行命令如下:
time curl http://127.0.0.1:4000
运行完成以后可以看到如下的结果:
499999999075959400
real 0m1.100s
user 0m0.004s
sys 0m0.005s
启动第一行是计算结果,第二行是执行时长。经过多次运行,其结果基本相近,都在 1.1s 左右。接下来我们利用 Node.js 异步事件循环的方式来优化这部分计算方式。
异步网络 I/O
异步网络 I/O 对比主流程执行,优化的思想是将上面的两个计算函数 startCount 和 nextCount 分别交给其他两个进程来处理,然后主进程应用异步网络 I/O 的方式来调用执行。
我们先看下主流程逻辑,如下代码所示:
const http = require('http');
const rp = require('request-promise');
/**
*
* 创建 http 服务,简单返回
*/
const server = http.createServer((req, res) => {
Promise.all([startCount(), nextCount()]).then((values) => {
let sum = values.reduce(function(prev, curr, idx, arr){
return parseInt(prev) + parseInt(curr);
})
res.write(`${sum}`);
res.end();
})
});
/**
* 从 0 计算到 500000000 的和
*/
async function startCount() {
return await rp.get('http://127.0.0.1:5000');
}
/**
* 从 500000000 计算到 1000000000 之间的和
*/
async function nextCount() {
return await rp.get('http://127.0.0.1:6000');
}
/**
*
* 启动服务
*/
server.listen(4000, () => {
console.log('server start http://127.0.0.1:4000');
});
代码中使用到了 Promise.all 来异步执行两个函数 startCount 和 nextCount,待 2 个异步执行结果返回后再计算求和。其中两个函数 startCount 和 nextCount 中的 rp.get 地址分别是:
http://127.0.0.1:5000
http://127.0.0.1:6000
其实是两个新的进程分别计算两个求和的逻辑,具体以 5000 端口的逻辑为例看下,代码如下:
const http = require('http');
/**
*
* 创建 http 服务,简单返回
*/
const server = http.createServer((req, res) => {
let sum = 0;
for(let i=0; i<500000000; i++){
sum = sum + i;
}
res.write(`${sum}`);
res.end();
});
/**
*
* 启动服务
*/
server.listen(5000, () => {
console.log('server start http://127.0.0.1:5000');
});
接下来我们分别打开三个命令行窗口,使用以下命令分别启动三个服务:
node startServer.js
node nextServer.js
node async.js
启动成功后,再运行如下命令,查看执行时间:
time curl http://127.0.0.1:4000
运行成功后,你可以看到如下结果:
499999999075959400
real 0m0.575s
user 0m0.004s
sys 0m0.005s
结果还是一致的,但是运行时间缩减了一半,大大地提升了执行效率。
响应分析
两个服务的执行时间相差一半,因为异步网络 I/O 充分利用了 Node.js 的异步事件驱动能力,将耗时 CPU 计算逻辑给到其他进程来处理,而无须等待耗时 CPU 计算,可以直接处理其他请求或者其他部分逻辑。第一种同步执行的方式就无法去处理其逻辑,导致性能受到影响。
如果使用压测还可以使对比效果更加明显,我将在第 12 讲为你详细介绍关于压测使用以及分析过程。
单线程/多线程
我相信在面试过程中,面试官经常会问这个问题“Node.js 是单线程的还是多线程的”。
学完上面的内容后,你就可以回答了。
主线程是单线程执行的,但是 Node.js 存在多线程执行,多线程包括 setTimeout 和异步 I/O 事件。其实 Node.js 还存在其他的线程,包括垃圾回收、内存优化等。
这里也可以解释我们前面提到的第 4 个问题,主要还是主线程来循环遍历当前事件。
总结
本讲主要介绍了 Node.js 事件循环机制和原理,然后通过实践对比了两种情况下的性能耗时,并且说明了异步事件循环驱动的好处。学完本讲以后,你就可以掌握 Node.js 的事件循环原理,也可以掌握如何充分利用 Node.js 的事件循环原理的优势。
你可以自行思考下这个问题:浏览器的事件循环原理和 Node.js 事件循环原理的区别以及联系有哪些点,欢迎你把答案写在评论区。
本讲就到这了,下一讲我会为你介绍服务端研发的 RPC 服务的知识点。
精选评论
*猛:
平时都是在用java写后端,一直好奇node怎么做后端
*聪:
老师,有几个问题想请教一下:1. Node.js 官网的事件循环原理的核心流程图中,执行的顺序是从上到下吗?2. 文中提到 【timers:本阶段执行已经被 setTimeout() 和 setInterval() 调度的回调函数】和【poll:检索新的 I/O 事件,执行与 I/O 相关的回调,其他情况 Node.js 将在适当的时候在此阻塞。所有的事件循环以及回调处理都在这个阶段执行】这两个有冲突吗?setTimeout的回调是放在timers中还是放在poll里?3.文中【由于当前 poll 队列中存在可执行回调函数,因此需要先执行完,待完全执行完成后,才会执行check:setImmediate】,我试着运行了一下,setImmediate 1在read file success之前输出了,这是为啥?4.【在 Node.js 中宏任务包含 4 种——setTimeout、setInterval、setImmediate 和 I/O】,宏任务之间有优先级吗?5.文中【根据优先级先执行 fs.readFile 再执行 setTimeout,但是这里需要注意,即使先执行 fs.readFile,但是它执行需要时间肯定大于 1ms,所以虽然 fs.readFile 先于 setTimeout 执行,但是 setTimeout 执行更快,所以先输出 setTimeout ,最后输出 read file success】这里没太大理解,fs.readFile不是先执行吗,怎么不会阻塞setTimeout?是不是成功读取完文件(读文件是另外一个线程执行)后回调才加入宏任务队列,而读文件这个过程超过了1ms,所以读取完文件后回调是在setTimeout回调添加到宏任务队列后再加入的?
讲师回复:
1. 是的。
- 不冲突,前者是 timers 相关的回调事件,后者是除了 timers 几乎所有的事件循环事件,这里使用几乎所有的可能会合适些,你提的问题还是很好的。
- 你是运行的哪个例子呢,这里有个概念需要注意,就是当前没有可执行的事件任务,并不代表说 setImmediate 需要等所有的异步事件都执行完成,而是在当前事件任务中没有其他事件任务可执行时调用。
- 在我之前有份资料里面是有说明IO 和 timers的优先级,但是经过大家提问,我重新去查了些资料,并且进行了一些测试,严格意义上没有优先级的概念,但是 timers 和 IO 肯定优先与 setImmediate,如果你有一些看法也可以和我交流,原文我也进行了一些修改免得误导大家。
- 我在重新举个例子解释一下,我们首先有一个主线程,然后 IO 是有独立线程处理的,timers 是系统线程处理,比如说,我主线程先告诉 IO 线程,我需要处理这个事情,然后交给 IO 线程去处理了,我主线程就不管了,接下来我主线程发现 timers 事件,我告诉 timers 要处理这个事件了,然后我主线程就等待他们线程执行完成。这时候 timers 先执行完成了,那我主线程就开始处理这个回调了,接下来 IO 线程执行完成了,回调给主线程,那我最后再执行 IO 线程的回调,不知道这样举例能否理解。
**胜:
老师,nodejs 多线程包括 setTimeout 和异步 I/O 事件,那在运行时,nodejs有线程数量限制吗
讲师回复:
setTimeout 我是没有遇到过限制。但是 I/O 是会的,和系统有关因为 I/O 是会占用句柄的,假设文件句柄超出限制,那么肯定是无法启动新的线程来处理的。有些 I/O 是网络的,那么和系统的网络模块也是相关,有些是文件 I/O 那跟文件 I/O 限制相关。但是这些都是来自于系统,而不是 Node.js 。
**6312:
我注意到文中写的setTimeout如果没有设置时间,会默认为1ms,这个在node里面是确定的吗? 我记得在浏览器中这种情况好像需要根据具体浏览器内核实现为准,大部分为4ms。
讲师回复:
嗯,默认时1ms,可以查看下官方文档,里面有明确的说明。
http://nodejs.cn/api/timers.html#timers_settimeout_callback_delay_args
**南:
我在测试主流程执行和异步执行的时候发现,使用给的例子去测试发现主流程的耗时要比异步耗时短,这是什么原因呢
讲师回复:
有使用 time curl 的方式吗,你两个的启动命令和测试命令评论发我下,以及具体运行结果,我看看是哪里的问题影响到的。
*舒:
但在node11之后,两者就基本没什么区别了
讲师回复:
在运行流程上区别是不大的
**GUNDAM:
老师演示的异步处理 node.js中遇到密集运算场景 除了可以自己分拆异步请求 在大的系统中 是否可以借助rpc通信调用其他语言计算 算完将结果返回给node 最终返回给用户
讲师回复:
可以的,这里我只是为了演示。其实主要目的是将复杂计算交由其他进程处理,从而不会影响到 Node.js 当前进程的主线程。
**1505:
感觉浏览器和node的事件循环机制是一样的,主线程、微任务、宏任务执行逻辑都没有差异,区别在于浏览器中没有process.nextTick()和I/O
讲师回复:
是的呢,主流程基本没有差异,你说的区别也是非常正确的。
**峰:
node是基于libuv,不是libev吧?
讲师回复:
确实,这里有误,我让编辑修改下,libev 兼容 windows 不太友好,转为了 libuv。感谢提醒。
*浩:
当setTimeout之前有特别耗时的任务时,比如setTimeout时间到了前面的任务还没处理完,setTimeout的回调会有延迟吗
讲师回复:
会的,只要主线程被block住,那么settimeout无法及时处理,就很可能导致无法处理其回调。因此说settimeout并不是严格准时的,其次还可以利用settimeout来判断主线程是否被block,如果setimeout 延迟执行的时间-真实执行的时长 > 0 时则代表主线程有压力。
*振:
while 模拟 sleep 太耗 cpu 了,有其他办法吗
讲师回复:
你意思是要 await 这样的功能吗?等待上一段异步逻辑执行结束这种吗?如果是话,await/async 是可以做到的呢。
*舒:
浏览器和node环境下,microtask任务队列的执行时机不同。node端在事件循环的各个阶段之间执行;浏览器端,microtask在事件循环的macrotask执行完之后执行
**喝王老吉:
老师的例子非常直观的讲解了事件循环的原理那么浏览器的和Node的有什么区别呢
讲师回复:
当前阶段的浏览器和Node.js的宏任务和微任务执行已经一致了,因此在事件循环方面是没有差异了,有一篇说两者差异的是基于之前的版本的,这里提出这个问题也是希望大家自行能够去尝试验证以下。
*亮:
多个定时器圈套,跟多个读写任务,是如何工作的?本节中只是提到一个简单的例子
讲师回复:
如果有场景的话,可以在 GitHub 上留言以下,给份示例代码,我可以帮你一起解析下。