【golang基础教程(持续更新ing)】
精简的GOLANG基础教程
- go语言须知
- go语言环境
- go常用命令
- go语言标识符&关键字
-
- 标识符
- 关键字
- go语言数据类型
-
- 变量
- 常量
- 布尔类型
- 数字类型
- 字符串类型
- type关键字
- go语言格式化输出
- go语言运算符
-
- 算数运算符
- 关系运算符
- 逻辑运算符
- 赋值运算符
- 位运算符
- 其他运算符
- 运算符的优先级
- 键盘输入语句
- 进制
- 位运算
- go语言控制语句
-
- 分支结构
- 循环结构
- switch
- goto&break&continue
- go语言容器
-
- 数组
- 切片
- map
- go语言函数
-
- 函数
- 函数类型实现接口
- 匿名函数
- 闭包
- 递归函数
- defer
- init函数
- go语言指针
- go语言结构体
- go语言接口
- go语言包
-
- 包的导入
- 包加载
- 包管理
go语言须知
简介
Go语言(或 Golang)起源于 2007 年,并在 2009 年正式对外发布。Go 是非常年轻的一门语言,它的主要目标是“兼具 Python 等动态语言的开发速度和 C/C++ 等编译型语言的性能与安全性”。
Go语言是编程语言设计的又一次尝试,是对类C语言的重大改进,它不但能让你访问底层操作系统,还提供了强大的网络编程和并发编程支持。Go语言的用途众多,可以进行网络编程、系统编程、并发编程、分布式编程。
Go语言的推出,旨在不损失应用程序性能的情况下降低代码的复杂性,具有“部署简单、并发性好、语言设计良好、执行性能好”等优势,目前国内诸多 IT 公司均已采用Go语言开发项目。
Go语言有时候被描述为“C 类似语言”,或者是“21 世纪的C语言”。Go 从C语言继承了相似的表达式语法、控制流结构、基础数据类型、调用参数传值、指针等很多思想,还有C语言一直所看中的编译后机器码的运行效率以及和现有操作系统的无缝适配。
因为Go语言没有类和继承的概念,所以它和 Java 或 C++ 看起来并不相同。但是它通过接口(interface)的概念来实现多态性。Go语言有一个清晰易懂的轻量级类型系统,在类型之间也没有层级之说。因此可以说Go语言是一门混合型的语言。
此外,很多重要的开源项目都是使用Go语言开发的,其中包括 Docker、Go-Ethereum、Thrraform 和 Kubernetes。
特点
语法简单
Go语言的语法处于简单和复杂的两极。C语言简单到你每写下一行代码,都能在脑中想象出编译后的模样,指令如何执行,内存如何分配,等等。而 C 的复杂在于,它有太多隐晦而不着边际的规则,着实让人头疼。相比较而言,Go 从零开始,没有历史包袱,在汲取众多经验教训后,可从头规划一个规则严谨、条理简单的世界。
Go语言的语法规则严谨,没有歧义,更没什么黑魔法变异用法。任何人写出的代码都基本一致,这使得Go语言简单易学。放弃部分“灵活”和“自由”,换来更好的维护性,我觉得是值得的。
并发模型
时至今日,并发编程已成为程序员的基本技能,在各个技术社区都能看到诸多与之相关的讨论主题。在这种情况下Go语言却一反常态做了件极大胆的事,从根本上将一切都并发化,运行时用 Goroutine 运行所有的一切,包括 main.main 入口函数。
可以说,Goroutine 是 Go 最显著的特征。它用类协程的方式来处理并发单元,却又在运行时层面做了更深度的优化处理。这使得语法上的并发编程变得极为容易,无须处理回调,无须关注线程切换,仅一个关键字,简单而自然。
搭配 channel,实现 CSP 模型。将并发单元间的数据耦合拆解开来,各司其职,这对所有纠结于内存共享、锁粒度的开发人员都是一个可期盼的解脱。若说有所不足,那就是应该有个更大的计划,将通信从进程内拓展到进程外,实现真正意义上的分布式。
内存分配
将一切并发化固然是好,但带来的问题同样很多。如何实现高并发下的内存分配和管理就是个难题。好在 Go 选择了 tcmalloc,它本就是为并发而设计的高性能内存分配组件。
可以说,内存分配器是运行时三大组件里变化最少的部分。刨去因配合垃圾回收器而修改的内容,内存分配器完整保留了 tcmalloc 的原始架构。使用 cache 为当前执行线程提供无锁分配,多个 central 在不同线程间平衡内存单元复用。在更高层次里,heap 则管理着大块内存,用以切分成不同等级的复用内存块。快速分配和二级内存平衡机制,让内存分配器能优秀地完成高压力下的内存管理任务。
垃圾回收
垃圾回收一直是个难题。早年间,Java 就因垃圾回收低效被嘲笑了许久,后来 Sun 连续收纳了好多人和技术才发展到今天。可即便如此,在 Hadoop 等大内存应用场景下,垃圾回收依旧捉襟见肘、步履维艰。
相比 Java,Go 面临的困难要更多。因指针的存在,所以回收内存不能做收缩处理。幸好,指针运算被阻止,否则要做到精确回收都难。
每次升级,垃圾回收器必然是核心组件里修改最多的部分。从并发清理,到降低 STW 时间,直到 Go 的 1.5 版本实现并发标记,逐步引入三色标记和写屏障等等,都是为了能让垃圾回收在不影响用户逻辑的情况下更好地工作。尽管有了努力,当前版本的垃圾回收算法也只能说堪用,离好用尚有不少距离。
静态链接
Go 刚发布时,静态链接被当作优点宣传。只须编译后的一个可执行文件,无须附加任何东西就能部署。这似乎很不错,只是后来风气变了。连着几个版本,编译器都在完善动态库 buildmode 功能,场面一时变得有些尴尬。
暂不说未完工的 buildmode 模式,静态编译的好处显而易见。将运行时、依赖库直接打包到可执行文件内部,简化了部署和发布操作,无须事先安装运行环境和下载诸多第三方库。这种简单方式对于编写系统软件有着极大好处,因为库依赖一直都是个麻烦。
标准库
功能完善、质量可靠的标准库为编程语言提供了充足动力。在不借助第三方扩展的情况下,就可完成大部分基础功能开发,这大大降低了学习和使用成本。最关键的是,标准库有升级和修复保障,还能从运行时获得深层次优化的便利,这是第三方库所不具备的。
Go 标准库虽称不得完全覆盖,但也算极为丰富。其中值得称道的是 net/http,仅须简单几条语句就能实现一个高性能 Web Server,这从来都是宣传的亮点。更何况大批基于此的优秀第三方 Framework 更是将 Go 推到 Web/Microservice 开发标准之一的位置。
当然,优秀第三方资源也是语言生态圈的重要组成部分。近年来崛起的几门语言中,Go 算是独树一帜,大批优秀作品频繁涌现,这也给我们学习 Go 提供了很好的参照。
工具链
完整的工具链对于日常开发极为重要。Go 在此做得相当不错,无论是编译、格式化、错误检查、帮助文档,还是第三方包下载、更新都有对应的工具。其功能未必完善,但起码算得上简单易用。
内置完整测试框架,其中包括单元测试、性能测试、代码覆盖率、数据竞争,以及用来调优的 pprof,这些都是保障代码能正确而稳定运行的必备利器。
除此之外,还可通过环境变量输出运行时监控信息,尤其是垃圾回收和并发调度跟踪,可进一步帮助我们改进算法,获得更佳的运行期表现。
应用领域
go语言环境
- 安装包下载
https://golang.google.cn/dl/ - 配置环境变量
GOPATH:指定go安装包路径 GOROOT:工程的目录 GOPROXY:<https://goproxy.cn> GO111MODULE:on #具体参考: - git下载&安装:
