Java代码操作xml文件--dom解析
一、Dom解析
使用Java自带的包对xml文件进行操作
(1)Node接口和Document接口
1)Node接口,Node 接口是整个文档对象模型的主要数据类型,它表示该文档树中的单个节点。
2)Document接口继承Node接口,Document 接口表示整个 HTML 或 XML 文档。从概念上讲,它是文档树的根,并提供对文档数据的基本访问。
(2)创建Document对象
1)DocumentBuilderFactory.newInstance() 获取DocumentBuilderFactory对象
2)documentBuilderFactory.newDocumentBuilder() 获取DocumentBuilder对象
3)duocumentBuilder.parse(String uri) 获取Document对象
注意:可以把获取document的代码写成一个方法,简化后续的获取。
(3)创建Transformer对象
作用->将内存中的document对象写入xml文件
1)TransformerFactory.newInstance() 获取TransformerFactory()对象
2)transformerFactory.newTransformer() 获取Transformer对象
3)transformer.transform() 将document写入xml文件
二、对xml文件进行增删改查
(1)增:
package com.practise01;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.*;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.IOException;
public class AddXml {
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException, TransformerException {
/*xml文件
*
* 添加Brand元素
* 思想:
* 创建两个元素
* 将两个元素建立父子
* 再将这个整体与根元素建立父子关系
* 最后将document从内存中写入xml文件
* */
// 获取document对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
Document document = documentBuilder.parse("收藏信息.xml");
// 创建Brand元素
Element brandElement = document.createElement("Brand");
// 设置元素属性及值
brandElement.setAttribute("name","OnePlus");
// 创建Type元素
Element typeElement = document.createElement("Type");
// 设置元素属性及值
typeElement.setAttribute("name","11 Pro");
// 建立父子关系 使用appendChild(Node child) 由于Element继承Node 多态
brandElement.appendChild(typeElement);
// 再将brandElement与根元素PhoneInfo建立父子关系
NodeList phoneInfoNodeList = document.getElementsByTagName("PhoneInfo");
// 该集合就一个元素 则无需便利直接使用item(int index)取元素
phoneInfoNodeList.item(0).appendChild(brandElement);
// 至关重要的一步 就是将内存中document写入到xml文件 否则以上操作始终在内存
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
// transformer调用transform(Source s,Result r)方法
// 首先获取两个参数
DOMSource domSource = new DOMSource(document);
Result result = new StreamResult("收藏信息.xml");
// 调用方法 将document写入收藏信息.xml
transformer.transform(domSource,result);
}
}
xml文件:由于dom解析局限性,不会自动缩进
(2)删除:
package com.practise01;
import com.xmlutil.XmlUtil;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class RemoveXml {
public static void main(String[] args) {
// 获取document的过程繁琐且重复 所以包装成工具类直接调用
/*
*
* */
// 获取document对象 使用写好的工具类
Document document = XmlUtil.getDocument("收藏信息.xml");
// 获取元素节点
NodeList brandNodeList = document.getElementsByTagName("Brand");
// 遍历集合找到要删除的元素 如OnePlus
for (int i = 0; i < brandNodeList.getLength(); i++) {
// 取出集合元素
Node brandNode = brandNodeList.item(i);
// 向下转型
Element brandElement = (Element) brandNode;
// 判断是否为要删除的元素
if (brandElement.getAttribute("name").equals("OnePlus")){
// 需要获取父元素才能删除子元素
brandElement.getParentNode().removeChild(brandElement);
}
}
// 删除完后 一定记得将缓存中的document写入xml文件
// 使用写好的工具类
XmlUtil.save(document,"收藏信息.xml");
}
}
xml文件:
(3)改:
package com.practise01;
import com.xmlutil.XmlUtil;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class SetXml {
public static void main(String[] args) {
/* 对xml文件中的元素进行修改操作
*
*
* */
// 获取document对象
Document document = XmlUtil.getDocument("收藏信息.xml");
// 获取Brand的元素
NodeList brandNodeList = document.getElementsByTagName("Brand");
// 遍历 找到要修改的元素 如修改小米为XiaoMi
for (int i = 0; i < brandNodeList.getLength(); i++) {
// 将集合中的元素取出
Node brandNode = brandNodeList.item(i);
// 向下转型
Element brandElement = (Element) brandNode;
// 判断
if (brandElement.getAttribute("name").equals("小米")){
brandElement.setAttribute("name","XiaoMi");
}
}
// 一定要将内存中的document写入xml文件
XmlUtil.save(document,"收藏信息.xml");
}
}
xml文件:
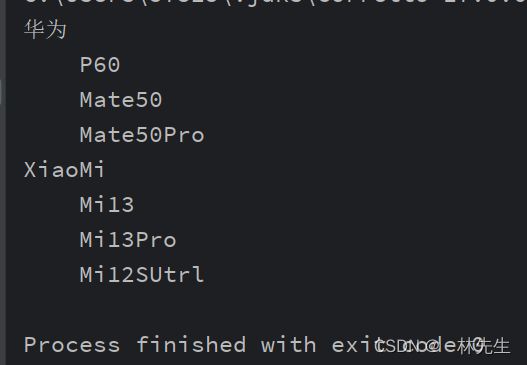
(4)查:
package com.practise01;
import com.xmlutil.XmlUtil;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class SearchXml {
public static void main(String[] args) {
/*
* 对xml文件进行遍历
*
*
* */
// 获取document对象
Document document = XmlUtil.getDocument("收藏信息.xml");
// 获取Brand元素
NodeList brandNodeList = document.getElementsByTagName("Brand");
// 遍历
for (int i = 0; i < brandNodeList.getLength(); i++) {
// 获取集合中的元素
Node brandNode = brandNodeList.item(i);
// 向下转型
Element brandElement = (Element) brandNode;
// 打印Brand
System.out.println(brandElement.getAttribute("name"));
// 再通过brandElement获取Type元素的集合
NodeList typeNodeList = brandElement.getElementsByTagName("Type");
// 重复上面步骤 遍历该集合
for (int j = 0; j < typeNodeList.getLength(); j++) {
// 获取 强转
Element typeElement = (Element) typeNodeList.item(j);
// 打印
System.out.println("\t" + typeElement.getAttribute("name"));
}
// 因为十遍历xml 所以无需写入
}
}
}
控制台: