ARM Cortex-A系列编程指南之ARMv8 A -- 第五章 ARMv8指令集介绍
ARMv8体系结构增加了64位指令集,是对现存的32位指令集的补充,被叫做A64(运行在AArch64运行状态下)。运行在AArch32运行状态下的指令集是A32和T32。
如果想详细了解A64的汇编语言,可以参考Documentation – Arm Developer,《Arm Compiler armasm User Guide Version 6.12》。
5.1 ARMv8指令集
5.1.1 区分32位和64位A64指令
在A64指令集的指令有2种形式,或者32位,或者64位。
1)寄存器以X开头,存储64bit的值
2)寄存器以W开头,存储32bit的值
当选了32位的形式:
1)右移或者反转,操作的是第31位,而不是63位
2)指令设置的条件标志,从低32位开始算
3)写W寄存器,X寄存器的高32位会被设为0
5.1.2 寻址
当处理器在一个寄存器能存储64位值的时候,在一个程序里访问大内存就变得简单了。执行在32位核上的一个单线程,只能访问最大4GB的地址空间,其中高端地址部分会被预留给OS内核、库、外围设备等使用。内存空间的缺乏,意味着程序在执行的时候需要映射一些数据到内存空间之外。64位指针,有更大的寻址空间,避免了此问题。
其他寻址方面的改进包括
1)互斥访问(exclusive access)
几个寄存器同时被更新(保证一个操作的原子性)。
2)PC寄存器的相对寻址空间增加了
PC寄存器的常量加载有不超过±1MB范围的相对寻址空间。相对于A32指令集PC存器相关的加载过程,A64减少了数据缓冲池的数量,并且增加了函数之间数据缓冲池的共享程度。反过来,也减少了对I-cache和TLB的污染。
3)对地址不对齐的支持
除了互斥访问和有序访问,所有访问普通存储空间的加载和存储过程都支持使用未对齐的地址。这简化了向A64移植代码的难度。
4)块传输
在A64指令集,LDM、STM、PUSH、POP指令不再存在。
块传输可以使用LDP、STP,他们可以从连续的存储空间中读取、存储一对相互独立的寄存器值。
LDNP、STNP指令,用于提供流或非临时数据的指示,让数据不必要长期保存在cache中。
PRFM指令(预取内存指令),能够将预先载入的内容绑定到特定的cache等级。
5)Load/Store
所有的Load/Store指令支持一致的寻址模式,这样char、short、int、long都可以使用相同的方式进行处理。
浮点寄存器和NEON寄存器也和核心寄存器一样,使用相同的寻址模式,这样也比较方便的交替使用2个寄存器组。
6)对齐检查
当在AArch64运行模式下,额外地对齐检查操作将会在如下三个过程
a、取指令
b、使用栈指针加载或存储数据
c、使能对PC和SP寄存器对齐失败检查
5.1.3 寄存器
64位程序调用标准(PCS, Procedule Call Standard)可以传最多8个参数(X0~X7),而A32和T32仅仅可以通过寄存器传4个参数,其他的通过堆栈进行。
PCS也定义了一个专用帧指针(FP:frame pointer),提高了可靠展开堆栈的可能性,降低了调试和调用图分析的难度。
不同的类型的长度,有一些标准:
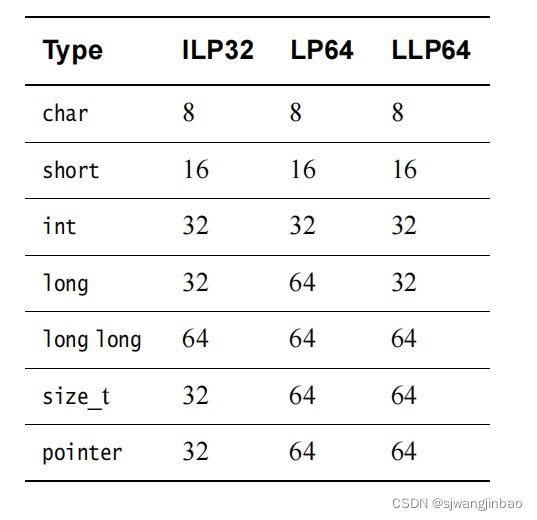
64位的Linux使用的是LP64标准。
1)零寄存器(WZR/XZR)
a、它会被用在一些编程技巧中
b、不用立即数0,直接用零寄存器
c、空指令
2)堆栈指针
堆栈指针不能被所有的指令访问,一些形式的算数指令可以读或写当前的栈指针。这种操作通常用来在函数开始或结束的位置调整栈指针的位置。例如 ADD SP, SP, #256 // SP = SP + 256。
3)程序计数器
4)FP和NEON寄存器
目前有32个16位 NEON寄存器,之前是16个。浮点和NEON寄存器组中不同的寄存器尺寸之间有更简单的映射表,让这些寄存器更加易用。新的映射表让编译和优化器的建模和分析变得更容易。
5)寄存器变址寻址
base + index 乘 scale
5.2 C/C++内联汇编
如何将汇编代码,集成在C、C++代码里呢?用asm关键字,例如:
在C、C++与汇编之间互相调用需要遵守AAPCS64规范,可以参考:Using Assembly Language with C (Using the GNU Compiler Collection (GCC))
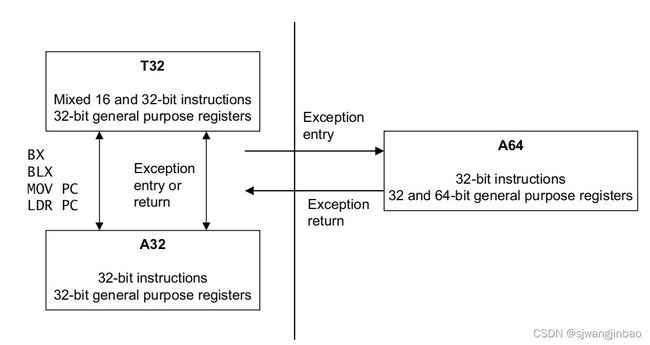
5.3 各个指令集之间进行切换
在一个应用程序中,使用两种执行状态的代码是不可能的。
以A64 ARMv8写得代码,不能运行在ARMv7系列的处理器上。但是为ARMv7-A写得代码能够运行在ARMv8的AArch32运行状态。
可以总结如下:
=========================================================================
注意:本文为本人原创,版权所属为个人所有,欢迎转载,但是转载请注明出处。
=========================================================================