基于跳表实现的轻量级KV存储引擎 项目总结
参考:https://github.com/youngyangyang04/Skiplist-CPP
项目介绍
KV存储引擎
众所周知,非关系型数据库redis,以及levedb,rockdb其核心存储引擎的数据结构就是跳表。
本项目就是基于跳表实现的轻量级键值型存储引擎,使用C++实现。插入数据、删除数据、查询数据、数据展示、数据落盘、文件加载数据,以及数据库大小显示。
在随机写读情况下,该项目每秒可处理啊请求数(QPS): 24.39w,每秒可处理读请求数(QPS): 18.41w
项目存储文件
- main.cpp 包含skiplist.h使用跳表进行数据操作
- skiplist.h 跳表核心实现
- README.md 中文介绍
- README-en.md 英文介绍
- bin 生成可执行文件目录
- makefile 编译脚本
- store 数据落盘的文件存放在这个文件夹
- stress_test_start.sh 压力测试脚本
- LICENSE 使用协议
提供接口
- insertElement(插入数据)
- deleteElement(删除数据)
- searchElement(查询数据)
- displayList(展示已存数据)
- dumpFile(数据落盘)
- loadFile(加载数据)
- size(返回数据规模)
存储引擎数据表现
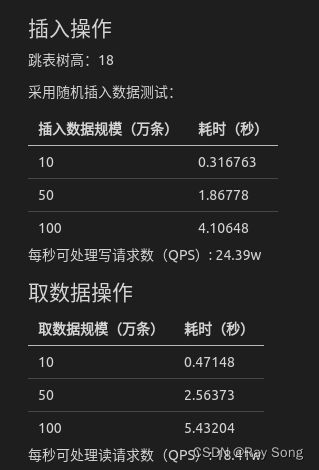
- 插入操作
跳表树高:18
采用随机插入数据测试:
| 插入数据规模(万条) | 耗时(秒) |
|---|---|
| 10 | 0.316763 |
| 50 | 1.86778 |
| 100 | 4.10648 |
每秒可处理写请求数(QPS): 24.39w
- 取数据操作
| 取数据规模(万条) | 耗时(秒) |
|---|---|
| 10 | 0.47148 |
| 50 | 2.56373 |
| 100 | 5.43204 |
每秒可处理读请求数(QPS): 18.41w
- 项目运行方式
make // complie demo main.cpp
./bin/main // run
如果想自己写程序使用这个kv存储引擎,只需要在你的CPP文件中include skiplist.h 就可以了。
可以运行如下脚本测试kv存储引擎的性能(当然你可以根据自己的需求进行修改)
sh stress_test_start.sh
待优化
- delete的时候没有释放内存
- 压力测试并不是全自动的
- 跳表的key用int型,如果使用其他类型需要自定义比较函数,当然把这块抽象出来更好
- 如果再加上一致性协议,例如raft就构成了分布式存储,再启动一个http server就可以对外提供分布式存储服务了
部分代码解析
项目涉及知识
- 函数模板、类模板
- 跳表结构的增、删、查 以及 mutex的使用
- 压力测试、线程(pthread 和 chrono)
代码阅读
从main函数开始阅读,然后跳到头文件,最后压力测试
SkipList
头文件全局变量

node节点类
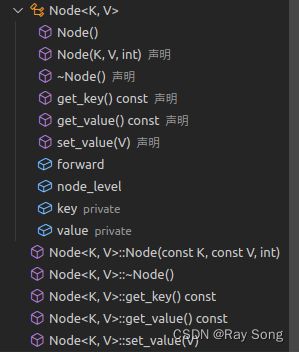
跳表类

该项目的跳表对Redis的跳表结构进行了一定的简化
Redis跳表
跳表数据结构:
 代码实现:
代码实现:
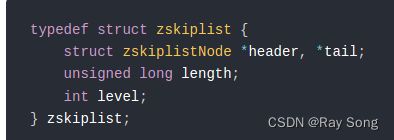
 本项目的跳表
本项目的跳表
- 节点