git下载 - vscode下载:
vscode下载
自定义插件配置
go常用命令
bug start a bug report
build compile packages and dependencies
clean remove object files and cached files
doc show documentation for package or symbol
env print Go environment information
fix update packages to use new APIs
fmt gofmt (reformat) package sources
generate generate Go files by processing source
get add dependencies to current module and install them
install compile and install packages and dependencies
list list packages or modules
mod module maintenance
work workspace maintenance
run compile and run Go program
test test packages
tool run specified go tool
version print Go version
vet report likely mistakes in packages
go语言标识符&关键字
标识符
Go中对各种变量、函数等命名时使用的字符序列称为标识符。
(一)标识符的命名规则
- 由26个英文字母大小写、0-9数字、_ 组成
- 数字不能开头
- 严格区分大小写(a和A是两个不同的变量)
- 标识符不能包含空格
- _ 在Go中是一个特殊的标识符,仅能作为占位符使用而不能作为标识符使用,比如返回值使用_进行忽略
- 不能以系统关键字作为标识符使用
(二)注意事项
- 包名 尽量保持package与目录的名称一致,采用简短、有意义、不和标准库重名的包名
- 变量名、函数名、常量名(大写下划线分割) 、结构体、接口 采用驼峰法命名
- 如果变量名、函数名常量名首字母大写是公开的,可以被其它包访问,如果首字母小写则是私有的,只能被本包访问
关键字
Go中有保留关键字25个,详情如下表:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
预定义标识符就是事先定义好的有特殊意义的词,与关键字类似。
append bool byte cap close complex complex64 complex128 uint16
copy false float32 float64 imag int int8 int16 uint32
int32 int64 iota len make new nil panic uint64
print println real recover string true uint uint8 uintptr
go语言数据类型
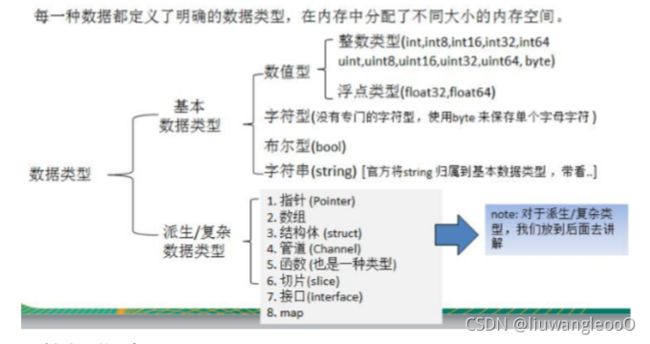
这部分先介绍基本数据类型,下面会详细介绍每个复杂数据类型
变量
变量相当于内存中数据存储空间的表示,通过变量名访问到变量值,直接上代码
package main
import (
"fmt"
"reflect"
)
func main() {
/*
变量 程序运行间 可以改变的量
*/
// 1.声名格式 var 变量名 类型 变量声明了 必须使用
// 2.只是声明没有初始化的变量 默认值为0
// 3.在同一作用域里 声明的变量名是唯一的
var a int
fmt.Println(a)
// 4.可以同时声明多个变量
// var b, c string
// 5.变量赋值
a = 10
fmt.Println(a)
// 6.声明变量&初始化
var b int = 100
b = 3
fmt.Println(b)
// 另外一种方法 := 自动推导类型
c := "aaa"
fmt.Println(c)
fmt.Println("c is ", reflect.TypeOf(c))
// 多重赋值
i, j := "ac", 100
// 匿名变量 丢弃数据
m, _ := j, i
fmt.Println(m)
}
常量
package main
import (
"fmt"
)
const (
PI = 2.22
SUPER = "dd"
)
func main() {
// 常量 运行期间 不可改变的量 常量声明需要使用const
const a int = 1000
fmt.Println(a)
//
// iota 常量自动生成器
// 给常量赋值使用
// iota遇到const 重置为0
// 可以只写一个iota
// 如果是同一行 值都一样
}
布尔类型
package main
import "fmt"
func main() {
// 布尔类型 条件判断 循环 go中0/1不能用作bool
b := true
fmt.Printf("b: %v\n", b)
}
数字类型
package main
import (
"bytes"
"fmt"
"math"
"strings"
"unsafe"
)
func main() {
/*
数字类型
int uint (8,16,32,64)
float32 float64默认
整形格式化输出 %d
进制格式化输出 %b %o %x
浮点格式化输出 %f
*/
var i8 int8
fmt.Printf("%T %dB %v~%v\n", i8, unsafe.Sizeof(i8), math.MaxInt8, math.MinInt8)
var f32 float32
fmt.Printf("%T %dB %v~%v\n", f32, unsafe.Sizeof(f32), math.MaxInt8, math.MinInt8)
}
字符串类型
package main
import (
"bytes"
"fmt"
"strings"
"unsafe"
)
func main() {
/*
字符串类型
字面量使用""或者反引号``创建
格式化输出 %s
*/
var name string = "James"
fmt.Printf("name: %v\n", name)
//字符串连接
s1 := "200"
s2 := "success"
msg := s1 + s2
fmt.Printf("msg: %v\n", msg)
msg = fmt.Sprintf("%s%s", s1, s2)
fmt.Printf("msg: %v\n", msg)
msg = strings.Join([]string{s1, s2}, " ")
fmt.Printf("msg: %v\n", msg)
var buffer bytes.Buffer
buffer.WriteString(s1)
buffer.WriteString(s2)
fmt.Printf("buffer.String(): %v\n", buffer.String())
//转义字符
