MySQL数据库的高级SQL语句与高级操作
目录
一.克隆表——将数据表的数据记录生成到新的表中
方法一:先创建再导入
方法二:创建的时候同时导入
二.清空表——删除表内的所有数据
方法一:delete删除(自增长)
方法二:truncate删除(重新记录)
方法三:创建临时表(退出数据库自动销毁)
三.导入文件或脚本进数据库
四.SQL高级语句——select:查询语句
1.select:显示表格中的一个或者多个字段中所有的信息
2.distinct:查询不重复记录
3.where:根据条件查询
4.and且、or或:根据多个条件查询
5.in:显示已知值的资料
6.between:显示两个值范围内的资料
7.like+通配符:模糊查询
8.order by:按关键字排序
五.SQL函数
1.数学函数
2.聚合函数
3.字符串函数
3.1 trim:返回去除指定格式的值
3.2 length:返回字符串的长度
3.3 replace:替代
3.4 concat:将提供的参数拼接成一个字符串
3.5 substr:根据要求截取长度查看
六.group by:查询结果进行汇总分组
七.having:过滤返回的记录集
八.as:别名
九.连接查询
1.inner join(等值相连):只返回两个表中联结字段相等的行
2.left join(左联接):返回包括左表中的所有记录和右表中联结字段相等的记录
3.right join(右联接):返回包括右表中的所有记录和左表中联结字段相等的记录
十.子查询
一.克隆表——将数据表的数据记录生成到新的表中
方法一:先创建再导入
create table 新表 like 旧表;
insert into 新表 select * from 旧表;
例如:
create table test1 like students; #通过 LIKE 方法,复制 info 表结构生成 test01 表
insert into test1 select * from students; #导入数据

方法二:创建的时候同时导入
create table test2 (select * from students);

二.清空表——删除表内的所有数据
方法一:delete删除(自增长)
DELETE清空表后,返回的结果内有删除的记录条目;DELETE工作时是一行一行的删除记录数据的;如果表中有自增长字段,使用DELETE FROM 删除所有记录后,再次新添加的记录会从原来最大的记录 ID 后面继续自增写入记录。
delete from 表名;
例如:
delete from students;

方法二:truncate删除(重新记录)
TRUNCATE 清空表后,没有返回被删除的条目;TRUNCATE 工作时是将表结构按原样重新建立,因此在速度上 TRUNCATE 会比 DELETE 清空表快;使用 TRUNCATE TABLE 清空表内数据后,ID 会从 1 开始重新记录。
truncate table 表名;
例如:
truncate table test1;

方法三:创建临时表(退出数据库自动销毁)
临时表创建成功之后,使用SHOW TABLES命令是看不到创建的临时表的,临时表会在连接退出后被销毁。 如果在退出连接之前,也可以可执行增删改查等操作,比如使用 DROP TABLE 语句手动直接删除临时表。
##添加临时表test3
create temporary table test3 (
id int(4) zerofill primary key auto_increment,
name varchar(10) not null,
cardid int(18) not null unique key,
hobby varchar(50));
show tables; ## 查看当前库中所有表
insert into test3 values(1,'zhangsan',123456789,'watch a film'); ##在临时表中添加数据
select * from test3; ##查看当前表中所有数据
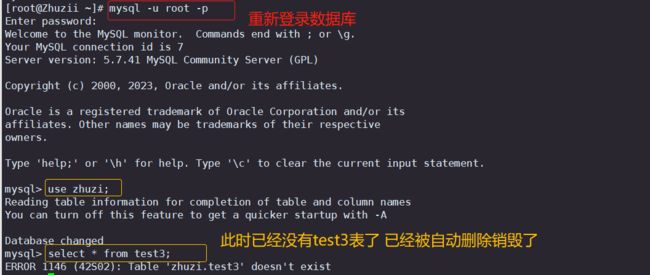
quit ##退出数据库
mysql -u root -p ##重新登录后进行查看
select * from test3; ##查看之前创建的临时表中所有数据,发现已经被自动销毁

