cockroach官方文档翻译---2.5复制层
2.5 复制层
CockroachDB的复制层在节点间复制副本集,实现我们自己的一致性算法保证副本的一致性。
**概要
--与其他层进行交互
**组件
--raft
--快照(snapshots)
--租约(leases)
--成员改变(membership changes):重定向和修复
**与其他层交互
--复制层与分布层
--复制层与存储层
2.5.1 概要
高可用要求数据库容忍部分节点离线,不中断应用服务。这意味着节点的复制数据需要确保是可达的。
在部分节点离线的情况下,确保一致性,是一个很多数据库没完成的挑战。为了解决这个问题,cockroachDB使用一致性算法,要求更改提交之前,副本的规定数目节点同意这个更改。3是最小的数量可以达到规定数目(3个中的2个),cockroachDB高可用(多数节点活跃高可用)需要3个节点。
可以容忍失败数=(副本集因子-1)/2,例如,有3x个副本,1个副本失败可以被容忍;如果有5x个副本,2个失败可以容忍;你可以控制集群/数据库/表中的副本集因子使用副本集区域
https://www.cockroachlabs.com/docs/stable/configure-replication-zones.html
当失败发生时,cockroachDB自动检测到节点停止响应和工作,重新分配你的数据保证最大的耐受性。进程触发:新的节点加入集群,数据自动重分配,保证负载均匀的分布。
**与其他层的交互
复制层:
--接收来自分布式层的请求,并向分布式层发送请求
--向存储层发送写请求
2.5.2 组件
** raft
Raft是一个一致性协议,是一个算法保证数据在多机器上安全存储。即使部分节点当前无法连接,这些机器可以同意当前状态。
Raft管理包含一个组中的一个range的一个副本的所有节点,叫做raft组。raft组的每个副本不是领导者(leader)就是跟随者(follower)。领导者是被raft和长期活跃的节点选举出来的,负责协调raft组的所有写。领导者向跟随者周期性发送心跳,保证他们的日志被复制。如果心跳缺失,跟随者变为随机的选举的候选者,选举新的领导者。
一旦一个节点接收到对它包含一个的range的BatchRequest,将这些KV操作转化为Raft指令。这些指令提给raft组的领导者,raft组的领导者将其理想化为租获得者,raft组的领导者也是其中一个,并写入raft日志。
对于raft的更多细节,请查看。
http://thesecretlivesofdata.com/raft/
>> 如何理解raft一致性
如果有一个单节点,存储单个值,并作为数据库服务器,客户端发送一个值到服务器,单节点很容易保证一致性。
如果有多节点,如何保证一致性,这就是分布式一致性问题。Raft是一个协议实现分布式一致性。
>> 协议概要
高可用是如何工作的,一个节点可以是三种状态中的一种,follower(跟随者)状态,candidate(参与者)状态,leader(领导者)状态,所有的节点都是从follower状态开始,如果followers没听到leader,follower转化为candidate(参与者),这个参与者向其他节点发送投票请求,其他节点将回复他们的投票,参与者变成领导者如果他获取到多数节点的投票。这叫做领导者选举。系统中所有的改变需要通过领导者。每个更改作为一个实体被添加到节点日志中,这个日志实体没有提交,所以并不会更新到节点的值中。为了提交这个实体,节点首先将他复制到跟随节点,然后领导者等待直到大多数的节点实体被写入,实体在leader节点提交。然后leader告知跟随者实体已经提交。集群现在处于系统状态的一致性状态。这个过程叫做日志复制。
>> leader 选举
在raft中有两个超时设置,去控制选举,第一个是选举超时,选举超时是follower等待直到变成一个candidate。选举超时是随机的,在150ms和300ms之间,在选举超时以后,follower变成一个参与者,开始一个新的选举阶段。投票给他自己,向其他节点发送投票请求。如果接受到请求的节点尚未投票,它将投票给candidate,然后节点重置选举超时。一旦一个节点获取到多数节点的投票,它变成leader。Leader向他的跟随者发送Append Entries消息,这些消息被发送的间隔时间为心跳超时。Follower回复每个Append Entries消息。这个选举阶段会一直持续直到Follower停止接受心跳,变为candidate者。
让我们停止leader,看看再次选举是如何发生的,
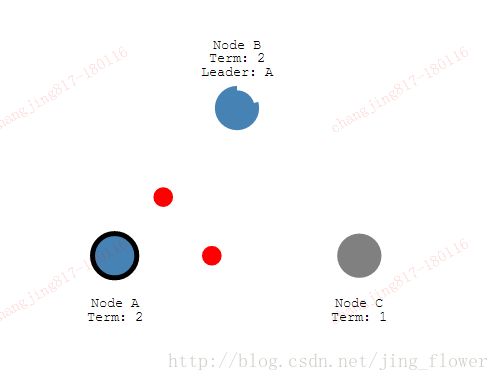
节点A现在是阶段2的leader,需要多数节点的投票,保证在每个阶段只有一个leader,如果两个节点同时变成candidate,将发生一个投票分裂。我们查看一个投票分裂的例子。

两个节点在同一个阶段开始投票,每个在另一个之前或者一个follower,

现在每个candidate有两票,无法在这个阶段接受其他的投票。节点等待新一轮的投票。

在第五阶段,节点D获得了多数投票,变成leader。
>> 日志复制
一旦我们选举出一个leader,我们需要向系统中的所有节点复制所有的更改。通过使用与被用于心跳的相同的Append Entries消息完成。现在我们来看看这个进程。
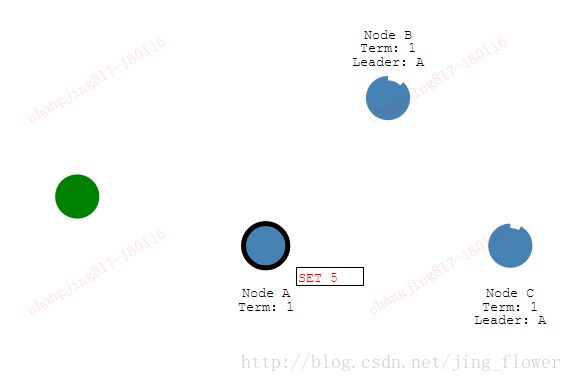
首先一个客户端向leader发送一个更改,这个更改记录在leader的log中,这个更改发送给Follower在下一个心跳中。实体提交一但大多数Follower获得它,将相应发送给客户端。

现在发送一个命令增加2,我们的系统被更新到7.
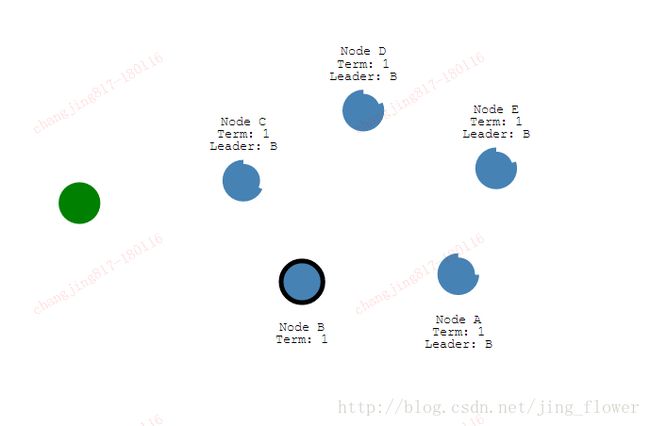
Raft可以保持一致,面对网络墙。我们添加一个墙隔离AB和CDE。
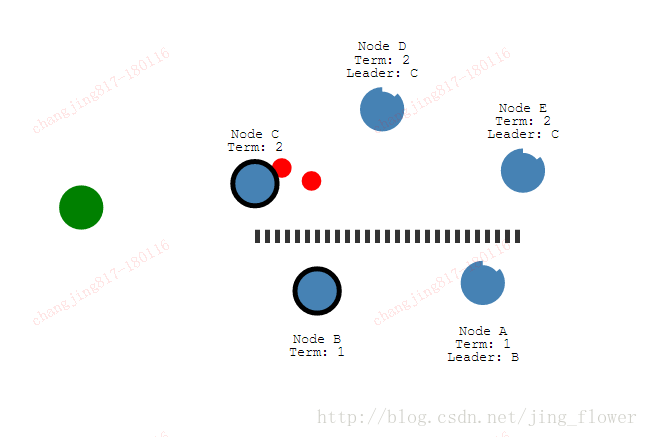
因为我们的墙,在不同的阶段具有两个leader。
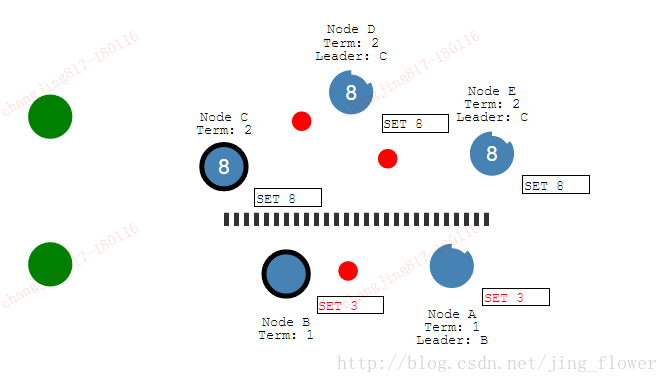
再添加一个客户端,试图去更新两个leader,一个客户端试图将节点B设置为3.节点B不能复制到多数节点,它的日志实体不能提交。客户端试图将节点C的值设置为8,将会成功,因为可以复制到大多数节点。现在我们恢复网络,节点B看到更高的选举阶段,自己转化为follower。
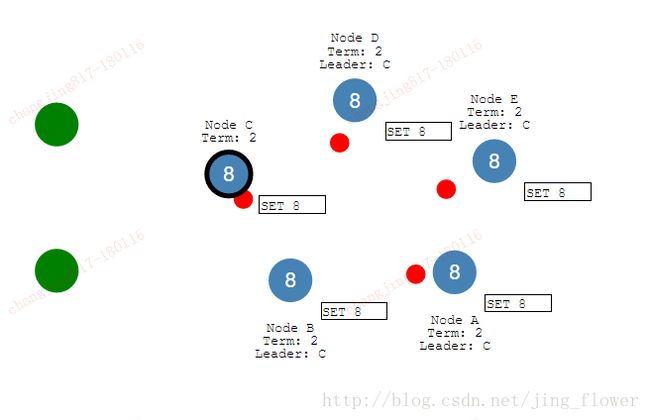
节点AB将回滚他们的未提交实体,匹配新的leader日志。日志在整个集群保持一致性。
**Raft日志
当写接受到规定数据,raft组领导者提交,他们将写入raft log。它提供了一个有序的指令集,是得到副本同意的,并且是一致副本的真实源。
因为日志是序列化的,可以被重放,使一个节点从过去的一个状态达到当前的状态。这个日志使节点当前离线可以被捕获,并恢复到当前状态,不需要对当前已存在数据进行快照,获得数据副本。
**快照
每个副本可以被快照,快照是所有数据的副本有一个精确的时间戳(因为MVCC),在重新平衡(rebalance)中,快照可以发送给其他节点加快复制。