// \n \t
//索引切片 同python
s := "I LOVE GOLANG"
fmt.Printf("%v\n", s[1:9])
// 其他常用方法
fmt.Printf("%v\n", len(s))
fmt.Printf("%v\n", strings.Split(s, " "))
fmt.Printf("%v\n", strings.Contains(s, "LOVE"))
fmt.Printf("%v\n", strings.ToUpper(s))
fmt.Printf("%v\n", strings.ToLower(s))
fmt.Printf("%v\n", strings.HasPrefix(s, " "))
fmt.Printf("%v\n", strings.HasSuffix(s, "GO"))
fmt.Printf("%v\n", strings.Index(s, "G"))
}
type关键字
类型定义
语法 type NewType Type
package main
import "fmt"
func main(){
type MyInt int
var i MyInt
i = 10
fmt.Println(i)
}
类型别名
语法 type TypeAlias = Type
类型别名规定:TypeAlias 只是 Type 的别名,本质上 TypeAlias 与 Type 是同一个类型,就像一个孩子小时候有小名、乳名,上学后用学名,英语老师又会给他起英文名,但这些名字都指的是他本人。
类型别名与类型定义表面上看只有一个等号的差异,那么它们之间实际的区
别有哪些呢?下面通过一段代码来理解。
package main
import (
"fmt"
)
// 将NewInt定义为int类型
type NewInt int
// 将int取一个别名叫IntAlias
type IntAlias = int
func main() {
// 将a声明为NewInt类型
var a NewInt
// 查看a的类型名
fmt.Printf("a type: %T\n", a)
// 将a2声明为IntAlias类型
var a2 IntAlias
// 查看a2的类型名
fmt.Printf("a2 type: %T\n", a2)
}
区别
- 类型定义相当于定义了一个全新的类型,与之前的类型不同,而类型别名并没有定义全新的类型,而是使用别名替换了之前的类型
- 类型别名只会在代码中存在,在编程完成之后不会存在该别名
- 因为类型别名和原来的类型是一致的,所以原来类型的所有方法,类型别名都可以调用,但如果是重新定义的一个类型,那么不可以调用原来的任何方法。
go语言格式化输出
package main
import "fmt"
type WebSite struct {
Name string
}
func main() {
/*
%v var 任何变量值
%#v
%T 类型
%b %o %x 进制
%c 字符对应的Unicode值
%s 字符串
%p 指针
*/
webSite := WebSite{Name: "baidu"}
fmt.Printf("webSite: %v\n", webSite)
fmt.Printf("webSite: %#v\n", webSite)
fmt.Printf("webSite: %T\n", webSite)
b := false
fmt.Printf("b: %v\n", b)
}
go语言运算符
运算符介绍 运算符是一种特殊的符号,用以表示数据的运算,赋值和比较等
算数运算符
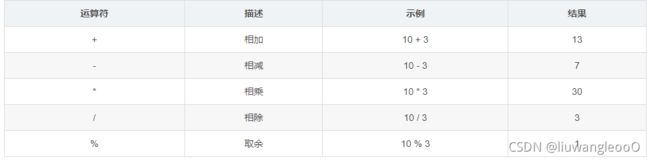
注意:
- 自增( ++ )和自减( – )在Go语言中是单独的语句, 并不是运算符, 也不是表达式.
- 不允许不同类型进行相加。
关系运算符
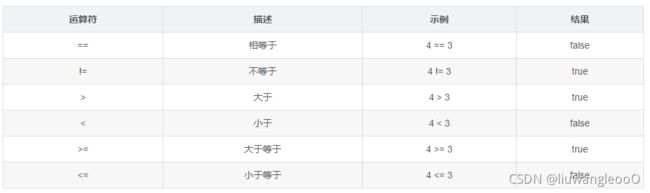
关系运算符中结果是布尔类型的,只有两个值true和false
逻辑运算符

赋值运算符

位运算符

其他运算符

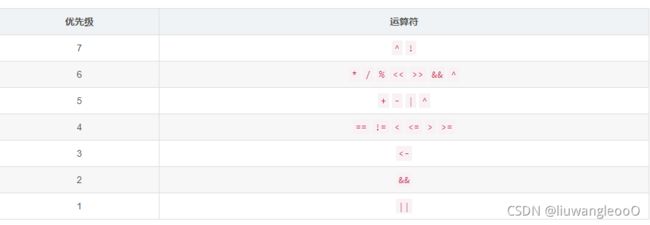
运算符的优先级
从上到下优先级由高到低
键盘输入语句
导包 fmt 调用fmt包的函数 Scanln 或者Scanf


进制
https://studygolang.com/search?q=golang%E8%BF%9B%E5%88%B6
位运算

go语言控制语句
分支结构
三种写法格式:if if……else if……else……if 话不多说上代码
package main
import "fmt"
func main() {
//if
flag := true
// 表达式一定是布尔值
if flag {
fmt.Println("a")
} else {
fmt.Println("b")
}
// 初始化变量放在表达式中 注意作用域
if age := 20; age > 18 {
fmt.Println("成年")
}
// 不能使用0/1表示真假
// if ……else
a, b := 1, 2
if a > b {
fmt.Println("a")
} else {
fmt.Println("b")
}
// if ……else if
score := 80
if score >= 60 && score < 70 {
fmt.Printf("score: %v\n", "C")
} else if score >= 70 && score < 90 {
fmt.Printf("score: %v\n", "B")
} else {
fmt.Printf("score: %v\n", "A")
}
}
特殊写法: if 还有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断,代码如下:
if err := Connect(); err != nil {
fmt.Println(err)
return
}
Connect 是一个带有返回值的函数,err:=Connect() 是一个语句,执行 Connect 后,将错误保存到 err 变量中。err != nil 才是 if 的判断表达式,当 err 不为空时,打印错误并返回。这种写法可以将返回值与判断放在一行进行处理,而且返回值的作用范围被限制在 if、else 语句组合中。
提示
在编程中,变量的作用范围越小,所造成的问题可能性越小,每一个变量代表一个状态,有状态的地方,状态就会被修改,函数的局部变量只会影响一个函数的执行,但全局变量可能会影响所有代码的执行状态,因此限制变量的作用范围对代码的稳定性有很大的帮助。
循环结构
与多数语言不同的是,Go语言中的循环语句只支持 for 关键字,而不支持 while 和 do-while 结构,关键字 for 的基本使用方法与C语言和 C++ 中非常接近,主要有以下这几种循环方法
package main
import "fmt"
func main() {
// for循环
s := "1234"
for i := 0; i < len(s); i++ {
fmt.Printf("i: %v\n", i)
}
i := 1
for ; i < 5; i++ {
fmt.Println(i)
}
j := 1
for j < 5 {
