kafka查看topic中的数据_实战!Kafka Manager能统计出Topic中的记录条数吗?

问题描述
今天现场实施同事说Kafka Manager上显示有3500w条记录,但使用我们的平台落地后,一统计发现只有2200w条记录,这是不是说明我们的平台存在丢数据的可能。
经了解,对接方是通过如下界面来判断topic中的记录条数的。
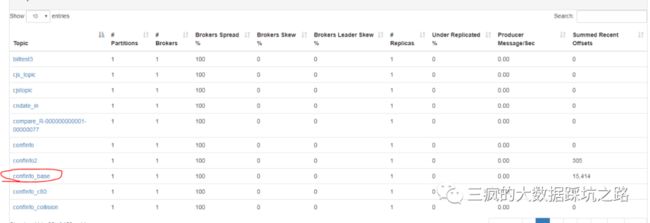 上图是Kafka Manager的其中一个界面,该界面显示了Kafka Topic的分区数,Broker的分布情况,以及每个Topic中Recent Offset之和。(在各个分区中,Offset值都是从0开始往后递增的)
上图是Kafka Manager的其中一个界面,该界面显示了Kafka Topic的分区数,Broker的分布情况,以及每个Topic中Recent Offset之和。(在各个分区中,Offset值都是从0开始往后递增的)
在很久以前,我们团队其实已经考虑到了数据丢失的可能,于是,利用StreamingListener接口去监听StreamingListenerBatchCompleted事件,只有监听到该事件,才会去提交offset。理论上来说,我们的平台是可以保证“至少一次”的语义。竟然敢怀疑我维护了四年的大数据平台!不能忍,我得证明不是我的问题啊~
在开启甩锅大法之前,首先介绍一下与本题有一定关联度的知识点——Kafka的老化机制。
kafka老化机制
有两种情况,会触发Kafka的老化机制
一、根据设定时间触发Kafka老化。
相关的配置项有
log.retention.hourslog.retention.minuteslog.retention.ms这三个参数都是用来设置老化时间的,只是时间单位不太一样。这些参数都是topic级别的,既可以通过命令的方式对特定的topic设置老化时间,也可以在server.properties文件里配置。
命令方式设置老化时间如下:
./kafka-configs.sh --zookeeper 127.0.0.1:2181 --entity-type topics --entity-name aypayp1 --alter --add-config retention.ms=300000默认情况下,配置文件中设置了log.retention.hours为168,另外两个没有给初始值,所以默认情况下,kafka老化时间是7天。
二、根据每个分区保存数据大小。
log.retention.bytes该参数指定了每个分区保留多少字节数据,数据量超过该值,便可触发老化的动作。该参数值默认为-1,是没有限制的。
另外,还要介绍一个配置项
log.retention.check.interval.ms默认值300000该参数表示kafka进程中起了一个定时线程,该线程5分钟扫描本机器管理的所有partition数据,是否有分区满足老化条件,从而触发真正的老化动作。
综上:
默认情况下,kafka仅仅根据时间来触发老化动作。
Kafka Manager介绍
Kafka Manager是Yahoo开源的项目,也是为了更方便去维护Yahoo的kafka集群。在我的平常使用中,我可以用它来做如下的工作:
1、观察kafka topic 吞吐量,即每秒进入多少条数据。根据这个信息,我们就可以判断Spark Streaming要达到什么样的处理速度,才能够及时处理数据。
2、观察kafka中最新的offset值之和,一般可以大致知道topic中的数据量。
3、观察消费组的消费情况,消费组消费了各个分区消费了多少条,滞留了多少条。这个信息,也可以判断自己系统的处理能力。
4、观察各个分区的数据是否均衡。
甩锅过程
下面过程用来证明Kafka Manager列出的summed recent offset值,在老化的情况下,并不能代表topic总条数。
1、向topic aypayp1 发送10条数据,并在kafka Manager中确定summed recent offset值也是10。
2、用测试代码,重头消费aypayp1 topic中的数据。
结果如下:
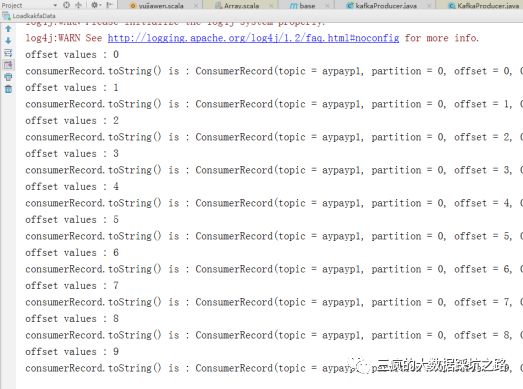
证明数据也是进去了。
3、对该topic设置老化时间,命令如下:
./kafka-configs.sh --zookeeper 127.0.0.1:2181 --entity-type topics --entity-name aypayp1 --alter --add-config retention.ms=300000查看是否生效
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --topic aypayp1 --describe4、五分钟后,再往该topic中发送10条消息,并用Kafka Manager确认summed recent offset值为20。
5、再过五分钟,重头消费该topic,消费结果如下:

通过上述过程,可以证明对接方的观点是错误的。
总结
1、kafka manager上显示的summed recent offset值,只是表征该topic接收到多少条消息,并不能代表去消费时,就能消费出这么多的消息。
2、Kafka提供了kafka-run-class.sh脚本,利用该脚本也可以查看topic每个partition的offset值区间范围,该脚本的使用方式
# 查看各个partition的最小offset值。sh kafka-run-class.sh kafka.tools.GetOffsetShell --topic mytopic --time -2 --broker-list host1:9092,host2:9092,host3:9092# 查看各个partition的最新offset值。sh kafka-run-class.sh kafka.tools.GetOffsetShell --topic mytopic--time -1 --broker-list host1:9092,host2:9092,host3:9092查看GetOffsetShell类可知,--time设为-1时,表示使用latest方式;--time设为-2时,表示使用earliest方式。通过 该类的底层实现可知,其实就是用latest或earliest方式去消费该topic,从而拿到这个区间范围。