CDH 安装 presto集成hive和mysql
原创地址:https://blog.csdn.net/qq595662096/article/details/88077211
Presto是由Facebook开源,完全基于内存的并行计算以及分布式SQL交互式查询引擎。它可以共享Hive的元数据,然后直接访问HDFS中的数据,同时支持Hadoop中常见的文件格式比如文本,ORC和Parquet。同Impala一样,作为Hadoop之上的SQL交互式查询引擎,通常比Hive要快5-10倍。另外,Presto不仅可以访问HDFS,还可以访问RDBMS中的数据,以及其他数据源比如CASSANDRA。
适合场景:PB级海量数据复杂分析,交互式SQL查询,⽀持跨数据源查询
不适合场景:多个大表的join操作,因为presto是基于内存的,join操作输入小但产生的中间数据大,在内存里可能放不下
与Hive的区别:
(1)hive是一个数据仓库,提供存储服务,但只能访问HDSF的数据,presto是一个分布式的查询引擎,并不提供数据的储存服务,为此,presto是一个插拔式的设计思路,支持多种数据源,包括hive,hdfs,mysql,等。
(2)两者的基本架构
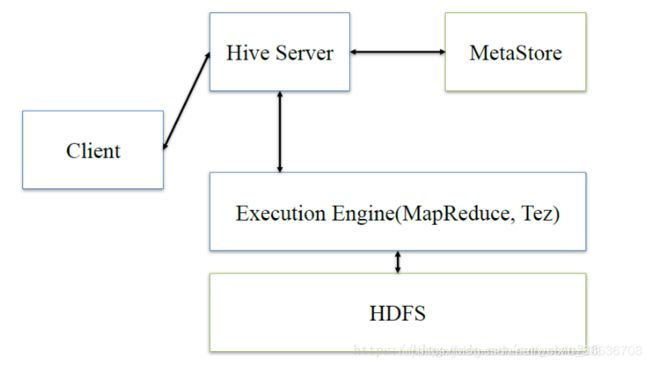
hive:Client将查询请求发送到hive Service,它会和Metastor交互,获取表的源信息(如表的位置结构)之后Hive Service会进行语法分析,解析成语法树,变成查询计划,进行优化后将查询计划交给执行引擎(默认是Map reduce),然后翻译成Map Reduce任务来运行。
Presto:presto是在它内部做hive类似的逻辑
2 Presto内部架构
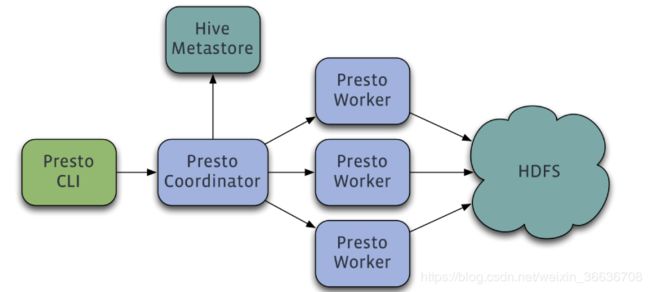
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker
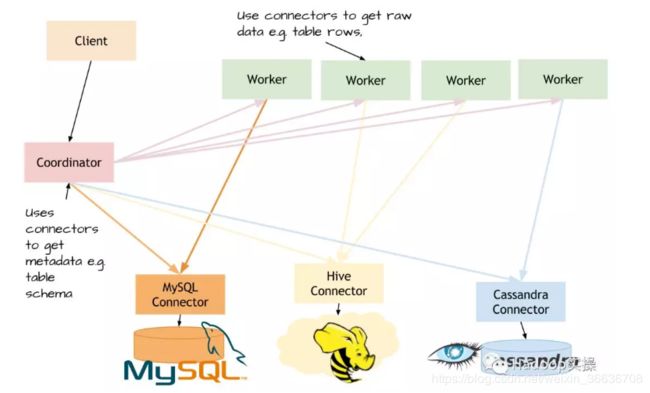
Presto查询引擎是一个Master-Slave的架构模式,由三部分组成:
1.一个 coordinator
2.一个discovery server
3.多个worker
coodinator:用于解析查询sql,生成执行计划,并分发给worker执行。
discovery server:通常内嵌与Coordinator节点中,worker上线后,向discovery server注册。coodinator分发任务前,需要向discovery server获取可以正常工作worker列表。
worker:具体执行任务的工作节点。
presto可以借助hive的元信息找到hdfs上的节点
Presto中SQL运行流程:

step1:当我们执行一条sql查询,coordinator接收到这条sql语句以后,它会有一个sql的语法解析器去把sql语法解析变成一个抽象的语法树(AST),这抽象的语法树它里面只是进行一些语法解析,如果你的sql语句里面,比如说关键字你用的是int而不是Integer,就会在语法解析这里给暴露出来
step2:如果语法是符合sql语法规范,之后会经过一个逻辑查询计划器的组件,他的主要作用是,比如说你sql里面出现的表,他会通过connector的方式去meta里面把表的schema,列名,列的类型等,全部给找出来,将这些信息,跟语法树给对应起来,之后会生成一个物理的语法树节点,这个语法树节点里面,不仅拥有了它的查询关系,还拥有类型的关系,如果在这一步,数据库表里某一列的类型,跟你sql的类型不一致,就会在这里报错.