三.导入文件或脚本进数据库
1. #将脚本上传至数据库外文件夹内
cd /opt
rz -E
2. #登入数据库并进入一个数据库
mysql -u root -p
use 数据库名
3. #将脚本导入 source 加文件路径
source /opt/脚本名;

四.SQL高级语句——select:查询语句
导入一个脚本,内含数据库hellodb,为接下来的示例作准备 :

1.select:显示表格中的一个或者多个字段中所有的信息
#格式:select 字段名 from 表名;
#示例1:显示数据表students的所有数据
select * from students;
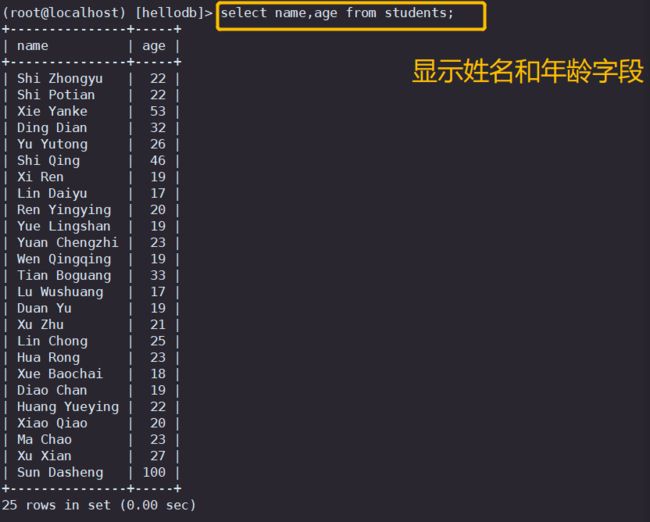
#示例2:显示数据表students的名字与年龄字段
select name,age from students;
2.distinct:查询不重复记录
#语法:select distinct 字段 from 表名﹔
#示例1:去除年龄字段中重复的
select distinct age from students;
#示例2:查找性别
select distinct gender from students;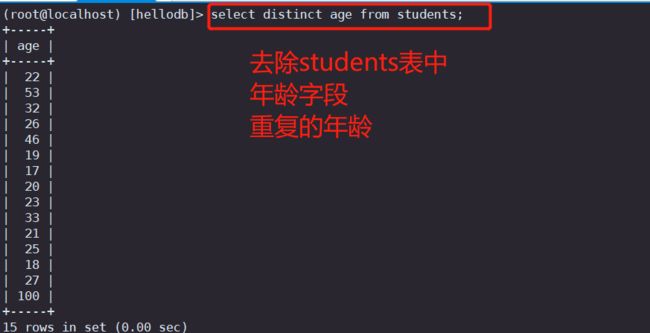

3.where:根据条件查询
#语法:select '字段' from 表名 where 条件
#示例:显示name和age 字段 并且要找到age小于20
select name,age from students where age < 20;