fmt.Println(j)
j++
}
// for range
var k = [...]int{1, 2, 3, 4, 5}
for i, v := range k {
fmt.Printf("i:%v v:%v\n", i, v)
}
}
switch
Go语言的 switch 要比C语言的更加通用,表达式不需要为常量,甚至不需要为整数,case 按照从上到下的顺序进行求值,直到找到匹配的项,如果 switch 没有表达式,则对 true 进行匹配,因此,可以将 if else-if else 改写成一个 switch。
package main
import "fmt"
func main() {
// switch
// 条件匹配 表达式
grade := 1
fmt.Println(grade)
switch grade {
case 'A':
fmt.Println("字母")
// 跨越 case 的 fallthrough——兼容C语言的 case 设计
fallthrough
case 1, 2, 3:
fmt.Println("数字")
default:
fmt.Println("默认")
}
}
在Go语言中 case 是一个独立的代码块,执行完毕后不会像C语言那样紧接着执行下一个 case,但是为了兼容一些移植代码,依然加入了 fallthrough 关键字来实现这一功能.
goto&break&continue
package main
import "fmt"
func f1() {
OuterLoop:
for i := 0; i < 2; i++ {
for j := 0; j < 5; j++ {
switch j {
case 2:
fmt.Println(i, j)
break OuterLoop
case 3:
fmt.Println(i, j)
break OuterLoop
}
}
}
fmt.Println("end...")
}
func f2() {
for x := 0; x < 10; x++ {
for y := 0; y < 10; y++ {
if y == 2 {
// 跳转到标签
goto breakHere
}
}
}
// 手动返回, 避免执行进入标签
return
// 标签
breakHere:
fmt.Println("done")
}
func f3() {
OuterLoop:
for i := 0; i < 2; i++ {
for j := 0; j < 5; j++ {
switch j {
case 2:
fmt.Println(i, j)
continue OuterLoop
}
}
}
}
func main() {
//流程控制关键字
/*break
结束 for、switch 和 select 的代码块
另外 break 语句还可以在语句后面添加标签,表示退出某个标签对应的代码块,
标签要求必须定义在对应的 for、switch 和 select 的代码块上。
*/
f1()
/*goto
Go语言中 goto 语句通过标签进行代码间的无条件跳转,
同时 goto 语句在快速跳出循环、避免重复退 出上也有一定的帮助,
使用 goto 语句能简化一些代码的实现过程。
*/
f2()
/*continue
Go语言中 continue 语句可以结束当前循环,
开始下一次的循环迭代过程,仅限在 for 循环内使用,
在 continue 语句后添加标签时,表示开始标签对应的循环,
*/
f3()
}
go语言容器
数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。因为数组的长度是固定的,所以在Go语言中很少直接使用数组。
package main
import "fmt"
func test() {
// 数字 字符串数组定义
var arr1 [2]int
fmt.Printf("arr1: %v\n", arr1)
fmt.Printf("arr1: %T\n", arr1)
var arr2 [2]string
fmt.Printf("arr2: %v\n", arr2)
fmt.Printf("arr2: %T\n", arr2)
// 初始化定义 名称 长度 类型
arr1 = [2]int{1, 3}
fmt.Printf("arr1: %v\n", arr1)
// 忽略数组长度
var arr3 = [...]string{"1", "32"}
fmt.Printf("arr3: %v\n", len(arr3))
}
// 数组的遍历
func getArrElement() {
var a1 = [...]int{1, 3, 4}
fmt.Printf("a1: %v\n", a1)
for _, v := range a1 {
fmt.Printf("v: %v\n", v)
}
}
func main() {
test()
getArrElement()
}
切片
和数组对应的类型是 Slice(切片),Slice 是可以增长和收缩的动态序列,功能也更灵活。
切片(slice)是对数组的一个连续片段的引用,所以切片是一个引用类型(因此更类似于 C/C++ 中的数组类型,或者 Python 中的 list 类型),这个片段可以是整个数组,也可以是由起始和终止索引标识的一些项的子集,需要注意的是,终止索引标识的项不包括在切片内。
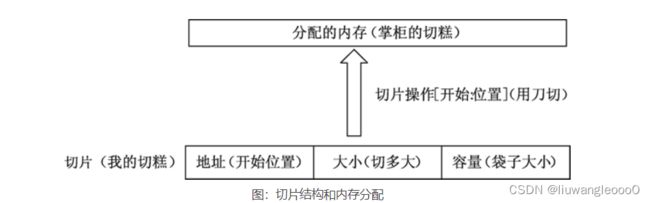
Go语言中切片的内部结构包含地址、大小和容量,切片一般用于快速地操作一块数据集合,如果将数据集合比作切糕的话,切片就是你要的“那一块”,切的过程包含从哪里开始(切片的起始位置)及切多大(切片的大小),容量可以理解为装切片的口袋大小,如下图所示。
package main
import "fmt"
func main() {
var arr1 = [...]int{1, 2, 3, 4}
fmt.Printf("arr1: %v\n", arr1)
// 切片 声明 定义
var s1 []int
fmt.Printf("slice1: %v\n", s1)
var s2 = make([]int, 2)
fmt.Printf("s2: %v\n", s2)
// 长度 容量
s1 = []int{1, 3, 4, 5}
fmt.Printf("s1: %v\n", s1)
fmt.Printf("len(s1): %v\n", len(s1))
fmt.Printf("cap(s1): %v\n", cap(s1))
//初始化
// 使用数组初始化
s3 := arr1[:]
fmt.Printf("s3: %v\n", s3)
//使用数组的部分元素初始化 (切片表达式)
s4 := arr1[1:4]
fmt.Printf("s4: %v\n", s4)
// 遍历
for i := 0; i < len(s1); i++ {
fmt.Printf("s1[i]: %v\n", s1[i])
}
for _, v := range s1 {
fmt.Printf("v: %v\n", v)
}
// 添加
s1 = append(s1, 100)
fmt.Printf("s1: %v\n", s1)
// 删除
s1 = append(s1[:3], s1[4:]...)