step3:如果通过,就会得到一个逻辑的查询计划,然后这个逻辑查询计划,会被送到一个分布式的逻辑查询计划器里面,进行一个分布式的解析,分布式解析里面,他就会去把对应的每一个查询计划转化为task
step4:在每一个task里面,他会把对应的位置信息全部给提取出来,交给执行的plan,由plan把对应的task发给对应的worker去执行,这就是整个的一个过程,与hive默认的引擎Mapreduce相比,presto将数据放在内存中,task之间进行数据shuffle时,直接从内存里处理,所以很快。
3 .安装
3.1 Presto的安装基本环境
.Linux或Mac OS X.
.Java 8,64位
.Python 2.4+
连接器:
Presto支持从以下版本的Hadoop中读取Hive数据:支持以下文件类型:Text, SequenceFile, RCFile, ORC
Apache Hadoop 1.x (hive-hadoop1)
Apache Hadoop 2.x (hive-hadoop2)
Cloudera CDH 4 (hive-cdh4)
Cloudera CDH 5 (hive-cdh5)
Cloudera CDH5安装文档:
集群规划:
| IP地址 |
HOSTNAME |
NodeID |
角色 |
| 10.18.100.116 |
utility |
presto-cdh1 |
coordinator |
| 10.18.100.173 |
master |
presto-cdh2 |
worker |
| 10.18.100.174 |
worker1 |
presto-cdh3 |
worker |
| 10.18.100.175 |
worker2 |
presto-cdh4 |
worker |
3.2安装JDK1.8
presto-server-0.216需要1.8.0_151+版本的,如果默认的版本低于1.8.0_151,则启动presto时修改Java的临时环境变量(临时环境变量只在本终端有效,不影响Java的默认版本),修改方式见 3.4.3 在/opt/cloudera/parcels/presto/bin/launcher文件如下位置添加JAVA环境变量,使用这种方式就可以直为Presto服务指定JAVA环境,而不会影响服务器上其它服务的JAVA环境。
3.3 安装python
一般的系统会自带python,我用的是自带的Python2.7

3.4安装presto
Presto服务的安装目录为/opt/cloudera/parcels/presto
1.在Presto官网下载presto-server-0.216.tar.gz安装包,下载地址:
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.216/presto-server-0.216.tar.gz
将下载好的presto-server-0.216.tar.gz上传至Presto集群的所有服务器上
2.将presto-server-0.216.tar.gz压缩包解压至/opt/cloudera/parcels目录
tar -zxvf presto-server-0.216.tar.gz -C /opt/cloudera/parcels/
为presto-server-0.216创建persto软链接
ln -s presto-server-0.216 presto

该步骤需要在Presto集群的所有节点进行操作,这里以utility节点为例。
3.在/opt/cloudera/parcels/presto/bin/launcher文件如下位置添加JAVA环境变量用whereis java,java -version,查看linux都有那些版本的java
-
[root@utility ~]
# whereis java
-
java:
/usr/bin
/java /usr
/lib/java /etc/java /usr/
local/java /usr/share/java /app/ins/jdk1.
