2019独角兽企业重金招聘Python工程师标准>>> 
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 Hive 的 10 倍以上。Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品,单个 Presto 查询可合并来自多个数据源的数据进行统一分析。Presto 的目标是在可期望的响应时间内返回查询结果,Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。
目录:
- presto架构
- presto低延迟原理
- presto存储插件
- presto执行过程
- presto引擎对比
Presto架构
- Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
- 一个Coordinator节点
- 一个Discovery Server节点
- 多个Worker节点
- Coordinator: 负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
- Discovery Server: 通常内嵌于Coordinator节点中
- Worker节点: 负责实际执行查询任务,负责与HDFS交互读取数据
- Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息
- 更形象架构图如下:
Presto低延迟原理
- 完全基于内存的并行计算
- 流水线式计算作业
- 本地化计算
- 动态编译执行计划
- GC控制
Presto存储插件
- Presto设计了一个简单的数据存储的抽象层, 来满足在不同数据存储系统之上都可以使用SQL进行查询。
- 存储插件(连接器,connector)只需要提供实现以下操作的接口, 包括对元数据(metadata)的提取,获得数据存储的位置,获取数据本身的操作等。
- 除了我们主要使用的Hive/HDFS后台系统之外, 我们也开发了一些连接其他系统的Presto 连接器,包括HBase,Scribe和定制开发的系统
- 插件结构图如下:
presto执行过程
- 执行过程示意图:
- 提交查询:用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行,如下图:示例SQL如下
-
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;
- 逻辑执行过程示意图如下:
- 上图逻辑执行计划图中的虚线就是Presto对逻辑执行计划的切分点,逻辑计划Plan生成的SubPlan分为四个部分,每一个SubPlan都会提交到一个或者多个Worker节点上执行
- SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性整个执行过程的流程图如下:
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
- Source:表示这个SubPlan是数据源,Source类型的任务会按照数据源大小确定分配多少个节点进行执行
- Fixed: 表示这个SubPlan会分配固定的节点数进行执行(Config配置中的query.initial-hash-partitions参数配置,默认是8)
- None: 表示这个SubPlan只分配到一个节点进行执行
- OutputPartitioning:表示这个SubPlan的输出是否按照partitionBy的key值对数据进行Shuffle(洗牌), 只有两个值HASH和NONE
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
- 在上图的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据,如下图:
- SubPlan1和SubPlan0 作为Source节点,它们读取HDFS文件数据的方式就是调用的HDFS InputSplit API,然后每个InputSplit分配一个Worker节点去执行,每个Worker节点分配的InputSplit数目上限是参数可配置的,Config中的query.max-pending-splits-per-node参数配置,默认是100
- SubPlan1的每个节点读取一个Split的数据并过滤后将数据分发给每个SubPlan0节点进行Join操作和Partial Aggr操作
- SubPlan0的每个节点计算完成后按GroupBy Key的Hash值将数据分发到不同的SubPlan2节点
- 所有SubPlan2节点计算完成后将数据分发到SubPlan3节点
- SubPlan3节点计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
presto引擎对比
- 与hive、SparkSQL对比结果图
1,Presto基本认识
1.1 定义
Presto是一个分布式的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析;但是对于OLTP场景,并不是Presto所擅长,所以不要把Presto当做数据库来使用。
和大家熟悉的Mysql相比:首先Mysql是一个数据库,具有存储和计算分析能力,而Presto只有计算分析能力;其次数据量方面,Mysql作为传统单点关系型数据库不能满足当前大数据量的需求,于是有各种大数据的存储和分析工具产生,Presto就是这样一个可以满足大数据量分析计算需求的一个工具。
1.2 数据源
Presto需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等
一条Presto查询可以将多个数据源的数据进行合并分析。
比如:select * from a join b where a.id=b.id;,其中表a可以来自Hive,表b可以来自Mysql。
1.3 优势
Presto是一个低延迟高并发的内存计算引擎,相比Hive,执行效率要高很多。
举例:
SELECT id,
name,
source_type,
created_at
FROM dw_dwb.dwb_user_day
WHERE dt='2018-06-03'
AND created_at>’2018-05-20’;
上述SQL在Presto运行时间不到1秒钟,在Hive里要几十秒钟。
1.4数据模型
Presto使用Catalog、Schema和Table这3层结构来管理数据。
---- Catalog:就是数据源。Hive是数据源,Mysql也是数据源,Hive 和Mysql都是数据源类型,可以连接多个Hive和多个Mysql,每个连接都有一个名字。一个Catalog可以包含多个Schema,大家可以通过show catalogs 命令看到Presto连接的所有数据源。
---- Schema:相当于一个数据库实例,一个Schema包含多张数据表。show schemas from 'catalog_name'可列出catalog_name下的所有schema。
---- Table:数据表,与一般意义上的数据库表相同。show tables from 'catalog_name.schema_name'可查看'catalog_name.schema_name'下的所有表。
在Presto中定位一张表,一般是catalog为根,例如:一张表的全称为 hive.test_data.test,标识 hive(catalog)下的 test_data(schema)中test表。
可以简理解为:数据源的大类.数据库.数据表。
2,Presto与Hive
Hive是一个基于HDFS(分布式文件系统)的一个数据库,具有存储和分析计算能力, 支持大数据量的存储和查询。Hive 作为数据源,结合Presto分布式查询引擎,这样大数据量的查询计算速度就会快很多。
Presto支持标准SQL,这里需要提醒大家的是,在使用Hive数据源的时候,如果表是分区表,一定要添加分区过滤,不加分区扫描全表是一个很暴力的操作,执行效率低下并且占用大量集群资源,大家尽量避免这种写法。
这里提到Hive分区,我简单介绍一下概念。Hive分区就是分目录,把一个大的数据集根据业务需要分割成更细的数据集。
举例:假如一个表的数据都放在/user/xiaoming/table/目录下,如果想把数据按照每天的数据细分,则就变成/user/xiaoming/table/2018-06-01/,/user/xiaoming/table/2018-06-02/,……如果查询某一天的数据,就可以直接取某一天目录下的数据,不需要扫描其他天的数据,节省了时间和资源。
使用Presto:
3,Presto接入方式
Presto的接入方式有多种:presto-cli,pyhive,jdbc,http,golang,SQLAlchemy,PHP等,其中presto-cli是Presto官方提供的,下面以presto-cli为例展开说明(自行下载)。
以连接hive数据源为例,在电脑终端输入:./presto-cli.jar --server presto.xxx-apps.com:9200 --catalog hive --user xxxx --source 'pf=adhoc;client=cli'就可以进入presto终端界面。
先解释下各参数的含义:
--server 是presto服务地址;
--catalog 是默认使用哪个数据源,后面也可以切换,如果想连接mysql数据源,使用mysql数据源名称即可;
--user 是用户名;
--source 是代表查询来源,source设置格式为key=value形式(英文分号分割); 例如个人从command line查询应设置为pf=adhoc;client=cli。
进入终端后:
查看数据源: show catalogs;
查看数据库实例:show schemas;
Presto使用手册:https://prestodb.io/docs/current/
问答:
1.使用场景?
-mysql跨数据库查询;-数仓的表数据查询(数据分析) ...
2.为什么presto查询速度比Hive快?