在加载快照之后,节点需要从raft组日志中,重放所有的快照时间点后的动作。
**租约
一个单独的节点作为租约获得者(leaseholder),对于raft组leader(所有来自于DistSender的动作,将接受到BatchRequests),只有一个节点可以提供读或者写服务。
在读服务中,通过raft的租约获得者,对于租约获得者的写在一个地方提交时,必须已经达到一致状态,所以对于相同数据的第二次一致是没必要的。这样是有益处的raft不受网络情况影响,可以提高读的速度(不需要牺牲一致性)。
CockroachDB试图去选举一个租约获得者,这也是raft组的领导者,可以优化写的速度。
如果没有租约获得者(leaseholder),接收请求的任何节点试图成为租约获得者。为了防止两个节点都需要租约,请求方包含一个最新的有效的租约副本,如果另一个节点变成租约获得者,这个请求忽略。
--raft leadership重定向
Range租约与raftleadership完全分离。所以没有未来的努力,相同的副本不会同时持有raftleadership与range租约。不过我们可以优化query的表现,相同的节点成为raftleader和 leaseholder(租约获得者),可以减少了网络往返,如果leaseholder收到请求可以简单的给他自己发送raft的命令,不需要与其他节点交流。
为了达到这个,每个租约重建或者转移试图搭配他们,在实验中,错配是极少的,可以被快速自我修正。
--Epoch-Based Leases,基于代际的租约(表数据)
为了管理表数据的租约,cockroachDB实现了”epoch”(代)的概念,代是一个节点加入集群到与集群失连的一段时间。当一个节点失连,epoch改变,节点失去了它的所有租约。
这个机制使我们没必要跟踪每个range的租约,消除了大量的交易,我们可以视为一个租约不会过期,直到节点失连。
--基于期限的租约(元或者系统range)
表的元range和系统range(具体查看分发层)被视为正常的KV数据,因此租约也是。与使用epochs(代)不同,他们有一个基于期限的租约。这些租约过期有一个具体的时间戳(一般是几秒),不过只要节点继续发送raft指令,就继续续期租约。否则,包含副本的另一个节点试图读或者写range变成租约获得者。
**成员改变: 重新平衡或者修复
无论何时集群中的节点数目改变,raft 组改变,为了保证最优的耐受性和性能,副本需要重新平衡。节点数目即节点添加或者下线。
节点添加:一个新节点与自己及其他节点交流,表明有空余的空间。集群重新平衡一些副本到新的节点。
节点下线:如果raft group的一个节点停止响应,5分钟后,接线会自动下线,集群开始复制数据,重新平衡。
**重新平衡副本集
当cockroachDB检测到一个成员改变,副本将在节点之间移动。使用leaseholder的副本快照,当通过gRpc发送数据到其他节点,在转换完成之后,节点拥有新的副本加入到range的raft组中,检查range的raft组的最近实体最新的时间戳,在节点上重放raft log中所有的事件。
1.5.3 与其他节点交互
**复制层与分布式层
复制层接收来自自己或其他节点的DistSender发送的请求,如果节点是这个range的租约获得者,接受这个请求,如果不是,返回错误,并返回指针,指向租约获得者,这些KV请求转化为raft命令。
复制层发送BatchResponses 返回给分布式层的DistSender。
**复制层与存储层
提交raft命令被写入raft日志中,最终通过存储层存储在磁盘上。
租约获得者通过RocksDB实例处理读,在存储层。