CockroachDB架构浅析
本文源自:http://www.cockroachchina.cn/?p=685
这篇文档介绍和说明了cockroachdb的架构,简单明了。
作为Spanner的开源实现,CockroachDB具有支持标准SQL接口,线性扩展,强一致,高可用等重要特性。总体架构如下图所示:
CockroachDB架构图
总览
Node代表一个CockroachDB进程实例,一般情况下一台物理机部署一个CockroachDB实例,一个CockroachDB实例可以配置多个Store, 单个Store与RocksDB实例一一对应,一般情况下一个Store对应一块物理磁盘。
CockroachDB按照范围进行数据切分,最小数据切分单元是Range。Range默认的配置大小是64M, 以3副本的方式分布在各个节点上,副本间通过Raft协议进行数据同步。
元数据管理
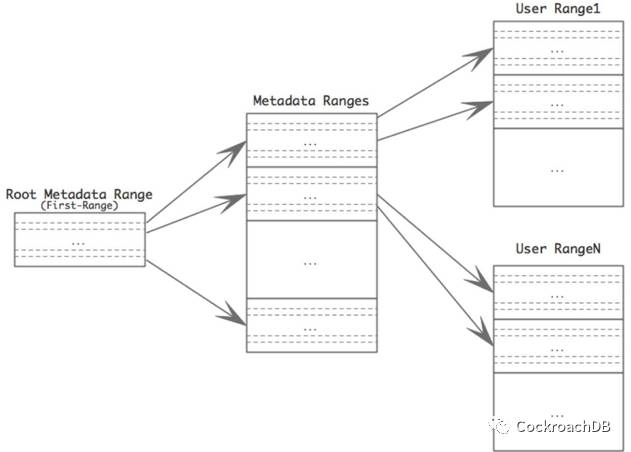
CockroachDB通过两级路由的方式管理元数据,类似普通用户数据的管理方式,元数据也是基于Range进行管理。每条路由元数据约为256B,默认情况下,单个元数据Range可存储256K条路由信息(64MB/256B),那么,CockroachDB集群理论上最大容量为4EB(256K*256K*64MB)。
第一级元数据永远不会发生分裂而且第一级元数据的路由信息会通过Gossip协议同步到各个节点。由于第一级元数据发生变更的几率较小,所以各个节点大部分时间可直接根据本地的元数据信息将请求路由到指定节点处理。
SQL层
CockroachDB支持标准SQL, 当CockroachDB集群的某个节点收到SQL请求时,会经过SQL解析、SQL执行计划生成、SQL执行等重要步骤。
1. 协议层
CockroachDB兼容PostgreSQL协议,对于报文的封装和解析完全按照PostgreSQL的方式进行,所以用户可以直接使用PostgreSQL的客户端访问CockroachDB。
2. SQL解析
CockroachDB对于用户的SQL语句按照PostgreSQL的语法进行解析,解析完成后生成语法树(AST),调用示例类似 :
func (p *Parser) Parse(sql string)
(stmts StatementList, err error) {
p.scanner.init(sql)
if p.parserImpl.Parse(&p.scanner) != 0 {
return nil, errors.New(p.scanner.lastError)
}
return p.scanner.stmts, nil
}
3. SQL执行计划生成
CockroachDB 会根据不同的语法树生成对应的执行计划。目前执行计划基本是基于规则的方式来生成的。对于OLAP的SQL Statement, CockroachDB会将逻辑计划转化为物理执行计划,即通过分布式任务的方式进行并行执行。
// makePlan implements the Planner interface.
func (p *planner) makePlan(
ctx context.Context,
stmt parser.Statement) (planNode, error) {
plan, err := p.newPlan(ctx, stmt, nil)
if err != nil {
return nil, err
}
if err :=
p.semaCtx.Placeholders.AssertAllAssigned();
err != nil {
return nil, err
}
needed := allColumns(plan)
plan, err = p.optimizePlan(ctx, plan, needed)
if err != nil {
return nil, err
}
if log.V(3) {
log.Infof(ctx, “statement %s compiled to:\n%s”,
stmt, planToString(ctx, plan))
}
return plan, nil
}
4. SQL执行当执行计划生成完毕后,CockroachDB会按照约定的方式开始执行,此时CockroachDB将调用事务性的KV接口。执行完成后通过协议层将执行结果返回给客户端。
分布式KV层
SQL到分布式KV映射
在CockroachDB中,所有的Table必须包含一个主键(若建表时无显式声明主键,则系统默认创建)。每列数据构成一个Key-Value存储单元。Key就是每个存储单元值的地址,如/
我们再往表格中插入两条数据:

此时,KV层存储的数据结构是: 对于Key-Value存储单元,分布式KV存储层对外提供了操作原语接口,SQL层通过调用KV操作原语接口实现对KV对象的增删改查操作。
对于Key-Value存储单元,分布式KV存储层对外提供了操作原语接口,SQL层通过调用KV操作原语接口实现对KV对象的增删改查操作。
分布式事务
对于CockroachDB集群,接收请求的节点会充当事务协调节点(Coordinator), 不同于传统的2PC,CockroachDB通过事务表来保证事务的原子性。CockroachDB在事务开始时,会在事务表中新增一条事务记录,初始状态为Pending,然后协调节点会将请求发送给参与节点进行处理,当所有的参与节点执行完毕后,协调节点会将该事务的状态置为Committed;若事务回滚,则把事务状态标记为Abort。这样做的优点是既消除了两阶段锁,同时大大降低了事务提交和回滚的开销。
多副本强一致
多副本数据:Range默认3副本存储,副本数可设置成2N+1;若少于一半的副本丢失,CockroachDB集群会自动在其他可用节点上补齐丢失的副本数据。
故障容灾:根据不同的容灾等级,Range数据多副本可配置为跨机器、跨数据中心、跨地域存储。Range数据分布越分散,相应的读写延时也会越大,集群整体性能会有所下降。
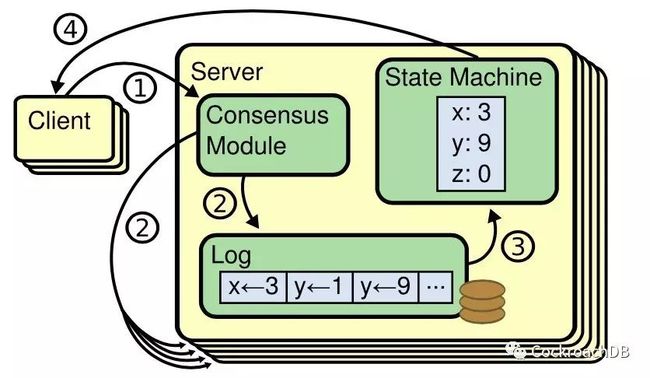
Raft协议:对于CockroachDB而言,单个Range的多个副本通过Raft协议进行数据同步。Raft协议将所有的请求以Raft Log的形式串行化并由Leader同步给Follower,当绝大多数副本写Raft Log成功后,该Raft Log会标记为Committed状态,并Apply到状态机(即写RocksDB)。对于读请求,由于直接使用Raft协议开销比较大,为此CockroachDB引入了Leaseholder的概念。Leaseholder在有效期内可以保证该Range的Raft Group的Leader不会发生切换,从而保证从Leaseholder上即可读到最新的数据,一般情况下Leaseholder也同样是Raft Leader。