presto是常驻任务,接受请求立即执行,全内存并行计算;hive需要用yarn做资源调度,接受查询需要先申请资源,启动进程,并且中间结果会经过磁盘。
Presto简介
不是什么
虽然Presto可以解析SQL,但它不是一个标准的数据库。不是MySQL、PostgreSQL或者Oracle的代替品,也不能用来处理在线事务(OLTP)
是什么
Presto通过使用分布式查询,可以快速高效的完成海量数据的查询。作为Hive和Pig的替代者,Presto不仅能访问HDFS,也能访问不同的数据源,包括:RDBMS和其他数据源(如Cassandra)。
架构
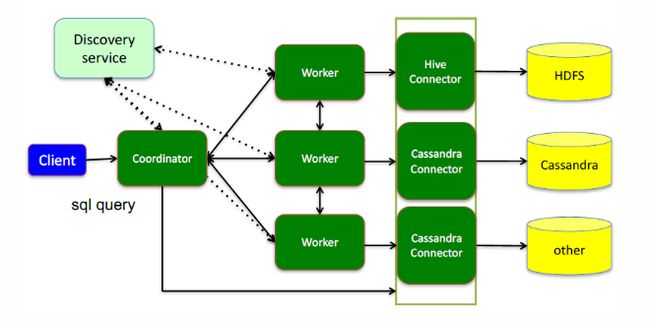
图中各个组件的概念及作用会在下文讲述。
Presto中SQL运行过程:MapReduce vs Presto
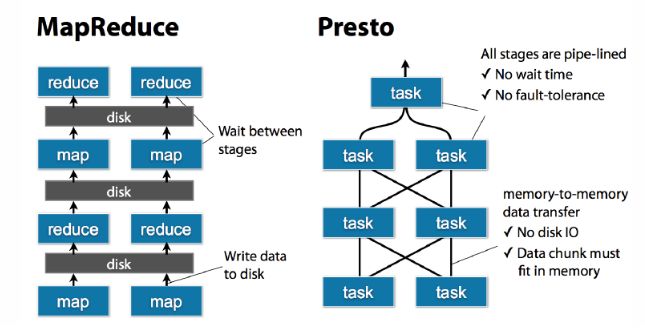
使用内存计算,减少与硬盘交互。
优点
1.Presto与hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
2.能够连接多个数据源,跨数据源连表查,如从hive查询大量网站访问记录,然后从mysql中匹配出设备信息。
3.部署也比hive简单,因为hive是基于HDFS的,需要先部署HDFS。
缺点
1.虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而hive此时会更擅长。
2.为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
Presto概念
服务器类型(Server Types)
Presto有两类服务器:coordinator和worker。
Coordinator
Coordinator服务器是用来解析语句,执行计划分析和管理Presto的worker结点。Presto安装必须有一个Coordinator和多个worker。如果用于开发环境和测试,则一个Presto实例可以同时担任这两个角色。
Coordinator跟踪每个work的活动情况并协调查询语句的执行。 Coordinator为每个查询建立模型,模型包含多个stage,每个stage再转为task分发到不同的worker上执行。
Coordinator与Worker、client通信是通过REST API。
Worker
Worker是负责执行任务和处理数据。Worker从connector获取数据。Worker之间会交换中间数据。Coordinator是负责从Worker获取结果并返回最终结果给client。
当Worker启动时,会广播自己去发现 Coordinator,并告知 Coordinator它是可用,随时可以接受task。
Worker与Coordinator、Worker通信是通过REST API。
数据源
贯穿全文,你会看到一些术语:connector、catelog、schema和table。这些是Presto特定的数据源
Connector
Connector是适配器,用于Presto和数据源(如Hive、RDBMS)的连接。你可以认为类似JDBC那样,但却是Presto的SPI的实现,使用标准的API来与不同的数据源交互。
Presto有几个内建Connector:JMX的Connector、System Connector(用于访问内建的System table)、Hive的Connector、TPCH(用于TPC-H基准数据)。还有很多第三方的Connector,所以Presto可以访问不同数据源的数据。
每个catalog都有一个特定的Connector。如果你使用catelog配置文件,你会发现每个文件都必须包含connector.name属性,用于指定catelog管理器(创建特定的Connector使用)。一个或多个catelog用同样的connector是访问同样的数据库。例如,你有两个Hive集群。你可以在一个Presto集群上配置两个catelog,两个catelog都是用Hive Connector,从而达到可以查询两个Hive集群。
Catelog
一个Catelog包含Schema和Connector。例如,你配置JMX的catelog,通过JXM Connector访问JXM信息。当你执行一条SQL语句时,可以同时运行在多个catelog。
Presto处理table时,是通过表的完全限定(fully-qualified)名来找到catelog。例如,一个表的权限定名是hive.test_data.test,则test是表名,test_data是schema,hive是catelog。
Catelog的定义文件是在Presto的配置目录中。
Schema
Schema是用于组织table。把catelog好schema结合在一起来包含一组的表。当通过Presto访问hive或Mysq时,一个schema会同时转为hive和mysql的同等概念。
Table
Table跟关系型的表定义一样,但数据和表的映射是交给Connector。
执行查询的模型(Query Execution Model)
语句(Statement)
Presto执行ANSI兼容的SQL语句。当Presto提起语句时,指的就是ANSI标准的SQL语句,包含着列名、表达式和谓词。
之所以要把语句和查询分开说,是因为Presto里,语句知识简单的文本SQL语句。而当语句执行时,Presto则会创建查询和分布式查询计划并在Worker上运行。
查询(Query)
当Presto解析一个语句时,它将其转换为一个查询,并创建一个分布式查询计划(多个互信连接的stage,运行在Worker上)。如果想获取Presto的查询情况,则获取每个组件(正在执行这语句的结点)的快照。
查询和语句的区别是,语句是存SQL文本,而查询是配置和实例化的组件。一个查询包含:stage、task、split、connector、其他组件和数据源。
Stage
当Presto执行查询时,会将执行拆分为有层次结构的stage。例如,从hive中的10亿行数据中聚合数据,此时会创建一个用于聚合的根stage,用于聚合其他stage的数据。
层次结构的stage类似一棵树。每个查询都由一个根stage,用于聚合其他stage的数据。stage是Coordinator的分布式查询计划(distributed query plan)的模型,stage不是在worker上运行。
Task
由于stage不是在worker上运行。stage又会被分为多个task,在不同的work上执行。
Task是Presto结构里是“work horse”。一个分布式查询计划会被拆分为多个stage,并再转为task,然后task就运行或处理split。Task有输入和输出,一个stage可以分为多个并行执行的task,一个task可以分为多个并行执行的driver。
Split
Task运行在split上。split是一个大数据集合中的一块。分布式查询计划最底层的stage是通过split从connector上获取数据,分布式查询计划中间层或顶层则是从它们下层的stage获取数据。
Presto调度查询,coordinator跟踪每个机器运行什么任务,那些split正在被处理。
Driver
Task包含一个或多个并行的driver。Driver在数据上处理,并生成输出,然后由Task聚合,最后传送给stage的其他task。一个driver是Operator的序列。driver是Presto最最低层的并行机制。一个driver有一个输出和一个输入。
Operator
Operator消费,传送和生产数据。如一个Operator从connector中扫表获取数据,然后生产数据给其他Operator消费。一个过滤Operator消费数据,并应用谓词,最后生产出子集数据。
Exchange
Exchange在Presto结点的不同stage之间传送数据。Task生产和消费数据是通过Exchange客户端。
参考:https://prestodb.io/docs/curr...
Presto的部署
安装Presto
1.下载
wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.200/presto-server-0.200.tar.gz2.解压
tar -zxvf presto-server-0.200.tar.gz -C /usr/local//usr/local/presto-server-0.200则为安装目录,另外Presto还需要数据目录,数据目录最好不要在安装目录里面,方便后面Presto的版本升级。
配置Presto
在安装目录里创建etc目录。这目录会有以下配置:
- 结点属性(Node Properties):每个结点的环境配置
- JVM配置(JVM Config):Java虚拟机的命令行选项
- 配置属性(Config Properties):Persto server的配置
- Catelog属性(Catalog Properties):配置Connector(数据源)
结点属性(Node Properties)
结点属性文件etc/node.properties,包含每个结点的配置。一个结点是一个Presto实例。这文件一般是在Presto第一次安装时创建的。以下是最小配置:
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/presto/datanode.environment: 环境名字,Presto集群中的结点的环境名字都必须是一样的。
node.id: 唯一标识,每个结点的标识都必须是为一的。就算重启或升级Presto都必须还保持原来的标识。
node.data-dir: 数据目录,Presto用它来保存log和其他数据。
JVM配置(JVM Config)
JVM配置文件etc/jvm.config,包含启动Java虚拟机时的命令行选项。格式是每一行是一个命令行选项。此文件数据是由shell解析,所以选项中包含空格或特殊字符会被忽略。
以下是参考配置:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError因为OutOfMemoryError会导致JVM存在不一致状态,所以用heap dump来debug,来找出进程为什么崩溃的原因。
配置属性(Config Properties)
配置属性文件etc/config.properties,包含Presto server的配置。Presto server可以同时为coordinator和worker,但一个大集群里最好就是只指定一台机器为coordinator。
以下是coordinator的最小配置:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080以下是worker的最小配置:
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery.uri=http://example.net:8080如果适用于测试目的,需要将一台机器同时配置为coordinator和worker,则使用以下配置:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080coordinator: 是否运行该实例为coordinator(接受client的查询和管理查询执行)。
node-scheduler.include-coordinator:coordinator是否也作为work。对于大型集群来说,在coordinator里做worker的工作会影响查询性能。
http-server.http.port:指定HTTP端口。Presto使用HTTP来与外部和内部进行交流。
query.max-memory: 查询能用到的最大总内存
query.max-memory-per-node: 查询能用到的最大单结点内存
discovery-server.enabled: Presto使用Discovery服务去找到集群中的所有结点。每个Presto实例在启动时都会在Discovery服务里注册。这样可以简化部署,不需要额外的服务,Presto的coordinator内置一个Discovery服务。也是使用HTTP端口。
discovery.uri: Discovery服务的URI。将example.net:8080替换为coordinator的host和端口。这个URI不能以斜杠结尾,这个错误需特别注意,不然会报404错误。
另外还有以下属性:
jmx.rmiregistry.port: 指定JMX RMI的注册。JMX client可以连接此端口
jmx.rmiserver.port: 指定JXM RMI的服务器。可通过JMX监听。
详情请查看Resource Groups
Catelog属性(Catalog Properties)
Presto通过connector访问数据。而connector是挂载(mount)在catelog中。connector支持catelog里所有的schema和table。举个例子,Hive connector映射每个Hive数据库到schema,因此Hive connector挂载在hive catelog(所以可以把catelog理解为目录,挂载),而且Hive包含table clicks在数据库web,所以这个table在Presto是hive.web.clicks。
Catalog的注册是通过etc/catalog目录下的catalog属性文件。例如,创建etc/catalog/jmx.properties,将jmxconnector挂载在jmx catelog:
connector.name=jmx查看Connectors查看更多信息。
运行Presto
启动命令:
bin/launcher start日志在val/log目录下:
launcher.log: 记录服务初始化情况和一些JVM的诊断。
server.log: Presto的主要日志文件。会自动被压缩。
http-request.log: 记录HTTP请求。会自动被压缩。
运行Presto命令行界面
1.下载 presto-cli-0.200-executable.jar,
2.修改名字 presto-cli-0.200-executable.jar为 presto
3.修改执行权限chmod +x
4.运行
./presto --server localhost:8080 --catalog hive --schema default一、Presto简介
1、PRESTO是什么?
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
2、它可以做什么?
Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
Presto以分析师的需求作为目标,他们期望响应时间小于1秒到几分钟。 Presto终结了数据分析的两难选择,要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
3、介绍
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
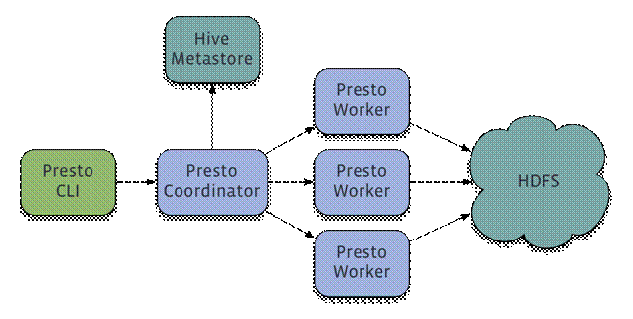
4、需求
Presto的基本需求
Linux or Mac OS X
Java 8, 64-bit
Python 2.4+
5、连接器
Presto支持插接式连接器提供的数据。 各连接器的设计需求会有所不同。
HADOOP / HIVE
Presto支持从以下版本的Hadoop中读取Hive数据:
Apache Hadoop 1.x
Apache Hadoop 2.x
Cloudera CDH 4
Cloudera CDH 5
支持以下文件类型:Text, SequenceFile, RCFile, ORC
此外,需要有远程的Hive元数据。 不支持本地或嵌入模式。 Presto不使用MapReduce,只需要HDFS。
二、Presto安装部署
1、下载presto tar包:
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.189/presto-server-0.189.tar.gz
2、将下载的presto tar包通过ftp工具上传到linux服务器上,然后解压安装文件。
tar -zxvf presto-server-0.189.tar.gz -C /opt/cdh-5.3.6/
chown -R hadoop:hadoop /opt/cdh-5.3.6/presto-server-0.189/
3、配置presto
分别执行以下步骤:
在安装目录中创建一个etc目录。 在这个etc目录中放入以下配置信息:
l 节点属性:每个节点的环境配置信息
l JVM 配置:JVM的命令行选项
l 配置属性:Presto server的配置信息
l Catalog属性:configuration forConnectors(数据源)的配置信息
1)Node Properties
节点属性配置文件:etc/node.properties包含针对于每个节点的特定的配置信息。 一个节点就是在一台机器上安装的Presto实例。 这份配置文件一般情况下是在Presto第一次安装的时候,由部署系统创建的。 一个etc/node.properties配置文件至少包含如下配置信息:
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/presto/data
针对上面的配置信息描述如下:
node.environment: 集群名称。所有在同一个集群中的Presto节点必须拥有相同的集群名称。
node.id: 每个Presto节点的唯一标示。每个节点的node.id都必须是唯一的。在Presto进行重启或者升级过程中每个节点的node.id必须保持不变。如果在一个节点上安装多个Presto实例(例如:在同一台机器上安装多个Presto节点),那么每个Presto节点必须拥有唯一的node.id。
node.data-dir: 数据存储目录的位置(操作系统上的路径)。Presto将会把日期和数据存储在这个目录下。
2)JVM配置
JVM配置文件,etc/jvm.config, 包含一系列在启动JVM的时候需要使用的命令行选项。这份配置文件的格式是:一系列的选项,每行配置一个单独的选项。由于这些选项不在shell命令中使用。 因此即使将每个选项通过空格或者其他的分隔符分开,java程序也不会将这些选项分开,而是作为一个命令行选项处理。(就想下面例子中的OnOutOfMemoryError选项)。
一个典型的etc/jvm.config配置文件如下:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
由于OutOfMemoryError将会导致JVM处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是将dump headp中的信息(用于debugging),然后强制终止进程。
Presto会将查询编译成字节码文件,因此Presto会生成很多class,因此我们我们应该增大Perm区的大小(在Perm中主要存储class)并且要允许Jvm class unloading。
3)Config Properties
Presto的配置文件:etc/config.properties包含了Presto server的所有配置信息。 每个Presto server既是一个coordinator也是一个worker。 但是在大型集群中,处于性能考虑,建议单独用一台机器作为 coordinator。
一个coordinator的etc/config.properties应该至少包含以下信息:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080
以下是最基本的worker配置:
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery.uri=http://example.net:8080
但是如果你用一台机器进行测试,那么这一台机器将会即作为coordinator,也作为worker。配置文件将会如下所示:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://example.net:8080
对配置项解释如下:
coordinator:指定是否运维Presto实例作为一个coordinator(接收来自客户端的查询情切管理每个查询的执行过程)。
node-scheduler.include-coordinator:是否允许在coordinator服务中进行调度工作。对于大型的集群,在一个节点上的Presto server即作为coordinator又作为worke将会降低查询性能。因为如果一个服务器作为worker使用,那么大部分的资源都不会被worker占用,那么就不会有足够的资源进行关键任务调度、管理和监控查询执行。
http-server.http.port:指定HTTP server的端口。Presto 使用 HTTP进行内部和外部的所有通讯。
task.max-memory=1GB:一个单独的任务使用的最大内存 (一个查询计划的某个执行部分会在一个特定的节点上执行)。 这个配置参数限制的GROUP BY语句中的Group的数目、JOIN关联中的右关联表的大小、ORDER BY语句中的行数和一个窗口函数中处理的行数。 该参数应该根据并发查询的数量和查询的复杂度进行调整。如果该参数设置的太低,很多查询将不能执行;但是如果设置的太高将会导致JVM把内存耗光。
discovery-server.enabled:Presto 通过Discovery 服务来找到集群中所有的节点。为了能够找到集群中所有的节点,每一个Presto实例都会在启动的时候将自己注册到discovery服务。Presto为了简化部署,并且也不想再增加一个新的服务进程,Presto coordinator 可以运行一个内嵌在coordinator 里面的Discovery 服务。这个内嵌的Discovery 服务和Presto共享HTTP server并且使用同样的端口。
discovery.uri:Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri。修改example.net:8080,根据你的实际环境设置该URI。注意:这个URI一定不能以“/“结尾。
4)日志级别
日志配置文件:etc/log.properties。在这个配置文件中允许你根据不同的日志结构设置不同的日志级别。每个logger都有一个名字(通常是使用logger的类的全标示类名). Loggers通过名字中的“.“来表示层级和集成关系。 (像java里面的包). 如下面的log配置信息:
com.facebook.presto=INFO
This would set the minimum level to INFO for both com.facebook.presto.server and com.facebook.presto.hive. The default minimum level is INFO (thus the above example does not actually change anything). There are four levels: DEBUG, INFO, WARN and ERROR.
5)Catalog Properties
Presto通过connectors访问数据。这些connectors挂载在catalogs上。 connector 可以提供一个catalog中所有的schema和表。 例如: Hive connector 将每个hive的database都映射成为一个schema, 所以如果hive connector挂载到了名为hive的catalog, 并且在hive的web有一张名为clicks的表, 那么在Presto中可以通过hive.web.clicks来访问这张表。
通过在etc/catalog目录下创建catalog属性文件来完成catalogs的注册。 例如:可以先创建一个etc/catalog/jmx.properties文件,文件中的内容如下,完成在jmxcatalog上挂载一个jmxconnector:
connector.name=jmx
查看Connectors的详细配置选项。
4、运行Presto
在安装目录的bin/launcher文件,就是启动脚本。Presto可以使用如下命令作为一个后台进程启动:
bin/launcher start
另外,也可以在前台运行, 日志和相关输出将会写入stdout/stderr(可以使用类似daemontools的工具捕捉这两个数据流):
bin/launcher run
运行bin/launcher–help,Presto将会列出支持的命令和命令行选项。 另外可以通过运行bin/launcher–verbose命令,来调试安装是否正确。
启动完之后,日志将会写在var/log目录下,该目录下有如下文件:
launcher.log: 这个日志文件由launcher创建,并且server的stdout和stderr都被重定向到了这个日志文件中。 这份日志文件中只会有很少的信息,包括:
在server日志系统初始化的时候产生的日志和JVM产生的诊断和测试信息。
server.log: 这个是Presto使用的主要日志文件。一般情况下,该文件中将会包括server初始化失败时产生的相关信息。这份文件会被自动轮转和压缩。
http-request.log: 这是HTTP请求的日志文件,包括server收到的每个HTTP请求信息,这份文件会被自动轮转和压缩。
三、部署presto client
1、下载:
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.189/presto-cli-0.189-executable.jar
