Hadoop伪分布式安装与配置
本教程参考厦门大学数据库实验室 / 给力星出品,转载注明。
其中简化了安装步骤并了一些我安装时遇见的新问题。PS:创建hadoop 用户后进行登陆,此后操作在hadoop用户权限下进行
目录
文件准备
环境
创建hadoop用户
更新apt
安装SSH、配置SSH无密码登录
安装Java环境(手动安装)
安装Hadoop
Hadoop伪分布式配置
文件准备
JDK1.8安装包(提取码:6str)
hadoop-2.10.0(提取码:52pr)(如需搭建HBase,请选择兼容性匹配的hadoop安装包进行安装)
WinSCR(提取码:azzw)
环境
本教程使用 Ubuntu 18.04 64位 作为系统环境(Ubuntu其它版本也行,32位、64位均可)
装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做一些必备工作。
创建hadoop用户
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo在登陆界面中选择刚创建的 hadoop 用户进行登陆,此后操作在hadoop用户权限下进行(重要)。
su hadoop更新apt
建议使用阿里云软件源,提高下载速度,shell命令前进行软件源设置。
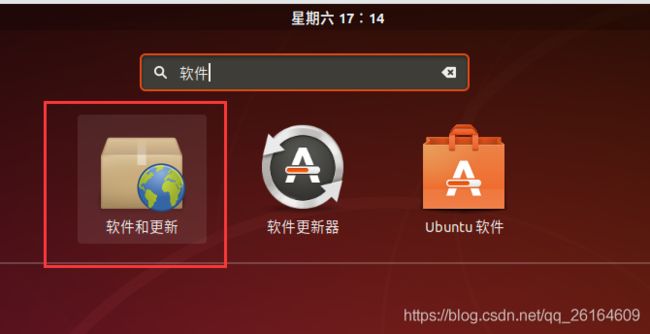

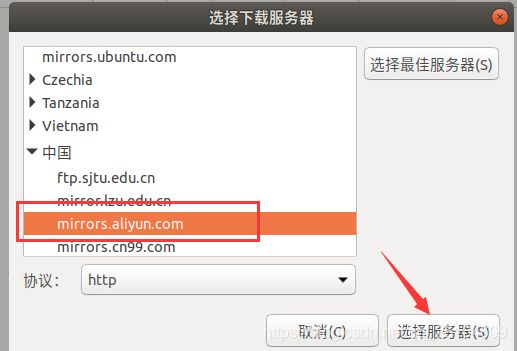
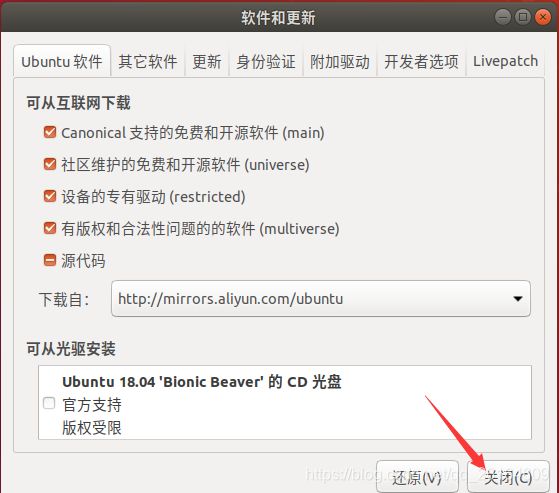
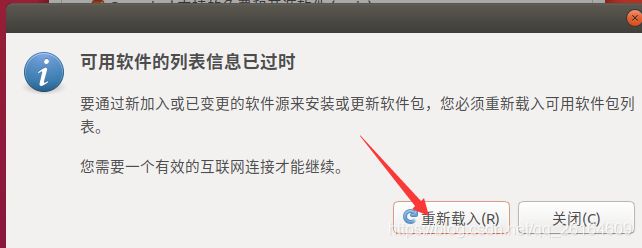
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt-get update安装SSH、配置SSH无密码登录
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server安装后,可以使用如下命令登陆本机:
ssh localhost此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
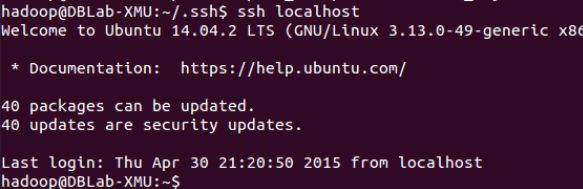
问题小结:
ssh localhost 登录时出现Permission denied,Please try again。
是因为在root用户权限下造成的,使用命 su hadoop 切换到hadoop用户登陆即可