fmt.Printf("s1: %v\n", s1)
// copy
s1Copy := make([]int, len(s1))
copy(s1Copy, s1)
fmt.Printf("s1Copy: %v\n", s1Copy)
}
…用法
● 第一个用法主要是用于函数有多个不定参数的情况,表示为可变参数,可以接受任意个数但相同类型的参数。
● 第二个用法是slice可以被打散进行传递。
map
Go语言中 map 是一种特殊的数据结构,一种元素对(pair)的无序集合,pair 对应一个 key(索引)和一个 value(值),所以这个结构也称为关联数组或字典,这是一种能够快速寻找值的理想结构,给定 key,就可以迅速找到对应的 value。
package main
import "fmt"
func main() {
// 声明 名称 key的类型 value的类型
var m1 map[int]string
fmt.Printf("m1: %v\n", m1)
fmt.Printf("m1: %T\n", m1)
m2 := make(map[int]string)
fmt.Printf("m2: %v\n", m2)
// 初始化
var m3 = map[int]string{1: "TOM", 2: "lib"}
fmt.Printf("m1: %v\n", m3)
m4 := make(map[string]string)
m4["a"] = "1"
fmt.Printf("m3: %v\n", m4)
fmt.Printf("m4[\"a\"]: %v\n", m4["a"])
// 遍历
for k, v := range m3 {
fmt.Printf("k: %v\n", k)
fmt.Printf("v: %v\n", v)
}
}
go语言函数
特性
- 3种函数:普通函数 匿名函数 方法(定义在结构体上)
- 不允许重载
- 不能嵌套函数 但可以嵌套匿名函数
- 函数是一个值 可以将函数赋值给一个变量
- 函数可以作为参数传递给另外一个函数
- 函数的返回值可以是一个函数
- 函数调用的时候,如果有参数传递给函数 则先拷贝参数的副本 再将副本传递给函数
- 函数的参数可以没有名称
函数
package main
import "fmt"
func sum(a int, b int) int {
return a + b
}
func test1() {
fmt.Println("没有参数和返回值的函数")
}
func test2() string {
return "123"
}
func test3() (name string, age int) {
name = "job"
age = 23
return name, age
}
// 形参
func test4(x int) string {
x = 200
return "111"
// return x
}
func test5(s []int) {
s[0] = 1000
}
func test6(args ...int) {
for _, v := range args {
fmt.Printf("v: %v\n", v)
}
}
func sayHello(name string) {
fmt.Printf("hello, %s\n", name)
}
func test7(name string, f func(string)) {
f(name)
}
func main() {
// 返回值
// 没有参数和返回值
test1()
// 有参数一个返回值
r := test2()
fmt.Printf("r: %v\n", r)
// 有多个返回值
n, _ := test3()
fmt.Printf("n: %v\n", n)
// 参数
ret := sum(1, 2)
fmt.Printf("ret: %v\n", ret)
// 实参
/*
x的值没有改变 说明参数传递是拷贝一个副本
有些数据类型是就是指针类型 所以拷贝传值也就是拷贝的指针
拷贝后的参数任然指向底层数据结构 可能会改变原来的数据结构的值
如
*/
x := 100
new_x := test4(x)
fmt.Printf("new_x: %v\n", new_x)
fmt.Printf("x: %v\n", x)
s := []int{1, 2, 4}
test5(s)
fmt.Printf("s: %v\n", s)
// 可变参数
test6(1, 2, 43, 5)
// 高阶函数 函数作为参数
test7("liusan", sayHello)
// 函数作为返回值
f := cal("-")
ff := f(1, 2)
fmt.Printf("ff: %v\n", ff)
}
函数类型实现接口
package main
import (
"fmt"
)
// 调用器接口
type Invoker interface {
// 需要实现一个Call方法
Call(interface{})
}
// 结构体类型
type Struct struct {
}
// 实现Invoker的Call
func (s *Struct) Call(p interface{}) {
fmt.Println("from struct", p)
}
// 函数定义为类型
type FuncCaller func(interface{})
// 实现Invoker的Call
func (f FuncCaller) Call(p interface{}) {
// 调用f函数本体
f(p)
}
func main() {
// 声明接口变量
var invoker Invoker
// 实例化结构体
s := new(Struct)
// 将实例化的结构体赋值到接口
invoker = s
// 使用接口调用实例化结构体的方法Struct.Call
invoker.Call("hello")
// 将匿名函数转为FuncCaller类型,再赋值给接口
invoker = FuncCaller(func(v interface{}) {
fmt.Println("from function", v)
})
// 使用接口调用FuncCaller.Call,内部会调用函数本体
invoker.Call("hello")
}
匿名函数
匿名函数是指不需要定义函数名的一种函数实现方式,由一个不带函数名的函数声明和函数体组成,下面来具体介绍一下匿名函数的定义及使用。
定义一个匿名函数
// 匿名函数
nm := func(a int, b int) int {
return a + b
}
fmt.Printf("nm: %v\n", nm)
匿名函数用作回调函数
package main
import (
"fmt"
)
// 遍历切片的每个元素, 通过给定函数进行元素访问
func visit(list []int, f func(int)) {
for _, v := range list {
f(v)
}
}
func main() {
// 使用匿名函数打印切片内容
visit([]int{1, 2, 3, 4}, func(v int) {
fmt.Println(v)
})
}
使用匿名函数实现操作封装
package main
import (
"flag"
"fmt"
)
var skillParam = flag.String("skill", "", "skill to perform")
func main() {
flag.Parse()
var skill = map[string]func(){
"fire": func() {
fmt.Println("chicken fire")
},
"run": func() {
fmt.Println("soldier run")
},
"fly": func() {
fmt.Println("angel fly")
},
}
if f, ok := skill[*skillParam]; ok {
f()
} else {
fmt.Println("skill not found")
}
}
闭包
