Spring动态数据源配置
一 背景
在互联网系统中,随着用户量的增长,单数据源通常无法满足系统的负载要求。因此为了解决用户量增长带来的压力,在数据库层面会采用读写分离技术和数据库拆分等技术。
读写分离就是就是一个Master数据库,多个Slave数据库,Master数据库负责数据的写操作,slave库负责数据读操作,通过slave库来降低Master库的负载。
因为在实际的应用中,数据库都是读多写少(读取数据的频率高,更新数据的频率相对较少),而读取数据通常耗时比较长,占用数据库服务器的CPU较多,从而影响用户体验。
我们通常的做法就是把查询从主库中抽取出来,采用多个从库,使用负载均衡,减轻每个从库的查询压力。同时随着业务的增长,会对数据库进行拆分,根据业务将业务相关的数据库表拆分到不同的数据库中。
二 Spring 框架
Spring动态多数据源的整体框架
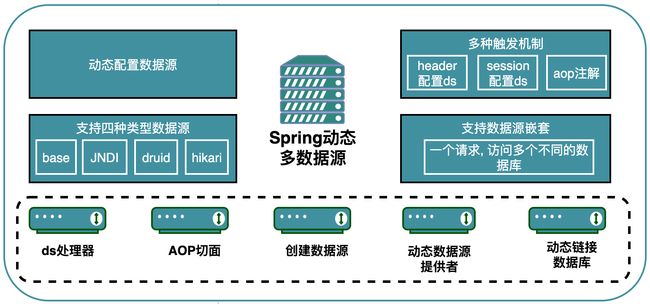
上图中虚线框部分是Spring动态多数据源的几个组成部分
ds处理器
aop切面
创建数据源
动态数据源提供者
动态连接数据库
除此之外,还可以看到如下信息:
Spring动态多数据源是通过动态配置配置文件的方式来指定多数据源的。
Spring动态多数据源支持四种类型的数据:base数据源,jndi数据源,druid数据源,hikari数据源。
多种触发机制:通过header配置ds,通过session配置ds,通过spel配置ds,其中ds是datasource的简称。
支持数据源嵌套:一个请求过来,这个请求可能会访问多个数据源,也就是方法嵌套的时候调用多数据源,也是支持的。
三 AOP读写分离实现
具体到开发中,如何方便的实现读写分离呢? 目前常用的有两种方式:
第一种方式是最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。对数据库进行操作时,先根据需求获取dataSource,然后通过dataSource对数据库进行操作。这种方式配置简单,但是缺乏灵活新。
第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:annotation,Spring AOP ,反射。下面会详细的介绍实现方式。
3.1 AbstractRoutingDataSource
在介绍实现方式之前,先准备一些必要的知识,spring的AbstractRoutingDataSource类。AbstractRoutingDataSource这个类是spring2.0以后增加的,我们先来看下AbstractRoutingDataSource的定义:
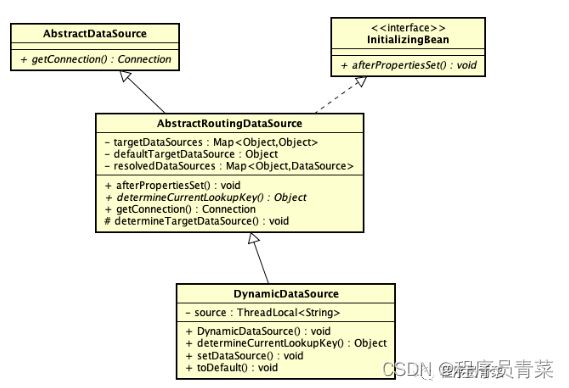
AbstractRoutingDataSource是Spring-jdbc提供一个继承自AbstractDataSource的抽象类,并实现了InitializingBean,因此AbstractRoutingDataSource会在系统启动时自动初始化实例。
3.1.1 关键属性
targetDataSources:存放Key和数据库连接映射关系
defaultTargetDataSource: 默认连接
resolvedDataSources:这个数据是通过targetDataSources构建而成,也是存放Key和数据库连接映射关系。
3.1.2 关键方法
afterPropertiesSet:在初始化Bean时就会执行,将外部传入的targetDataSources构建为内部的resolvedDataSources。
determineTargetDataSource:获取数据库连接getConnection方法会调
determineTargetDataSource来创建连接,它决定Spring容器使用的是哪一个连接。
determineCurrentLookupKey:抽像方法,一个扩展点,由子类实现,获取连接标识。
determineTargetDataSource方法定义如下:
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}最关心的还是下面2句话:
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
determineCurrentLookupKey方法返回lookupKey,resolvedDataSources方法就是根据lookupKey从Map中获得数据源。resolvedDataSources 和determineCurrentLookupKey定义如下:
private Map
protected abstract Object determineCurrentLookupKey()
3.2 DynamicDataSource
继承AbstractRoutingDataSource
用ThreadLocal
存放当前线程的数据源标识
实现determineCurrentLookupKey方法获得当前数据源标记
