使用dinky自动savepoint、checkpoint恢复flink sql作业
一. 场景
使用dinky自动savepoint、checkpoint恢复
| 组件 | 版本 |
|---|---|
| flink | 1.14.4 |
| Flink-mysql-cdc | 2.2.1 |
| Mysql | 5.7+ |
| Dinky | 0.6.6 |
温馨提示: dinky暂时不支持flink1.15.X 版本做savepoint处理, 请等待后续更新支持, 或者使用小于flink1.15的版本
二. 运行模式
flink on yarn — perjob
三. 部署
将 flink-sql-connector-mysql-cdc-2.2.1.jar 添加到 dinky家目录plugins和hdfs集群配置路径上
依赖图:


3.1. mysql 数据源准备
create database emp_1;
use emp_1;
CREATE TABLE IF NOT EXISTS `employees_1` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into employees_1 VALUES ("10", "1992-09-12", "cai", "kunkun", "M", "2022-09-22");
insert into employees_1 VALUES ("11", "1990-09-15", "wang", "meimei", "F", "2021-04-12");
3.2. Flink sql 准备
-- 测试参数, 生成环境不需设置
SET pipeline.operator-chaining = false;
SET table.local-time-zone = Asia/Shanghai;
SET execution.runtime-mode = streaming;
SET execution.checkpointing.interval = 6000;
SET execution.checkpointing.tolerable-failed-checkpoints = 10;
SET execution.checkpointing.timeout =600000;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
SET execution.checkpointing.mode = EXACTLY_ONCE;
SET execution.checkpointing.unaligned = true;
SET execution.checkpointing.max-concurrent-checkpoints = 1;
SET state.checkpoints.num-retained = 3;
SET restart-strategy = fixed-delay;
SET restart-strategy.fixed-delay.attempts = 10 ;
SET restart-strategy.fixed-delay.delay = 20s;
SET table.exec.source.cdc-events-duplicate = true;
SET table.sql-dialect = default;
--SET pipeline.name = hive_catalog_cdc_orders;
SET jobmanager.memory.process.size = 1600m;
SET taskmanager.memory.process.size = 1780m;
SET taskmanager.memory.managed.size = 200m;
SET taskmanager.numberOfTaskSlots=1;
SET yarn.application.queue= default;
EXECUTE CDCSOURCE dinkySource_mysqlCDC_to_Doris WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop102',
'port' = '3306',
'username' = 'root',
'password' = 'xxxxxx',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'emp_1\.employees_[0-9]+',
'sink.connector' = 'print',
)
补充说明:
flink需要开启checkpoint, 配置好状态后端参数
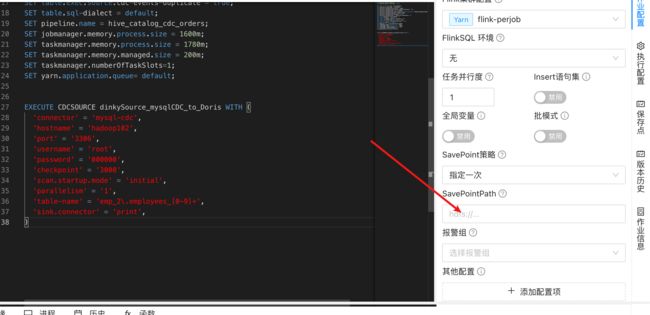
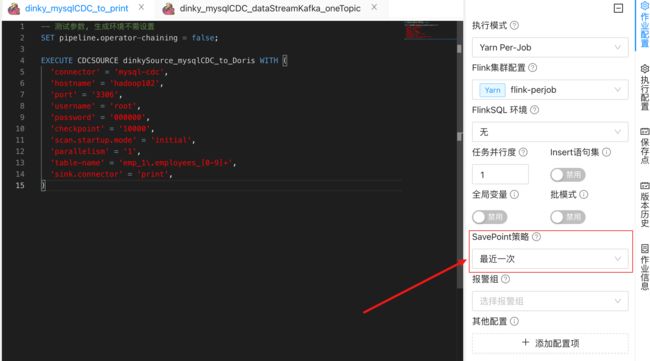
3.3. dinky 面板
savepoint 策略选择 最近一次
3.4. 任务提交
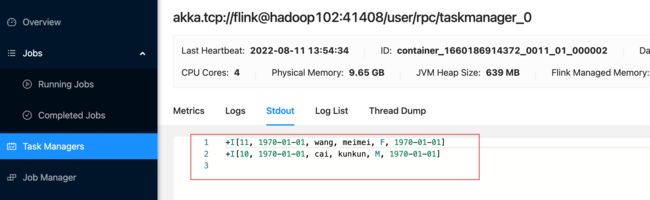
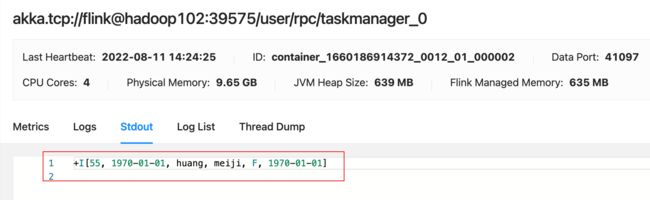
因为作业是第一次运行, 之前没有做过savepoint, 所以作业是一个新的程序,消费两条数据