Go语言中闭包是引用了自由变量的函数,被引用的自由变量和函数一同存在,即使已经离开了自由变量的环境也不会被释放或者删除,在闭包中可以继续使用这个自由变量,因此,简单的说:
函数 + 引用环境 = 闭包
同一个函数与不同引用环境组合,可以形成不同的实例,如下图所示。
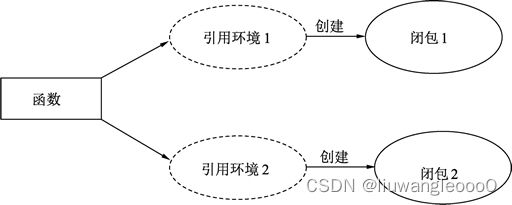
一个函数类型就像结构体一样,可以被实例化,函数本身不存储任何信息,只有与引用环境结合后形成的闭包才具有“记忆性”,函数是编译期静态的概念,而闭包是运行期动态的概念
在闭包内部修改引用的变量
// 准备一个字符串
str := "hello world"
// 创建一个匿名函数
foo := func() {
// 匿名函数中访问str
str = "hello dude"
}
// 调用匿名函数
foo()
闭包的记忆效应
被捕获到闭包中的变量让闭包本身拥有了记忆效应,闭包中的逻辑可以修改闭包捕获的变量,变量会跟随闭包生命期一直存在,闭包本身就如同变量一样拥有了记忆效应。
package main
import (
"fmt"
)
// 提供一个值, 每次调用函数会指定对值进行累加
func Accumulate(value int) func() int {
// 返回一个闭包
return func() int {
// 累加
value++
// 返回一个累加值
return value
}
}
func main() {
// 创建一个累加器, 初始值为1
accumulator := Accumulate(1)
// 累加1并打印
fmt.Println(accumulator())
fmt.Println(accumulator())
// 打印累加器的函数地址
fmt.Printf("%p\n", &accumulator)
// 创建一个累加器, 初始值为1
accumulator2 := Accumulate(10)
// 累加1并打印
fmt.Println(accumulator2())
// 打印累加器的函数地址
fmt.Printf("%p\n", &accumulator2)
}
递归函数
几个例子说明
斐波那契数列
package main
import "fmt"
func main() {
result := 0
for i := 1; i <= 10; i++ {
result = fibonacci(i)
fmt.Printf("fibonacci(%d) is: %d\n", i, result)
}
}
func fibonacci(n int) (res int) {
if n <= 2 {
res = 1
} else {
res = fibonacci(n-1) + fibonacci(n-2)
}
return
}
阶乘
package main
import "fmt"
func Factorial(n uint64) (result uint64) {
if n > 0 {
result = n * Factorial(n-1)
return result
}
return 1
}
func main() {
var i int = 10
fmt.Printf("%d 的阶乘是 %d\n", i, Factorial(uint64(i)))
}
defer
用于注册延迟调用
直到函数return之前执行
多个defer语句 按照先进后出执行
defer语句中的变量 在声明时定义
package main
import "fmt"
func s1() {
defer fmt.Println("后面执行1")
fmt.Println("1111")
defer fmt.Println("后面执行")
fmt.Println("2222")
}
func main() {
s1()
}
init函数
先于main函数自动执行 不能被调用
没有输入参数 返回值
每个包有多个init函数
包的每个源文件可以有多个init函数
同一包的init函数执行顺序 没有明确定义 编程时要注意程序不要依赖这个执行顺序
不同的init函数按照包导入的依赖关系决定执行顺序
go语言指针
与 Java 和 .NET 等编程语言不同,Go语言为程序员提供了控制数据结构指针的能力,但是,并不能进行指针运算。Go语言允许你控制特定集合的数据结构、分配的数量以及内存访问模式,这对于构建运行良好的系统是非常重要的。指针对于性能的影响不言而喻,如果你想要做系统编程、操作系统或者网络应用,指针更是不可或缺的一部分。
指针(pointer)在Go语言中可以被拆分为两个核心概念:
- 类型指针,允许对这个指针类型的数据进行修改,传递数据可以直接使用指针,而无须拷贝数据,类型指针不能进行偏移和运算。
- 切片,由指向起始元素的原始指针、元素数量和容量组成。
受益于这样的约束和拆分,Go语言的指针类型变量即拥有指针高效访问的特点,又不会发生指针偏移,从而避免了非法修改关键性数据的问题。同时,垃圾回收也比较容易对不会发生偏移的指针进行检索和回收。
切片比原始指针具备更强大的特性,而且更为安全。切片在发生越界时,运行时会报出宕机,并打出堆栈,而原始指针只会崩溃。
指针地址和指针类型
一个指针变量可以指向任何一个值的内存地址,它所指向的值的内存地址在 32 和 64 位机器上分别占用 4 或 8 个字节,占用字节的大小与所指向的值的大小无关。当一个指针被定义后没有分配到任何变量时,它的默认值为 nil。指针变量通常缩写为 ptr。
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用在变量名前面添加&操作符(前缀)来获取变量的内存地址(取地址操作),格式如下:
ptr := &v // v 的类型为 T
其中 v 代表被取地址的变量,变量 v 的地址使用变量 ptr 进行接收,ptr 的类型为*T,称做 T 的指针类型,*代表指针。
指针语法:var var_name *var_type
package main
import (
"fmt"
)
func main() {
var cat int = 1
var str string = "banana"
fmt.Printf("%p %p", &cat, &str)
}
从指针获取指针指向的值
当使用&操作符对普通变量进行取地址操作并得到变量的指针后,可以对指针使用*操作符,也就是指针取值,代码如下。
package main
import (
"fmt"
)
func main() {
// 准备一个字符串类型
var house = "Malibu Point 10880, 90265"
// 对字符串取地址, ptr类型为*string
ptr := &house
// 打印ptr的类型
fmt.Printf("ptr type: %T\n", ptr)
// 打印ptr的指针地址
fmt.Printf("address: %p\n", ptr)
// 对指针进行取值操作
value := *ptr
// 取值后的类型
fmt.Printf("value type: %T\n", value)
// 指针取值后就是指向变量的值
fmt.Printf("value: %s\n", value)
}
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址操作使用&操作符,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值操作使用*操作符,可以获得指针变量指向的原变量的值。
使用指针修改值
package main
import "fmt"
// 交换函数
func swap(a, b *int) {
// 取a指针的值, 赋给临时变量t
t := *a
// 取b指针的值, 赋给a指针指向的变量
*a = *b
// 将a指针的值赋给b指针指向的变量
*b = t
}
func main() {
// 准备两个变量, 赋值1和2
x, y := 1, 2
// 交换变量值
swap(&x, &y)
// 输出变量值
fmt.Println(x, y)
}
创建指针的另一种方法——new() 函数
Go语言还提供了另外一种方法来创建指针变量,格式如下:
new(类型)
一般这样写:
str := new(string)
*str = "Go语言教程"
fmt.Println(*str)
new() 函数可以创建一个对应类型的指针,创建过程会分配内存,被创建的指针指向默认值。
go语言结构体
Go 语言通过用自定义的方式形成新的类型,结构体是类型中带有成员的复合类型。Go 语言使用结构体和结构体成员来描述真实世界的实体和实体对应的各种属性。
Go 语言中的类型可以被实例化,使用new或&构造的类型实例的类型是类型的指针。
结构体成员是由一系列的成员变量构成,这些成员变量也被称为“字段”。字段有以下特性:
- 字段拥有自己的类型和值。
- 字段名必须唯一。
- 字段的类型也可以是结构体,甚至是字段所在结构体的类型。
关于 Go 语言的类(class),Go 语言中没有“类”的概念,也不支持“类”的继承等面向对象的概念。
Go 语言的结构体与“类”都是复合结构体,但 Go 语言中结构体的内嵌配合接口比面向对象具有更高的扩展性和灵活性。
Go 语言不仅认为结构体能拥有方法,且每种自定义类型也可以拥有自己的方法。
话不多说,全在代码
package main
import "fmt"
// 嵌套结构体
type Dog struct {
name, color string
age int
}
// 定义结构体
type Person struct {
id int
name string
age int
email string
dog Dog
}
type Customer struct {
name string
}
func (customer Customer) login(name string, pwd string) bool {
fmt.Printf("customer: %p\n", customer)
if name == customer.name && pwd == "123" {
return true
}
return false
}
func (customer *Customer) show(name string) {
fmt.Printf("customer: %p\n", customer)
fmt.Printf("%v 欢迎登陆 %v\n", customer.name, name)
}
func (person Person) eat(food string) {
fmt.Printf("%v...eat...%v\n", person.name, food)
}
func showPerson(person *Person) {
person.id = 12
person.name = "func"
fmt.Printf("person: %v\n", *person)
}
func main() {
// 定义结构体 var strcut_name struct{}
var james Person
// 初始化
james = Person{
id: 1,
name: "james",
age: 13,
email: "[email protected]",
}
fmt.Printf("james: %v\n", james)
// 匿名结构体
var dog struct {
name string
}
fmt.Printf("dog: %v\n", dog)
// 创建结构体指针
var person Person
person.id = 0
person.name = "ROB"
person.age = 11
person.email = "[email protected]"
fmt.Printf("p: %v\n", person)
var p_person *Person
p_person = &person
fmt.Printf("person: %v\n", person)
fmt.Printf("p_person: %p\n", p_person)
fmt.Printf("p_person: %v\n", *p_person)
// new创建
var new_person = new(Person)
fmt.Printf("p_new: %v\n", new_person)
fmt.Printf("p_new: %T\n", new_person)
// 结构体为函数参数
func_person := Person{
id: 100,
name: "func_struct",
}
p_func_person := &func_person
fmt.Printf("p_func_person: %v\n", *p_func_person)
showPerson(p_func_person)
//结构体嵌套
d := Dog{
name: "修狗",
color: "red",
age: 2,
}
zhuren := Person{
name: "zhuren",
age: 23,
dog: d,
}
fmt.Printf("zhuren: %v\n", zhuren)
// 方法 func (recv mytype) my_method(param) return_type
zhuren.eat("狗屎")
var customer Customer
customer = Customer{
name: "li",
}
customer.login("li", "123")
customer.show("系统")
// 方法接收者类型
// 结构体实例中 也有值类型和引用类型 方法的接收者是结构体
// 值类型 复制 引用类型 不复制
}
go语言接口
接口本身是调用方和实现方均需要遵守的一种协议,大家按照统一的方法命名参数类型和数量来协调逻辑处理的过程。
Go 语言中使用组合实现对象特性的描述。对象的内部使用结构体内嵌组合对象应该具有的特性,对外通过接口暴露能使用的特性。
Go 语言的接口设计是非侵入式的,接口编写者无须知道接口被哪些类型实现。而接口实现者只需知道实现的是什么样子的接口,但无须指明实现哪一个接口。编译器知道最终编译时使用哪个类型实现哪个接口,或者接口应该由谁来实现。
·话不多说,全在代码
package main
import "fmt"
type USB interface {
read()
write()
}
type Computer struct {
name string
}
type Player interface {
playMusic()
}
type Video interface {
playVideo()
}
type Mobile struct {
}
type Pet interface {
eat()
}
type Pig struct{}
type Cat struct{}
type Flyer interface {
fly()
}
type Swimmer interface {
swim()
}
type FlyFish interface {
Flyer
Swimmer
}
type Fish struct{}
func (f Fish) fly() {
fmt.Println("flying")
}
func (f Fish) swim() {
fmt.Println("swimming")
}
func (p Pig) eat() {
fmt.Printf("pig eating...\n")
}
func (c Cat) eat() {
fmt.Printf("cat eating...\n")
}
func (m Mobile) playMusic() {
fmt.Println("play music")
}
func (m Mobile) playVideo() {
fmt.Println("play video")
}
func (c Computer) read() {
fmt.Printf("c.name: %v\n", c.name)
fmt.Println("reading...")
}
func (c Computer) write() {
fmt.Printf("c.name: %v\n", c.name)
fmt.Println("write...")