8.0_171/bin/java /usr/share/man/man1/java.
1.gz
-
[root@utility ~]
# /usr/bin/java -version
-
openjdk version
"1.8.0_191"
-
OpenJDK Runtime Environment (build
1.8.
0_191-b12)
-
OpenJDK
64-Bit Server VM (build
25.191-b12, mixed mode)
/usr/bin/java下是 1.8.0_191版本,在 vim presto/bin/launcher 中增加一下内容:

使用这种方式就可以直为Presto服务指定JAVA环境,而不会影响服务器上其它服务的JAVA环境
3.5准备Presto的配置文件并分发
1.在Presto集群所有节点创建/opt/cloudera/pracles/presto/etc目录
新建node.properties文件,内容如下:
-
[
root@utility etc]# vi node.properties
-
node.environment=presto
-
node.id=presto-cdh1
-
node.
data-dir=/
data/disk1/presto
配置说明:
node.environment:集群名称。所有在同一个集群中的Presto节点必须拥有相同的集群名称。建议环境名称直接用presto。
node.id:每个Presto节点的唯一标示。每个节点的node.id都必须是唯一的。在Presto进行重启或者升级过程中每个节点的node.id必须保持不变。如果在一个节点上安装多个Presto实例(例如:在同一台机器上安装多个Presto节点),那么每个Presto节点必须拥有唯一的node.id。
node.data-dir:数据存储目录的位置(操作系统上的路径)。Presto将会把日期和数据存储在这个目录下。
将node.properties拷贝至Presto集群的所有节点
注意:这里拷贝了需要将Presto所有节点的node.id修改为对应节点的ID。
2.配置Presto的JVM参数,创建jvm.config文件,内容如下:
-
[root@utility etc]# vi jvm.config
-
-server
-
-Xmx8G
-
-XX:+UseG1GC
-
-XX:G1HeapRegionSize=32M
-
-XX:+UseGCOverheadLimit
-
-XX:+ExplicitGCInvokesConcurrent
-
-XX:+HeapDumpOnOutOfMemoryError
-
-XX:+ExitOnOutOfMemoryError
配置文件的格式是:一系列的选项,每行配置一个单独的选项。由于这些选项不在shell命令中使用。因此即使将每个选项通过空格或者其他的分隔符分开,java程序也不会将这些选项分开,而是作为一个命令行选项处理。(就想下面例子中的OnOutOfMemoryError选项)。
由于OutOfMemoryError将会导致JVM处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是将dump headp中的信息(用于debugging),然后强制终止进程。
Presto会将查询编译成字节码文件,因此Presto会生成很多class,因此我们我们应该增大Perm区的大小(在Perm中主要存储class)并且要允许Jvm class unloading。
3.新建日志文件log.properties,内容如下:
-
[root@utility etc]
# vi log.properties
-
-
com.facebook.presto=INFO
将jvm.config和log.properties配置文件拷贝至Presto集群所有节点
4.创建config.properties文件
该配置文件包含了Presto Server的所有配置信息。每个Presto Server既是Coordinator也是一个Worker。在大型集群中,处于性能考虑,建议单独用一台服务器作为Coordinator。
coordinator节点的配置如下:
-
[root@utility etc]# vi coordinator-config.properties
-
coordinator=
true
-
node-scheduler.include-coordinator=
true
-
http-server.http.port=
9999
-
query.
max-memory=4GB
-
query.
max-memory-per-node=1GB
-
discovery-server.enabled=
true
-
discovery.uri=http:
//10.18.100.116:9999
worker节点的配置如下:
-
[root@utility etc]# vi worker-config.properties
-
coordinator=
false
-
http-server.http.port=
9999
-
query.
max-memory=4GB
-
query.
max-memory-per-node=1GB
-
discovery.uri=http:
//10.18.100.116:9999
配置项说明:
coordinator:指定是否运维Presto实例作为一个coordinator(接收来自客户端的查询情切管理每个查询的执行过程)。
node-scheduler.include-coordinator:是否允许在coordinator服务中进行调度工作。对于大型的集群,在一个节点上的Presto server即作为coordinator又作为worke将会降低查询性能。因为如果一个服务器作为worker使用,那么大部分的资源都不会被worker占用,那么就不会有足够的资源进行关键任务调度、管理和监控查询执行。
http-server.http.port:指定HTTP server的端口。Presto 使用 HTTP进行内部和外部的所有通讯。
discovery.uri:Discoveryserver的URI。由于启用了Prestocoordinator内嵌的Discovery 服务,因此这个uri就是Prestocoordinator的uri。修改example.net:9999,根据你的实际环境设置该URI。注意:这个URI一定不能以“/“结尾。
将coordinator-config.properties文件拷贝至utility节点,并重命名为config.properties
将worker-config.properties文件拷贝至Presto集群的worker节点,并重命名为config.properties
5.配置Catalog Properties:
Presto通过connectors访问数据。这些connectors挂载在catalogs上。connector可以提供一个catalog中所有的schema和表。
例如: Hive connector 将每个hive的database都映射成为一个schema, 所以如果hive connector挂载到了名为hive的catalog, 并且在hive的web有一张名为clicks的表, 那么在Presto中可以通过hive.web.clicks来访问这张表。
通过在etc/catalog目录下创建catalog属性文件来完成catalogs的注册。
-
[root@master catalog]
# vi jmx.properties
-
connector.name=jmx
6.Presto需要一个用于存储日志、本地元数据等的数据目录。建议在安装目录的外面创建一个数据目录。本次安装我用的存储路径是/data/disk1/presto
以上在是在etc中创建的Presto的所有配置文件,这些文件的内容是:
.node.properties:每个节点的环境变量配置
.jvm.config:jvm参数 ,Java虚拟机的命令行选项
.config.properties:Presto 服务配置
.log.properties:Server参数 ,允许你根据不同的日志结构设置不同的日志级别
.catalog:每个连接者配置(data sources)
至此就完成了Presto集群的部署。
4 .Presto服务启停
1.在Presto集群的所有节点执行如下命令启动Presto服务
-
[
root@utility bin]
# /opt/cloudera/parcels/presto/bin/launcher start
-
Already running
as
8908
2.在Presto集群的所有节点执行如下命令来停止Presto服务
[root@utility bin]# /opt/cloudera/parcels/presto/bin/launcher stop
关于Presto的更多命令,可以通过如下命令查看
[root@utility bin]# /opt/cloudera/parcels/presto/bin/launcher --help
web端访问:http://10.18.100.116:9999(config.properties文件中配置的discovery.uri=http://10.18.100.116:9999)

5.presto集成各数据库
Presto与各数据库的集成使用Presto提供的Presto CLI,该CLI是一个可执行的JAR文件,也意味着你可以想UNIX终端窗口一样来使用CLI。
下载Presto的presto-cli-0.216-executable.jar,并重命名为presto放到presto/bin/ 目录下,并赋予可以执行权限
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.216/presto-cli-0.216-executable.jar
-
[root@utility bin]#
mv
presto-cli-0
.216-executable