flink web ui

taskmanger 成功输出两条数据
四. 使用savepoint自动恢复功能
查看作业详情栏, 如下图右上角所示, 他们的含义分别为:
| 名称 | 含义 |
|---|---|
| 智能停止 | 触发一次Savepoint, 并停止作业 |
| Savepoint 触发 | 触发一次Savepoint. 作业继续运行 |
| Savepoint 暂停 | 触发一次Savepoint. 并暂停运行 |
| Savepoint 停止 | 触发一次Savepoint, 并停止作业 |
4.1. 所以这里我们点击 ‘智能停止’ 或者 ‘Savepoint停止’, 触发一次Savepoint, 并停止作业.

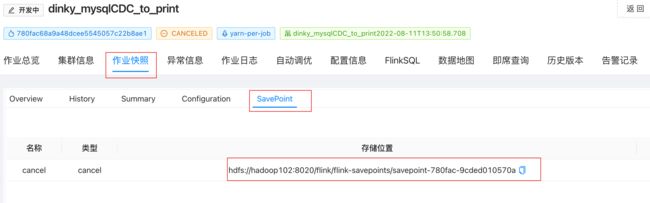
4.2. 等作业停止后, 在作业快照 --> Savepoint 栏中, 查看到刚刚成功保存的Savepoint记录
4.3. 在dlink数据库中, 也可以查看到保存的Savepoint元数据

4.4. 同时, 在’数据开发’ 面板对应的作业中, 右边栏也可以查看到savepoint记录

4.5. 接下来, 往表中插入一条新的数据
insert into employees_1 VALUES ("55", "2020-09-15", "huang", "meiji", "F", "2022-04-12");
4.6. 重启作业
作业会自动从之前保存的savepoint处 启动