4.and且、or或:根据多个条件查询
#语法:select 字段名 from 表名 where 条件1 (and|or) 条件2 (and|or)条件3;
#示例:显示name和age 并且要找到age大于20小于30
select name,age from students where age >20 and age <30;
5.in:显示已知值的资料
#语法:select 字段名 from 表名 where 字段 in ('值1','值2'....);
#示例1:显示学号为1,2,3,4的学生记录
select * from students where StuID in (1,2,3,4);
#示例2:显示班级为1和3的学生记录
select * from students where ClassID in (1,3);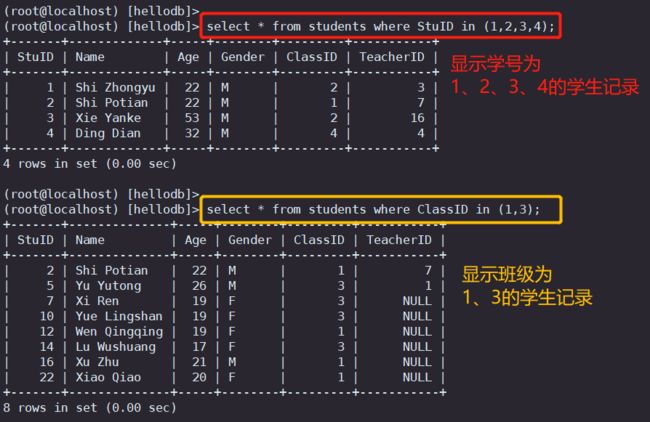
6.between:显示两个值范围内的资料
#语法:select 字段名 from 表名 where 字段 between '值1' and '值2';
包括 and两边的值
#示例1:显示学生姓名在Ding Dian和Hua Rong中的学生记录
select * from students where name between 'ding dian' and 'Hua Rong';
#示例2:显示学生号码id在2-5 的信息
select * from students where stuid between 2 and 5;
#示例3:显示学生年龄在20-35之间的信息,不需要表中一定有该字段,只会将20到25 已有的都显示出来
select * from students where age between 20 and 25;


7.like+通配符:模糊查询
#语法:select 字段名 from 表名 where 字段 like 模式| 通配符 | 含义 |
|---|---|
| % | 表示零个,一个或者多个字符 |
| _ | 下划线表示单个字符 |
| A_Z | 所有以A开头 Z 结尾的字符串 'ABZ' 'ACZ' 'ACCCCZ'不在范围内 下划线只表示一个字符 AZ 包含a空格z |
| ABC% | 所有以ABC开头的字符串 ABCD ABCABC |
| %CBA | 所有以CBA结尾的字符串 WCBA CBACBA |
| %AN% | 所有包含AN的字符串 los angeles |
| _AN% | 所有 第二个字母为 A 第三个字母 为N 的字符串 |
#示例1:查找名字以s开头的学生记录
select * from students where name like 's%';
#示例2:查找名字包含ong的学生记录
select * from students where name like '%ong%';
#示例3:查找名字第二个字母为u,第三个字母为a的学生记录
select * from students where name like '_ua%';
8.order by:按关键字排序
#语法:
select 字段名 from 表名 where 条件 order by 字段 [asc,desc];
#############################################################
asc :正向排序
desc :反向排序
######################默认是正向排序###########################示例1:按学生的年龄正向排序显示年龄和姓名字段
select age,name from students order by age;
#示例2:按学生的年龄反向排序显示年龄和姓名字段
select age,name from students order by age desc;
#示例3:显示name、age和classid字段的数据 并且只显示classid字段为3 的 并且以age字段排序
select age,name,classid from students where classid=3 order by age;