resolvedDataSources是Map类型,可以把MasterDataSource和SlaveDataSource存到Map中。通过写一个类DynamicDataSource继承AbstractRoutingDataSource,实现其determineCurrentLookupKey() 方法,该方法返回Map的key,master或slave。
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey() {
return DatabaseContextHolder.getCustomerType();
}
}3.3 DatabaseContextHolder
public class DatabaseContextHolder {
public static ThreadLocal contextHolder = new ThreadLocal<>();
static {
contextHolder.set(DataSourceType.Master);
}
public static Object get() {
return contextHolder.get();
}
public static void master() {
contextHolder.set(DataSourceType.Master);
}
public static void slave() {
contextHolder.set(DataSourceType.Slave);
} 从DynamicDataSource 的定义看出,他返回的是DynamicDataSourceHolder.getDataSouce()值,我们需要在程序运行时调用DynamicDataSourceHolder.putDataSource()方法,对其赋值。
3.4 AbstractDataSourceAspect
利用AOP进行数据源切换,AbstractDataSourceAspect类会去获取Mapper方法上的注解,如果没有注解则使用默认数据源,否则得到注解从库,调用DynamicDataSource将数据源标识设置进去,然后调用方法该线程就使用该数据源。
定义注解
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})
public @interface Slave {
}定义枚举
public enum DataSourceType
{
/**
* 主库
*/
MASTER,
/**
* 从库
*/
SLAVE
}定义抽象切入点,具体子类来实现拦截那些包下方法
public abstract class AbstractDataSourceAspect {
//子类实现具体dao包路径
public abstract void readPoint();
public abstract void writePoint();
@Before("readPoint() && @annotation(com.github.Slave)")
public void read() {
DatabaseContextHolder.slave();
}
@After("readPoint() && @annotation(com.github.Slave)")
public void readAfter() {
DatabaseContextHolder.master();
}
@Before("writePoint() && !@annotation(com.github.Slave)")
public void write() {
DatabaseContextHolder.master();
}
}3.5 Datasource多源
使用@Primary来赋予bean更高的优先级
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource dataSource(DataSource masterDataSource, DataSource slaveDataSource, DataSource devOpsDataSource){
Map targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
targetDataSources.put(DataSourceType.SLAVE.name(), slaveDataSource);
return new DynamicDataSource(masterDataSource, targetDataSources);
}
} 3.6 Mapper注解
@Repository
public interface TestMapper {
@Slave
int getUsercount();
}具体服务实现AOP切面
@Aspect
@Component
public class DataSourceAspect extends AbstractDataSourceAspect {
@Override
@Pointcut("execution(public * com.github.dao..*.*(..))")
public void readPoint() {
}
@Override
@Pointcut("execution(public * com.github.dao..*.*(..))")