4.7. 观察到作业, 成功做到断点续传, 只消费到一条记录

flink web ui
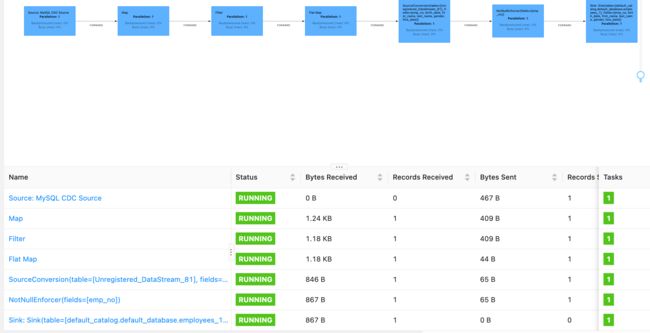
Taskmanager 成功输出一条记录
五. 使用checkpoint自动恢复功能
dinky的checkpoint恢复功能使用非常方便, 只需要点击一个按钮即可恢复, 整体过程如下所示:
5.1. 准备数据源 sql
create database emp_2;
use emp_2;
CREATE TABLE IF NOT EXISTS `employees_2` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- flink sql
-- 测试参数, 生成环境不需设置
SET pipeline.operator-chaining = false;
SET table.local-time-zone = Asia/Shanghai;
SET execution.runtime-mode = streaming;
SET execution.checkpointing.interval = 6000;
SET execution.checkpointing.tolerable-failed-checkpoints = 10;
SET execution.checkpointing.timeout =600000;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
SET execution.checkpointing.mode = EXACTLY_ONCE;
SET execution.checkpointing.unaligned = true;
SET execution.checkpointing.max-concurrent-checkpoints = 1;
SET state.checkpoints.num-retained = 3;
SET restart-strategy = fixed-delay;
SET restart-strategy.fixed-delay.attempts = 10 ;
SET restart-strategy.fixed-delay.delay = 20s;
SET table.exec.source.cdc-events-duplicate = true;
SET table.sql-dialect = default;
--SET pipeline.name = hive_catalog_cdc_orders;
SET jobmanager.memory.process.size = 1600m;
SET taskmanager.memory.process.size = 1780m;
SET taskmanager.memory.managed.size = 200m;
SET taskmanager.numberOfTaskSlots=1;
SET yarn.application.queue= default;
EXECUTE CDCSOURCE dinkySource_mysqlCDC_to_Doris WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop102',
'port' = '3306',
'username' = 'root',
'password' = 'xxxxxx',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'emp_2\.employees_[0-9]+',
'sink.connector' = 'print',
)
5.2. 提交作业
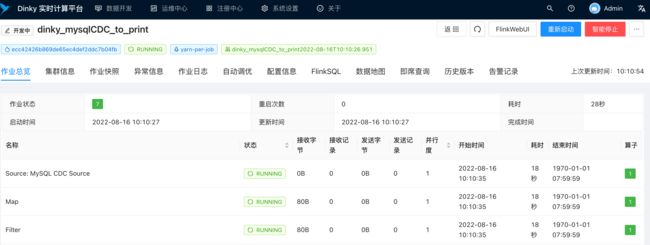
5.3. 往 employees_2 表插入两条数据
insert into employees_2 VALUES ("10", "1992-09-12", "cai", "kunkun", "M", "2022-09-22");
insert into employees_2 VALUES ("11", "1990-09-15", "wang", "meimei", "F", "2021-04-12");
5.4. 成功消费两条数据

5.5. 这次我们点击 ‘普通停止’, 不做savepoint, 从checkpoint 处启动
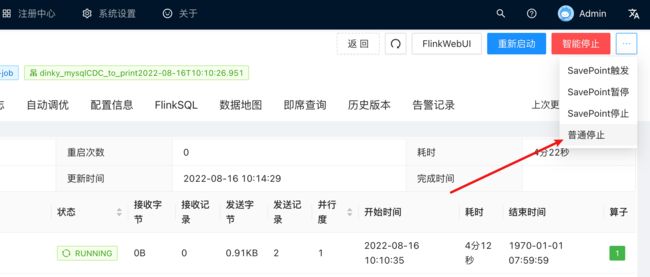
5.6. 停止之后, 我们可以从 '作业快照’中, 查看到作业保存的checkpoint记录

这跟hdfs 上保存的checkpoint记录 是一致的
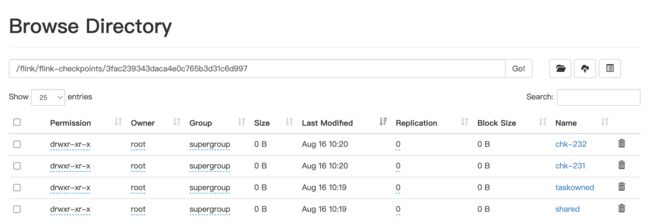
然后点击 ‘此处恢复’ 按钮, 恢复最新的checkpoint

5.7. 等作业重新启动后, 往 employees_2 表插入一条数据
insert into employees_2 VALUES ("13", "1992-09-12", "cai", "kunkun", "M", "2022-09-22");
5.8. 成功断点续传, 消费到一条数据

温馨提示
运行perjob、 app 模式的作业, 如果作业被强行kill掉、内部错误等原因导致作业意外退出, 会导致ck信息不能及时同步, 可能导致dinky保存的checkpoint记录, 跟hdfs上保存的记录不一致, 有可能晚几个版本, 所以线上作业恢复ck时, 需要查看hdfs上保存的ck记录, 跟dinky作比较
六. 手动指定某处checkpoint 恢复
6.1. 在上一个步骤中, 点击 ‘此处恢复’ 之后, 作业能 ‘断点续传’, 实际原理是, dinky将checkpoint的记录填充到了作业的右边栏, 选项为 ‘指定一次’ 然后运行的.

6.2 所以, dinky也是支持手动指定某处checkpoint 恢复, 只需
‘SavePoin策略’ 选择 ‘指定一次’, 将ck路径粘贴到 ‘SavePointPath’, 运行即可恢复checkpoint