五.SQL函数
1.数学函数
| 函数 | 含义 |
|---|---|
| abs(x) | 返回x 的 绝对值 |
| rand() | 返回0到1的随机数 |
| mod(x,y) | 返回x除以y以后的余数 |
| power(x,y) | 返回x的y次方 |
| round(x) | 返回离x最近的整数 |
| round(x,y) | 保留x的y位小数四舍五入后的值 |
| sqrt(x) | 返回x的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2.....) | 返回返回集合中最大的值 |
| least(x1,x2..........) | 返回返回集合中最小的值 |
#示例1:返回-2的绝对值
select abs(-2);
#示例2:随机生成一个数
select rand (1);
#示例3:随机生成排序
select * from students order by rand();
#示例4:返回7除以2以后的余数
select mod(7,2);
#示例5:返回2的3次方
select power(2,3);
#示例6:返回离2.6最近的数
select round(2.6);
#返回离2.4最近的数
select round(2.4);
#示例7:保留2.335321的3位小数四舍五入后的值
select round(2.335321,2);
#示例8:返回数字 2.335321 截断为2位小数的值
select truncate(2.335321,2);
#示例9:返回大于或等于2.335321 的最小整数
select ceil(2.335321);
#示例10:返回小于或等于 2.335321 的最大整数
select floor(2.335321);
#示例11:返回集合中最大的值
select greatest(1,4,3,9,20);
#示例12:返回集合中最小的值
select least(1,4,3,9,20);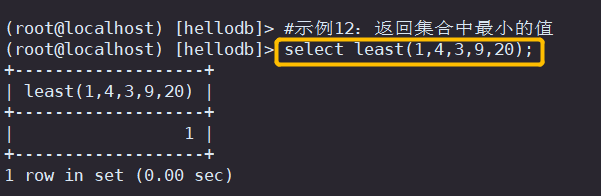
2.聚合函数
| 函数 | 含义 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
#示例1:求表中年龄的平均值
select avg(age) from students;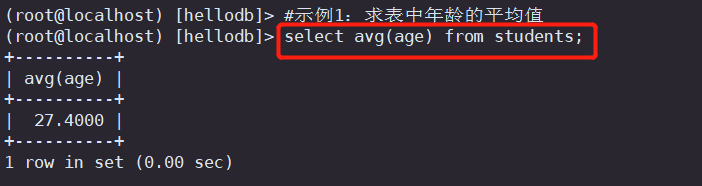
#示例2:求表中年龄的总和
select sum(age) from students;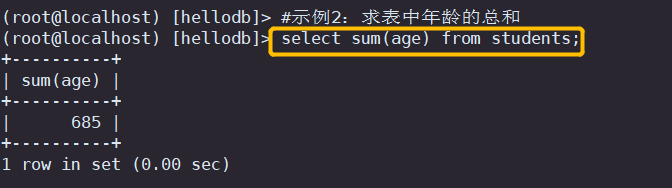
#示例3:求表中年龄的最大值
select max(age) from students;
#示例4:求表中年龄的最小值
select min(age) from students;
#示例5:求表中有多少班级字段非空记录
select count(classid) from students;
count(明确字段):不会忽略空记录
#示例6:求表中有多少条记录
select count(*) from students;
count(*)包含空字段,会忽略空记录
#示例7:看空格字段是否会被匹配
insert into students values(26,' ',28,'f',1,8);
3.字符串函数
| 函数 | 描述 |
|---|---|
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
3.1 trim:返回去除指定格式的值
语法:select trim (位置 要移除的字符串 from 字符串)
其中位置的值可以是
leading(开始)
trailing(结尾)
both(起头及结尾)
#区分大小写
要移除的字符串:从字符串的起头、结尾或起头及结尾移除的字符串,缺省时为空格。#示例:从名字开头的开始,移除Sun Dasheng中的Sun显示
select trim(leading 'Sun' from 'Sun Dasheng');
3.2 length:返回字符串的长度
#语法:select length(字段) from 表名;
#示例:计算出字段中记录的字符长度
select name,length(name) from students;
3.3 replace:替代
#语法:select replace(字段,'原字符''替换字符') from 表名;
#示例:查看名字里包含ua的记录
select name from students where name like '%ua%';
#将ua替换成hh显示出来
select replace(name,'ua','hh') from students;
3.4 concat:将提供的参数拼接成一个字符串
#语法:select concat(字段1,字段2)from 表名
#示例:将name,classid字段拼接成一个字符串
select concat(name,classid) from students;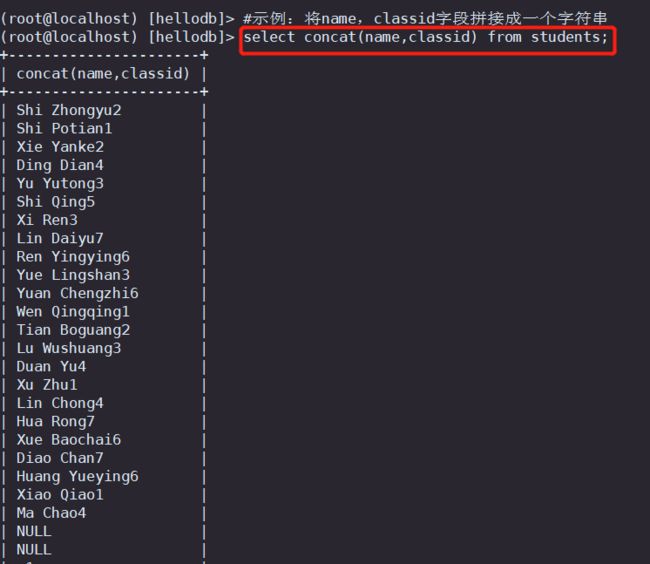
3.5 substr:根据要求截取长度查看
#语法:select substr(字段,开始截取字符,截取的长度) where 字段='截取的字符串'
#示例1:截取第6个字符往后
select substr(name,6) from students where name='Yue Lingshan';
#示例2:截取第6个字符往后的两个字符
select substr(name,6,2) from students where name='Yue Lingshan';
六.group by:查询结果进行汇总分组
-
对group by 后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
-
group by 有一个原则,就是select 后面的所有列中,没有使用聚合函数的列必须出现在 group by 的后面
#语法:select 字段1,sum(字段2) from 表名 group by 字段1;
#示例1:求各个班的年龄总和
select classid,sum(age) from students group by classid;
#示例2:求各个班的平均年龄
select classid,avg(age) from students group by classid;
#示例3:根据年龄查看每个班的人数
select classid,count(age) from students group by classid;