上传linux服务器上,重命名为presto:
$mv presto-cli-0.189-executable.jar presto
$chmod a+x presto
执行以下命令:
$ ./presto --server localhost:8080 --catalog hive --schema default
四、proste连接hive
1、编辑hive-site.xml文件,增加以下内容:
2、启动hiveserver2和hive元数据服务:
bin/hive --service hiveserver2 &
bin/hive --service matestore &
3、配置hive插件,etc/catalog目录下创建hive.properties文件,输入如下内容。
3.1)hive配置:
connector.name=hive-hadoop2 #这个连接器的选择要根据自身集群情况结合插件包的名字来写
hive.metastore.uri=thrift://chavin.king:9083 #修改为 hive-metastore 服务所在的主机名称,这里我是安装在master节点
3.2)HDFS Configuration:
如果hive metastore的引用文件存放在一个存在联邦的HDFS上,或者你是通过其他非标准的客户端来访问HDFS集群的,请添加以下配置信息来指向你的HDFS配置文件:
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
大多数情况下,Presto会在安装过程中自动完成HDFS客户端的配置。 如果确实需要特殊配置,只需要添加一些额外的配置文件,并且需要指定这些新加的配置文件。 建议将配置文件中的配置属性最小化。尽量少添加一些配置属性,因为过多的添加配置属性会引起其他问题。
3.3)Configuration Properties
| Property Name |
Description |
Example |
| hive.metastore.uri |
The URI of the Hive Metastore to connect to using the Thrift protocol. This property is required. |
thrift://192.0.2.3:9083 |
| hive.config.resources |
An optional comma-separated list of HDFS configuration files. These files must exist on the machines running Presto. Only specify this if absolutely necessary to access HDFS. |
/etc/hdfs-site.xml |
| hive.storage-format |
The default file format used when creating new tables |
RCBINARY |
| hive.force-local-scheduling |
Force splits to be scheduled on the same node as the Hadoop DataNode process serving the split data. This is useful for installations where Presto is collocated with every DataNode. |
true |
4、presto连接hive schema,注意presto不能进行垮库join操作,测试结果如下:
$ ./presto --server localhost:8080 --catalog hive --schema chavin
presto:chavin> select * from emp;
empno | ename | job | mgr | hiredate | sal | comm | deptno
-------+--------+-----------+------+------------+--------+--------+--------
7369 | SMITH | CLERK | 7902 | 1980/12/17 | 800.0 | NULL | 20
7499 | ALLEN | SALESMAN | 7698 | 1981/2/20 | 1600.0 | 300.0 | 30
7521 | WARD | SALESMAN | 7698 | 1981/2/22 | 1250.0 | 500.0 | 30
7566 | JONES | MANAGER | 7839 | 1981/4/2 | 2975.0 | NULL | 20
7654 | MARTIN | SALESMAN | 7698 | 1981/9/28 | 1250.0 | 1400.0 | 30
7698 | BLAKE | MANAGER | 7839 | 1981/5/1 | 2850.0 | NULL | 30
7782 | CLARK | MANAGER | 7839 | 1981/6/9 | 2450.0 | NULL | 10
7788 | SCOTT | ANALYST | 7566 | 1987/4/19 | 3000.0 | NULL | 20
7839 | KING | PRESIDENT | NULL | 1981/11/17 | 5000.0 | NULL | 10
7844 | TURNER | SALESMAN | 7698 | 1981/9/8 | 1500.0 | 0.0 | 30
7876 | ADAMS | CLERK | 7788 | 1987/5/23 | 1100.0 | NULL | 20
7900 | JAMES | CLERK | 7698 | 1981/12/3 | 950.0 | NULL | 30
7902 | FORD | ANALYST | 7566 | 1981/12/3 | 3000.0 | NULL | 20
7934 | MILLER | CLERK | 7782 | 1982/1/23 | 1300.0 | NULL | 10
(14 rows)
Query 20170711_081802_00002_ydh8n, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:05 [14 rows, 657B] [2 rows/s, 130B/s]
presto:chavin>
五、JDBC驱动
通过使用JDBC驱动,可以访问Presto。下载presto-jdbc-0.100.jar并将这个jar文件添加到你的java应用程序的classpath中,Presto支持的URL格式如下:
jdbc:presto://host:port
jdbc:presto://host:port/catalog
jdbc:presto://host:port/catalog/schema
例如,可以使用下面的URL来连接运行在example.net服务器8080端口上的Presto的hive catalog中的sales schema:
jdbc:presto://example.net:8080/hive/sales
六、presto管理之队列配置
排队规则定义在一个Json文件中,用于控制能够提交给Presto的查询的个数,以及每个队列中能够同时运行的查询的个数。用config.properties中的query.queue-config-file来指定Json配置文件的名字。
排队规则如果定义了多个队列,查询会按顺序依次进入不同的队列中。排队规则将按照顺序进行处理,并且使用第一个匹配上的规则。在以下的配置例子中,有5个队列模板,在user.${USER}队列中,${USER}表示着提交查询的用户名。同样的${SOURCE}表示提交查询的来源。
同样有五条规则定义了哪一类查询会进入哪一个队列中:
第一条规则将使bob成为管理员,bob提交的查询进入admin队列。
第二条规则表示,所有使用了experimental_big_querysession参数并且来源包含pipeline的查询将首先进入 用户的个人队列中,然后进入pipeline队列,最后进入big队列中。当一个查询进入一个新的队列后,直到查询结束 才会离开之前的队列。
第三条规则同上一条类似,但是没有experimental_big_query的要求,同时用global队列替换了big队列。
最后两条规则跟以上两条规则类似,但是没有了pipeline来源的要求。
所有这些规则实现了这样的策略,bob是一个管理员,而其他用户需要遵循以下的限制:
每个用户最多能同时运行5个查询。
big查询同时只能运行一个
最多能同时运行10个pipeline来源的查询。
最多能同时运行100个非big查询
{
"queues": {
"user.${USER}": {
"maxConcurrent": 5,
"maxQueued": 20
},
"pipeline": {
"maxConcurrent": 10,
"maxQueued": 100
},
"admin": {
"maxConcurrent": 100,
"maxQueued": 100
},
"global": {
"maxConcurrent": 100,
"maxQueued": 1000
},
"big": {
"maxConcurrent": 1,
"maxQueued": 10
}
},
"rules": [
{
"user": "bob",
"queues": ["admin"]
},
{
"session.experimental_big_query": "true",
"source": ".*pipeline.*",
"queues": [
"user.${USER}",
"pipeline",
"big"
]
},
{
"source": ".*pipeline.*",
"queues": [
"user.${USER}",
"pipeline",
"global"
]
},
{
"session.experimental_big_query": "true",
"queues": [
"user.${USER}",
"big"
]
},
{
"queues": [
"user.${USER}",
"global"
]
}
]
}
七、presto连接mysql数据库
1、在etc/catalog目录下创建文件mysql.properties,输入如下内容,保存退出。
connector.name=mysql
connection-url=jdbc:mysql://example.net:3306
connection-user=root
connection-password=secret
2、presto客户端连接mysql服务并执行查询:
$ ./presto --server localhost:8080 --catalog mysql --schema chavin
presto:chavin> select * from mysql.chavin.emp;
empno | ename | job | mgr | hiredate | sal | comm | deptno
-------+--------+-----------+------+------------+--------+--------+--------
7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20
7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.0 | 300.0 | 30
7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.0 | 500.0 | 30
7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.0 | NULL | 20
7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.0 | 1400.0 | 30
7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.0 | NULL | 30
7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.0 | NULL | 10
7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.0 | NULL | 20
7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10
7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.0 | 0.0 | 30
7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.0 | NULL | 20
7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.0 | NULL | 30
7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.0 | NULL | 20
7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.0 | NULL | 10
(14 rows)
Query 20170711_085557_00002_hpvqh, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:00 [14 rows, 0B] [28 rows/s, 0B/s]
八、presto连接postgresql
1、在etc/catalog目录下创建文件postgresql.properties文件,添加如下内容:
connector.name=postgresql
connection-url=jdbc:postgresql://example.net:5432/database
connection-user=root
connection-password=secret
2、通过presto客户端查询postgresql数据库:
$ ./presto --server localhost:8080 --catalog postgresql --schema postgres
附:
参考文档:https://prestodb.io/docs/current/
presto是什么
是Facebook开源的,完全基于内存的并⾏计算,分布式SQL交互式查询引擎
是一种Massively parallel processing (MPP)架构,多个节点管道式执⾏
⽀持任意数据源(通过扩展式Connector组件),数据规模GB~PB级
使用的技术,如向量计算,动态编译执⾏计划,优化的ORC和Parquet Reader等
presto不太支持存储过程,支持部分标准sql
presto的查询速度比hive快5-10倍
上面讲述了presto是什么,查询速度,现在来看看presto适合干什么
适合:PB级海量数据复杂分析,交互式SQL查询,⽀持跨数据源查询
不适合:多个大表的join操作,因为presto是基于内存的,多张大表在内存里可能放不下
和hive的对比:
hive是一个数据仓库,是一个交互式比较弱一点的查询引擎,交互式没有presto那么强,而且只能访问hdfs的数据
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
hive在查询100Gb级别的数据时,消耗时间已经是分钟级了
但是presto是取代不了hive的,因为p全部的数据都是在内存中,限制了在内存中的数据集大小,比如多个大表的join,这些大表是不能完全放进内存的,实际应用中,对于在presto的查询是有一定规定条件的,比比如说一个查询在presto查询超过30分钟,那就kill掉吧,说明不适合在presto上使用,主要原因是,查询过大的话,会占用整个集群的资源,这会导致你后续的查询是没有资源进行查询的,这跟presto的设计理念是冲突的,就像是你进行一个查询,但是要等个5分钟才有资源继续查询,这是很不合理的,交互式就变得弱了很多
presto基本架构
在谈presto架构之前,先回顾下hive的架构
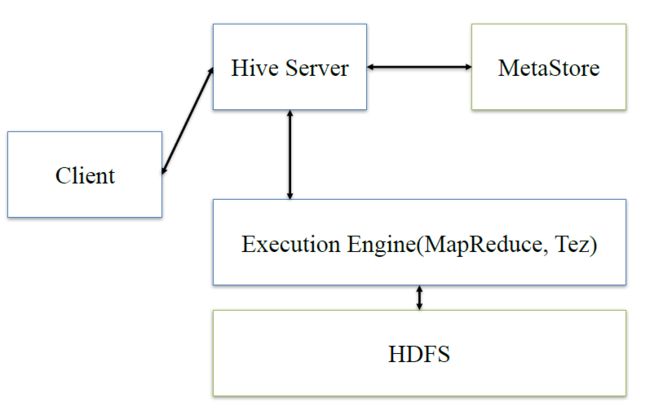
hive:client将查询请求发送到hive server,它会和metastor交互,获取表的元信息,如表的位置结构等,之后hive server会进行语法解析,解析成语法树,变成查询计划,进行优化后,将查询计划交给执行引擎,默认是MR,然后翻译成MR
presto:presto是在它内部做hive类似的逻辑
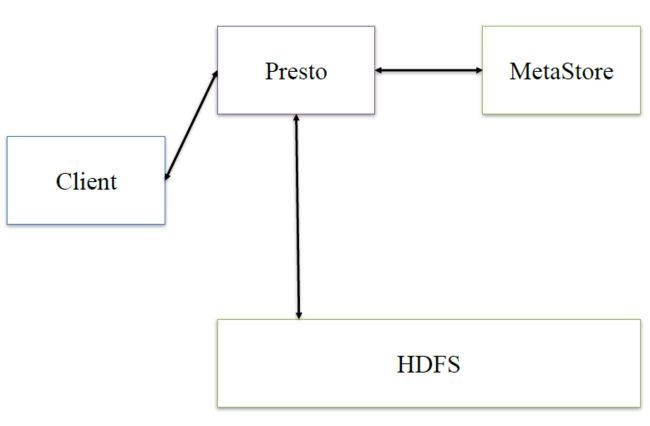
接下来,深入看下presto的内部架构
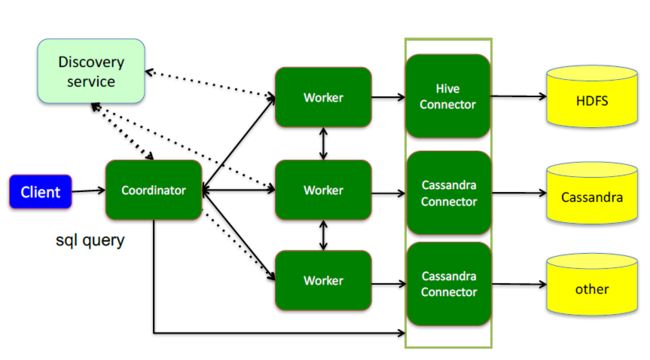
这里面三个服务:
Coordinator是一个中心的查询角色,它主要的一个作用是接受查询请求,将他们转换成各种各样的任务,将任务拆解后分发到多个worker去执行各种任务的节点
1、解析SQL语句
2、⽣成执⾏计划
3、分发执⾏任务给Worker节点执⾏
Worker,是一个真正的计算的节点,执行任务的节点,它接收到task后,就会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector:
1、负责实际执⾏查询任务
Discovery service,是将coordinator和woker结合到一起的服务:
1、Worker节点启动后向Discovery Server服务注册
2、Coordinator从Discovery Server获得Worker节点
coordinator和woker之间的关系是怎么维护的呢?是通过Discovery Server,所有的worker都把自己注册到Discovery Server上,Discovery Server是一个发现服务的service,Discovery Server发现服务之后,coordinator便知道在我的集群中有多少个worker能够给我工作,然后我分配工作到worker时便有了根据
最后,presto是通过connector plugin获取数据和元信息的,它不是⼀个数据存储引擎,不需要有数据,presto为其他数据存储系统提供了SQL能⼒,客户端协议是HTTP+JSON
Presto支持的数据源和存储格式
Hadoop/Hive connector与存储格式:
HDFS,ORC,RCFILE,Parquet,SequenceFile,Text
开源数据存储系统:
MySQL & PostgreSQL,Cassandra,Kafka,Redis
其他:
MongoDB,ElasticSearch,HBase
Presto中SQL运行过程:整体流程
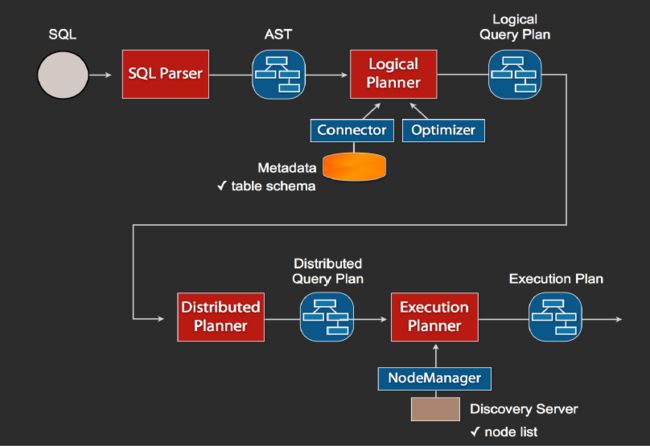
1、当我们执行一条sql查询,coordinator接收到这条sql语句以后,它会有一个sql的语法解析器去把sql语法解析变成一个抽象的语法树AST,这抽象的语法书它里面只是进行一些语法解析,如果你的sql语句里面,比如说关键字你用的是int而不是Integer,就会在语法解析这里给暴露出来
2、如果语法是符合sql语法规范,之后会经过一个逻辑查询计划器的组件,他的主要作用是,比如说你sql里面出现的表,他会通过connector的方式去meta里面把表的schema,列名,列的类型等,全部给找出来,将这些信息,跟语法树给对应起来,之后会生成一个物理的语法树节点,这个语法树节点里面,不仅拥有了它的查询关系,还拥有类型的关系,如果在这一步,数据库表里某一列的类型,跟你sql的类型不一致,就会在这里报错
3、如果通过,就会得到一个逻辑的查询计划,然后这个逻辑查询计划,会被送到一个分布式的逻辑查询计划器里面,进行一个分布式的解析,分布式解析里面,他就会去把对应的每一个查询计划转化为task
4、在每一个task里面,他会把对应的位置信息全部给提取出来,交给执行的plan,由plan把对应的task发给对应的worker去执行,这就是整个的一个过程
这是一个通用的sql解析流程,像hive也是遵循类似这样的流程,不一样的地方是distribution planner和executor pan,这里是各个引擎不一样的地方,前面基本上都一致的
Presto中SQL运行过程:MapReduce vs Presto
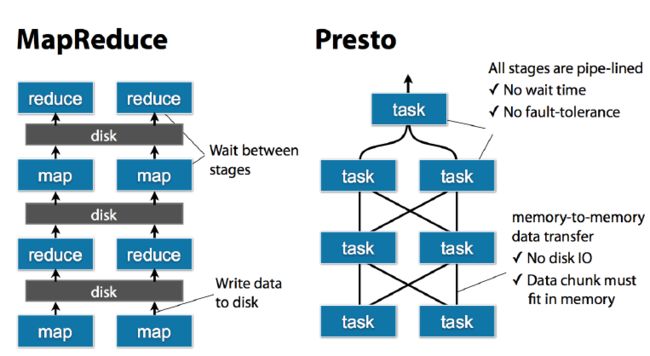
task是放在每个worker上该执行的,每个task执行完之后,数据是存放在内存里了,而不像mr要写磁盘,然后当多个task之间要进行数据交换,比如shuffle的时候,直接从内存里处理
Presto监控和配置:监控
Web UI
Query基本状态的查询
JMX HTTP API
GET /v1/jmx/mbean[/{objectName}]
• com.facebook.presto.execution:name=TaskManager
• com.facebook.presto.execution:name=QueryManager
• com.facebook.presto.execution:name=NodeScheduler
事件通知
Event Listener
• query start, query complete
Presto监控和配置:配置
执行计划计划(Coordinator)
node-scheduler.include-coordinator
• 是否让coordinator运行task
query.initial-hash-partitions
• 每个GROUP BY操作使⽤的hash bucket(=tasks)最大数目(default: 8)
node-scheduler.min-candidates
• 每个stage并发运行过程中可使用的最大worker数目(default:10)
query.schedule-split-batch-size
• 每个split数据量
任务执行(Worker)
query.max-memory (default: 20 GB)
• 一个查询可以使用的最大集群内存