- 跳表

插入节点
template<typename K, typename V>
int SkipList<K, V>::insert_element(const K key, const V value) {
mtx.lock();
Node<K, V> *current = this->_header;
// update 是个节点数组,用于后续插入位置的前向链接 和 后向链接
Node<K, V> *update[_max_level+1];
memset(update, 0, sizeof(Node<K, V>*)*(_max_level+1));
// 寻找插入位置,并保存插入位置前面的节点
// for进行高度遍历,while 行方向遍历
for(int i = _skip_list_level; i >= 0; i--) {
while(current->forward[i] != NULL && current->forward[i]->get_key() < key) {
current = current->forward[i];
}
update[i] = current;
}
// 定位到 == key 或者 > key 的 节点
current = current->forward[0];
// 如果current节点存在且和key相等,提示,并解锁
if (current != NULL && current->get_key() == key) {
std::cout << "key: " << key << ", exists" << std::endl;
mtx.unlock();
return 1;
}
//否则,需要在update[0]和current node节点之间插入 [节点]
if (current == NULL || current->get_key() != key ) {
// 随机生成节点的高度
int random_level = get_random_level();
// 如果随机高度比当前的跳表的高度大,update数组在多余高出来的部分保存头节点指针
if (random_level > _skip_list_level) {
for (int i = _skip_list_level+1; i < random_level+1; i++) {
update[i] = _header;
}
_skip_list_level = random_level;
}
// 用随机生成的高度 创建 insert node
Node<K, V>* inserted_node = create_node(key, value, random_level);
// node节点 forword 指向 所在位置后面的节点指针
// node节点 所在位置前面的节点 指向node
for (int i = 0; i <= random_level; i++) {
inserted_node->forward[i] = update[i]->forward[i];
update[i]->forward[i] = inserted_node;
}
std::cout << "Successfully inserted key:" << key << ", value:" << value << std::endl;
_element_count ++;
}
mtx.unlock();
return 0;
}
删除节点
template<typename K, typename V>
void SkipList<K, V>::delete_element(K key) {
mtx.lock();
Node<K, V> *current = this->_header;
// update数组 用于保存 删除节点前面的节点 ,用于删除节点后的指向链接,步骤和插入节点类似
Node<K, V> *update[_max_level+1];
memset(update, 0, sizeof(Node<K, V>*)*(_max_level+1));
// 寻找要删除的节点,并将该节点前面的节点保存到update数组中
for (int i = _skip_list_level; i >= 0; i--) {
while (current->forward[i] !=NULL && current->forward[i]->get_key() < key) {
current = current->forward[i];
}
update[i] = current;
}
// ==key 或者 > key 的元素节点
current = current->forward[0];
// 如果相等进行下面的操作,不相等直接解锁 return
if (current != NULL && current->get_key() == key) {
// 从低级别开始删除每层的节点,
for (int i = 0; i <= _skip_list_level; i++) {
// 如果在第i曾,其下一个节点不是所要删除的节点直接break
if (update[i]->forward[i] != current)
break;
// 如果是要删除的节点 重新设置指针的指向,将其指向下一个节点的位置
update[i]->forward[i] = current->forward[i];
}
// 减少没有元素的层,更新跳表的level
while (_skip_list_level > 0 && _header->forward[_skip_list_level] == 0) {
_skip_list_level --;
}
std::cout << "Successfully deleted key "<< key << std::endl;
_element_count --;
}
mtx.unlock();
return;
}
搜索节点
// Search for element in skip list
/*
+------------+
| select 60 |
+------------+
level 4 +-->1+ 100
|
|
level 3 1+-------->10+------------------>50+ 70 100
|
|
level 2 1 10 30 50| 70 100
|
|
level 1 1 4 10 30 50| 70 100
|
|
level 0 1 4 9 10 30 40 50+-->60 70 100
*/
template<typename K, typename V>
bool SkipList<K, V>::search_element(K key) {
std::cout << "search_element-----------------" << std::endl;
Node<K, V> *current = _header;
// for循环高度遍历,while循环水平遍历每一层。
for (int i = _skip_list_level; i >= 0; i--) {
while (current->forward[i] && current->forward[i]->get_key() < key) {
current = current->forward[i];
}
}
// 找到 > 或者 = key的 节点
current = current->forward[0];
// 如果存在且相等,成功找到
if (current and current->get_key() == key) {
std::cout << "Found key: " << key << ", value: " << current->get_value() << std::endl;
return true;
}
// 否则 没有找到 进行提示
std::cout << "Not Found Key:" << key << std::endl;
return false;
}
进一步优化
- 原始代码使用key进行排序,不具备通用型,增加score变量,通过score权重进行排序;
- 增加反向back指针
- 删除节点的时候没有释放内存,增加智能指针
github网址:
性能测试
-
参数设置
#define NUM_THREADS 1
#define TEST_COUNT 100000
SkipList -
测试的代码
pthread_t threads[NUM_THREADS];
pthread_create(&threads[i], NULL, insertElement, (void *)i);
void *insertElement(void* threadid) {
long tid;
tid = (long)threadid;
std::cout << tid << std::endl;
int tmp = TEST_COUNT/NUM_THREADS;
for (int i=tid*tmp, count=0; count<tmp; i++) {
count++;
skipList.insert_element(rand() % TEST_COUNT, "a");
}
pthread_exit(NULL);
}
- 计时
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed = finish - start;
std::cout << “insert elapsed:” << elapsed.count() << std::endl;
虚拟机测试:

项目官方测试:
知识补充:
4. c语言中__attribute__的意义 取消内存对齐
5. C++多线程之使用Mutex和Critical_Section
mutex和临界区的区别
异步日志系统
- 最新版Web服务器项目详解 - 09 日志系统(上)
- 最新版Web服务器项目详解 - 10 日志系统(下)
异步日志系统主要涉及了两个模块,一个是日志模块,一个是阻塞队列模块,其中加入阻塞队列模块主要是解决异步写入日志做准备.
- 自定义阻塞队列
- 单例模式创建日志
- 异步日志
0. 生产者消费者模型
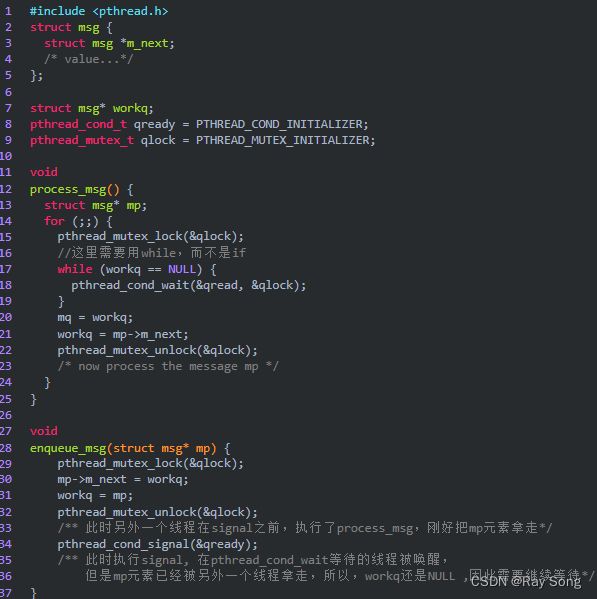
1. 阻塞队列
/*************************************************************
*循环数组实现的阻塞队列,m_back = (m_back + 1) % m_max_size;
*线程安全,每个操作前都要先加互斥锁,操作完后,再解锁
**************************************************************/
private:
locker m_mutex; // 循环数组加锁
cond m_cond; // 条件变量通知
T *m_array; // 循环数组
int m_size; // 已经有的size
int m_max_size; // 最大的size
int m_front; // 头部元素
int m_back; // 尾部元素
- 构造函数
block_queue(int max_size = 1000)
{
if (max_size <= 0)
{
exit(-1);
}
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
}
- 析构函数
~block_queue()
{
m_mutex.lock();
if (m_array != NULL)
delete [] m_array;
m_mutex.unlock();
}
- 队列中添加元素push():
- 0. 先加锁
- 1. 判断阻塞队列是否满了,满了的话就条件变量广播让pop来取,解锁,同时返回false
- 2. 如果阻塞队列没有满的话,就队列尾部添加string, size++,条件变量广播让pop来取,解锁
bool push(const T &item)
{
m_mutex.lock();
if (m_size >= m_max_size)
{
m_cond.broadcast();
m_mutex.unlock();
return false;
}
m_back = (m_back + 1) % m_max_size;
m_array[m_back] = item;
m_size++;
m_cond.broadcast();
m_mutex.unlock();
return true;
}
- pop消费操作
- 1. 先对阻塞队列加锁
- 2. 如果阻塞队列为空,条件变量阻塞在
-
//pop时,如果当前队列没有元素,将会等待条件变量
bool pop(T &item)
{
m_mutex.lock();
//多个消费者的时候,这里要是用while而不是if
while (m_size <= 0)
{
//当重新抢到互斥锁
if (!m_cond.wait(m_mutex.get()))
{
m_mutex.unlock();
return false;
}
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
m_mutex.unlock();
return true;
}
- 清空
void clear()
{
m_mutex.lock();
m_size = 0;
m_front = -1;
m_back = -1;
m_mutex.unlock();
}
- 判断队列满还是空 返回队首元素 队尾元素
bool full()
bool empty()
bool front(T &value)
bool back(T &value)
- 在size() 和max_size()操作的时候需要对size和max_size变量加锁
2. Log类头文件
单例模式
- 成员变量
private:
char dir_name[128]; //路径名
char log_name[128]; //log文件名
int m_log_buf_size; //日志缓冲区大小
FILE *m_fp; //打开log的文件指针
char *m_buf;
block_queue *m_log_queue; //阻塞队列
locker m_mutex;
- 成员函数
private:
Log();
virtual ~Log();
- public成员函数
//C++11以后,使用局部变量懒汉不用加锁
static Log *get_instance()
{
static Log instance;
return &instance;
}
static void *flush_log_thread(void *args)
{
string single_log;
//从阻塞队列中取出一个日志string,写入文件
while (m_log_queue->pop(single_log))
{
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
}
}
//可选择的参数有日志文件、日志缓冲区大小、最长日志条队列
bool init(const char *file_name, int log_buf_size = 8192, int max_queue_size = 1000);
void write_log(int level, const char *format, ...);
void flush(void);
3. Log实现文件
- init函数: 初始化
m_log_queue = new block_queue(max_queue_size);
pthread_t tid;
//flush_log_thread为回调函数,这里表示创建线程异步写日志
pthread_create(&tid, NULL, flush_log_thread, NULL);
m_fp = fopen(log_full_name, "a");
- write_log函数 : 如果阻塞队列满了,就直接将内容追加到日志文件中
if (!m_log_queue->full())
{
m_log_queue->push(log_str);
}
else
{
m_mutex.lock();
fputs(log_str.c_str(), m_fp);
m_mutex.unlock();
}
- flush强制刷新缓冲区
void Log::flush(void)
{
m_mutex.lock();
//强制刷新写入流缓冲区
fflush(m_fp);
m_mutex.unlock();
}