七.having:过滤返回的记录集
-
having:用来过滤由group by语句返回的记录集,通常与group by语句联合使用
-
having语句的存在弥补了where关键字不能与聚合函数联合使用的不足。如果被SELECT的只有函数栏,那就不需要GROUP BY子句。
-
要根据新表中的字段,来指定条件
#语法:
select 字段1,SUM("字段")from 表格名 group by 字段1 having(函数条件);
#示例:查看各个班的平均年龄在30以上的班级
select classid,avg(age) from students group by classid having avg(age) > 30;
八.as:别名
栏位別名 表格別名
#语法:
SELECT "表格別名"."栏位1" [AS] "栏位別名" FROM "表格名" [AS] "表格別名";
#示例:设置表名别名为f,基于班级号来统计各班年龄总和,sum(age)定义别名为total age
select f.classid,sum(age) 'total age' from students as f group by f.classid;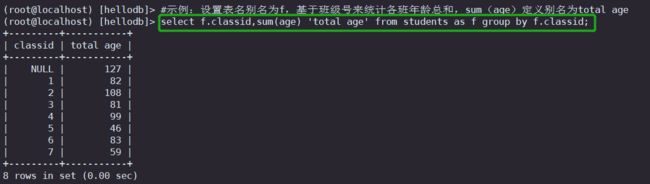
九.连接查询
准备两个表,此处两个表分别为students和scores


1.inner join(等值相连):只返回两个表中联结字段相等的行
SELECT * FROM students A INNER JOIN scores B on A.stuid = B.stuid;
2.left join(左联接):返回包括左表中的所有记录和右表中联结字段相等的记录
select * from scores A left join students B on A.stuid = B.stuid;
3.right join(右联接):返回包括右表中的所有记录和左表中联结字段相等的记录
select * from scores A right join students B on A.stuid = B.stuid;
十.子查询
连接表格,在WHERE 子句或HAVING 子句中插入另一个SQL语句
语法:SELECT "栏位1" FROM "表格1" WHERE "栏位2" [比较运算符]
#外查询
(SELECT "栏位1" FROM "表格1" WHERE "条件");
#示例:查询学生学号为1的得分总和
select sum(score) from scores where stuid in (select stuid from students where stuid=1);