安装Java环境(手动安装)
使用WinSCR SSH工具将前面下载的JDK压缩包与hadoop压缩包远程传输到ubuntu
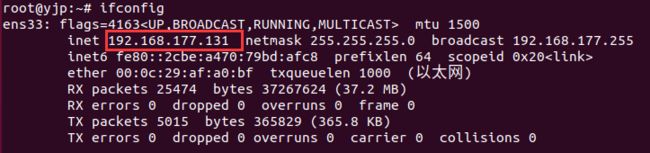
使用如下命令查看ubuntu网卡IP地址:
sudo apt-get install net-tools #先安装网络工具
ifconfig #查看ip
打开WinSCR连接ubuntu

选择目录进行传输,如果出现传输失败,是ubuntu文件夹权限问题,设置一下文件夹权限即可。
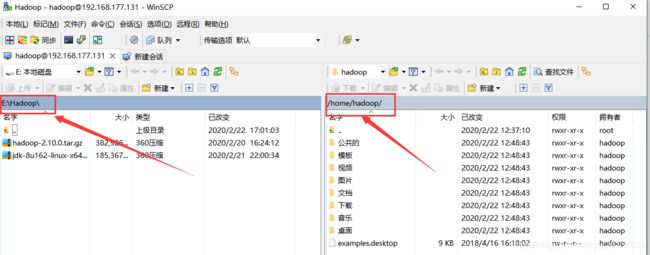
WinSCR连接ubuntu,看不懂我写的点这个!
接下来需要按照下面步骤来自己手动安装JDK1.8。
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下也可直接在文件系统中直接提取hadoop压缩文件,不使用tar命令
上面使用了解压缩命令tar,如果对Linux命令不熟悉,可以参考常用的Linux命令用法。
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_162目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc这时,可以使用如下命令查看是否安装成功:
java -version如果能够在屏幕上返回如下信息,则说明安装成功:

安装Hadoop
我们选择将 Hadoop 安装至 /usr/local/ 中:(也可直接在文件系统中直接提取hadoop压缩文件,不使用tar命令)
sudo tar -zxf ~/Download/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop versionHadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
修改为下面配置:
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
同样的,修改配置文件 hdfs-site.xml:
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format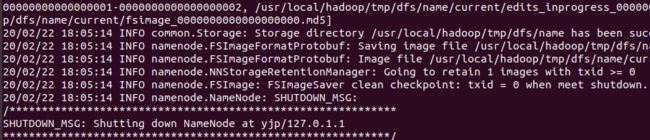
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。如果已经按照前面教程在.bashrc文件中设置了JAVA_HOME,还是出现 Error: JAVA_HOME is not set and could not be found. 的错误,那么,请到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,然后,再次启动Hadoop。一般只要java环境配置对不会出现此类问题,回过头查看java环境是否生效。
如果格式化时抛出io异常,参考Hadoop格式化namenode错误:java.io.IOException: Cannot create directory
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格若出现如下SSH提示,输入yes即可。
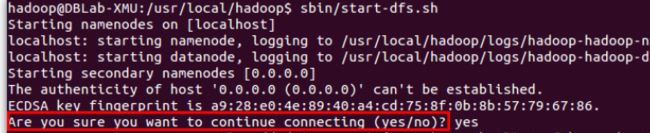
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,并不会影响正常使用。
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤或通过查看启动日志排查原因。
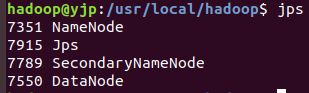
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。

如遇其他上面没有阐述到的其它问题,具体请参照Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04