• 控制集群资源使用,防止一个大查询占住集群所有资源
• 使用resource_overcommit可以突破限制
query.max-memory-per-node (default: 1 GB)
• 一个查询在一个节点上可以使用的最大内存
举例
• Presto集群配置: 120G * 40
• query.max-memory=1 TB
• query.max-memory-per-node=20 GB
query.max-run-time (default: 100 d)
• 一个查询可以运行的最大时间
• 防止用户提交一个长时间查询阻塞其他查询
task.max-worker-threads (default: Node CPUs * 4)
• 每个worker同时运行的split个数
• 调大可以增加吞吐率,但是会增加内存的消耗
队列(Queue)
任务提交或者资源使用的一些配置,是通过队列的配置来实现的
资源隔离,查询可以提交到相应队列中
• 资源隔离,查询可以提交到相应队列中
• 每个队列可以配置ACL(权限)
• 每个队列可以配置Quota
可以并发运行查询的数量
排队的最大数量

大数据OLAP引擎对比
Presto:内存计算,mpp架构
Druid:时序,数据放内存,索引,预计算
Spark SQL:基于Spark Core,mpp架构
Kylin:Cube预计算
最后,一些零散的知识点
presto适合pb级的海量数据查询分析,不是说把pb的数据放进内存,比如一张pb表,查询count,vag这种有个特点,虽然数据很多,但是最终的查询结果很小,这种就不会把数据都放到内存里面,只是在运算的过程中,拿出一些数据放内存,然后计算,在抛出,在拿,这种的内存占用量是很小的,但是join这种,在运算的中间过程会产生大量的数据,或者说那种查询的数据不大,但是生成的数据量很大,这种也是不合适用presto的,但不是说不能做,只是会占用大量内存,消耗很长的时间,这种hive合适点
presto算是hive的一个补充,需要尽快得出结果的用presto,否则用hive
work是部署的时候就事先部署好的,work启动100个,使用的work不一定100个,而是根据coordinator来决定拆分成多少个task,然后分发到多少个work去
一个coordinator可能同时又多个用户在请求query,然后共享work的去执行,这是一个共享的集群
coordinator和discovery server可以启动在一个节点一个进程,也可以放在不同的node上,但是现在公司大部分都是放在一个节点上,一个launcher start会同时把上述两个启动起来
对于presto的容错,如果某个worker挂掉了,discovery server会发现并通知coordinator
但是对于一个query,是没有容错的,一旦一个work挂了,那么整个qurey就是败了
因为对于presto,他的查询时间是很短的,与其查询这里做容错能力,不如重新执行来的快来的简单
对于coordinator和discovery server节点的单点故障,presto还没有开始处理这个问题貌似
Presto是一款由FaceBook开源的一个分布式SQL-on—Hadoop分析引擎。Presto目前由开源社区和FaceBook内部工程师共同维护,并衍生出多个商业版本。
基本特性
Presto使用Java语言进行开发,具备易用、高性能、强扩展能力等特点,具体的:
- 完全支持ANSI SQL。
- 支持丰富的数据源 Presto可接入丰富的数据来源,如下所示:
- 与Hive数仓互操作
- Cassandra
- Kafka
- MongoDB
- MySQL
- PostgreSQL
- SQL Server
- Redis
- Redshift
- 本地文件
- 支持高级数据结构:
- 支持数组和Map数据。
- 支持JSON数据。
- 支持GIS数据。
- 支持颜色数据。
- 功能扩展能力强 Presto提供了多种扩展机制,包括:
- 扩展数据连接器。
- 自定义数据类型。
- 自定义SQL函数。
用户可以根据自身业务特点扩展相应的模块,实现高效的业务处理。
-
基于Pipeline处理模型 数据在处理过程中实时返回给用户。
- 监控接口完善:
- 提供友好的WebUI,可视化的呈现查询任务执行过程。
- 支持JMX协议。
应用场景
Presto是定位在数据仓库和数据分析业务的分布式SQL引擎,比较适合如下几个应用场景:
- ETL
- Ad-Hoc查询
- 海量结构化数据/半结构化数据分析
- 海量多维数据聚合/报表
特别需要注意的是,Presto是一个数仓类产品,其设计目标并不是为了替代MySQL、PostgreSQL等传统的RDBMS数据库,对事务对支持有限,不适合在线业务场景。
产品优势
EMR Presto产品除了开源Presto本身具有的优点外,还具备如下优势:
- 即买即用 分分钟完成上百节点的Presto集群搭建。
- 弹性扩容 简单操作即可完成集群的扩容和缩容。
- 与EMR软件栈完美结合,支持处理存储在OSS的数据。
- 免运维 7*24一站式服务
本章将介绍Presto数据库的基本使用方法和应用开发方法,使开发者能够快速的使用Presto数据库进行应用开发。
系统组成
Presto的系统组成如下图所示: 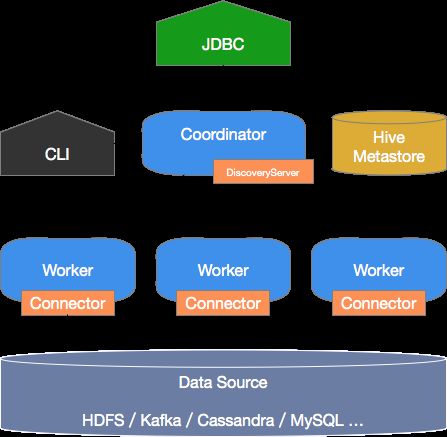
Presto是典型的M/S架构的系统,由一个Coordinator节点和多个Worker节点组成。Coordinator负责如下工作:
- 接收用户查询请求,解析并生成执行计划,下发Worker节点执行。
- 监控Worker节点运行状态,各个Worker节点与Coordinator节点保持心跳连接,汇报节点状态。
- 维护MetaStore数据。
Worker节点负责执行下发到任务,通过连接器读取外部存储系统到数据,进行处理,并将处理结果发送给Coordinator节点。
基本概念
本节介绍Presto中到基本概念,以便更好到理解Presto到工作机制。
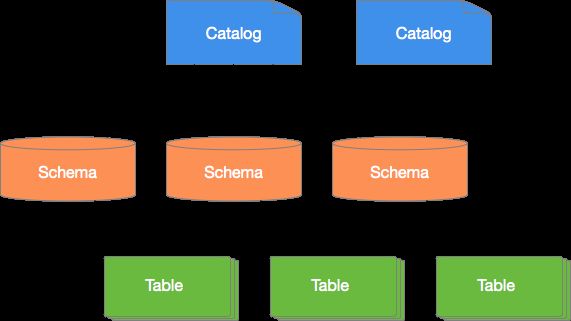
- 数据模型
数据模型即数据的组织形式。Presto使用 Catalog、Schema 和 Table 这3层结构来管理数据。
-
Catalog
一个 Catalog 可以包含多个 Schema,物理上指向一个外部数据源,可以通过 Connector 访问改数据源。一次查询可以访问一个或多个 Catalog。
-
Schema
相当于一个数据库示例,一个 Schema 包含多张数据表。
-
Table
数据表,与一般意义上的数据库表相同。
Catalog、Schema 和 Table 之间的关系如下图所示:
-
- Connector
Presto通过各种 Connector 来接入多种外部数据源。Presto提供了一套标准的SPI接口,用户可以使用这套接口,开发自己的 Connector,以便访问自定义的数据源。
一个 Catalog 一般会绑定一种类型的 Connector(在 Catalog 的 Properties 文件中设置)。Presto内置了多种 Connector 实现。
- 查询相关概念
本节主要介绍Presto查询过程中的相关概念,以便用户能够更好的理解Presto查询语句执行过程和性能调优方法。
-
Statement
即查询语句,表示用户通过JDBC或CLI输入对SQL语句。
-
Query
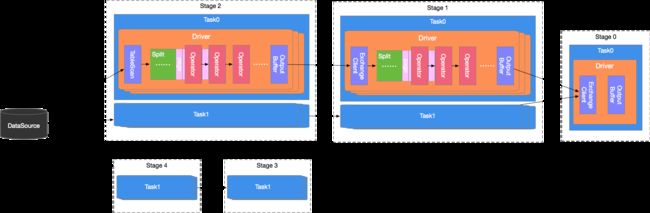
表示一次查询的执行过程,Presto接收到一个SQL Statement 后,在Coordinator中进行解析,生成执行计划,下发到Worker中执行。一个 Query 逻辑上由 Stage,Task,Driver,Split,Operator 和 DataSource 几个组件组成,如下所示:
-
Stage
Presto中的一个 Query 由多个 Stage 组成,Stage 是一个逻辑概念,表示查询过程的一个阶段,包含了一个或多个执行任务(Task)。Presto采用树状结构组织 Stage,该树的Root节点为 Single Stage,该Stage会汇聚其上游Stage输出的数据,进行聚合运算,将结果直接发送给 Coordinator。该树的叶子节点为 Source Stage,该Stage从 Connector 获取数据进行处理。
-
Task
Task 表示一个具体的执行任务,是Presto任务调度的最小单元,执行过程中,Presto任务调度器会将这些Task调度到各个Worker上执行。一个Stage中的任务可以并行执行。两个Stage之间的任务通过 Exchange 模块传递数据。
Task也是一个逻辑概念,包含了任务的参数和内容,实际的任务执行工作由 Driver 完成。 -
Driver
Driver 负责执行具体的任务工作。一个 Task 可以包含多个 Driver 实例,从而实现Task内部的并行处理。一个Driver 处理一个数据分片(Split)。一个 Driver 内部一组 Operator 组成,负责具体的数据操作,如转换、过滤等。
-
Operator
Operator 是最小的执行单元,负责对数据分片(Split)中的每一个 Page 进行处理,如加权、转换等,概念上与算子类似。Page 是 Operator 处理的最小数据单元,是一个列式的数据结构。一个 Page 对象由多个 Block 组成,每个 Block 代表一个字段的多行数据。一个Page最大为1MB,最多包含16*1024行数据。
-
Exchange
两个 Stage 之间通过 Exchange 模块进行数据交换。实际的数据传输过程出现在两个 Task 之间。通常,下游的 Task 会通过其上的 Exchange Client 模块从其上游 Task 的 Output Buffer 中拉去数据。拉取的数据以 Split 为单位传递给 Driver 进行处理。
-
命令行工具
通过SSH登入EMR集群,执行下面对命令进入Presto控制台:
试用
$ presto --server emr-header-1:9090 --catalog hive --schema default --user hadoop高安全集群使用如下命令形式:
试用
$ presto --server https://emr-header-1:7778 \
--enable-authentication \
--krb5-config-path /etc/krb5.conf \
--krb5-keytab-path /etc/ecm/presto-conf/presto.keytab \
--krb5-remote-service-name presto \
--keystore-path /etc/ecm/presto-conf/keystore \
--keystore-password 81ba14ce6084 \
--catalog hive --schema default \
--krb5-principal presto/[email protected]- XXXX 为集群的 ecm id,为一串数字,可以通过 cat /etc/hosts 获取。
- 81ba14ce6084 为 /etc/ecm/presto-conf/keystore 的默认密码,建议部署后替换为自己的keystore.
接下来就可已在该控制台下执行以下命令:
试用
presto:default> show schemas;
Schema
--------------------
default
hive
information_schema
tpch_100gb_orc
tpch_10gb_orc
tpch_10tb_orc
tpch_1tb_orc
(7 rows)执行 presto --help 命令可以获取控制台的帮助,各个参数对解释如下所示:
试用
--server # 指定Coordinator的URI
--user # 设置用户名
--catalog # 指定默认的Catalog
--schema # 指定默认的Schema
--execute # 执行一条语句,然后退出
-f , --file # 执行一个SQL文件,然后退出
--debug # 显示调试信息
--client-request-timeout # 指定客户端超时时间,默认为2m
--enable-authentication # 使能客户端认证
--keystore-password # KeyStore密码
--keystore-path # KeyStore路径
--krb5-config-path # Kerberos配置文件路径(默认为/etc/krb5.conf)
--krb5-credential-cache-path # Kerberos凭据缓存路径
--krb5-keytab-path # Kerberos Key table路径
--krb5-principal # 要使用的Kerberos principal
--krb5-remote-service-name # 远程Kerberos节点名称
--log-levels-file # 调试日志配置文件路径
--output-format # 批量导出的数据格式,默认为 CSV
--session # 指定回话属性,格式如下 key=value
--socks-proxy # 设置代理服务器
--source # 设置查询的Source
--version # 显示版本信息
-h, --help # 显示帮组信息 使用JDBC
Java应用可以使用Presto提供的JDBC driver连接数据库进,使用方式与一般RDBMS数据库差别不大。
- 在Maven中引入可以在pom文件中加入如下配置引入Presto JDBC driver:
试用
com.facebook.presto presto-jdbc 0.187 - Driver类名
Presto JDBC driver类为
com.facebook.presto.jdbc.PrestoDriver。 - 连接字串可以使用如下格式的连接字串:
试用
例如:jdbc:presto://: /[CATALOG]/[SCHEMA] 试用
jdbc:presto://emr-header-1:9090 # 连接数据库,使用默认的Catalog和Schema jdbc:presto://emr-header-1:9090/hive # 连接数据库,使用Catalog(hive)和默认的Schema jdbc:presto://emr-header-1:9090/hive/default # 连接数据库,使用Catalog(hive)和Schema(default) - 连接参数
Presto JDBC driver支持很多参数,这些参数既可以通过 Properties 对象传入,也可以通过URL参数传入,这两种方式是等价的。
通过 Properties 对象传入示例:试用
通过URL参数传入示例:String url = "jdbc:presto://emr-header-1:9090/hive/default"; Properties properties = new Properties(); properties.setProperty("user", "hadoop"); Connection connection = DriverManager.getConnection(url, properties); ......试用
下面对各个参数进行说明:String url = "jdbc:presto://emr-header-1:9090/hive/default?user=hadoop"; Connection connection = DriverManager.getConnection(url); ......参数名称 格式 参数说明 user STRING 用户名 password STRING 密码 socksProxy \:\ SOCKS代理服务器地址,如localhost:1080 httpProxy \:\ HTTP代理服务器地址,如localhost:8888 SSL true\ 是否使用HTTPS连接,默认为 false SSLTrustStorePath STRING Java TrustStore文件路径 SSLTrustStorePassword STRING Java TrustStore密码 KerberosRemoteServiceName STRING Kerberos服务名称 KerberosPrincipal STRING Kerberos principal KerberosUseCanonicalHostname true\ 是否使用规范化主机名,默认为 false KerberosConfigPath STRING Kerberos配置文件路径 KerberosKeytabPath STRING Kerberos KeyTab文件路径 KerberosCredentialCachePath STRING Kerberos credential缓存路径 - Java示例下面给出一个Java使用Presto JDBC driver的例子。
试用
..... // 加载JDBC Driver类 try { Class.forName("com.facebook.presto.jdbc.PrestoDriver"); } catch(ClassNotFoundException e) { LOG.ERROR("Failed to load presto jdbc driver.", e); System.exit(-1); } Connection connection = null; Statement statement = null; try { String url = "jdbc:presto://emr-header-1:9090/hive/default"; Properties properties = new Properties(); properties.setProperty("user", "hadoop"); // 创建连接对象 connection = DriverManager.getConnection(url, properties); // 创建Statement对象 statement = connection.createStatement(); // 执行查询 ResultSet rs = statement.executeQuery("select * from t1"); // 获取结果 int columnNum = rs.getMetaData().getColumnCount(); int rowIndex = 0; while (rs.next()) { rowIndex++; for(int i = 1; i <= columnNum; i++) { System.out.println("Row " + rowIndex + ", Column " + i + ": " + rs.getInt(i)); } } } catch(SQLException e) { LOG.ERROR("Exception thrown.", e); } finally { // 销毁Statement对象 if (statement != null) { try { statement.close(); } catch(Throwable t) { // No-ops } } // 关闭连接 if (connection != null) { try { connection.close(); } catch(Throwable t) { // No-ops } } }
其它参考:
- 快速入门
- 数据类型
- 常用函数和操作符
- SQL语句
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator(调度节点)和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker
目录:
- 环境基本要求
- 集群规划
- 连接器
- 安装步骤
- config.properties
- node.properties
- jvm.config
- log.properties
- Catalog Properties
- 运行presto
- 测试验证
环境基本要求
- Linux or Mac OS X
- Java 8, 64-bit
- Python 2.4+
集群规划
- hdp1 ( 192.169.1.89) : 调度节点
- hdp2 (192.169.1.2) : worker节点
- hdp3 (192.169.1.99) : worker节点
连接器
- Presto支持从以下版本的Hadoop中读取Hive数据:支持以下文件类型:Text, SequenceFile, RCFile, ORC
- Apache Hadoop 1.x (hive-hadoop1)
- Apache Hadoop 2.x (hive-hadoop2)
- Cloudera CDH 4 (hive-cdh4)
- Cloudera CDH 5 (hive-cdh5)
- 此外,需要有远程的Hive元数据。 不支持本地或嵌入模式。 Presto不使用MapReduce,只需要HDFS
安装步骤
- 下载 presto-server-0.100, ( 下载地址:https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.100/presto-server-0.100.tar.gz)
- 将 presto-server-0.100.tar.gz 上传至linux主机,解压后的文件目录结构如下(称为安装目录):Presto需要一个用于存储日志、本地元数据等的数据目录。 建议在安装目录的外面创建一个数据目录。这样方便Presto进行升级,如:/presto/data
- 在安装目录中创建一个etc目录, 在这个etc目录中放入以下配置文件:
-
- config.properties :Presto 服务配置
- node.properties :环境变量配置,每个节点特定配置
- jvm.config :Java虚拟机的命令行选项
- log.properties: 允许你根据不同的日志结构设置不同的日志级别
- catalog目录 :每个连接者配置(data sources)
config.properties
- 包含了Presto server的所有配置信息。 每个Presto server既是一个coordinator也是一个worker。 但是在大型集群中,处于性能考虑,建议单独用一台机器作为 coordinator,一个coordinator的etc/config.properties应该至少包含以下信息:
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=9000 task.max-memory=1GB discovery-server.enabled=true discovery.uri=http://192.169.1.89:9000
-
-
coordinator:指定是否运维Presto实例作为一个coordinator(接收来自客户端的查询情切管理每个查询的执行过程)
- node-scheduler.include-coordinator:是否允许在coordinator服务中进行调度工作, 对于大型的集群,在一个节点上的Presto server即作为coordinator又作为worke将会降低查询性能。因为如果一个服务器作为worker使用,那么大部分的资源都会被worker占用,那么就不会有足够的资源进行关键任务调度、管理和监控查询执行
- http-server.http.port:指定HTTP server的端口。Presto 使用 HTTP进行内部和外部的所有通讯
- task.max-memory=1GB:一个单独的任务使用的最大内存 (一个查询计划的某个执行部分会在一个特定的节点上执行)。 这个配置参数限制的GROUP BY语句中的Group的数目、JOIN关联中的右关联表的大小、ORDER BY语句中的行数和一个窗口函数中处理的行数。 该参数应该根据并发查询的数量和查询的复杂度进行调整。如果该参数设置的太低,很多查询将不能执行;但是如果设置的太高将会导致JVM把内存耗光
- discovery-server.enabled:Presto 通过Discovery 服务来找到集群中所有的节点。为了能够找到集群中所有的节点,每一个Presto实例都会在启动的时候将自己注册到discovery服务。Presto为了简化部署,并且也不想再增加一个新的服务进程,Presto coordinator 可以运行一个内嵌在coordinator 里面的Discovery 服务。这个内嵌的Discovery 服务和Presto共享HTTP server并且使用同样的端口
- discovery.uri:Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri。注意:这个URI一定不能以“/“结尾
-
- 注意:上例中如果是worker的config.properties,配置应该如下:
coordinator=false http-server.http.port=9000 query.max-memory=1GB discovery.uri=http://192.169.1.89:9000
-
如果用一台机器进行测试,那么这一台机器将会即作为coordinator,也作为worker。配置文件将会如下所示:
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=9000 task.max-memory=1GB discovery-server.enabled=true discovery.uri=http://192.169.1.89:9000
node.properties
- 包含针对于每个节点的特定的配置信息。 一个节点就是在一台机器上安装的Presto实例,etc/node.properties配置文件至少包含如下配置信息
