Python数据分析案例26——时间序列的多阶段预测(GRU+RVM)
本篇案例适合理工科硕士。
承接上两篇硬核案例:Python数据分析案例25——海上风力发电预测(多变量循环神经网络)
之前都是直接预测,即用前面的数据——之前的X和之前的y直接预测未来的y。
本章介绍一个多阶段的预测方法,即先先使用机器学习的方法将X和y的映射关系找到。然后使用循环神经网络用之前的X预测未来的X,得到未来的X之后再用前面训练好的机器学习模型预测未来的y。称为多阶段的预测方法。
数据来源,同样使用上一篇的海上风电数据集,可以对比效果。
机器学习模型采用RVM,相关向量机,同样也是学术界很喜欢的方法,回归问题上表现还不错。
代码准备
导入包和定义RVM类:
import os
import math
import time
import datetime
import random as rn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_score
import tensorflow as tf
import keras
from keras.models import Model, Sequential
from keras.layers import GRU, Dense,Conv1D, MaxPooling1D,GlobalMaxPooling1D,Embedding,Dropout,Flatten,SimpleRNN,LSTM
from keras.callbacks import EarlyStopping
#from tensorflow.keras import regularizers
#from keras.utils.np_utils import to_categorical
from tensorflow.keras import optimizersRVM
"""Relevance Vector Machine classes for regression and classification."""
from scipy.optimize import minimize
from scipy.special import expit
from sklearn.base import BaseEstimator, RegressorMixin, ClassifierMixin
from sklearn.metrics.pairwise import (
linear_kernel,
rbf_kernel,
polynomial_kernel
)
from sklearn.multiclass import OneVsOneClassifier
from sklearn.utils.validation import check_X_y
class BaseRVM(BaseEstimator):
"""Base Relevance Vector Machine class.
Implementation of Mike Tipping's Relevance Vector Machine using the
scikit-learn API. Add a posterior over weights method and a predict
in subclass to use for classification or regression.
"""
def __init__(
self,
kernel='rbf',
degree=3,
coef1=None,
coef0=0.0,
n_iter=3000,
tol=1e-3,
alpha=1e-6,
threshold_alpha=1e9,
beta=1.e-6,
beta_fixed=False,
bias_used=True,
verbose=False
):
"""Copy params to object properties, no validation."""
self.kernel = kernel
self.degree = degree
self.coef1 = coef1
self.coef0 = coef0
self.n_iter = n_iter
self.tol = tol
self.alpha = alpha
self.threshold_alpha = threshold_alpha
self.beta = beta
self.beta_fixed = beta_fixed
self.bias_used = bias_used
self.verbose = verbose
def get_params(self, deep=True):
"""Return parameters as a dictionary."""
params = {
'kernel': self.kernel,
'degree': self.degree,
'coef1': self.coef1,
'coef0': self.coef0,
'n_iter': self.n_iter,
'tol': self.tol,
'alpha': self.alpha,
'threshold_alpha': self.threshold_alpha,
'beta': self.beta,
'beta_fixed': self.beta_fixed,
'bias_used': self.bias_used,
'verbose': self.verbose
}
return params
def set_params(self, **parameters):
"""Set parameters using kwargs."""
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def _apply_kernel(self, x, y):
"""Apply the selected kernel function to the data."""
if self.kernel == 'linear':
phi = linear_kernel(x, y)
elif self.kernel == 'rbf':
phi = rbf_kernel(x, y, self.coef1)
elif self.kernel == 'poly':
phi = polynomial_kernel(x, y, self.degree, self.coef1, self.coef0)
elif callable(self.kernel):
phi = self.kernel(x, y)
if len(phi.shape) != 2:
raise ValueError(
"Custom kernel function did not return 2D matrix"
)
if phi.shape[0] != x.shape[0]:
raise ValueError(
"Custom kernel function did not return matrix with rows"
" equal to number of data points."""
)
else:
raise ValueError("Kernel selection is invalid.")
if self.bias_used:
phi = np.append(phi, np.ones((phi.shape[0], 1)), axis=1)
return phi
def _prune(self):
"""Remove basis functions based on alpha values."""
keep_alpha = self.alpha_ < self.threshold_alpha
if not np.any(keep_alpha):
keep_alpha[0] = True
if self.bias_used:
keep_alpha[-1] = True
if self.bias_used:
if not keep_alpha[-1]:
self.bias_used = False
self.relevance_ = self.relevance_[keep_alpha[:-1]]
else:
self.relevance_ = self.relevance_[keep_alpha]
self.alpha_ = self.alpha_[keep_alpha]
self.alpha_old = self.alpha_old[keep_alpha]
self.gamma = self.gamma[keep_alpha]
self.phi = self.phi[:, keep_alpha]
self.sigma_ = self.sigma_[np.ix_(keep_alpha, keep_alpha)]
self.m_ = self.m_[keep_alpha]
def fit(self, X, y):
"""Fit the RVR to the training data."""
X, y = check_X_y(X, y)
n_samples, n_features = X.shape
self.phi = self._apply_kernel(X, X)
n_basis_functions = self.phi.shape[1]
self.relevance_ = X
self.y = y
self.alpha_ = self.alpha * np.ones(n_basis_functions)
self.beta_ = self.beta
self.m_ = np.zeros(n_basis_functions)
self.alpha_old = self.alpha_
for i in range(self.n_iter):
self._posterior()
self.gamma = 1 - self.alpha_*np.diag(self.sigma_)
self.alpha_ = self.gamma/(self.m_ ** 2)
if not self.beta_fixed:
self.beta_ = (n_samples - np.sum(self.gamma))/(
np.sum((y - np.dot(self.phi, self.m_)) ** 2))
self._prune()
if self.verbose:
print("Iteration: {}".format(i))
print("Alpha: {}".format(self.alpha_))
print("Beta: {}".format(self.beta_))
print("Gamma: {}".format(self.gamma))
print("m: {}".format(self.m_))
print("Relevance Vectors: {}".format(self.relevance_.shape[0]))
print()
delta = np.amax(np.absolute(self.alpha_ - self.alpha_old))
if delta < self.tol and i > 1:
break
self.alpha_old = self.alpha_
if self.bias_used:
self.bias = self.m_[-1]
else:
self.bias = None
return self
class RVR(BaseRVM, RegressorMixin):
"""Relevance Vector Machine Regression.
Implementation of Mike Tipping's Relevance Vector Machine for regression
using the scikit-learn API.
"""
def _posterior(self):
"""Compute the posterior distriubtion over weights."""
i_s = np.diag(self.alpha_) + self.beta_ * np.dot(self.phi.T, self.phi)
self.sigma_ = np.linalg.inv(i_s)
self.m_ = self.beta_ * np.dot(self.sigma_, np.dot(self.phi.T, self.y))
def predict(self, X, eval_MSE=False):
"""Evaluate the RVR model at x."""
phi = self._apply_kernel(X, self.relevance_)
y = np.dot(phi, self.m_)
if eval_MSE:
MSE = (1/self.beta_) + np.dot(phi, np.dot(self.sigma_, phi.T))
return y, MSE[:, 0]
else:
return y
准备数据
读取数据
data0=pd.read_excel('5.xlsx').iloc[:1000,:].set_index('Sequence No.').rename(columns={'y (% relative to rated power)':'y'})
data0.head()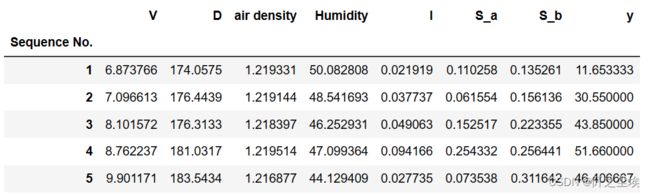
取出X和y,标准化:
X=data0.iloc[:,:-1] ; y=data0.iloc[:,-1]
scaler_s = StandardScaler()
scaler_s.fit(X)
X_s = scaler_s.transform(X)拟合RVM模型,下面使用了三种不同核函数的RVM。
#构建RVM模型
rvm_model_linear = RVR(kernel="linear")
rvm_model_linear.fit(X_s, y)
print(rvm_model_linear.score(X_s, y))
rvm_model_rbf = RVR(kernel="rbf")
rvm_model_rbf.fit(X_s, y)
print(rvm_model_rbf.score(X_s, y))
rvm_model_poly = RVR(kernel="poly")
rvm_model_poly.fit(X_s, y)
print(rvm_model_poly.score(X_s, y))
可以看到RBF核表现效果最好,后面默认使用RBF核的RVM。
深度学习准备
定义一些函数,固定随机数种子,回归问题评价指标函数
def set_my_seed():
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(1)
rn.seed(12345)
tf.random.set_seed(123)
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
r_2=r2_score(y_test, y_predict)
return mae, rmse, mape,r_2 #mse定义构建训练集和测试集的数据函数:
def build_sequences(text, window_size=24):
#text:list of capacity
x, y = [],[]
for i in range(len(text) - window_size):
sequence = text[i:i+window_size]
target = text[i+window_size]
x.append(sequence)
y.append(target)
return np.array(x), np.array(y)
def get_traintest(data,train_size=len(data0),window_size=24):
train=data[:train_size]
test=data[train_size-window_size:]
X_train,y_train=build_sequences(train,window_size=window_size)
X_test,y_test=build_sequences(test,window_size=window_size)
return X_train,y_train,X_test,y_test定义模型函数(5种神经网络模型),还有画损失图和拟合图对比的函数。
def build_model(X_train,mode='LSTM',hidden_dim=[32,16]):
set_my_seed()
model = Sequential()
if mode=='RNN':
#RNN
model.add(SimpleRNN(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(SimpleRNN(hidden_dim[1]))
elif mode=='MLP':
model.add(Dense(hidden_dim[0],activation='relu',input_shape=(X_train.shape[-1],)))
model.add(Dense(hidden_dim[1],activation='relu'))
elif mode=='LSTM':
# LSTM
model.add(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(LSTM(hidden_dim[1]))
elif mode=='GRU':
#GRU
model.add(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(GRU(hidden_dim[1]))
elif mode=='CNN':
#一维卷积
model.add(Conv1D(hidden_dim[0], kernel_size=3, padding='causal', strides=1, activation='relu', dilation_rate=1, input_shape=(X_train.shape[-2],X_train.shape[-1])))
#model.add(MaxPooling1D())
model.add(Conv1D(hidden_dim[0], kernel_size=3, padding='causal', strides=1, activation='relu', dilation_rate=2))
#model.add(MaxPooling1D())
model.add(Conv1D(hidden_dim[0], kernel_size=3, padding='causal', strides=1, activation='relu', dilation_rate=4))
#GlobalMaxPooling1D()
model.add(Flatten())
model.add(Dense(1))
model.compile(optimizer='Adam', loss='mse',metrics=[tf.keras.metrics.RootMeanSquaredError(),"mape","mae"])
return model
def plot_loss(hist,imfname):
plt.subplots(1,4,figsize=(16,2))
for i,key in enumerate(hist.history.keys()):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(hist.history[key], 'k', label=f'Training {key}')
plt.title(f'{imfname} Training {key}')
plt.xlabel('Epochs')
plt.ylabel(key)
plt.legend()
plt.tight_layout()
plt.show()
def plot_fit(y_test, y_pred,name):
plt.figure(figsize=(4,2))
plt.plot(y_test, color="red", label="actual")
plt.plot(y_pred, color="blue", label="predict")
plt.title(f"{name}拟合值和真实值对比")
plt.xlabel("Time")
plt.ylabel(name)
plt.legend()
plt.show()定义训练函数:
df_eval_all=pd.DataFrame(columns=['MAE','RMSE','MAPE','R2'])
df_preds_all=pd.DataFrame()
def train_fuc(mode='LSTM',window_size=64,batch_size=32,epochs=50,hidden_dim=[32,16],train_ratio=0.8,kernel="rbf",show_loss=True,show_fit=True):
df_preds=pd.DataFrame()
#预测每一列
for i,col_name in enumerate(data0.columns):
print(f'正在处理变量:{col_name}')
#准备数据
data=data0[col_name]
train_size=int(len(data)*train_ratio)
X_train,y_train,X_test,y_test=get_traintest(data.values,window_size=window_size,train_size=train_size)
#print(X_train.shape,y_train.shape,X_test.shape,y_test.shape)
#归一化
scaler = MinMaxScaler()
scaler = scaler.fit(X_train)
X_train=scaler.transform(X_train) ; X_test=scaler.transform(X_test)
y_train_orage=y_train.copy() ; y_scaler = MinMaxScaler()
y_scaler = y_scaler.fit(y_train.reshape(-1,1))
y_train=y_scaler.transform(y_train.reshape(-1,1))
if mode!='MLP':
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
#构建模型
s = time.time()
set_my_seed()
model=build_model(X_train=X_train,mode=mode,hidden_dim=hidden_dim)
earlystop = EarlyStopping(monitor='loss', min_delta=0, patience=5)
hist=model.fit(X_train, y_train,batch_size=batch_size,epochs=epochs,callbacks=[earlystop],verbose=0)
if show_loss:
plot_loss(hist,col_name)
#预测
y_pred = model.predict(X_test)
y_pred = y_scaler.inverse_transform(y_pred)
#print(f'真实y的形状:{y_test.shape},预测y的形状:{y_pred.shape}')
if show_fit:
plot_fit(y_test, y_pred,name=col_name)
e=time.time()
print(f"运行时间为{round(e-s,3)}")
df_preds[col_name]=y_pred.reshape(-1,)
s=list(evaluation(y_test, y_pred))
s=[round(i,3) for i in s]
print(f'{col_name}变量的预测效果为:MAE:{s[0]},RMSE:{s[1]},MAPE:{s[2]},R2:{s[3]}')
print("=================================================================================")
X_pred=df_preds.iloc[:,:-1]
X_pred_s = scaler_s.transform(X_pred)
y_direct=df_preds.iloc[:,-1]
if kernel=="rbf":
y_nodirect=rvm_model_rbf.predict(X_pred_s)
if kernel=="linear":
y_nodirect=rvm_model_linear.predict(X_pred_s)
if kernel=="ploy":
y_nodirect=rvm_model_ploy.predict(X_pred_s)
score1=list(evaluation(y_test, y_direct))
score2=list(evaluation(y_test, y_nodirect))
df_preds_all[mode]=y_direct
df_preds_all[f'{mode}+RVM']=y_nodirect
df_eval_all.loc[f'{mode}',:]=score1
df_eval_all.loc[f'{mode}+RVM',:]=score2
print(score2)
开始训练
初始化超参数
window_size=64
batch_size=32
epochs=50
hidden_dim=[32,16]
train_ratio=0.8
kernel="rbf"
show_fit=True
show_loss=True
mode='LSTM' #RNN,GRU,CNNLSTM预测
mode='LSTM'
set_my_seed()
train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)结果有点长,因为是每个X都是要经过一次循环神经网络预测的,最后再使用RVM结合一起预测y。可以看到最后的预测效果是0.95%。还行,但是直接用y自己预测自己拟合优度有97.5%。说明这种多阶段的方法不如直接预测。
RNN
不同的模型改mode参数就行
mode='RNN'
set_my_seed()
train_fuc(mode=mode,window_size=window_size,batch_size=32,epochs=epochs,hidden_dim=hidden_dim)RNN太慢了我这里就没运行。
GRU
mode='GRU'
set_my_seed()
train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)就不截那么长的图了,看最后的结果图
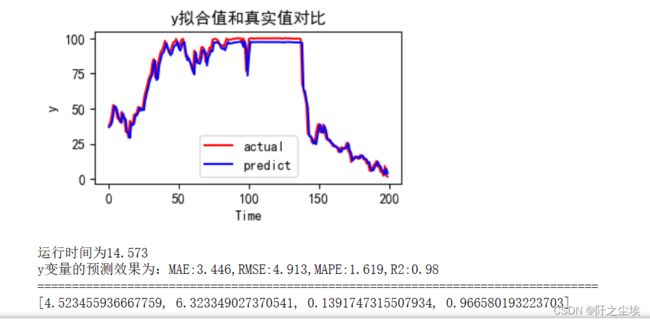
直接预测98%,多阶段96.6%。
CNN
mode='CNN'
set_my_seed()
train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)
MLP
mode='MLP'
set_my_seed()
train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=60,hidden_dim=hidden_dim)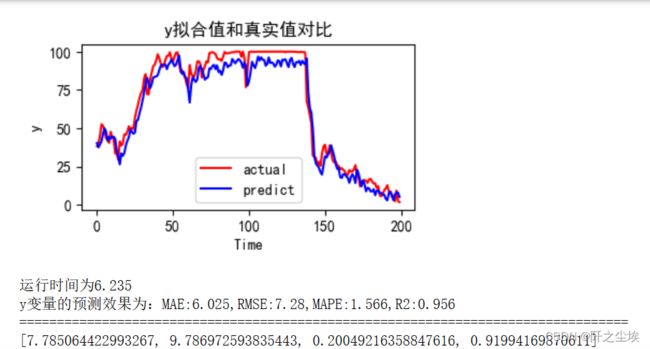
结论
查看所有模型的对比:
df_eval_all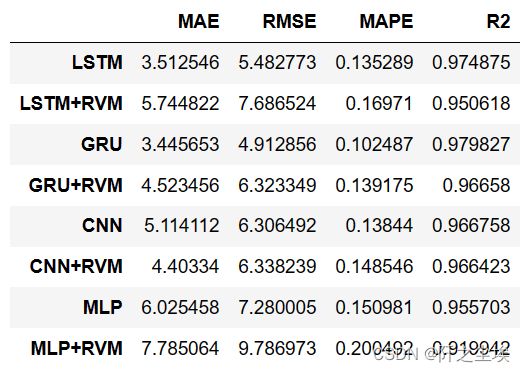
可以看到,加了RVM的多阶段预测基本表现都没直接预测的好, GRU和LSTM模型表现还是最好的。加了RVM准确率都下降了,这也是自然,你非要多塞一个方法进去,你的X就不是真实的X,X就有误差了,预测的y的误差自然就大一些。
也不知道为什么那么多论文为什么说这样多阶段的预测效果好,说自己做的多阶段模型比直接预测效果好。。。为了缝合模型显得有创新,然后都在乱编预测结果。。。其实很多时候都是一顿操作猛如虎,模型一顿缝合,论文看起来很有创新性,但是效果是越搞越差.....但是为了表现自己模型效果好就狂调参。。。学术界这个现象得管管了。