深度学习技巧应用6-神经网络中模型冻结-迁移学习技巧
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用6-神经网络中模型冻结:迁移学习的技巧,迁移学习中的部分模型冻结是一种利用预训练模型来解决新问题的技巧,是计算机视觉,自然语言处理等任务里面最重要的技巧,也是必须要学的技巧,学会了在我们后续的深度学习应用开发有着重要的作用,我们一起学起来吧。
一、迁移学习中的模型冻结
迁移学习中的模型部分冻结(也称为fine-tuning with frozen layers)是一种常用的技巧,可以使得在训练过程中只更新模型的一部分参数,从而加速训练,提高模型的精度。在模型训练过程中如何使用模型部分冻结的迁移学习技巧呢?
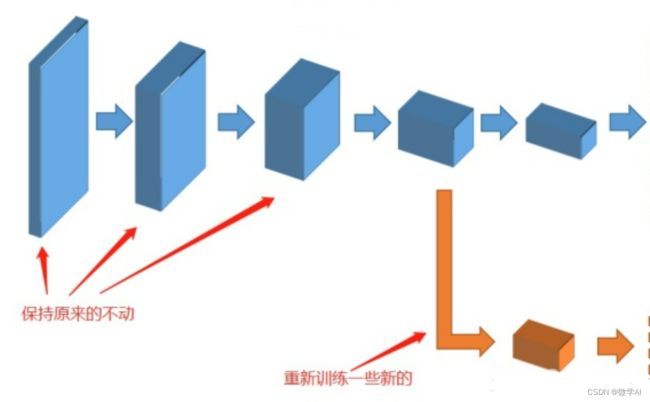
下面我来说下其中的步骤:
1. 导入预训练模型
首先,在训练模型之前,我们需要导入预训练模型,该模型通常已经在大规模数据上进行了预训练,例如在ImageNet上。Keras中有许多预训练模型可供选择,如ResNet、VGG、MobileNetV2等。
2. 选择需要冻结的层数
选择哪些层要参与训练,哪些层要冻结,这是模型部分冻结的最重要的决策,也是影响模型性能的最主要因素。一般而言,对于深度CNN模型,前面的几层包含了一些低层次的特征,这些特征具有通用性,可以被复用,因此我们可以选择冻结这些层的权重,只对后面的几层进行微调。冻结的层数可以根据具体问题和数据来决定,如果数据集和训练任务与预训练模型相似,则可以尝试冻结更多的层;如果数据集与训练任务差异较大,则可以尝试只冻结前几层。
3. 冻结权重
我们可以通过设置权重的trainable属性来冻结权重。具体来说,在Keras中可以通过调用model.layers[i].trainable = False将某些层的权重冻结起来。我们采用MobileNetV2模型进行操作,MobileNetV2是Google团队在2018年发布的深度卷积神经网络模型,主要用于图像分类、目标检测和语义分割等计算机视觉相关任务。MobileNetV2的推出是MobileNetV1的升级版本,采用了新的设计思想和优化策略,从而大幅度提高了模型的准确率和效率。
如果我们要冻结MobileNetV2模型的前10层,可以这样操作:
# 导入MobileNetV2模型
from tensorflow.keras.applications import MobileNetV2
# 构建模型
base_model =MobileNetV2(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 冻结前10层
for layer in base_model.layers[:10]:
layer.trainable = False以上操作,我们首先导入MobileNetV2模型,然后构建模型并指定input_shape。接着,我们冻结了前10层的权重,将它们的trainable属性设置为False。
4. 编译和训练模型
在冻结权重之后,我们需要重新编译模型,并开始训练。在编译模型时,我们需要选择适当的优化器和损失函数,并指定评估指标。在训练模型时,我们可以逐步解冻权重,并进行微调。一般而言,我们先解冻最后几层,让模型更加适应我们的训练数据,然后逐渐解冻更多的层,最终让整个模型都参与训练。解冻权重的代码可以使用如下方式:
# 解冻最后几层
for layer in base_model.layers[-10:]:
layer.trainable = True 以上操作中,我们解冻了MobileNetV2中的最后10层,并将它们的trainable属性设置为True。接着,我们可以开始训练模型,使用fit或fit_generator方法。
二、模型冻结代码案例
from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import MobileNetV2
# 加载CIFAR10数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 数据预处理
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 加载MobileNetV2模型
base_model = MobileNetV2(weights='imagenet', include_top=False, input_shape=(32, 32, 3))
#冻结前10个卷积层,其余权重参与微调
for layer in base_model.layers[:10]:
layer.trainable = False
# 在MobileNetV2基础上构建新模型
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(256, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(10, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer=Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=64, epochs=30, validation_data=(x_test, y_test))
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Test loss: {loss:.4f}, Test accuracy: {accuracy:.4f}")我实现模型冻结训练的思路:
首先用了CIFAR10数据集加载器加载了数据,并对数据进行了预处理,包括归一化和one-hot编码。接着,我使用Keras中的MobileNetV2模型加载器加载了预训练模型,并冻结了前10个卷积层,其余权重参与微调。然后使用前10层的权重构建了新模型,包括两个Dense层和两个Dropout层。
最后使用了Adam优化器,并将学习率设置为1e-4,设置了交叉熵损失函数和准确率评估指标,并训练了模型。 值得注意的是,在训练模型期间,我们可以逐步解冻MobileNetV2的权重,以便让模型更好地适应我们的数据集。同时,我们可以使用早期停止方法,以避免过拟合,并提高模型的泛化性能。