node.environment=test node.id=ffffffff-ffff-ffff-ffff-ffffffffff01 node.data-dir=/presto/data
-
node.environment: 集群名称, 所有在同一个集群中的Presto节点必须拥有相同的集群名称
- node.id: 每个Presto节点的唯一标示。每个节点的node.id都必须是唯一的。在Presto进行重启或者升级过程中每个节点的node.id必须保持不变。如果在一个节点上安装多个Presto实例(例如:在同一台机器上安装多个Presto节点),那么每个Presto节点必须拥有唯一的node.id
- node.data-dir: 数据存储目录的位置(操作系统上的路径), Presto将会把日期和数据存储在这个目录下
jvm.config
- 包含一系列在启动JVM的时候需要使用的命令行选项。这份配置文件的格式是:一系列的选项,每行配置一个单独的选项。由于这些选项不在shell命令中使用。 因此即使将每个选项通过空格或者其他的分隔符分开,java程序也不会将这些选项分开,而是作为一个命令行选项处理,信息如下:

-server -Xmx16G -XX:+UseConcMarkSweepGC -XX:+ExplicitGCInvokesConcurrent -XX:+CMSClassUnloadingEnabled -XX:+AggressiveOpts -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=kill -9 %p -XX:ReservedCodeCacheSize=150M
-
log.properties
- 这个配置文件中允许你根据不同的日志结构设置不同的日志级别。每个logger都有一个名字(通常是使用logger的类的全标示类名). Loggers通过名字中的“.“来表示层级和集成关系,信息如下:
com.facebook.presto=DEBUG
- 配置日志等级,类似于log4j。四个等级:DEBUG,INFO,WARN,ERROR
Catalog Properties
- 通过在etc/catalog目录下创建catalog属性文件来完成catalogs的注册。 例如:可以先创建一个etc/catalog/jmx.properties文件,文件中的内容如下,完成在jmxcatalog上挂载一个jmxconnector
connector.name=jmx
-
在etc/catalog目录下创建hive.properties,信息如下:
connector.name=hive-hadoop2 hive.metastore.uri=thrift://192.169.1.89:9083 hive.config.resources=/etc/hadoop/2.4.2.0-258/0/core-site.xml, /etc/hadoop/2.4.2.0-258/0/hdfs-site.xml hive.allow-drop-table=true
运行presto
- 在安装目录的bin/launcher文件,就是启动脚本。Presto可以使用如下命令作为一个后台进程启动:
bin/launcher start
- 也可以在前台运行, 可查看具体的日志
bin/launcher run
- 停止服务进程命令
bin/laucher stop
- 查看进程: ps -aux|grep PrestoServer 或 jps
测试验证
- 下载 presto-cli-0.100-executable.jar:Presto CLI为用户提供了一个用于查询的可交互终端窗口。CLI是一个 可执行 JAR文件, 这也就意味着你可以像UNIX终端窗口一样来使用CLI ,下载地址(https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.100/presto-cli-0.100-executable.jar)
- 文件下载后,重名名为 presto , 使用 chmod +x 命令设置可执行权限
chmod +x /presto/presto.jar
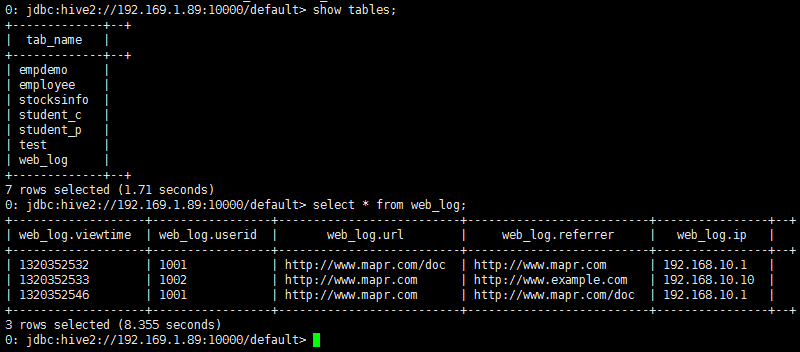
- 在hive中查一下hive default库中的表, 结果如下图:
- 退出hive cli,进入presto cli
- 命令: ./presto.jar --server 192.168.1.89:9000 --catalog hive --schema default (如果要调度,可加 --debug, 红色标识的项必须与 config.properties 配置文件中的uri 地址一致,配置的IP就用IP,机器名就用机器名)
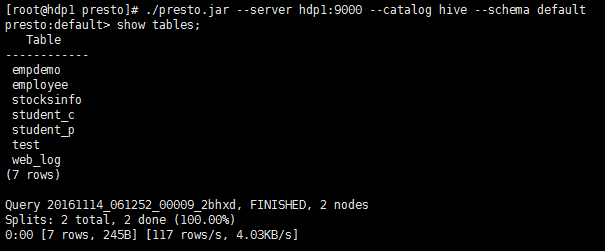
- 命令: show tables; (查看 hive defult 库中表结构),如下:
- 或者使用下面命令:
- ./presto.jar --server 192.168.1.89:9000 --catalog hive
- show tables from default;
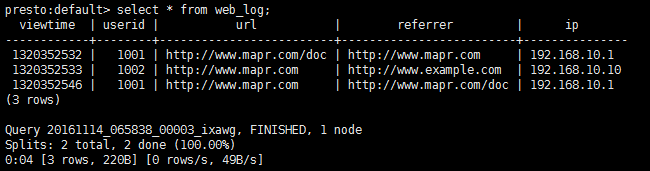
- 命令: select * from web_log; (查询上面创建Hive表的结果)
- 命令: quit; 退出presto cli
分类: Presto
2.导出数据
presto可以指定导出数据的格式,但是不能直接指定导出数据的文件地址,需要用Linux的命令支持。
下面是一个带有header的csv数据导出。
bin/presto --execute "sql statement" --output-format CSV_HEADER > test1.csv3.跨源join
查询mysql和hive的数据,并做join。
这里不再写出sql了。
注意:
- 需要指定catalog。
- 不同库之间做join的时候需要主要字段类型,比如userid,在hive中可能是String,在mysql可能是int,这时候需要使用cast转一下格式,然后再做等于的比较。
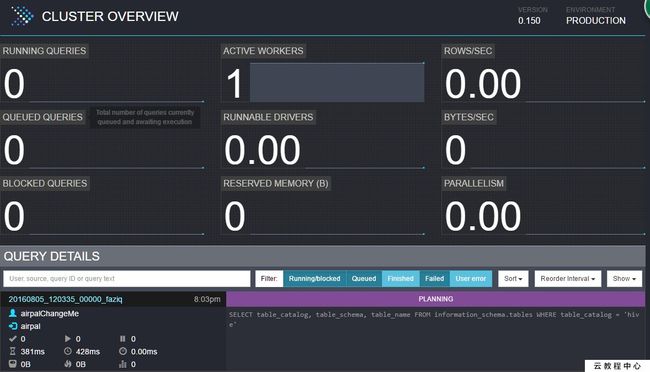
4.管理界面
默认的管理界面的端口是8080。看着很炫酷。
5.airpal
在airpal上提交query倒是也挺方便,但是有不少bug,目测更新的比较慢,跟不上presto的更新速度。用过就知道了…..
来源:
http://blog.csdn.net/zhaodedong/article/details/52132318
Presto调优
默认的Presto配置满足绝大部分的负载要求,下面的一些信息会帮助你解决Presto集群环境中的一些特殊的性能问题。
配置文件
task.info-refresh-max-wait
控制过期task信息,使用在调度中。增加这个值能够减少coordinator 的CPU负载,但是可能导致split调度不是最优的。
task.max-worker-threads
设置workers处理splits时使用的线程数。如果Worker的CPU利用率低并且所有的线程都在使用,那么增加这个值可以提高吞吐量,但是会增加堆内存空间大小。活动线程的数量可以通过
com.facebook.presto.execution.taskexecutor.runningsplitsJMX统计
distributed-joins-enabled
使用hash分布式join代替broadcast广播的join。分布式join需要根据join key的hash值来重新分布表,这可能比广播join慢,但是可以利用更大的表之间join操作。广播的join需要关接的右边的表加载到每一个节点的内存中,然而分布式join是将关联的右边的表加载到分布式内存中。我们可以在每一个查询中设置distributed_join 的session属性值来进行选择。
node-scheduler.network-topology
当调度split时,设置使用的网络拓扑。
当调度split时,“legacy”将忽略拓扑,“flat”将尝试在同一个节点调度split。
JVM配置
下面的参数可以帮助诊断GC问题:
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics=2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount=1
7.3 队列配置
队列规则定义在一个Json文件中,用于控制能够提交给Presto的查询的个数,以及每个队列中能够同时运行的查询的个数。用config.properties中的query.queue-config-file来指定Json配置文件的名字。
队列规则如果定义了多个队列,查询会按顺序依次进入不同的队列中。队列规则将按照顺序进行处理,并且使用第一个匹配上的规则。在以下的配置例子中,有5个队列模板,在user.${USER}队列中,${USER}表示着提交查询的用户名。同样的${SOURCE}表示提交查询的来源。
同样有如下的规则定义了哪一类查询会进入哪一个队列中:
· 第一条规则将使bob成为管理员,bob提交的查询进入admin队列。
· 第二条规则表示,来源包含pipeline的查询将首先进入用户的个人队列中,然后进入pipeline队列。当一个查询进入一个新的队列后,直到查询结束才会离开之前的队列。
· 最后一个规则包含所有的队列,将所有的查询加入到个人用户队列中
所有这些规则实现了这样的策略,bob是一个管理员,而其他用户需要遵循以下的限制:
1. 每个用户最多能同时运行5个查询,另外可以运行一个pipeline。
2. 最多能同时运行10个pipeline来源的查询。
3. 最多能同时运行100个其他查询。
{
"queues": {
"user.${USER}": {
"maxConcurrent": 5,
"maxQueued": 20
},
"user_pipeline.${USER}": {
"maxConcurrent": 1,
"maxQueued": 10
},
"pipeline": {
"maxConcurrent": 10,
"maxQueued": 100
},
"admin": {
"maxConcurrent": 100,
"maxQueued": 100
},
"global": {
"maxConcurrent": 100,
"maxQueued": 1000
}
},
"rules": [
{
"user": "bob",
"queues": ["admin"]
},
{
"source": ".*pipeline.*",
"queues": [
"user_pipeline.${USER}",
"pipeline",
"global"
]
},
{
"queues": [
"user.${USER}",
"global"
]
}
]
}
---------------------
0. 计算相关序列化
presto内部使用jackson-core进行序列化. 由于是分布式环境, 因此需要将每个split要计算的元数据序列化后传输到各个worker节点. 开发时需要注意凡是要被传输到其他节点执行的信息都要序列化.
1. ConnectorTableHandle, ColumnHandle 和 ConnectorTableMetadata , ColumnMetadata 有什么区别?
XXXMetadata是用来表示table的元数据的, 包括 column_name 和 type, 信息是catalog 不相关的XXXHandle是用来表示特定的catalog的table/column的信息, 包含column name 和数据类型. 简单来说,XXXHandle就是XXXMetadata+connectorId. 最必需的信息是connectorId. 虽然XXXHandle默认是一个Marker Interface(就是没有任何一个方法), 但该数据是会被序列化后传输到worker节点的, 因此connectorId 这个属性是绕不过的. 参见下面connectorId是干嘛呢
2. connectorId 是干嘛的
presto中数据的组织方式是三层: catalog-->schema --> table. 一个catalog 只能是一种connector, 通过配置文件中connector.name 指定, 例如hive的一个catalog的配置:
connector.name=hive-cdh5
hive.metastore.uri=thrift://localhost:10000
hive.config.resources=/home/ec2-user/presto/etc/core-site.xml,/home/ec2-user/presto/etc/hdfs-site.xml
hive.s3.pin-client-to-current-region=true
而catalog 的名称就是配置文件的名称(去除后缀). 在Connector中, connectorId就是这个对应的catalog的名称. XXXHandle 中connectorId的作用就是worker节点中根据这个 ID 查找对应的配置从而执行计算
3. ConnectorSplit
很简单, 就是coordinator 计算split后要将各个任务序列化后传输给各个worker节点计算. 因此实现的时候仅仅把分块计算所需的任何数据都扔到这个实现类里面, 搞成可序列化即可.
4. Guice 不了解怎么办?
看过presto源代码的都知道presto是使用Guice做为依赖注入框架, 不了解怎么办? 那就不用. presto 使用了java的Service Provider Interfaces 组织connector, 自己的connector 不使用guice 没有任何关系.
5. Presto如何初始化connector?
Service Provider Interfaces 有规范的, 简单讲就是在src/main/resources/META-INF/services/ 中添加一个名为 com.facebook.presto.spi.Plugin 的文件, 里面写你的connector中实现了com.facebook.presto.spi.Plugin 这个接口的类
总结
在QCon2015 中 开源大数据在Facebook与Dropbox的实践 得知, Presto 最初的原型是一个工程师一个月做出来的, 后面经过历代版本的优化至今. 代码质量非常高, 就是用了一个估计是几个哥们儿自己写的框架airlift, 文档比较少. 但正是这种connector的结构, 可以让我们很容易构建一个可以让异构数据源之间轻松 join 的数据平台, 减少数据接入的工作.