public void writePoint() {
}
}四 动态数据事务
4.1 Spring 事务原理
相信大家对这个都能说上来一些,Spring 事务是 Spring AOP 的一种具体应用,底层依赖的是动态代理
大致流程类似如下
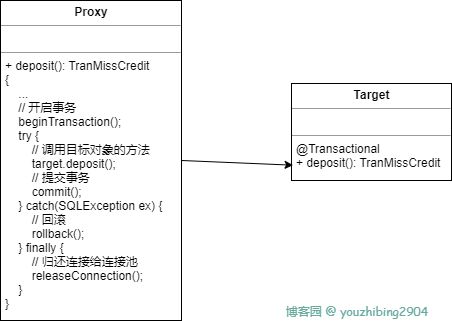
通过代理对象来调用目标对象,而在代理对象中有事务相关的增强处理
4.2 Spring 动态数据源原理

Spring AOP → 将我们指定的 lookupKey 放入 ThreadLocal
ThreadLocal → 线程内共享 lookupKey
DynamicDataSource → 对多数据源进行封装,根据 ThreadLocal 中的 lookupKey 动态选择具体的数据源
4.3 事务问题
既然事务和动态数据源都是 Spring AOP 的具体应用,那么代理就存在先后顺序了
情况1:

情况2:

两者区别:
情况1,动态数据源的前置增强会先执行,DynamicDataSource 需要的 lookupKey 会先于事务绑定到当前线程,那么事务从 DynamicDataSource 获取 Connection 的时候就能根据当前线程的 lookupKey 来动态选择 masterDataSource 还是 slaveDataSource,此种情况是没有问题的。
情况2,事务的前置增强处理会先生效,那么此时开始事务获取的 Connection 从哪来 ? 肯定是从 DynamicDataSource 来,因为我们给事务管理器配置的就是它。
既然是从 DynamicDataSource 获取的 Connection,那 DynamicDataSource 根据 lookupKey 获取 Connection 的时候,会从 masterDataSource 数据源获取还是从 slaveDataSource 数据源获取 ?因为此时还未将 lookupKey 绑定到当前线程,那么 DynamicDataSource 会从默认数据源获取,而我们配置的默认数据源是 slaveDataSource
说白了,此时的动态数据源对事务不生效,事务始终从默认数据源获取 Connection,而没有动态的效果,这就是问题了
4.4 解决方案
总结下问题:如何保证事务中的动态数据源也有动态的效果,也就是如何保证动态数据源的前置增强先于事务
我们知道 Spring AOP 是能够指定顺序的,只要我们显示的指定动态数据源的 AOP 先于 事务的 AOP 即可。
如何指定顺序,常用的方式是实现 Order 接口,或者使用 @Order 注解,Order 的值越小,越先执行,所以我们只需要保证动态数据源的 Order 值小于事务的 Order 值即可
我们先来看看事务的 Order 值默认是多少,在 EnableTransactionManagement 注解中
/**
* Indicate the ordering of the execution of the transaction advisor
* when multiple advices are applied at a specific joinpoint.
* The default is {@link Ordered#LOWEST_PRECEDENCE}.
*/
int order() default Ordered.LOWEST_PRECEDENCE;
默认是最低级别(值非常大),那么我们只需要保证动态数据源的 Order 比这个值小就好,我们就取 1
@Aspect
@Component
@Order(1)
public class DataSourceAspect extends AbstractDataSourceAspect {
@Override
@Pointcut("execution(public * com.github.dao..*.*(..))")
public void readPoint() {
}
@Override
@Pointcut("execution(public * com.github.dao..*.*(..))")
public void writePoint() {
}
}五 总结
不只是动态数据源和事务,只要涉及到多个 AOP,就可能会有顺序问题,这是值得大家注意的
主数据库执行 INSERT UPDATE DELETE 操作,还有部分 SELECT 操作,从数据库只执行 SELECT 操作。默认数据源为主数据源,只有在Dao层 查询方法 上添加注解@Slave才会使用从数据源。具体怎么选,需要大家结合实际情况来决定,因为主从同步多少有延时