.jar
presto
-
[root@utility bin]#
chmod +
x
presto
-
[root@utility bin]#
ll
presto
-
-rwxr-xr-x 1
qmjkdw
qmjkdw 15209119 2月 22 14
:38
presto
然后执行:
-
[root@utility bin]
#$ ./presto --server 10.18.100.116:9999 --catalog hive
-
presto> show schemas;
#查看数据库
-
presto>
use
default;
-
presto:
default> show tables;
#查看表
5.1 集成hive
在presto-server-0.216/etc/catalog下创建hive.properties文件,该文件与Hive服务集成使用,内容如下:
-
[
root@utility catalog]
# vi hive.properties
-
connector.name=hive-hadoop2
-
hive.metastore.uri=thrift:
//utility:9083
connector.name=hive-hadoop2 这个不是随便写的 应该暂时支持的hive-hadoop2
配置项解释:
hive.metastore.uri 内容对应 hive-site.xml 中添加的hive.metastore.uris配置:
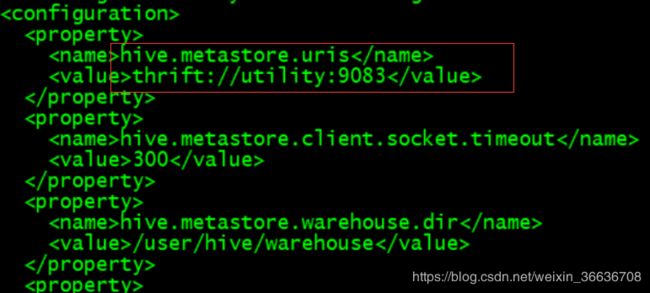
将hive.properties配置文件拷贝至Presto集群所有节点/opt/cloudera/parcels/presto/etc/catalog目录下
重启Presto服务,在Presto集群所有节点执行如下命令:
[root@utility bin]# /opt/cloudera/parcels/presto/bin/launcher restart
Presto与Hive集成测试
在命令行执行命令访问Hive库:
-
[root@utility bin]# ./presto --
server
10.18
.100
.116:
9999 --catalog=hive --schema=
default
-
-
presto:
default> show tables;
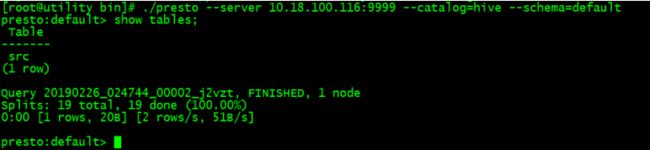
-
[root@utility bin]
# ./presto --server 10.18.100.116:9999 --catalog hive
-
presto> show schemas;

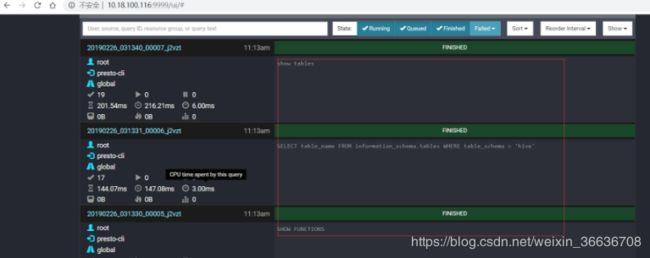
登录Presto的9999界面查看SQL执行记录

5.2 集成mysql
在presto-server-0.216/etc/catalog下创建mysql.properties文件,包含信息如下:
-
[
root@utility catalog]
# vi mysql.properties
-
connector.name=mysql
-
connection-url=jdbc:mysql:
//utility:3306
-
connection-user=root
-
connection-password=root
Presto与mysql集成测试
在命令行执行命令访问mysql库:
-
[root@utility bin]
# ./presto --server 10.18.100.116:9999 --catalog mysql
-
presto> show schemas;
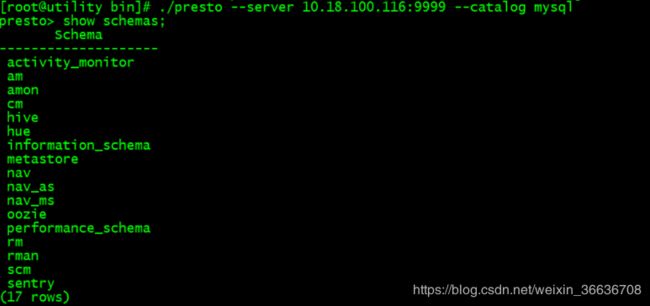
登录Presto的9999界面查看SQL执行记录
6.总结:
1.在指定Presto的node.environment名称时需要注意,不能包含特殊字符如“-”,否则在启动时会报错“Error: Constraint violation with property prefix'': environment is malformed”
2.Presto服务和Presto CLI均是JAVA实现,所以在部署前需要安装好JAVA的环境
3.如果集群启用了Sentry,在访问hive表时,需要为presto用户授权,否则访问表时会报没有权限读写HDFS目录。

4.如果worker1,2上启动时报 :
Path exists and is not a symlink:/data/disk1/presto/etc
则将/data/disk1/presto/下的所有文件删除。
5.如果出现Configuration property 'task.max-memory' was not used
将work的配置删除后再设置