}
func main() {
// 定义接口
/*
type interface_name interface{
}
*/
c := Computer{
name: "huawei",
}
c.read()
c.write()
// 接口 值类型接收者 指针类型接收者
//接口和类型关系
// 一个类型多个接口
m := Mobile{}
m.playMusic()
m.playVideo()
// 一个接口多个类型
var pet Pet
pet = Pig{}
pet.eat()
pet = Cat{}
pet.eat()
// 接口嵌套
var ff FlyFish
ff = Fish{}
ff.fly()
ff.swim()
}
go语言包
Go语言的包借助了目录树的组织形式,一般包的名称就是其源文件所在目录的名称,虽然Go语言没有强制要求包名必须和其所在的目录名同名,但还是建议包名和所在目录同名,这样结构更清晰。
包可以定义在很深的目录中,包名的定义是不包括目录路径的,但是包在引用时一般使用全路径引用。比如在GOPATH/src/a/b/ 下定义一个包 c。在包 c 的源码中只需声明为package c,而不是声明为package a/b/c,但是在导入 c 包时,需要带上路径,例如import “a/b/c”。
包的习惯用法:
- 包名一般是小写的,使用一个简短且有意义的名称。
- 包名一般要和所在的目录同名,也可以不同,包名中不能包含- 等特殊符号。
- 包一般使用域名作为目录名称,这样能保证包名的唯一性,比如 GitHub 项目的包一般会放到GOPATH/src/github.com/userName/projectName 目录下。
- 包名为 main 的包为应用程序的入口包,编译不包含 main 包的源码文件时不会得到可执行文件。
- 一个文件夹下的所有源码文件只能属于同一个包,同样属于同一个包的源码文件不能放在多个文件夹下。
包的导入
要在代码中引用其他包的内容,需要使用 import 关键字导入使用的包。具体语法如下:
import "包的路径"
注意事项:
- import 导入语句通常放在源码文件开头包声明语句的下面;
- 导入的包名需要使用双引号包裹起来;
- 包名是从GOPATH/src/ 后开始计算的,使用/ 进行路径分隔。
包的导入有两种写法,分别是单行导入和多行导入。
单行导入
单行导入的格式如下:
import "包 1 的路径"
import "包 2 的路径"
多行导入
多行导入的格式如下:
import (
"包 1 的路径"
"包 2 的路径"
)
包的导入路径
包的引用路径有两种写法,分别是全路径导入和相对路径导入。
全路径导入
包的绝对路径就是GOROOT/src/或GOPATH/src/后面包的存放路径,如下所示:
import "lab/test"
import "database/sql/driver"
import "database/sql"
上面代码的含义如下:
test 包是自定义的包,其源码位于GOPATH/src/lab/test 目录下;
driver 包的源码位于GOROOT/src/database/sql/driver 目录下;
sql 包的源码位于GOROOT/src/database/sql 目录下。
相对路径导入
相对路径只能用于导入GOPATH 下的包,标准包的导入只能使用全路径导入。
例如包 a 的所在路径是GOPATH/src/lab/a,包 b 的所在路径为GOPATH/src/lab/b,如果在包 b 中导入包 a ,则可以使用相对路径导入方式。示例如下:
// 相对路径导入
import "../a"
当然了,也可以使用上面的全路径导入,如下所示:
// 全路径导入
import "lab/a"
包的引用格式
包的引用有四种格式,下面以 fmt 包为例来分别演示一下这四种格式。
标准引用格式
import "fmt"
此时可以用fmt.作为前缀来使用 fmt 包中的方法,这是常用的一种方式。示例代码如下:
package main
import "fmt"
func main() {
fmt.Println("C语言中文网")
}
自定义别名引用格式
在导入包的时候,我们还可以为导入的包设置别名,如下所示:
import F "fmt"
其中 F 就是 fmt 包的别名,使用时我们可以使用F.来代替标准引用格式的fmt.来作为前缀使用 fmt 包中的方法。示例代码如下:
package main
import F "fmt"
func main() {
F.Println("C语言中文网")
}
省略引用格式
import . "fmt"
这种格式相当于把 fmt 包直接合并到当前程序中,在使用 fmt 包内的方法是可以不用加前缀fmt.,直接引用。示例代码如下:
package main
import . "fmt"
func main() {
//不需要加前缀 fmt.
Println("C语言中文网")
}
匿名引用格式
在引用某个包时,如果只是希望执行包初始化的 init 函数,而不使用包内部的数据时,可以使用匿名引用格式,如下所示:
import _ "fmt"
匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中。
使用标准格式引用包,但是代码中却没有使用包,编译器会报错。如果包中有 init 初始化函数,则通过import _ “包的路径” 这种方式引用包,仅执行包的初始化函数,即使包没有 init 初始化函数,也不会引发编译器报错。
示例代码如下:
package main
import (
_ "database/sql"
"fmt"
)
func main() {
fmt.Println("C语言中文网")
}
注意:
- 一个包可以有多个 init 函数,包加载时会执行全部的 init 函数,但并不能保证执行顺序,所以不建议在一个包中放入多个 init 函数,将需要初始化的逻辑放到一个 init 函数里面。
- 包不能出现环形引用的情况,比如包 a 引用了包 b,包 b 引用了包 c,如果包 c 又引用了包 a,则编译不能通过。
- 包的重复引用是允许的,比如包 a 引用了包 b 和包 c,包 b 和包 c 都引用了包 d。这种场景相当于重复引用了 d,这种情况是允许的,并且 Go 编译器保证包 d 的 init 函数只会执行一次。
包加载
通过前面一系列的学习相信大家已经大体了解了 Go 程序的启动和加载过程,在执行 main 包的 mian 函数之前, Go 引导程序会先对整个程序的包进行初始化。整个执行的流程如下图所示。
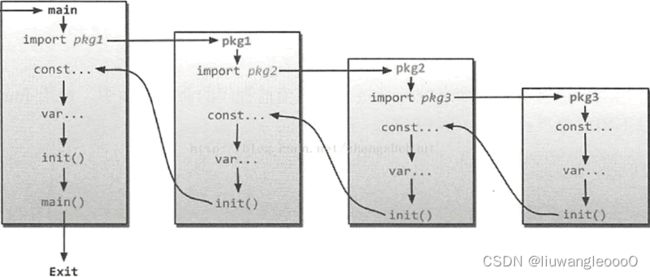
Go语言包的初始化有如下特点:
- 包初始化程序从 main 函数引用的包开始,逐级查找包的引用,直到找到没有引用其他包的包,最终生成一个包引用的有向无环图。
- Go 编译器会将有向无环图转换为一棵树,然后从树的叶子节点开始逐层向上对包进行初始化。
- 单个包的初始化过程如上图所示,先初始化常量,然后是全局变量,最后执行包的 init 函数。
包管理
go mod使用方法
- 初始化模块
go mod init 项目名称 - 依赖关系处理
go mod tidy - 将依赖包复制到项目下的vendor目录
go mod vendor - 显示依赖关系
go list -m -all - 显示详细依赖关系
go list -m - json all - 下载依赖
go mod download [path&version]